爬虫入门07——requests中携带cookie信息
- 对于需要登陆的网站如果不携带cookie是无法获取我们所需内容的
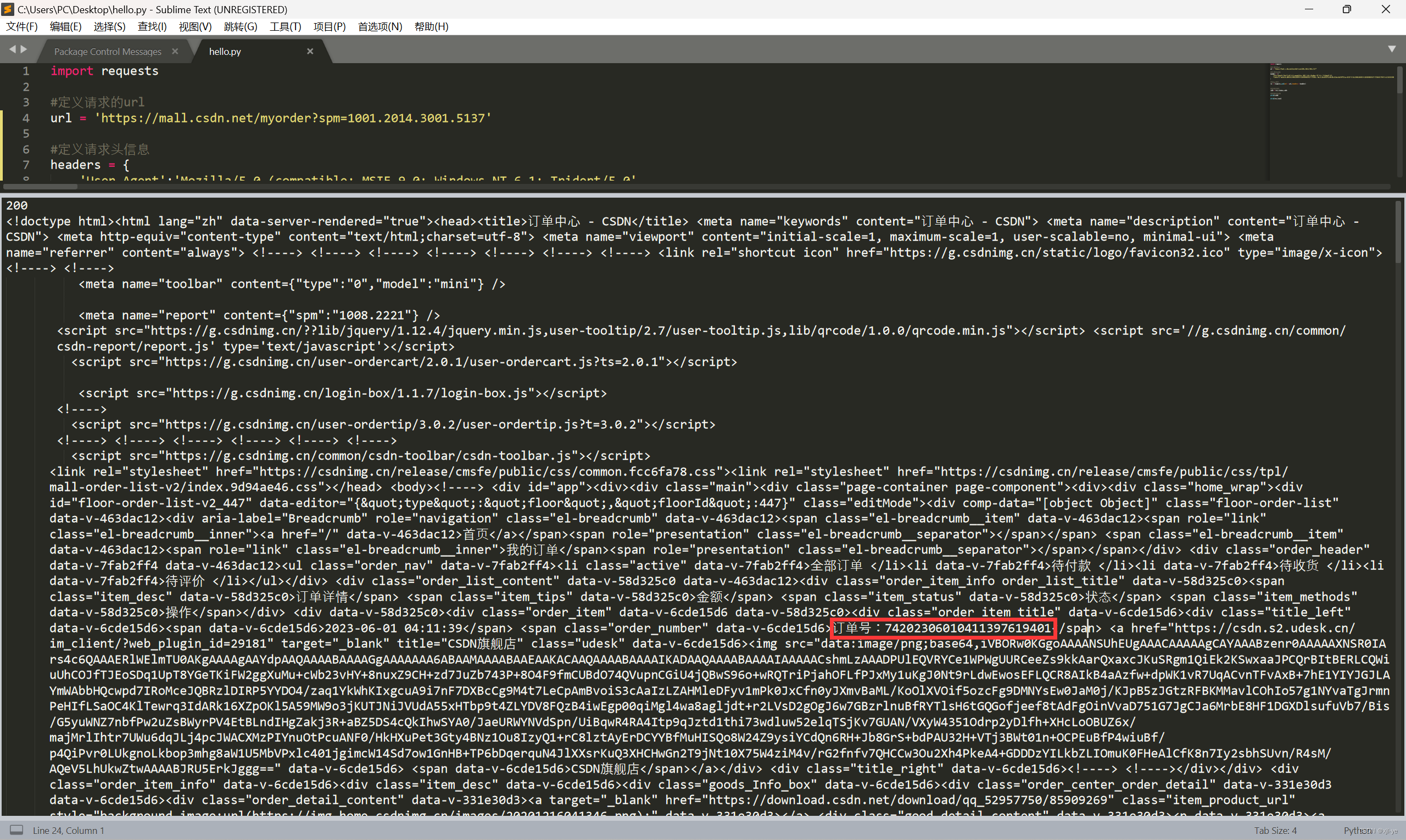
- 就以查看我在CSDN中的订单为例,在登陆后可以查看到订单信息
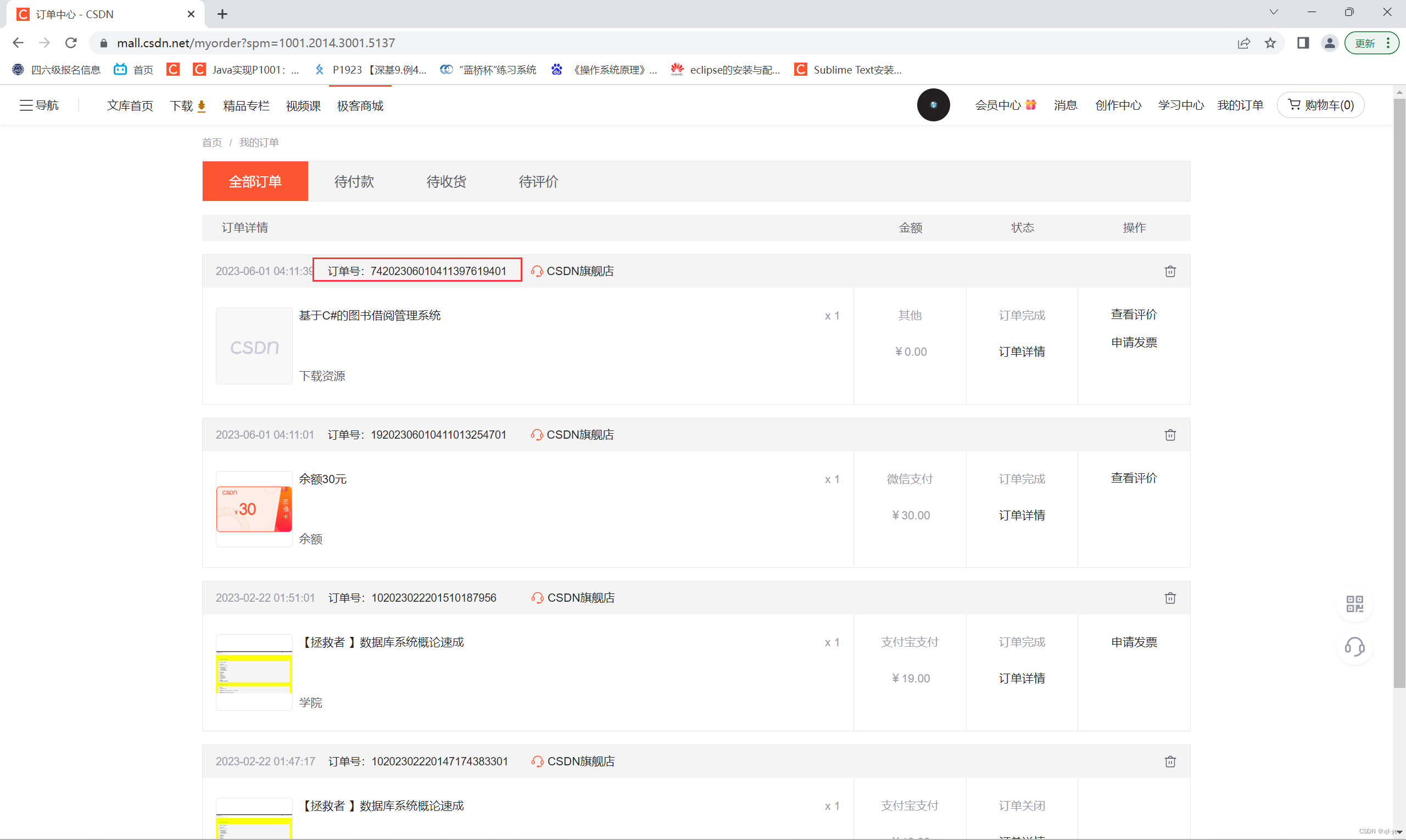
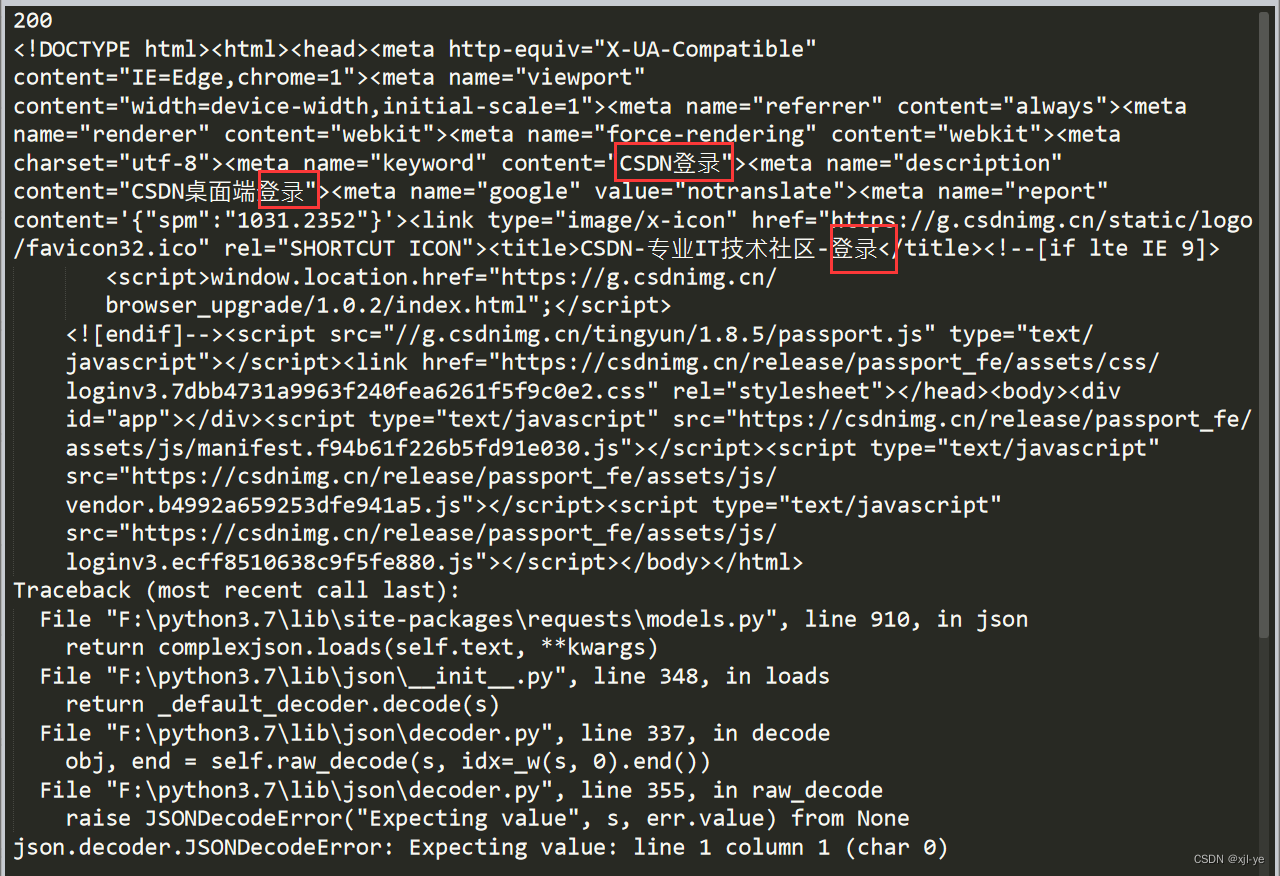
- 而当我们使用Python代码发出请求时,是不携带cookie,因此无法拿到订单相关信息,通过实验我们有的确发现得到的内容并不是所需的有关订单的内容,而是登陆的内容
import requests
#定义请求的url
url = 'https://mall.csdn.net/myorder?spm=1001.2014.3001.5137'
#定义请求头信息
headers = {
'User-Agent':'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0'
}
#发起get请求
res = requests.get(url = url,headers = headers)
#获取响应结果
code = res.status_code
#获取响应状态码
print(code)
print(res.text)
- 解决方法(笨方法,需要自己去找cookie是什么,但能用)
- 直接查看网站的cookie
- 右键单击选择检查
- 刷新一下,点击网络,标头,可以看到一大串的cookie
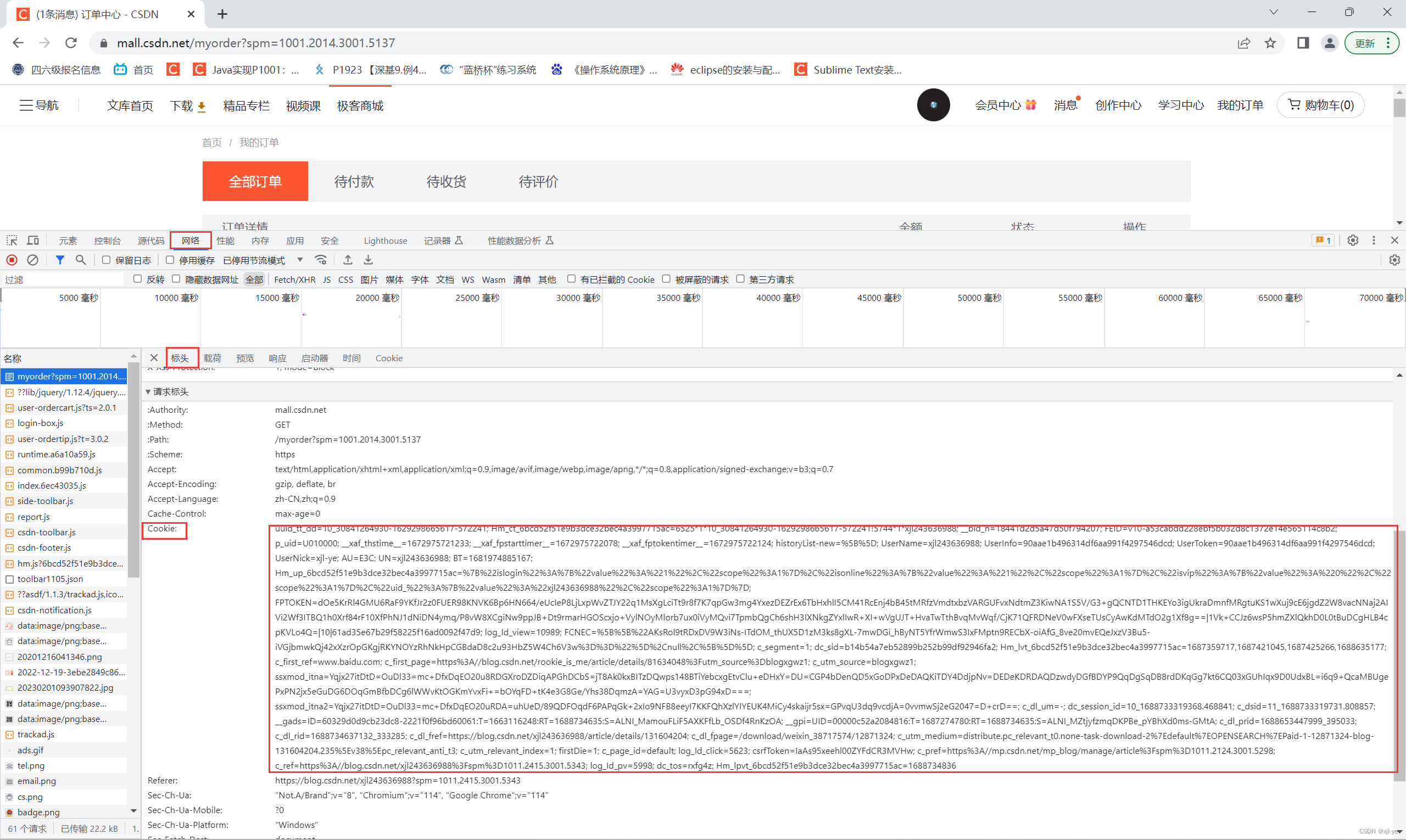
- 把这个cookie信息复制下来,放到代码中的头信息里

- 运行后可以发现获得了到订单编号啦