目录
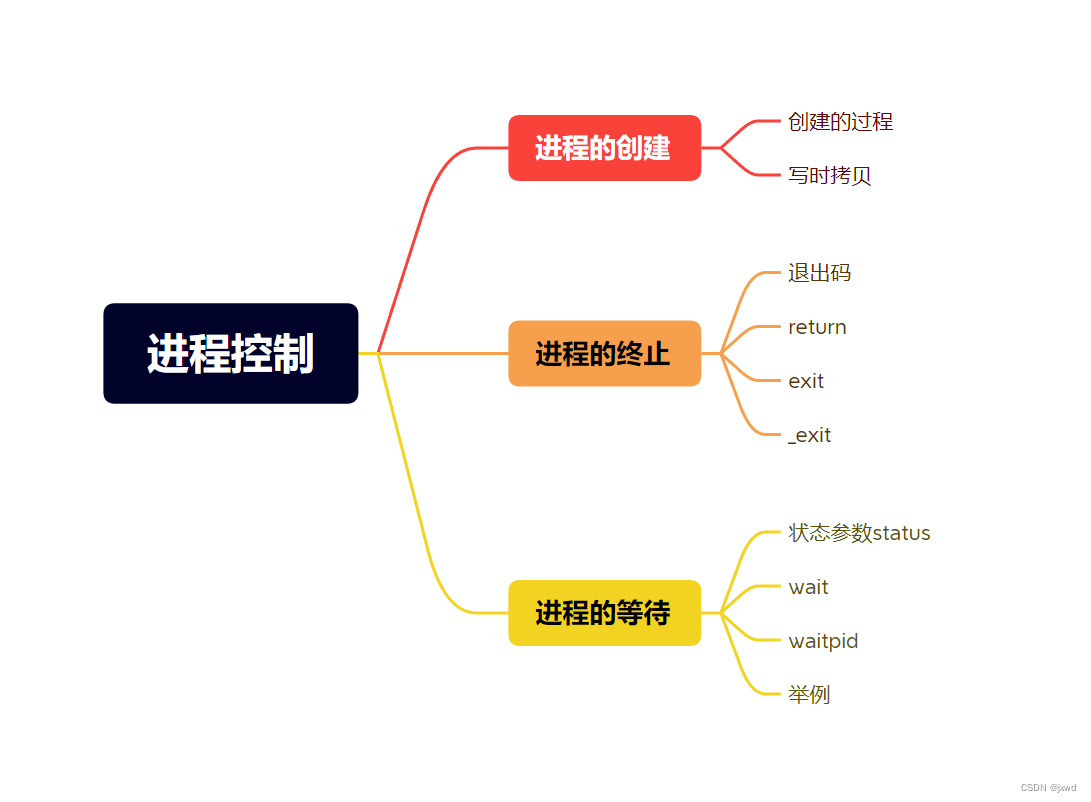
进程的创建
写时拷贝
进程的终止
进程的等待
状态参数status
wait函数和waitpid函数
我们本节内容,主要来讲述进程控制有关的内容。
同样,我们会用通俗易懂、不同于教科书的讲授思路,来为大家讲解。
同时,本节内容板块清晰简明,在最终同学们的思维导图可以做起来呦~~~
(同时需要说明一下,我们本节注重的是系统编程方面,而不是完完全全地侧重于系统理论知识呦,如果想要深入学习进程的知识,可以参考以后的《操作系统》篇章,敬请期待哈~)
本节导图:
进程的创建
进程是如何创建出来的?
实际上,进程的创建理论上都是由在另一个进程里创建出来的。
就好像是细胞分裂一样,子细胞怎么来的?由父代细胞分裂而来的。那子进程是怎么来的?同理,是由父进程创建的。最初的那个细胞叫做受精卵(就是老祖宗),那最初的那个进程是什么呢?通常是一个系统进程(通常为1号进程)(用户没有控制的权限),它可以理解为是你在系统开机的时候启动的进程。之后系统上所有的进程,都是由父代而来。
那,我们自己如果想写一个程序来创建和控制进程,我们应该怎么样来去做呢?
答案就是用Fork函数
我们通常用fork函数来创建新的进程。
//函数解释 fork
pid_t fork(void ); 具体的函数说明(在Centos 7中通过在命令行中: man fork得到 ):
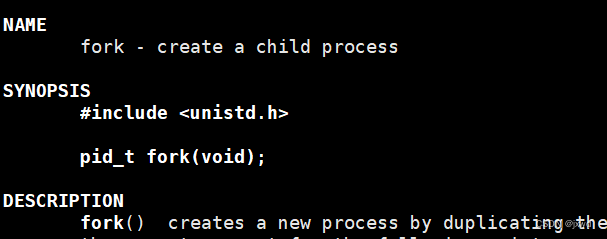
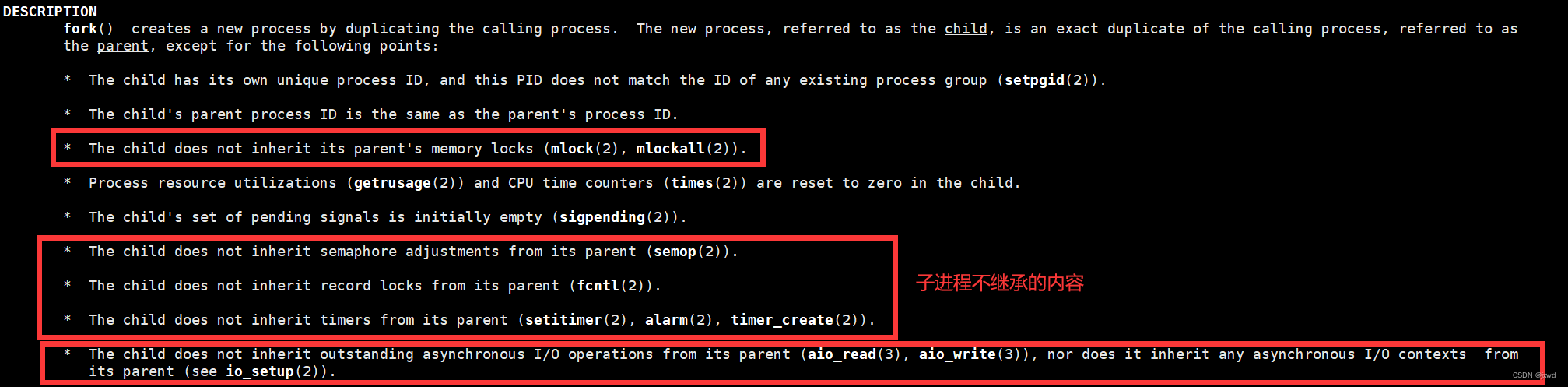
同时,从上述的手册中可以看出,在程序调用fork的时候,是以父进程为模板的。准确来说,就是复制一份父进程的除了信号、锁等的其他一切东西。比较常见的,有父进程的虚拟进程地址空间、PC(程序计数器)、已经PCB里其他的有关数据结构和数据等。
用比较标准的话来说,就是以父进程的数据结构和相关数据为模板,拷贝一份新的进程。
还需要注意的是,该函数是有两个返回值的。
一个是父进程的返回值,一个是子进程的返回值。
在父进程中,返回的是子进程的ID,在子进程中返回0。如果出错,会返回-1。
为何会有两个返回值?这是因为该函数是用来创建进程的,而在进程创建之前,我们的子进程就已经创建好了。而子进程和父进程的PC(即程序计数器)拥有相同的值,即它们从相同的位置开始执行。所以在返回之前,父子进程同时在执行、调用fork函数。所以,在fork函数返回的时候,也是会有两个返回值的。
从微观角度来解释的话或许更加容易理解上述过程:从微观来说,就是从程序运行的角度来说,可以分为这样几个过程:
1、分配新的内存块和内核数据结构给子进程
2、将父进程部分数据结构内容拷贝至子进程
3、添加子进程到系统进程列表当中
4、fork返回,开始调度器调度
所以说,还是那句话,创建了一个子进程,就是复制了一份和父进程相同的(部分不继承的东西除外)数据结构和数据。
对于虚拟地址空间和物理结构的映射的关系,就涉及到了另一个概念:写时拷贝。
我们来说说:
写时拷贝
父子进程在一开始拷贝过后,会有两个虚拟进程地址空间(父子进程各一个),两个页表。但是它们在物理内存中所映射的区域是同一块(如下图所示)。
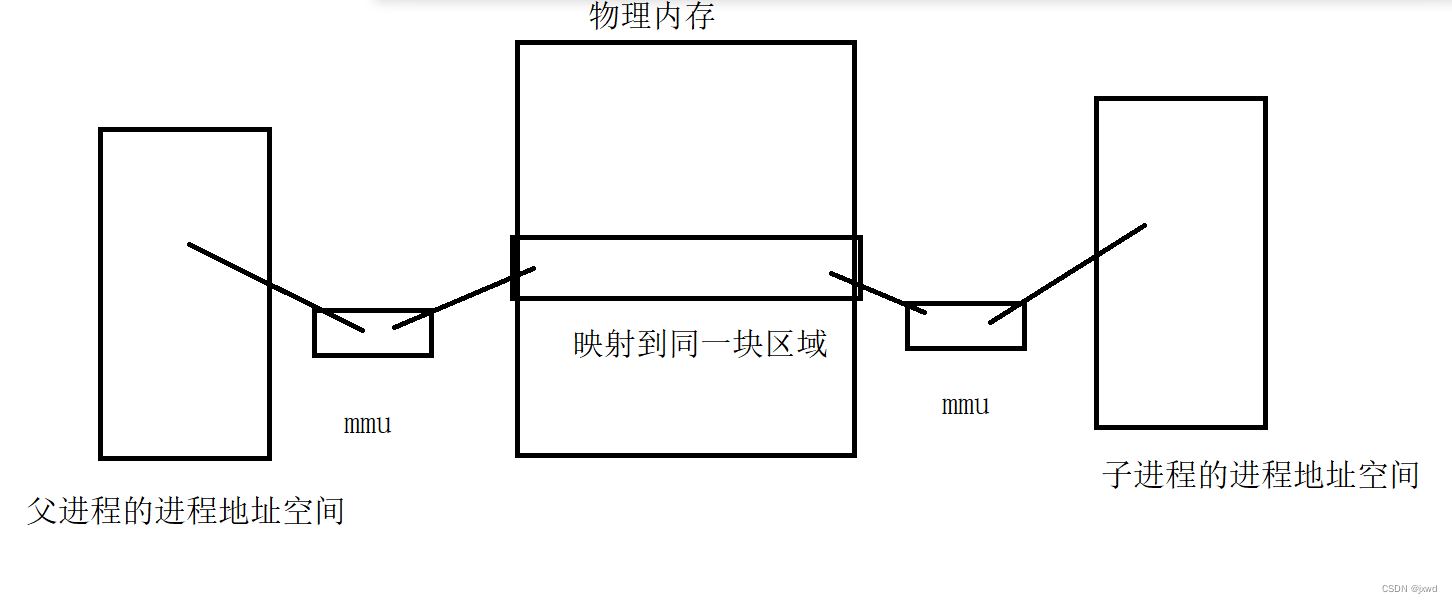
父子进程如果对这块区域的内容只是读取,而不进行写入(或者说是更改)的操作话,父子进程将始终映射到同一块物理空间上去(即上图所示)
但是如果父进程或者子进程对这一块区域的内容进行了写入更改操作的话,那么操作系统就会对写入更改的数据进行写时拷贝。即将会在其他的地方重新开辟一块空间,将现有的数据拷贝过去,并对新开辟的空间进行写入操作,同时,页表的映射关系也会随之改变(即映射到新的物理地址上去)(如下图所示):
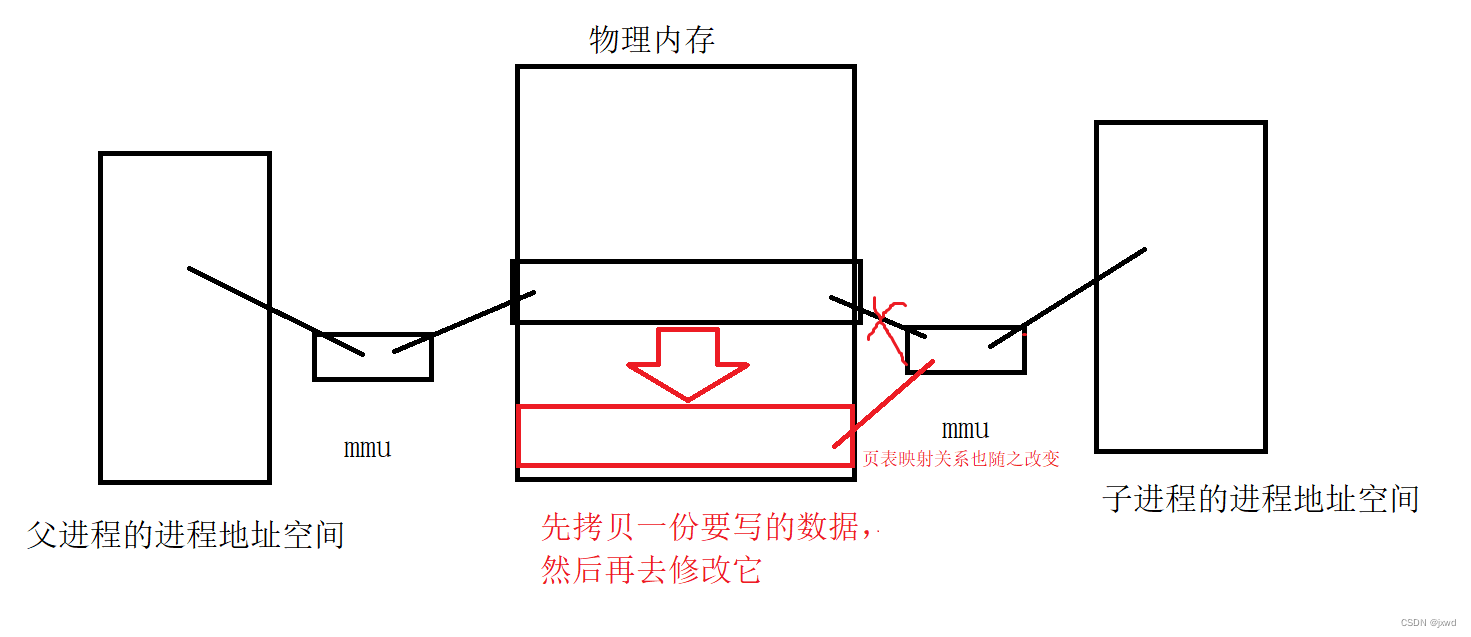
看到这里,想必你应该对写时拷贝的特点有了了解了。
那么,我们来稍稍总结下它有什么样的特点,以及我们为什么需要写时拷贝?
首先说后面的问题:我们为什么需要写时拷贝?
1、保证父子进程的 “ 独立性 ”。不要存在一种bug的情况:父进程要写个内容,把子进程的数据也给改了。进程之间是有着严格的独立性的。
2、如果是在创建进程的时候直接拷贝,而不是在需要写的时候才进行拷贝,有可能会浪费系统资源。因为不一定是所有的数据都是需要写或者更改的。而不过你不需要写或者不需要更改,那你拷贝就没有意义了。父子进程在物理空间上完全可以共用一块空间。
3、由(2)引出,如果不是在需要写的时候再进行拷贝,那么fork的效率将会变低。因为一次fork有可能在物理空间上也需要拷贝大量的数据。这样的话,就更有可能会导致fork失败。
那再来稍稍总结一下写时拷贝的特点及意义吧:
1、写才拷贝,不写不拷贝。
2、保证了父子进程的独立性。
3、提高的效率,减少了不必要的系统资源的浪费。
进程的终止
在这一部分,退出码是什么、有什么用。以及我们需要区分一下:exit、return和_exit三者之间的区别。
我们先说退出码:
退出码,就是进程终止的状态码。状态码是几,一般是人为规定的。比如我们一般规定退出码为0的时候,表示正常退出。
我们在main函数里的return 0,这里的0,就是退出码。因为在用户的角度来说,执行完return 0之后,该进程就结束了。
我们的程序,执行的结果按照是否出错(指能否运行起来)、是否正确来划分一般会有三种情况:
1、程序未出错,结果正确;
2、程序未出错,结果不正确;
3、程序出错,结果不正确。
(因为程序出错,结果肯定不会正确,所以不存在 程序出错,结果正确 这样一种情况)
所以,如果我们的程序未出错,我们可以通过设置退出码的方式,来表示结果是否正确,这样,我们在进程退出后,直接查看进程退出的退出码就可以了。
同时,通过查看进程退出的状态码,我们还能够准确定位到出错的地方是在什么位置。
比如,我们可以有这样一段代码:
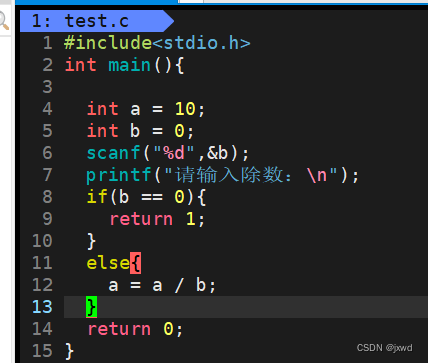
如图所示,我们说过,在main函数里的return值,就可以认为是进程的退出码。那么如果说,我的b为0时,我的退出码就被设置成了1。相反,在程序运行完后,倘若我查看我的退出码是1,我就能够知道我的错误是除数b被设置为0了。
我们说完了退出码,再来说说exit、return和_exit这三兄弟。其实它们的区别很明显,也很好区分。
1、return:一般来说,是一个函数的返回值,也就是说,遇到return 的时候,表明我这样一个函数过程结束了。但是前面说过,如果是main函数的return , 表示main函数这样一个过程结束。main函数结束,我们也就可以认为整个程序运行结束。它的退出码也会被设置成为main函数的返回值。
2、_exit:直接干掉整个进程
3、exit:它不仅会结束掉整个进程,还会进行资源回收处理等等“擦屁股”的动作。它会执行用户的有关清理函数(比如析构函数等),然后把缓冲区刷新、输入输出流等关闭。然后再调用_exit,向内核释放杀死进程的信号,干掉整个进程。
需要说明一下的是,我们这里的杀死进程,在内核当中,它并不一定是真的把该进程相关的资源(如pcb)等全部释放了。它通常可以采用一种“假释放”的方式:可以通过某一种方式,把该pcb的状态设置为“不用”,或者将该pcb的进程地址空间设置为“无效”的状态,然后取消和该进程有关的连接关系。然后下一次,在需要fork进程的时候,我们就直接可以用这些没有用的、但是已经创建出来的pcb就可以,把相关的属性设置回来即可。这样做,也可以大大提高fork的效率。
进程的等待
我们为什么要有进程等待?或者说,进程等待有这样一种必要吗?
答:有必要。
用比较官方、正式的来说,有如下三点原因:
1、回收僵尸进程,解决内存泄漏
2、需要获取子进程的运行结束状态 ( 这点不是必须的)3、父进程要尽量晚于子进程退出,可以规范化进行子进程的资源回收、处理业务。
关于第一点,我们可以多说一嘴:
当fork之后会创建子进程,如果子进程挂掉或者退出,父进程不管的话,就会变成僵尸进程,一直存在系统中,从而造成内存泄漏。
因为变成僵尸进程,就是杀不死的状态,kill -9也无能为力,因为无法去杀掉一个已经死了的进程。所以父进程要知道子进程是正常退出,还是运行完成,结果的对与不对。需要对子进程进行等待和回收,需要给子进程擦屁股。
状态参数status
它是一个输出型参数,关于它怎么用,我们一会儿来说。我们先来说它的性质:
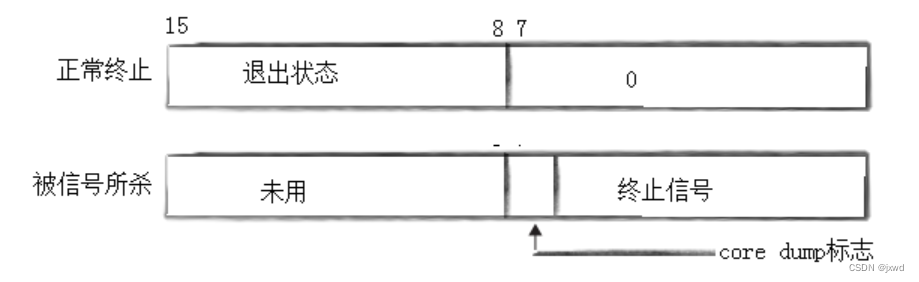
它实际上可以看作是一个十六位的位图:
如果有一个进程正常退出、正常终止,那么其0-7位都是数值0,然后在高8位(即8-15位)填充退出状态码;
如果该进程是被某个信号所杀,而信号一般情况下也都是有编号的,那么就会在低7位(0-6位)来填充该信号的编号,高8位不用,然后第8位用来填充是否生成core dump文件。(1表示生成,0表示不生产)
何为core dump文件?关于core dump文件可以查看一下这篇文章,看完后应该会有所收获。一文读懂 | coredump文件是如何生成的 - 腾讯云开发者社区-腾讯云 (tencent.com)
那么该参数是做什么用的呢?
wait函数和waitpid函数
我们在命令行输入
man 2 wait能够看到关于wait函数的相关介绍:(如下图)
与此同时,我们可以看到waitpid也显示出来了,与此同时显示出来的还有waitid
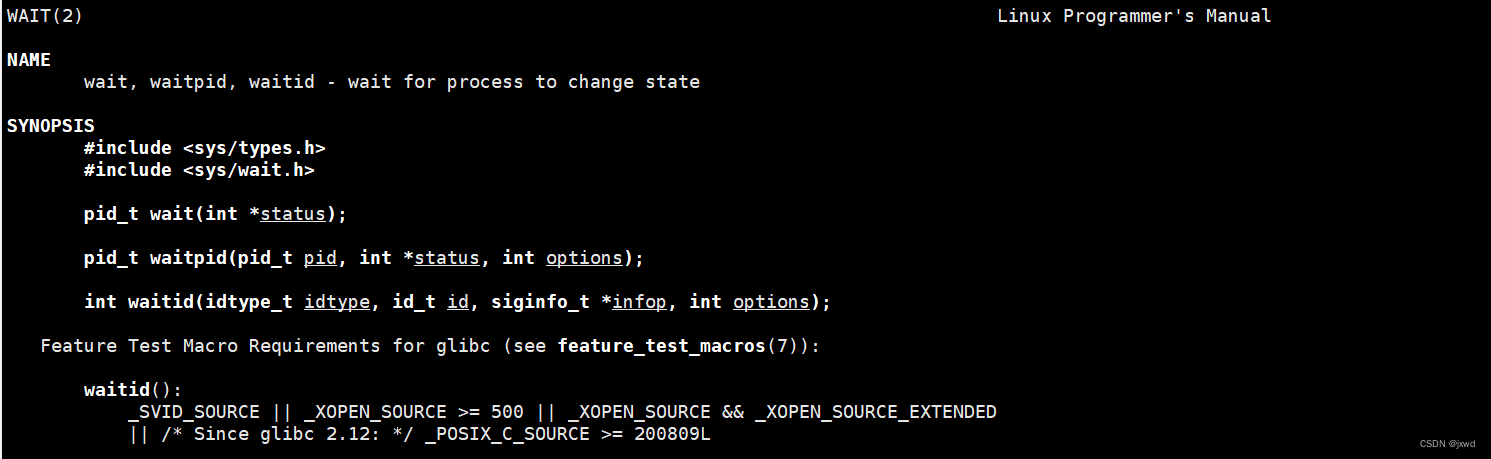
从上面可以看到,它的头文件是两个
我们先来说wait函数。
它的返回值是pid_t,即进程的pid;含义为如果等待成功,则返回被等待进程的pid;否则返回-1.
注意到其有一个参数status,该参数就是我们上面说到的参数。它的类型为int*。
需要注意的是,该参数是一个输出型参数,不是一个输入型参数。什么叫输出型参数?就是函数调用结束以后,会将参数的值写到这个变量里。
换句话说,这个status是用来接收的,本质上不是用来传参的。我们把我们的status定义好了之后,放到该函数里,作为参数传递过去,函数调用完后,操作系统就会把status的值自动填充好,然后还给我们。实现的原理很简单,因为其用的是指针,传递的是变量的地址。倘若我们不关心这个status状态,那么直接传递NULL即可。
我们接下来给出一个例子:
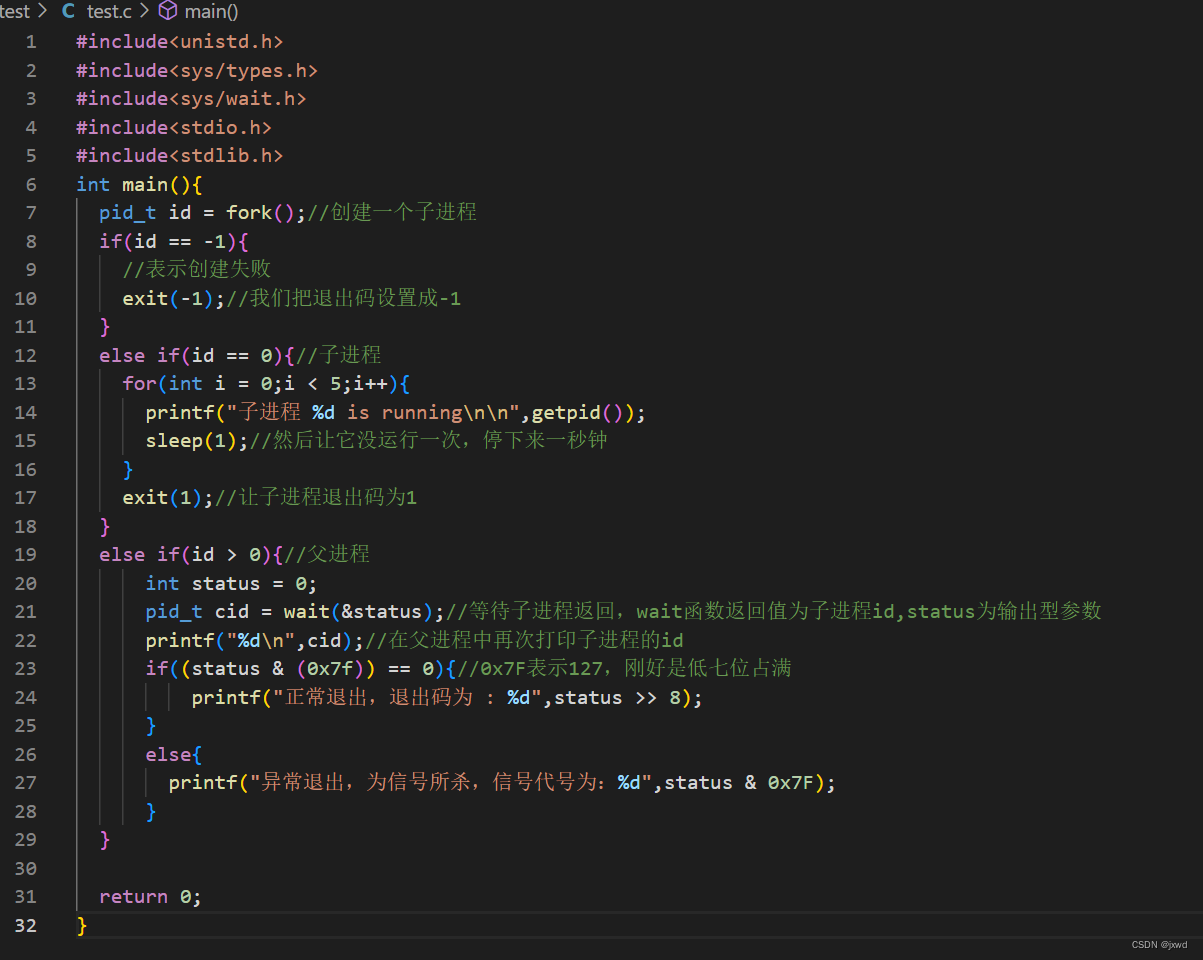
然后我们来运行一下:
运行结果如下图所示 :
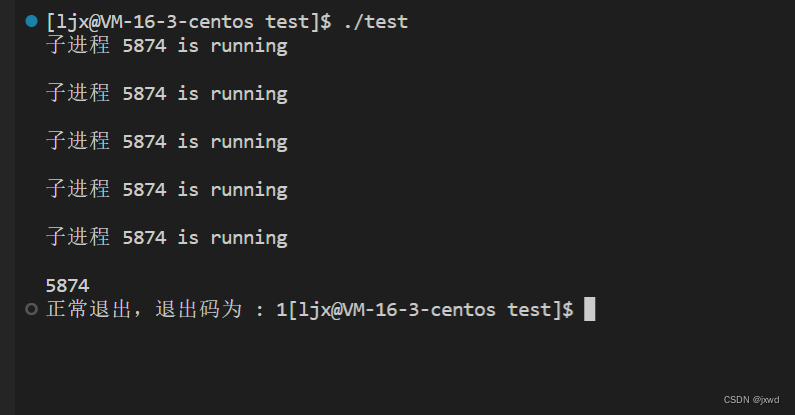
这段代码的含义就不用再过多赘述了,结合注释,还是比较清晰明了的。
我们再来说说waitpid方法:
pid_ t waitpid(pid_t pid, int *status, int options);返回值:
1、当正常返回的时候waitpid返回收集到的子进程的进程ID;
2、如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
3、如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
参数:
1、pid:
如果pid=-1,等待任一个子进程。与wait等效。
如果pid>0.等待其进程ID与pid相等的子进程。
2、status:同wait();
3、options:WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待,即非阻塞式等待。倘若为0,则为阻塞式的等待。
关于非阻塞式等待的用法,我们可以使用轮回询问的方式,即使用循环的方式,不断的询问子进程此时是否退出。而非阻塞式的等待使得父进程在子进程运行时,自己可以不用傻傻的等着,也可以做自己的事情。
好,我们本节的内容就暂时到这里。
如果觉得干货慢慢,不妨点个赞,手有余香~~~
![[附源码]计算机毕业设计的4s店车辆管理系统Springboot程序](https://img-blog.csdnimg.cn/0832d5be63614c3ca2e2458be749311b.png)

![[Go] go基础4](https://img-blog.csdnimg.cn/16d706db4f664c77a1ab4fd497f8e2dc.png)
![[附源码]JAVA毕业设计网络饮品销售管理系统(系统+LW)](https://img-blog.csdnimg.cn/10985da17bfd47ee99e1fd6350e9801b.png)