为啥要数据总线
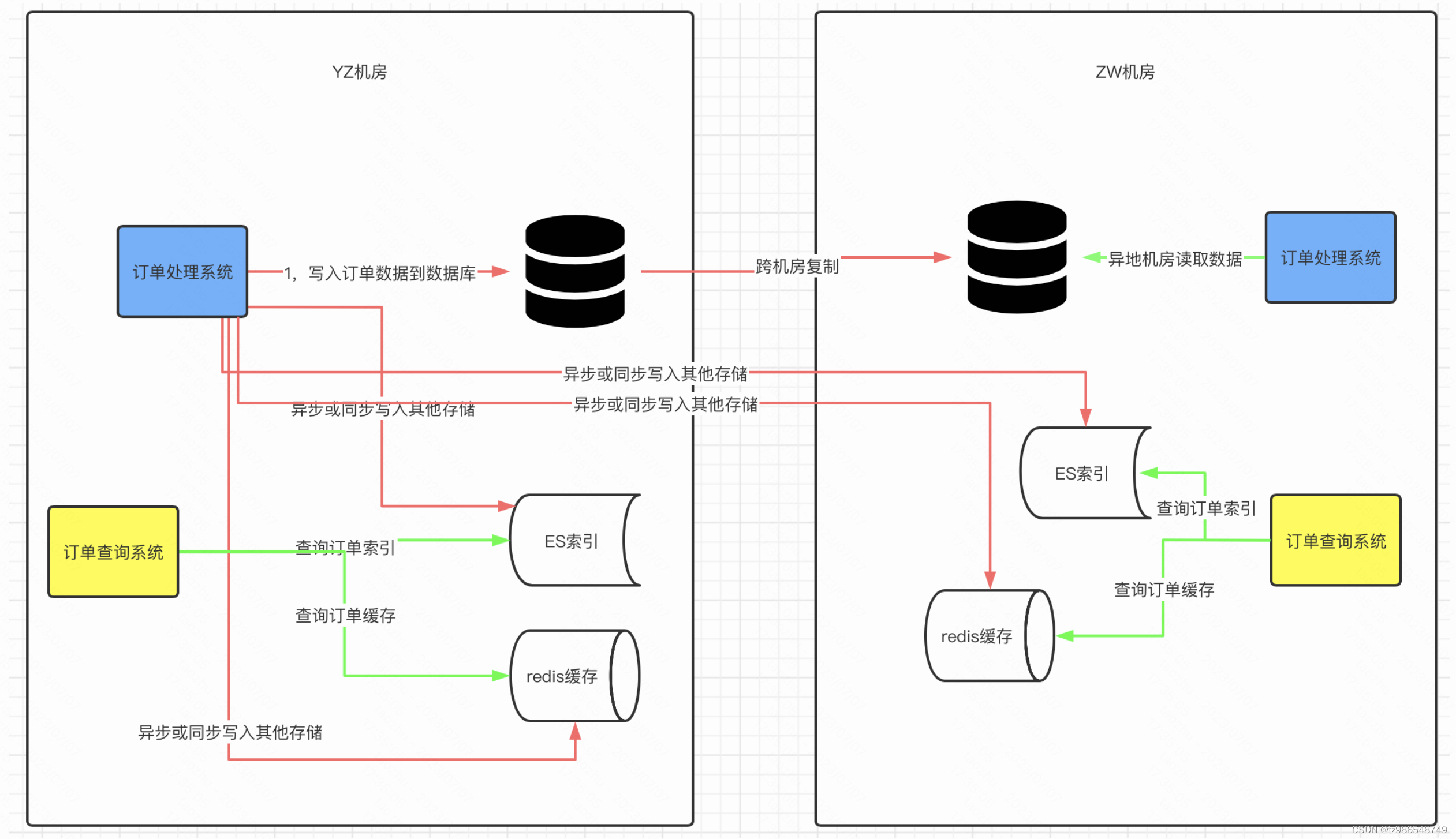
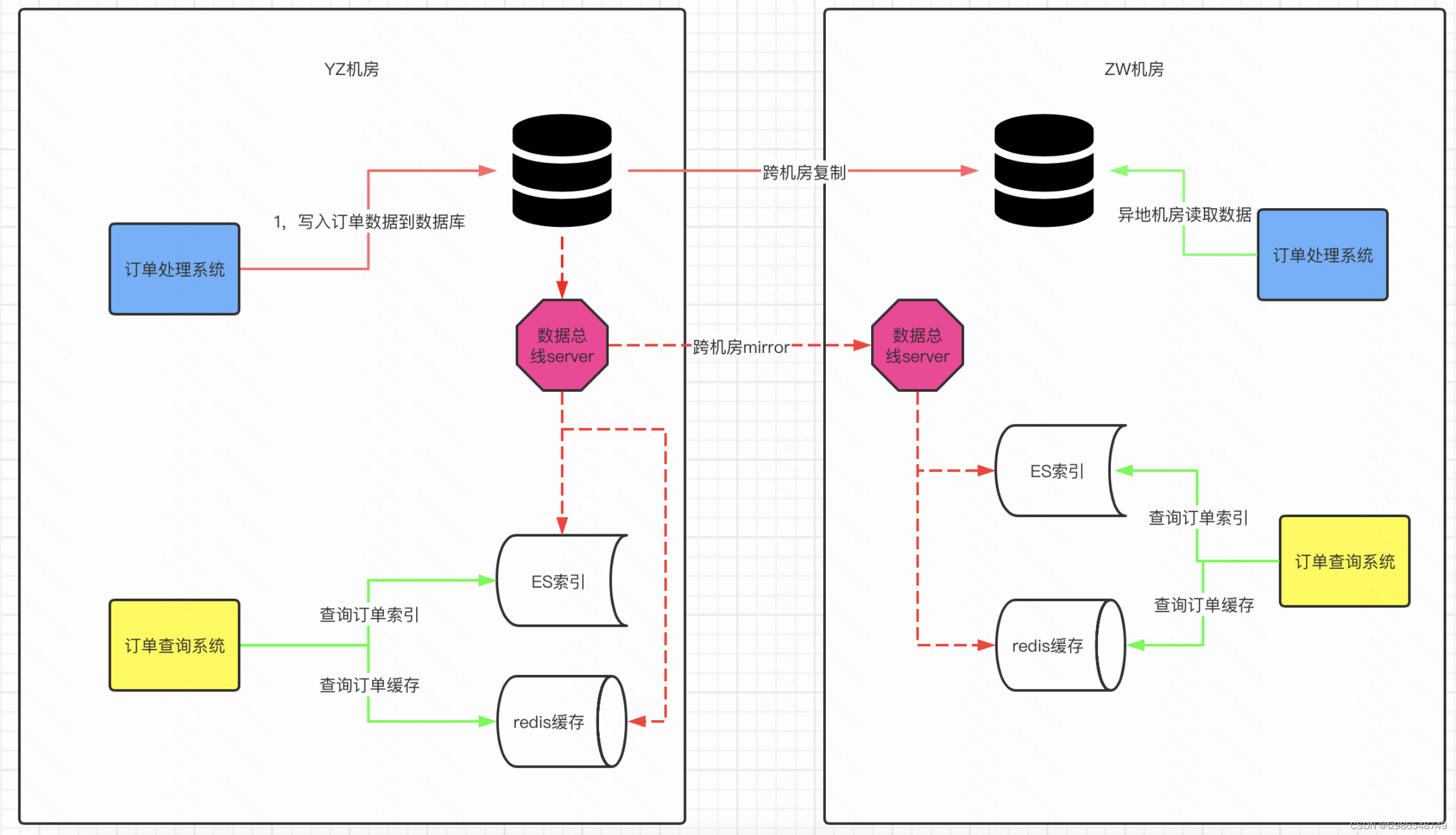
- 使用服务化方式发布,业务端和中间件完全解耦合。
- 一处生产,处处消费设计理念。
- 提供用户可定制的托管化通用消费方案(如同步mysql到缓存,同步mysql到es,消费mysql到大数据等托管服务)
特性
顺序消费
场景
刷缓存。在刷缓存的过程中,存在“回源”问题:缓存中不存在需要的数据时需要去数据库中重新查找。
在利用消息队列刷新缓存时,需要缓存的数据一般为表中某些行的值,所以保持表级别的有序即可。如果需要缓存的数据跨越多个表,则需要保持数据库级别的有序。
原理
要求整个链路是有序的
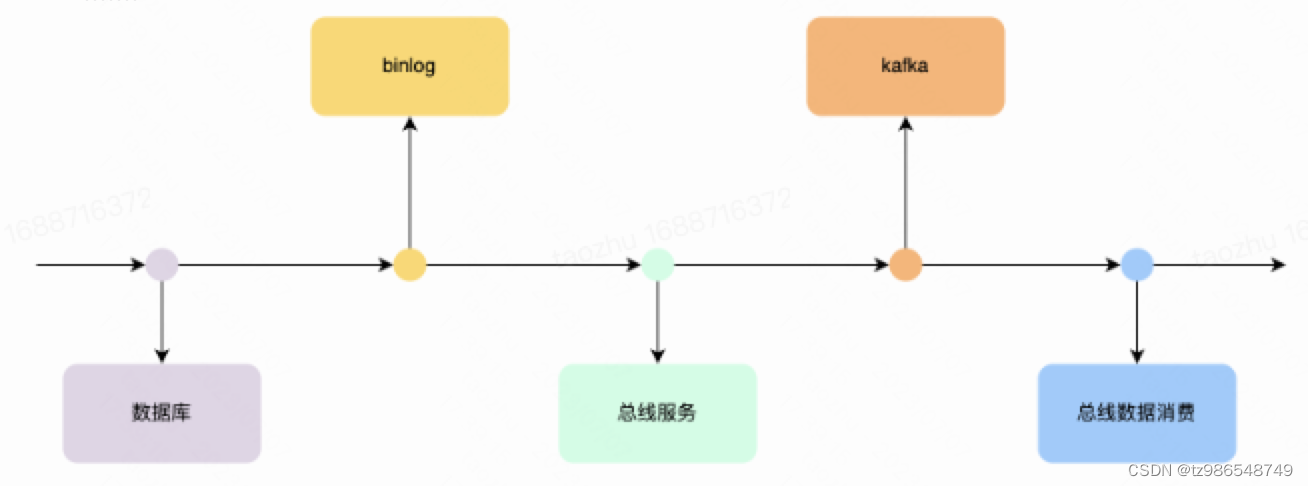
- 数据库到binlog
mysql的事务机制保证写入到binlog的顺序是整个mysql集群有序的 - 总线服务拉取binlog
分布式协调器确保一个mysql集群同时只有一个实例在消费 - 总线写入Kafka
在发送消息到 Kafka的过程中,会根据db标识进行hash计算,然后根据hash值执行顺序发送,保证同一个hash值的数据发送到同一个Kafka的分区 - 总线客户端消费
Client在消费消息时,定义顺序任务标识,放入同一队列,单线程执行队列任务,一旦用户消费失败触发重试逻辑,保证上一个消费成功才进行下一次的消费逻辑。
事务消费
场景
类似事务消息的玩法,本地数据库事务执行完成后,数据总线通知client消费方
原理
以GtidEvent、XidEvent事件作为事务起始和结束,将流式的Binlog按事务标识GTID打包,以库(Cluster)有序投递事件
全流量消费
场景
业务冷启动,数据全量校准补偿
原理
全量流的消息会被打包成insert binlog事件投递给Resolver
回溯消费
场景
消费过程中因为消费失败、上线bug或其他原因,会存在重新消费旧数据的需求。
原理
Kafka的offset回溯实现的,支持时间戳回溯,精度在秒级