1. 函数功能
返回DataFrame中值与计算组成的Series
2. 函数语法
DataFrame.value_counts(subset=None, normalize=False, sort=True, ascending=False, dropna=True)
3.函数参数
| 参数 | 含义 |
|---|---|
| subset | 可选参数,标签或者标签列表 ,计算时要用的列 |
| normalize | 布尔值,默认取值False:返回频数,取值为True:返回占比 |
| sort | 布尔值,默认取值True,按照频数排序 |
| ascending | 布尔值,默认取值False:降序排列 |
| dropna | 布尔值,默认取值True:计数不包含空值 |
3.1 默认参数
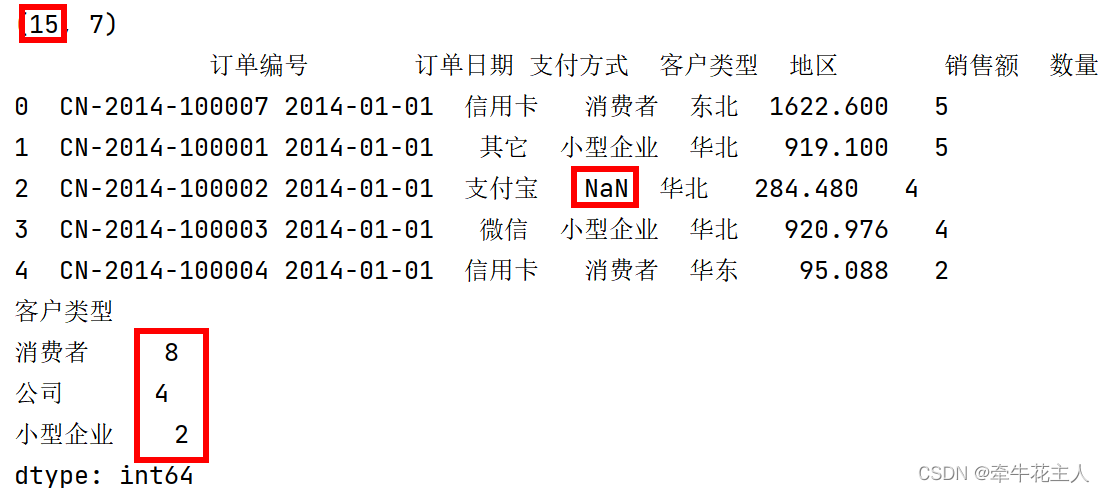
输出按照频数降序排序的结果,空值不被计算在内
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order.shape)
order.loc[2, '客户类型']=np.nan
print(order.head())
print(order.value_counts('客户类型'))
3.2 输出结果为占比:normalize=True
print(order.value_counts('客户类型', normalize=True))

3.3 不忽略空值
print(order.value_counts('客户类型', dropna=False))
print(order.value_counts('客户类型', normalize=True, dropna=False))