开篇
网上有很多篇粒子系统源码解析,但是只是简单的接口罗列,没有从最原理出发去讲清楚粒子系统的来龙去脉,我将从粒子系统的本质去讲清楚它的设计理念,当理解了它的理念以后,很多粒子遇到的问题就会迎刃解决了,这篇文章主讲粒子的实现和一些框架级的优化方式,其实有很多优化细节就不赘述
粒子系统的设计思想
在早期游戏发展的时候,有一些粒子效果是实现一些鼠标特效的,比如《刀剑封魔录》中滑动鼠标后,鼠标本身就会作为一个粒子发射器,在鼠标拖动后,会产生很多粒子并随着时间消亡,这就是最早的粒子系统模型

在早期的桌面系统中实现的粒子全是用cpu在屏幕上渲染的,如果需要世界中的3D粒子,则会将世界坐标转换为屏幕坐标,在屏幕指定位置渲染个粒子,而且这个粒子是每一帧去更新的
我给一个imgui类型渲染系统的粒子伪代码方便大家去理解,每一帧都去更新所有粒子的信息,当然现代游戏引擎粒子实现也类似于此
//定义粒子结构
struct particle
{
float x;
float y;
image img;
}
//定义粒子集合
vector<particle> particles
//设置粒子位置
void setparticlepositon(particle &p)
{
p.x++;
p.y++;
}
tick::update() //每一帧更行所有需要渲染的信息
{
for(auto i : particles)
{
setparticlepositon(i);//循环更新粒子位置
draw(i);//循环更新粒子绘制
}
}
更复杂的话就是定义每个粒子的周期,并定义粒子发射器,另外可以在setparticlepositon中设置更复杂的更新条件
class ParticleEmitter{
protected:
void Tick() {
Spawn(); //生成阶段:创建新粒子
UpdateAndRecycle(); //更新阶段:更新每个粒子的状态数据并回收已死亡的粒子
Render(); //渲染阶段:使用粒子渲染器将粒子效果渲染出来
}
private:
vector<Particle> Particles;
};万变不离其宗,都是源于这个思想
既然有大量相同的粒子,那么结合现代游戏引擎的特性,可以用到实例化(Instancing),将相同的mesh和材质用一套,大大减少了数据量,另外也可以用GPU粒子优化
使用几何着色器做优化
Nvidia在2006年的GeForce 8系列中出了DirectX 10.0,并推出了几何着色器
简单说,就是几何着色器可以把单个顶点扩充成多个顶点,如果粒子的mesh都一样的话,只需要从顶点着色器中传入的单个顶点和扩展规则,就可以生成想渲染的粒子mesh,而并不需要每回传入大量的顶点了
使用之前:

可见每个粒子需要传入五个位置然后生成五角星
使用之后:
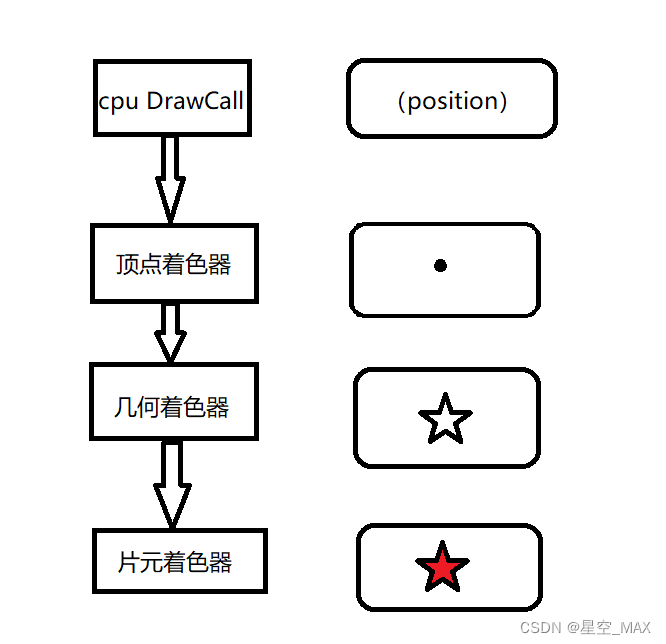
想渲染一个五角星只要传入一个顶点,就可以用几何着色器扩充为五角星,大大减少了draw所占的带宽
使用SMID粒子做的优化
关于smid的介绍我前面有篇文章可以看看,这里就不赘述它的原理了
(1条消息) 使用SIMD指令加速计算_星空_MAX的博客-CSDN博客
这种情况试用语cpu对大量粒子计算和更新的情况
unreal引擎的nigara和chaos就是用这种缓存友好的内存布局,和unity的ECS架构原理一样

写个大概的数据结构参考一下:
//定义粒子的组件集合
vector<particle> particlesx;
vector<particle> particlesy;
//设置粒子x位置
void setparticlepositonx(particlex &px)
{
px++;
}
//设置粒子y位置
void setparticlepositonx(particley &py)
{
py++;
}
//定义粒子和组件集合
class particle
{
vector<particle> *particlesx = particlesx;
vector<particle> *particlesx = particlesy;
}
//定义粒子集合
vector<particle> particles;
tick::update() //每一帧更行所有需要渲染的信息
{
for(auto i : particlesx)
{
setparticlepositonx(i);//循环更新粒子位置
}
for(auto i : particlesy)
{
setparticlepositony(i);//循环更新粒子位置
}
for(auto i : particles)
{
draw(i);//循环更新粒子绘制
}
}使用GPU粒子做的优化
CPU粒子设计上和我上一节提到的东西大同小异,不过原来的draw是CPU去绘制,现代会把这个内容送到GPU,会调用一次drawcall,但是粒子的消耗消耗会非常大,粒子渲染的数量非常有限
这时候能不能把把粒子更新的逻辑放在gpu里面呢,当然可以了
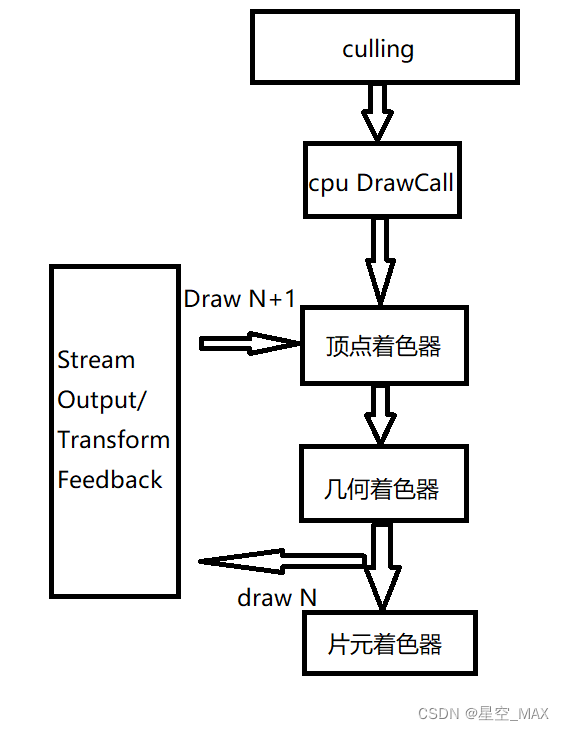
同样是DirectX 10.0引用了Stream Output的新特性,在OpenGL3.0中也加入了这种特性,不过在OpenGL称为Transform Feedback,在顶点着色器或者几何着色器之后,可以把顶点数据缓存到这个结构中,而这个结构在gpu中,这样每回就可以根据这个信息去更新顶点信息,重新传入顶点着色器中去做渲染
整体流程如下:
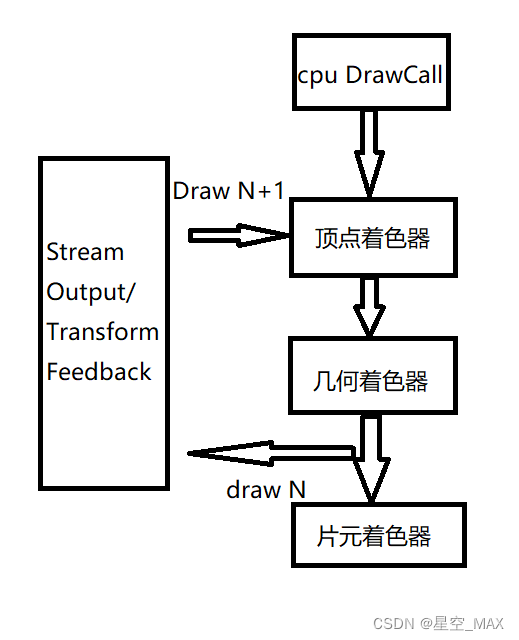
这时候就会发现GPU和cpu可以不进行数据传输了,粒子完成自我更新,大大减少了传输量和cpu的计算负担
带来的问题
如果用gpu粒子的话无法实时计算出剔除范围了,因为剔除步骤在传入顶点着色器之前,所以一开始就需要传入效果的bounds,并预估出粒子的最大范围,否则可能出现特效消失的问题
结尾
粒子系统还有其他很多部分,可做优化的部分非常多,我这里只介绍了一些粒子系统设计的基础思想,其他更全面的内容网上很多,就不赘述了