1总结
2:详解
运行模式 :: ShardingSphere
用户手册,开发手册。这俩比较重要
spring.shardingsphere.mode.type 默认内存模式
3官网案例
不同的依赖坐标,配置方式不一样。按照官网的配置来一步一步配置。

4 整合springboot方式
行表达式 :: ShardingSphere
Spring Boot Starter :: ShardingSphere
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>${shardingsphere.version}</version>
</dependency>
只有读写分离功能
1查询只会查询从库,并且是从库轮训查询
2:插入数据只会插入主库
application.properties
server.port=8080
spring.application.name=sharging-jdbc
spring.profiles.active=dev
# 配置的属性后面不要带空格 出问题
#内存模式
spring.shardingsphere.mode.type=Memory
# 真实数据源名称,多个数据源用逗号区分
spring.shardingsphere.datasource.names=master,slave1,slave2
#配置第一个数据源
spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://192.168.135.128:3306/db1?useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=root
#配置第二个数据源
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://192.168.135.4:3306/db1?useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.slave1.username=root1
spring.shardingsphere.datasource.slave1.password=root1
#配置第三个数据源
spring.shardingsphere.datasource.slave2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave2.jdbc-url=jdbc:mysql://192.168.135.128:3306/db2?useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.slave2.username=root
spring.shardingsphere.datasource.slave2.password=root
###################
#读写分离类型 ,如:Static(静态配置 配置文件方式应该) Dynamic(动态配置 代码方式应该)
# myspring 自己定义的 :类似于 mycat逻辑库名
spring.shardingsphere.rules.readwrite-splitting.data-sources.myspring.type=Static
# 写数据源名称 来源 -> spring.shardingsphere.datasource.names
spring.shardingsphere.rules.readwrite-splitting.data-sources.myspring.props.write-data-source-name=master
# 读数据名称 多个从库用逗号隔开 来源 -> spring.shardingsphere.datasource.names
spring.shardingsphere.rules.readwrite-splitting.data-sources.myspring.props.read-data-source-names=slave1,slave2
#负载均衡算法名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myspring.load-balancer-name=my_round
#负载均衡算法 类型 ROUND_ROBIN(轮询算法) RANDOM(随机访问算法) WEIGHT(权重访问算法)
spring.shardingsphere.rules.readwrite-splitting.load-balancers.my_round.type=ROUND_ROBIN
###################
# 分表策略,同分库策略
#spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=master.t_order
#spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=master$->{0..1}.t_order_$->{0..1}
# 分片列名称
#spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id
# 分片算法名称
#spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=HASH_MOD
#打印sql
spring.shardingsphere.props.sql-show=true
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis.configuration.map-underscore-to-camel-case=true
mybatis.configuration.default-fetch-size=100
mybatis.configuration.default-statement-timeout=300
mybatis.mapper-locations=classpath:mapper/*.xmlapplication.yml 方式配置了好久不好使
1:不做任何配置的表的增删改查 会走第一个数据源
2:增删改查 t_order 均来源于 db2 这个数据源:
server.port=8080
spring.application.name=sharging-jdbc
spring.profiles.active=dev
# 配置的属性后面不要带空格 出问题
#内存模式
spring.shardingsphere.mode.type=Memory
# 真实数据源名称,多个数据源用逗号区分
spring.shardingsphere.datasource.names=db1,db2
#配置第一个数据源
spring.shardingsphere.datasource.db1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.jdbc-url=jdbc:mysql://localhost:3306/db1
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=root
#配置第二个数据源
spring.shardingsphere.datasource.db2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db2.jdbc-url=jdbc:mysql://localhost:3306/db2
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=root
#################### 标准分片表配置
# 垂直分库 指定哪个表的数据只来自哪个库
#spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=
# 只要对t_order的任何操作都只会到 db2节点里面去(注意:读写分离去除)
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=db2.t_order
#打印sql
spring.shardingsphere.props.sql-show=true
#mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis.configuration.map-underscore-to-camel-case=true
mybatis.configuration.default-fetch-size=100
mybatis.configuration.default-statement-timeout=300
mybatis.mapper-locations=classpath:mapper/*.xml配置 多数据源但是每个数据源不在分表 (db0,db1 都有t_order,每个库不会在将 t_order 分表操作 )
分片算法 :: ShardingSphere
server.port=8080
spring.application.name=sharging-jdbc
spring.profiles.active=dev
# 配置的属性后面不要带空格 出问题
#内存模式
spring.shardingsphere.mode.type=Memory
# 真实数据源名称,多个数据源用逗号区分
spring.shardingsphere.datasource.names=db0,db1
#配置第一个数据源
spring.shardingsphere.datasource.db0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.jdbc-url=jdbc:mysql://localhost:3306/db1
spring.shardingsphere.datasource.db0.username=root
spring.shardingsphere.datasource.db0.password=root
#配置第二个数据源
spring.shardingsphere.datasource.db1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.jdbc-url=jdbc:mysql://localhost:3306/db2
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=root
#################### 标准分片表配置
# 垂直分库 指定哪个表的数据只来自哪个库
#spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=
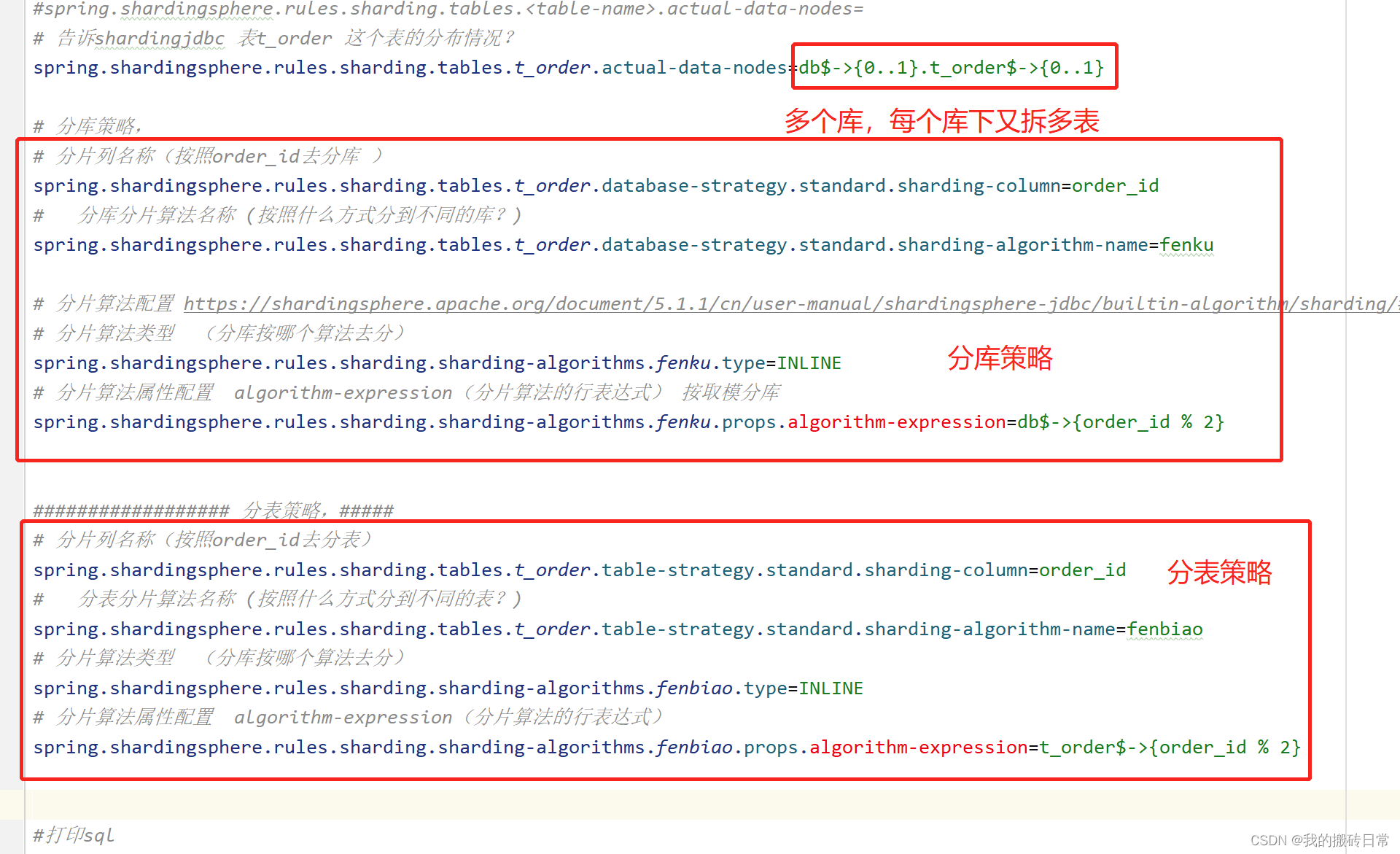
# 告诉shardingjdbc 表t_order 这个表的分布情况?
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=db$->{0..1}.t_order0
# 分库策略,
# 分片列名称(按照order_id去分库 )
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id
# 分库分片算法名称 (按照什么方式分到不同的库?)
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=fenku
# 分片算法配置
#https://shardingsphere.apache.org/document/5.1.1/cn/user-manual/shardingsphere-jdbc/builtin-algorithm/sharding/#%E5%8F%96%E6%A8%A1%E5%88%86%E7%89%87%E7%AE%97%E6%B3%95
# 分片算法类型 (分库按哪个算法去分)
#spring.shardingsphere.rules.sharding.sharding-algorithms.fenku.type=INLINE
# 分片算法属性配置 algorithm-expression(分片算法的行表达式) 按取模分库
#spring.shardingsphere.rules.sharding.sharding-algorithms.fenku.props.algorithm-expression=db$->{order_id % 2}
# 分片算法类型 (分库按哪个算法去分)
spring.shardingsphere.rules.sharding.sharding-algorithms.fenku.type=MOD
# 分片算法属性配置 algorithm-expression(分片算法的行表达式) 按取模分库
spring.shardingsphere.rules.sharding.sharding-algorithms.fenku.props.sharding-count=2
# 分片算法类型 (分库按哪个算法去分) hash方式
#spring.shardingsphere.rules.sharding.sharding-algorithms.fenku.type=HASH_MOD
# 分片算法属性配置 algorithm-expression(分片算法的行表达式) 按取模分库
#spring.shardingsphere.rules.sharding.sharding-algorithms.fenku.props.sharding-count=2
#打印sql
spring.shardingsphere.props.sql-show=true
#mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis.configuration.map-underscore-to-camel-case=true
mybatis.configuration.default-fetch-size=100
mybatis.configuration.default-statement-timeout=300
mybatis.mapper-locations=classpath:mapper/*.xml分库+分表 (db0,db1 俩个库中,每个库还要分为 t_order0,t_order1)
server.port=8080
spring.application.name=sharging-jdbc
spring.profiles.active=dev
# 配置的属性后面不要带空格 出问题
#内存模式
spring.shardingsphere.mode.type=Memory
# 真实数据源名称,多个数据源用逗号区分
spring.shardingsphere.datasource.names=db0,db1
#配置第一个数据源
spring.shardingsphere.datasource.db0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.jdbc-url=jdbc:mysql://localhost:3306/db1
spring.shardingsphere.datasource.db0.username=root
spring.shardingsphere.datasource.db0.password=root
#配置第二个数据源
spring.shardingsphere.datasource.db1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.jdbc-url=jdbc:mysql://localhost:3306/db2
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=root
#################### 标准分片表配置
# 垂直分库 指定哪个表的数据只来自哪个库
#spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=
# 告诉shardingjdbc 表t_order 这个表的分布情况?
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=db$->{0..1}.t_order$->{0..1}
# 分库策略,
# 分片列名称(按照order_id去分库 )
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id
# 分库分片算法名称 (按照什么方式分到不同的库?)
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=fenku
# 分片算法配置 https://shardingsphere.apache.org/document/5.1.1/cn/user-manual/shardingsphere-jdbc/builtin-algorithm/sharding/#%E5%8F%96%E6%A8%A1%E5%88%86%E7%89%87%E7%AE%97%E6%B3%95
# 分片算法类型 (分库按哪个算法去分)
spring.shardingsphere.rules.sharding.sharding-algorithms.fenku.type=INLINE
# 分片算法属性配置 algorithm-expression(分片算法的行表达式) 按取模分库
spring.shardingsphere.rules.sharding.sharding-algorithms.fenku.props.algorithm-expression=db$->{order_id % 2}
################## 分表策略,#####
# 分片列名称(按照order_id去分表)
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
# 分表分片算法名称 (按照什么方式分到不同的表?)
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=fenbiao
# 分片算法类型 (分库按哪个算法去分)
spring.shardingsphere.rules.sharding.sharding-algorithms.fenbiao.type=INLINE
# 分片算法属性配置 algorithm-expression(分片算法的行表达式)
spring.shardingsphere.rules.sharding.sharding-algorithms.fenbiao.props.algorithm-expression=t_order$->{order_id % 2}
#打印sql
spring.shardingsphere.props.sql-show=true
#mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis.configuration.map-underscore-to-camel-case=true
mybatis.configuration.default-fetch-size=100
mybatis.configuration.default-statement-timeout=300
mybatis.mapper-locations=classpath:mapper/*.xml配置使用雪花算法
自己实现雪花算法时要使用静态方式调用获取id,new对象方式获取id 老是主键冲突?不知道为啥?
t_order 表插入使用雪花算法
# 分布式序列策略配置
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=order_id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=xuehua
# 分布式序列算法配置
# 分布式序列算法类型
#spring.shardingsphere.rules.sharding.key-generators.<key-generate-algorithm-name>.type=
spring.shardingsphere.rules.sharding.key-generators.xuehua.type=SNOWFLAKE字典表 (广播表)
每个库都是一模一样的数据 ,插入的时候,所有的库都要插一份
server.port=8080
spring.application.name=sharging-jdbc
spring.profiles.active=dev
# 配置的属性后面不要带空格 出问题
#内存模式
spring.shardingsphere.mode.type=Memory
# 真实数据源名称,多个数据源用逗号区分
spring.shardingsphere.datasource.names=db0,db1
#配置第一个数据源
spring.shardingsphere.datasource.db0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.jdbc-url=jdbc:mysql://localhost:3306/db1
spring.shardingsphere.datasource.db0.username=root
spring.shardingsphere.datasource.db0.password=root
#配置第二个数据源
spring.shardingsphere.datasource.db1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.jdbc-url=jdbc:mysql://localhost:3306/db2
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=root
#################### 标准分片表配置
# 垂直分库 指定哪个表的数据只来自哪个库
#spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=
# 告诉shardingjdbc 表t_order 这个表的分布情况?
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=db$->{0..1}.t_order$->{0..1}
###############分库策略########
# 分库策略,
# 分片列名称(按照order_id去分库 )
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id
# 分库分片算法名称 (按照什么方式分到不同的库?)
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=fenku
# 分片算法配置 https://shardingsphere.apache.org/document/5.1.1/cn/user-manual/shardingsphere-jdbc/builtin-algorithm/sharding/#%E5%8F%96%E6%A8%A1%E5%88%86%E7%89%87%E7%AE%97%E6%B3%95
# 分片算法类型 (分库按哪个算法去分)
spring.shardingsphere.rules.sharding.sharding-algorithms.fenku.type=INLINE
# 分片算法属性配置 algorithm-expression(分片算法的行表达式) 按取模分库
spring.shardingsphere.rules.sharding.sharding-algorithms.fenku.props.algorithm-expression=db$->{order_id % 2}
###############分库策略########
################## 分表策略,开始#####
# 分片列名称(按照order_id去分表)
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
# 分表分片算法名称 (按照什么方式分到不同的表?)
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=fenbiao
# 分片算法类型 (分库按哪个算法去分)
spring.shardingsphere.rules.sharding.sharding-algorithms.fenbiao.type=INLINE
# 分片算法属性配置 algorithm-expression(分片算法的行表达式)
spring.shardingsphere.rules.sharding.sharding-algorithms.fenbiao.props.algorithm-expression=t_order$->{order_id % 2}
##################分表策略,结束#####
###################分布式主键配置开始##
# 分布式序列策略配置
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=order_id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=xuehua
# 分布式序列算法配置
# 分布式序列算法类型
#spring.shardingsphere.rules.sharding.key-generators.<key-generate-algorithm-name>.type=
spring.shardingsphere.rules.sharding.key-generators.xuehua.type=SNOWFLAKE
###################分布式主键配置结束##
######################### 字典表配置开始############
#告诉分布情况 分库没分表所以只配置分库规则即可
spring.shardingsphere.rules.sharding.tables.t_dict.actual-data-nodes=db$->{0..1}.t_dict
# 广播表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[0]=t_dict
#########################字典表配置结束#######################################
#打印sql
spring.shardingsphere.props.sql-show=true
#mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis.configuration.map-underscore-to-camel-case=true
mybatis.configuration.default-fetch-size=100
mybatis.configuration.default-statement-timeout=300
mybatis.mapper-locations=classpath:mapper/*.xml配置总结:
1:如下图:db1,db2 中都只有t_order0这个表,只需要配置分库规则即可
2:如下图:db1,db2中 都包含 t_order0,t_order1 这个俩表。必须配置完分库,还必须配置分表规则。这样才能让数据具体落地到哪个表里。

数据库分库分表(二)shardingjdbc配置文件_w_t_y_y的博客-CSDN博客
分库分表ShardingSphere,一文带你搞透(建议收藏)_china_coding的博客-CSDN博客





![[附源码]计算机毕业设计的4s店车辆管理系统Springboot程序](https://img-blog.csdnimg.cn/0832d5be63614c3ca2e2458be749311b.png)

![[Go] go基础4](https://img-blog.csdnimg.cn/16d706db4f664c77a1ab4fd497f8e2dc.png)