The Linux Kernel Module Programming Guide
- Peter Jay Salzman, Michael Burian, Ori Pomerantz, Bob Mottram, Jim Huang
- 译 断水客(WaterCutter)
- 源 LKMPG

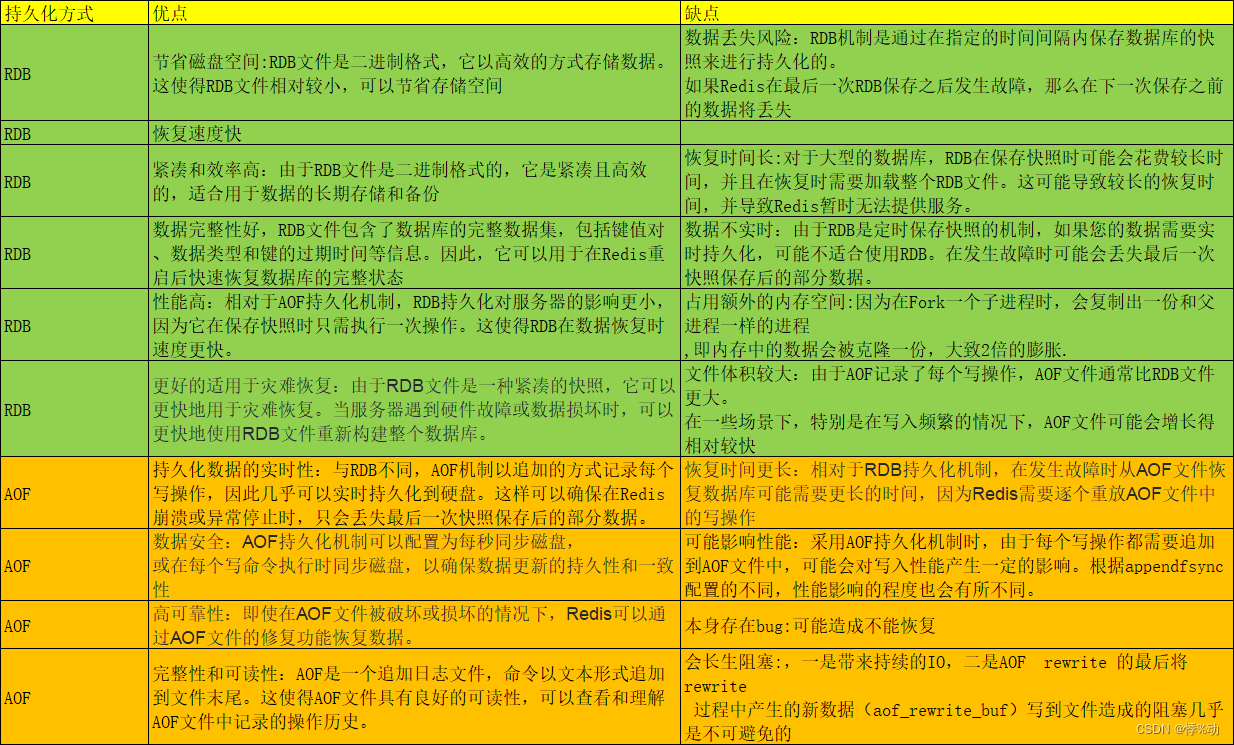
7 /proc 文件系统
Linux 中有一个额外的机制——/proc file system,用于支持内核和模块向进程(processes)发送信息。
这个机制最设计为访问进程信息,现在用于内核报告(used by every bit of the kernel which has something interesting to report),这些报告包括提供模块列表的 /proc/modules 文件、收集内存使用情况的 /proc/meminfo 文件。
/proc 文件系统的用法与设备驱动类似——创建一个包含 /proc 文件信息和多个句柄函数(handler function)的指针的结构体,使用 init_module 注册,使用 cleanup_module 注销。
常规的(normal)文件系统在磁盘(disk)上,而 /proc 在内存(memory)中,inode number 是一个指向文件在磁盘上的位置的指针。inode 中包含文件的权限、指向文件数据在磁盘中的位置的指针。
因为此类文件在被打开或者关闭时不会收到调用,开发者也就无处调用 try_module_get() 和 module_put() (见第 6 章对这两个函数的说明), 这也意味着文件打开时模块可以被移除。
下面是一个使用 /proc 文件的例程,包含初始化函数 init_module()、返回一个值和 buffer 的读取函数 procfile_read() 以及删除文件 /proc/helloworld 的函数 cleanup_module()。
模块被函数 proc_create() 加载时将创建文件 /proc/helloworld。类型为 struct proc_dir_entry 的返回值将被用于配置文件 /proc/helloworld ,返回值为 NULL 则意味着创建文件失败。
每当文件 proc/helloworld 被读取时,函数 procfile_read() 就会被调用。这个函数的第二个参数 buffer 和第四个参数 offset 十分重要。 buffer 的内容将被传递给读取该文件的应用程序(例如 cat 命令), offset 则标记文件当前的读取位置。如果该函数的返回值不为 NULL ,则将被不停地调用(called endlessly)。
$ cat /proc/helloworld
HelloWorld!
/*
* procfs1.c
*/
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/proc_fs.h>
#include <linux/uaccess.h>
#include <linux/version.h>
#if LINUX_VERSION_CODE >= KERNEL_VERSION(5, 6, 0)
#define HAVE_PROC_OPS
#endif
#define procfs_name "helloworld"
static struct proc_dir_entry *our_proc_file;
static ssize_t procfile_read(struct file *file_pointer, char __user *buffer,
size_t buffer_length, loff_t *offset)
{
char s[13] = "HelloWorld!\n";
int len = sizeof(s);
ssize_t ret = len;
if (*offset >= len || copy_to_user(buffer, s, len)) {
pr_info("copy_to_user failed\n");
ret = 0;
} else {
pr_info("procfile read %s\n", file_pointer->f_path.dentry->d_name.name);
*offset += len;
}
return ret;
}
#ifdef HAVE_PROC_OPS
static const struct proc_ops proc_file_fops = {
.proc_read = procfile_read,
};
#else
static const struct file_operations proc_file_fops = {
.read = procfile_read,
};
#endif
static int __init procfs1_init(void)
{
our_proc_file = proc_create(procfs_name, 0644, NULL, &proc_file_fops);
if (NULL == our_proc_file) {
proc_remove(our_proc_file);
pr_alert("Error:Could not initialize /proc/%s\n", procfs_name);
return -ENOMEM;
}
pr_info("/proc/%s created\n", procfs_name);
return 0;
}
static void __exit procfs1_exit(void)
{
proc_remove(our_proc_file);
pr_info("/proc/%s removed\n", procfs_name);
}
module_init(procfs1_init);
module_exit(procfs1_exit);
MODULE_LICENSE("GPL");
7.1 proc_ops 结构体
proc_ops 结构体定义在 5.6 及更高版本 Linux 内核的 include/linux/proc_fs.h 文件中。旧版本内核使用 file_operations /proc 文件系统的用户钩子(user hooks)。但它包含一些在 VFS 中不必要的成员,并且每次 VFS 扩展 file_operations 集时,/proc 代码都会变得臃肿。除此之外,proc_ops 结构不仅节省了空间,还节省了一些操作以提高其性能。例如,在 /proc 中永远不会消失的文件可以将proc_flag设置为PROC_ENTRY_PERMANENT,以在每个 open/read/close 序列中省去 2 个原子操作、1 个allocation、1 个free 。
7.2 读写 /proc 文件
7.1 节中展示了一个简单的 /proc 文件读取操作,这里我们尝试写入 /proc 文件。二者非常类似,但写 /proc 的数据来自于用户,所以咱需要用 copy_from_user 或者 get_user 把数据从用户空间(user space)导入(import)到内核空间(kernel space)。
The reason for copy_from_user or get_user is that Linux memory (on Intel architecture, it may be different under some other processors) is segmented. This means that a pointer, by itself, does not reference a unique location in memory, only a location in a memory segment, and you need to know which memory segment it is to be able to use it. There is one memory segment for the kernel, and one for each of the processes.
The only memory segment accessible to a process is its own, so when writing regular programs to run as processes, there is no need to worry about segments. When you write a kernel module, normally you want to access the kernel memory segment, which is handled automatically by the system. However, when the content of a memory buffer needs to be passed between the currently running process and the kernel, the kernel function receives a pointer to the memory buffer which is in the process segment. The put_user and get_user macros allow you to access that memory. These functions handle only one character, you can handle several characters with copy_to_user and copy_from_user . As the buffer (in read or write function) is in kernel space, for write function you need to import data because it comes from user space, but not for the read function because data is already in kernel space.
/*
* procfs2.c - create a "file" in /proc
*/
#include <linux/kernel.h> /* We're doing kernel work */
#include <linux/module.h> /* Specifically, a module */
#include <linux/proc_fs.h> /* Necessary because we use the proc fs */
#include <linux/uaccess.h> /* for copy_from_user */
#include <linux/version.h>
#if LINUX_VERSION_CODE >= KERNEL_VERSION(5, 6, 0)
#define HAVE_PROC_OPS
#endif
#define PROCFS_MAX_SIZE 1024
#define PROCFS_NAME "buffer1k"
/* This structure hold information about the /proc file */
static struct proc_dir_entry *our_proc_file;
/* The buffer used to store character for this module */
static char procfs_buffer[PROCFS_MAX_SIZE];
/* The size of the buffer */
static unsigned long procfs_buffer_size = 0;
/* This function is called then the /proc file is read */
static ssize_t procfile_read(struct file *file_pointer, char __user *buffer,
size_t buffer_length, loff_t *offset)
{
char s[13] = "HelloWorld!\n";
int len = sizeof(s);
ssize_t ret = len;
if (*offset >= len || copy_to_user(buffer, s, len)) {
pr_info("copy_to_user failed\n");
ret = 0;
} else {
pr_info("procfile read %s\n", file_pointer->f_path.dentry->d_name.name);
*offset += len;
}
return ret;
}
/* This function is called with the /proc file is written. */
static ssize_t procfile_write(struct file *file, const char __user *buff,
size_t len, loff_t *off)
{
procfs_buffer_size = len;
if (procfs_buffer_size > PROCFS_MAX_SIZE)
procfs_buffer_size = PROCFS_MAX_SIZE;
if (copy_from_user(procfs_buffer, buff, procfs_buffer_size))
return -EFAULT;
procfs_buffer[procfs_buffer_size & (PROCFS_MAX_SIZE - 1)] = '\0';
*off += procfs_buffer_size;
pr_info("procfile write %s\n", procfs_buffer);
return procfs_buffer_size;
}
#ifdef HAVE_PROC_OPS
static const struct proc_ops proc_file_fops = {
.proc_read = procfile_read,
.proc_write = procfile_write,
};
#else
static const struct file_operations proc_file_fops = {
.read = procfile_read,
.write = procfile_write,
};
#endif
static int __init procfs2_init(void)
{
our_proc_file = proc_create(PROCFS_NAME, 0644, NULL, &proc_file_fops);
if (NULL == our_proc_file) {
proc_remove(our_proc_file);
pr_alert("Error:Could not initialize /proc/%s\n", PROCFS_NAME);
return -ENOMEM;
}
pr_info("/proc/%s created\n", PROCFS_NAME);
return 0;
}
static void __exit procfs2_exit(void)
{
proc_remove(our_proc_file);
pr_info("/proc/%s removed\n", PROCFS_NAME);
}
module_init(procfs2_init);
module_exit(procfs2_exit);
MODULE_LICENSE("GPL");
7.3 用标准文件系统管理 /proc 文件
咱已知晓如何使用 /proc 接口读写 /proc文件,但是否有可能使用 inode 管理 /proc 文件呢? 问题聚焦于一些高级功能(advance function)——譬如权限管理。
Linux 中有一套标准的文件注册机制,每个文件系统都有处理 inode 和文件操作的函数,也有一些内含这些函数的指针的结构体—— struct inode_operations, 这个结构体中包含一个指向 struct proc_ops 的指针。
文件操作(file operations)和 inode 操作的(inode operations)区别在于,前者处理文件本身,而后者处理文件索引相关的事情——比如创建文件链接(create links to it)。
这里要提到另一个有趣的东西—— module_permission 函数。这个函数在进程尝试操作 /proc 文件时被调用,决定是否允许相应的操作。目前允许与否仅取决于当前用户的 uid, 但实际可以取决于其他进程对该文件的操作、日期、或者收到的信息等我们指定的任意判据。
需要注意到内核中的读写是方向颠倒的,使用 read 函数写,用 write 函数读。因为读写是从用户的视角描述的,当用户需要从内核读取数据时,内核应当输出对应的数据。
It is important to note that the standard roles of read and write are reversed in the kernel. Read functions are used for output, whereas write functions are used for input. The reason for that is that read and write refer to the user’s point of view — if a process reads something from the kernel, then the kernel needs to output it, and if a process writes something to the kernel, then the kernel receives it as input.
/*
* procfs3.c
*/
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/proc_fs.h>
#include <linux/sched.h>
#include <linux/uaccess.h>
#include <linux/version.h>
#if LINUX_VERSION_CODE >= KERNEL_VERSION(5, 10, 0)
#include <linux/minmax.h>
#endif
#if LINUX_VERSION_CODE >= KERNEL_VERSION(5, 6, 0)
#define HAVE_PROC_OPS
#endif
#define PROCFS_MAX_SIZE 2048UL
#define PROCFS_ENTRY_FILENAME "buffer2k"
static struct proc_dir_entry *our_proc_file;
static char procfs_buffer[PROCFS_MAX_SIZE];
static unsigned long procfs_buffer_size = 0;
static ssize_t procfs_read(struct file *filp, char __user *buffer,
size_t length, loff_t *offset)
{
if (*offset || procfs_buffer_size == 0) {
pr_debug("procfs_read: END\n");
*offset = 0;
return 0;
}
procfs_buffer_size = min(procfs_buffer_size, length);
if (copy_to_user(buffer, procfs_buffer, procfs_buffer_size))
return -EFAULT;
*offset += procfs_buffer_size;
pr_debug("procfs_read: read %lu bytes\n", procfs_buffer_size);
return procfs_buffer_size;
}
static ssize_t procfs_write(struct file *file, const char __user *buffer,
size_t len, loff_t *off)
{
procfs_buffer_size = min(PROCFS_MAX_SIZE, len);
if (copy_from_user(procfs_buffer, buffer, procfs_buffer_size))
return -EFAULT;
*off += procfs_buffer_size;
pr_debug("procfs_write: write %lu bytes\n", procfs_buffer_size);
return procfs_buffer_size;
}
static int procfs_open(struct inode *inode, struct file *file)
{
try_module_get(THIS_MODULE);
return 0;
}
static int procfs_close(struct inode *inode, struct file *file)
{
module_put(THIS_MODULE);
return 0;
}
#ifdef HAVE_PROC_OPS
static struct proc_ops file_ops_4_our_proc_file = {
.proc_read = procfs_read,
.proc_write = procfs_write,
.proc_open = procfs_open,
.proc_release = procfs_close,
};
#else
static const struct file_operations file_ops_4_our_proc_file = {
.read = procfs_read,
.write = procfs_write,
.open = procfs_open,
.release = procfs_close,
};
#endif
static int __init procfs3_init(void)
{
our_proc_file = proc_create(PROCFS_ENTRY_FILENAME, 0644, NULL,
&file_ops_4_our_proc_file);
if (our_proc_file == NULL) {
remove_proc_entry(PROCFS_ENTRY_FILENAME, NULL);
pr_debug("Error: Could not initialize /proc/%s\n",
PROCFS_ENTRY_FILENAME);
return -ENOMEM;
}
proc_set_size(our_proc_file, 80);
proc_set_user(our_proc_file, GLOBAL_ROOT_UID, GLOBAL_ROOT_GID);
pr_debug("/proc/%s created\n", PROCFS_ENTRY_FILENAME);
return 0;
}
static void __exit procfs3_exit(void)
{
remove_proc_entry(PROCFS_ENTRY_FILENAME, NULL);
pr_debug("/proc/%s removed\n", PROCFS_ENTRY_FILENAME);
}
module_init(procfs3_init);
module_exit(procfs3_exit);
MODULE_LICENSE("GPL");
仍觉得例程不够丰富?有传言称procfs即将被淘汰,建议考虑使用sysfs代替。如果想自己记录一些与内核相关的内容,再考虑使用这种机制。
Consider using this mechanism, in case you want to document something kernel related yourself.
7.4 使用 seq_file 管理 /proc 文件
如你所见,/proc 文件可能有些复杂,故而有一组名为 seq_file 有助于格式化输出的 API, 这组 API 基于一个由 start()、 next()、 stop() 等 3 个函数组成的操作序列(sequence)。当用户读取 /proc 文件时, seq_file 会启动这个操作序列,其内容如下:
- 调用函数
start()。 - 如果
start()返回值非 NULL,调用函数next()。这个函数是一个迭代器(iterator),用于遍历数据(go through all the data)。每次next()被调用时,也调用函数show(),把用户要读取的数据写到缓冲区。 next()返回值不为 NULL,重复调用next()。next()返回值为 NULL,调用函数stop()。
注意:调用函数 stop() 之后又会调用函数 start(),直到函数 start() 返回值为 NULL
sqe_file 为 proc_ops 提供了 seq_read、seq_lseek 等基本函数,但不提供写 /proc 文件的函数。下面是使用例程:
/*
* procfs4.c - create a "file" in /proc
* This program uses the seq_file library to manage the /proc file.
*/
#include <linux/kernel.h> /* We are doing kernel work */
#include <linux/module.h> /* Specifically, a module */
#include <linux/proc_fs.h> /* Necessary because we use proc fs */
#include <linux/seq_file.h> /* for seq_file */
#include <linux/version.h>
#if LINUX_VERSION_CODE >= KERNEL_VERSION(5, 6, 0)
#define HAVE_PROC_OPS
#endif
#define PROC_NAME "iter"
/* This function is called at the beginning of a sequence.
* ie, when:
* - the /proc file is read (first time)
* - after the function stop (end of sequence)
*/
static void *my_seq_start(struct seq_file *s, loff_t *pos)
{
static unsigned long counter = 0;
/* beginning a new sequence? */
if (*pos == 0) {
/* yes => return a non null value to begin the sequence */
return &counter;
}
/* no => it is the end of the sequence, return end to stop reading */
*pos = 0;
return NULL;
}
/* This function is called after the beginning of a sequence.
* It is called untill the return is NULL (this ends the sequence).
*/
static void *my_seq_next(struct seq_file *s, void *v, loff_t *pos)
{
unsigned long *tmp_v = (unsigned long *)v;
(*tmp_v)++;
(*pos)++;
return NULL;
}
/* This function is called at the end of a sequence. */
static void my_seq_stop(struct seq_file *s, void *v)
{
/* nothing to do, we use a static value in start() */
}
/* This function is called for each "step" of a sequence. */
static int my_seq_show(struct seq_file *s, void *v)
{
loff_t *spos = (loff_t *)v;
seq_printf(s, "%Ld\n", *spos);
return 0;
}
/* This structure gather "function" to manage the sequence */
static struct seq_operations my_seq_ops = {
.start = my_seq_start,
.next = my_seq_next,
.stop = my_seq_stop,
.show = my_seq_show,
};
/* This function is called when the /proc file is open. */
static int my_open(struct inode *inode, struct file *file)
{
return seq_open(file, &my_seq_ops);
};
/* This structure gather "function" that manage the /proc file */
#ifdef HAVE_PROC_OPS
static const struct proc_ops my_file_ops = {
.proc_open = my_open,
.proc_read = seq_read,
.proc_lseek = seq_lseek,
.proc_release = seq_release,
};
#else
static const struct file_operations my_file_ops = {
.open = my_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release,
};
#endif
static int __init procfs4_init(void)
{
struct proc_dir_entry *entry;
entry = proc_create(PROC_NAME, 0, NULL, &my_file_ops);
if (entry == NULL) {
remove_proc_entry(PROC_NAME, NULL);
pr_debug("Error: Could not initialize /proc/%s\n", PROC_NAME);
return -ENOMEM;
}
return 0;
}
static void __exit procfs4_exit(void)
{
remove_proc_entry(PROC_NAME, NULL);
pr_debug("/proc/%s removed\n", PROC_NAME);
}
module_init(procfs4_init);
module_exit(procfs4_exit);
MODULE_LICENSE("GPL");
通过下面几个页面获取更多信息:
-
https://lwn.net/Articles/22355/
-
https://kernelnewbies.org/Documents/SeqFileHowTo
-
fs/seq_file.c