文章目录
- STC15 - C51 - Memory Models
- 概述
- 笔记
- 内存用量的优化思路
- END
STC15 - C51 - Memory Models
概述
在STC上测试呢, 想看看变量(不同类型的定义)被编译器分配在哪个内存范围(idata, pdata, xdata)?
同时, 总结一下降低内存用量的思路(如果像上位机那样内存管够, 就不用考虑内存用量的优化).
笔记
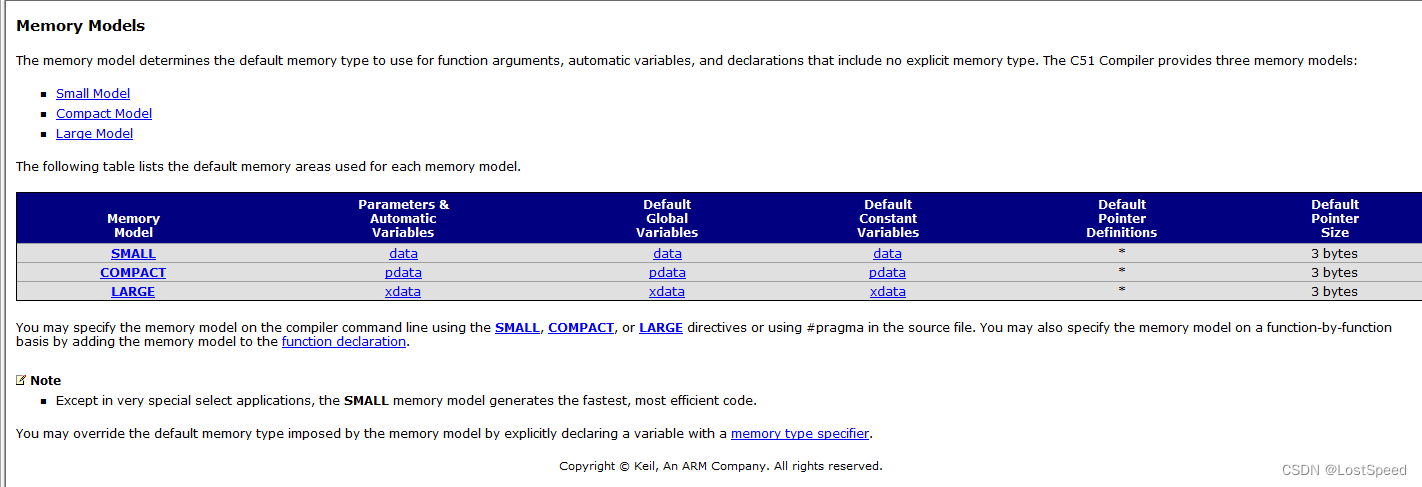
MDK5的自带帮助中, 有关于内存模型的说明.
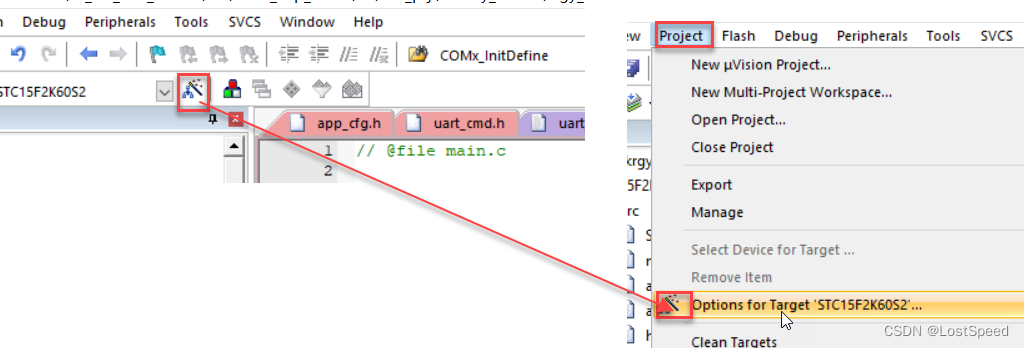
MDK5中可以设置默认的内存模型.
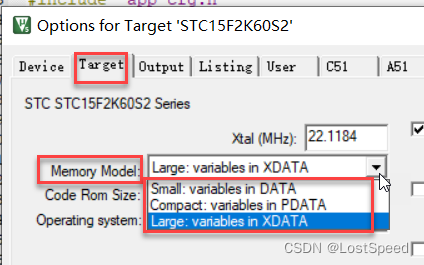
内存模型有3种可选 : Small, Compact, Large.
选定了内存模型后, 可以让编译器按照指定的内存模型, 来分配变量到默认的内存范围.

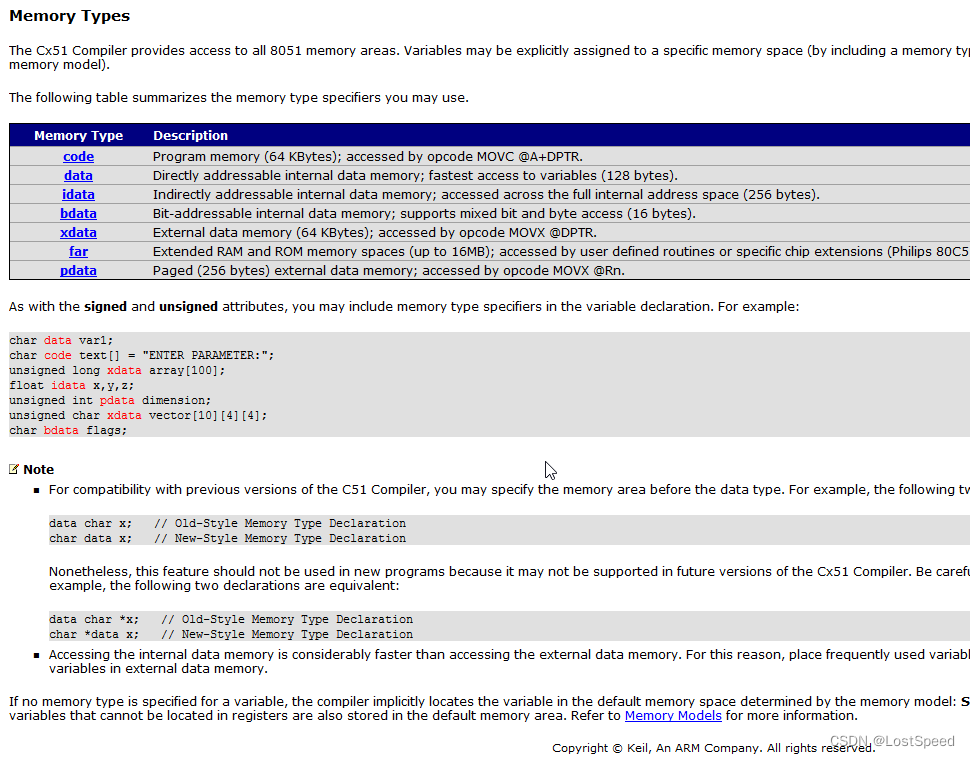
内存模型 - Small : 默认将变量都分配到idata(总共128bytes)
内存模型 - Compact : 默认将变量都分配到pdata(总共256bytes)
内存模型 - Large : 默认将变量都分配到xdata(具体是否超过对应MCU的内部扩展RAM或外部扩展RAM, 需要看具体硬件连接情况), 对于IAP15F2K61S2, 内部扩展RAM范围 0x0 ~ 0x6ff, 但是IAP15自己要用0x400~0x6ff, 所以可用的内部扩展RAM范围为0x0 ~ 0x3ff
选定内存模型后, 变量被编译器自动分配到默认的内存范围. 但是可以单独指定函数入参和局部变量, 全局变量到底存在哪里.
C51的函数调用时, 参数并不在栈内, 而是全局变量.
可以单独指定函数参数的存储位置.
#pragma small /* Default to small model */
extern int calc (char i, int b) large reentrant;
extern int func (int i, float f) large;
extern void *tcp (char xdata *xp, int ndx) compact;
int mtest (int i, int y) /* Small model */
{
return (i * y + y * i + func(-1, 4.75));
}
int large_func (int i, int k) large /* Large model */
{
return (mtest (i, k) + 2);
}
如上的函数定义, 只能告诉编译器将函数入参分配到哪个内存区, 但是对节约内存没有帮助. 多一个被调用的函数实现(假设函数有入参), 内存用量还是会增加.
在C51中的局部变量也不在栈中(其实也是全局变量). 可以单独指定局部变量分配在哪个内存范围.
我的测试程序, 变量空间> 0x256, 直接将内存模型选为Large了.
在一个函数内定义3个变量, idata, pdata, xdata, 看看编译后内存空间大小的变化.
int main(void)
{
// int idata x1 = 0;
// int pdata x2 = 0;
// int xdata x3 = 0;
每次编译后, 就逐个注释掉3个变量定义, 再编译, 得到如下实验结果.
Program Size: data=25.1 xdata=969 code=28811 x1,x2, x3
Program Size: data=25.1 xdata=967 code=28803 x1,x2
Program Size: data=25.1 xdata=965 code=28796 x1
Program Size: data=23.1 xdata=965 code=28789
可以看出:
idata变量被编译器分配在data区.
pdata变量被编译器分配在xdata区.
xdata变量被编译器分配在xdata区.
内存用量的优化思路
51MCU, 内部扩展RAM就那么多(1K+), 如果不规划内存用量, 多一个函数就多占用一些内存(函数入参, 函数内的局部变量), 函数写的越多, 内存占用越多. 最后直到程序编译不过去, 显示内存越界.
将不在一条调用链上的函数, 公用一些内存空间, 就能节省一些内存. 且不随着函数数量的增加, 内存占用量上升不明显.
中断函数的内存用量要是单独的.
顶层函数的内存用量最好是单独的.
被顶层函数调用的多个并排的底层函数(这些函数之间, 不存在同时被调用的可能), 内存可以是公用的.
自己做一个结构体, 将变量都放到里面.
不能公用的变量, 就是结构体中的一个变量或结构.
能公用的变量, 就是结构体中的联合中的一个变量或结构. 如下所示.
// D:\my_dev\my_local_git_prj\hardware\LS_stc_dev_board\src\stc15_exp_box4\v5\soft_prj\factory_mode\uart_cmd.c
typedef struct _tag_uart_cmd {
int len;
int i;
int len1;
int len2;
TAG_CMD_ITEM code* pcmd_item;
TAG_CMD_PARAM* pcmd_param;
} TAG_uart_cmd;
// D:\my_dev\my_local_git_prj\hardware\LS_stc_dev_board\src\stc15_exp_box4\v5\soft_prj\factory_mode\hardware_init.c
typedef struct _tag_hardware_init{
COMx_InitDefine COMx_InitStructure; //结构定义
}TAG_hardware_init;
typedef union un_app_cfg {
// union中的内容不能为空
TAG_hardware_init hardware_init;
TAG_uart_cmd uart_cmd;
TAG_uart_cmd_help uart_cmd_help;
TAG_uart_cmd_test_ind_leds uart_cmd_test_ind_leds;
TAG_uart_cmd_test_7seg uart_cmd_test_7seg;
TAG_Exti Exti;
TAG_uart_cmd_test_exint_2key uart_cmd_test_exint_2key;
TAG_uart_cmd_test_key16_normal uart_cmd_test_key16_normal;
TAG_uart_cmd_test_key16_adc uart_cmd_test_key16_adc;
TAG_uart_cmd_test_ex_ram uart_cmd_test_ex_ram;
TAG_uart_cmd_test_12864 uart_cmd_test_12864;
TAG_uart_cmd_test_1602 uart_cmd_test_1602;
TAG_EEPROM EEPROM;
TAG_uart_cmd_test_e2prom uart_cmd_test_e2prom;
TAG_uart_cmd_test_LVD uart_cmd_test_LVD;
TAG_uart_cmd_test_RTC uart_cmd_test_RTC;
TAG_uart_cmd_test_pm25 uart_cmd_test_pm25;
Tag_uart_cmd_test_NTC uart_cmd_test_NTC;
} UN_APP_CFG;
typedef struct _tag_app_global_var {
// 需要被同时使用的变量, 放在union外面的结构中
u8 g_tmp_buf[TMP_BUFFER_LEN];
u8 g_param_buf[TMP_BUFFER_LEN];
UFP_uart_cmd g_UFP_uart_cmd;
BOOL is_cmd_was_process;
BOOL is_cmd_process_ok;
// 能不同时使用的变量都放un中的每个应用参数中
UN_APP_CFG un;
} TAG_APP_GLOBAL_VAR;
extern u8 bdata u8_flag;
extern TAG_APP_GLOBAL_VAR xdata app;
调用这些变量时, 示例如下:
不能公用的变量用法 app.is_cmd_process_ok
可以公用的变量用法 app.un.uart_cmd.pcmd_item
这种方法还挺管用的, 从1200字节, 优化到了965字节. 这样的话,使用片内扩展RAM(0x0~0x400)就可以满足逻辑运行的要求.
这种内存优化思路不好的地方, 没有直接写全局变量直观了(每个变量都好长, 需要好几个结构的.操作才能使用这个变量, 看起来也挺恶心).
u8 code fn_parse_user_input_form_uart1(void /*u8* pbuf, int len_buf*/)
{
app.un.uart_cmd.len = 0;
if ( (NULL == app.g_UFP_uart_cmd.fn_parse_user_input_form_uart1.pbuf)
|| (app.g_UFP_uart_cmd.fn_parse_user_input_form_uart1.len_buf < 2)
|| (COM1.RX_Cnt < 2)) {
return FALSE;
}
memset(app.g_UFP_uart_cmd.fn_parse_user_input_form_uart1.pbuf, 0,
app.g_UFP_uart_cmd.fn_parse_user_input_form_uart1.len_buf);
RX1_Buffer[COM1.RX_Cnt - 2] = '\0';
app.un.uart_cmd.len = strlen(RX1_Buffer);
PrintString1("您输入的命令为[");
PrintString1(RX1_Buffer);
PrintString1("]\r\n");
PrintString2("您输入的命令为[");
PrintString2(RX1_Buffer);
PrintString2("]\r\n");
if ((app.un.uart_cmd.len <= 0)
|| (app.un.uart_cmd.len >= (app.g_UFP_uart_cmd.fn_parse_user_input_form_uart1.len_buf - 1))) {
return FALSE;
}
strcpy(app.g_UFP_uart_cmd.fn_parse_user_input_form_uart1.pbuf, RX1_Buffer); // 得到了没有\r\n, 以\0结尾的用户命令
return TRUE;
}
甚至为了进一步降低内存用量, 直接将有些函数改成(void)无入参. 实际的入参由外部调用直接赋值, 函数内部直接使用函数外部赋值的全局变量, 看着更恶心了.
函数调用
app.un.uart_cmd_test_pm25.SPI_Write_Nbytesaddr = app.un.uart_cmd_test_pm25.Flash_addr;
app.un.uart_cmd_test_pm25.SPI_Write_Nbytesbuffer = app.un.uart_cmd_test_pm25.tmp;
app.un.uart_cmd_test_pm25.SPI_Write_Nbytessize = 0x10;
SPI_Write_Nbytes(); //写N个字节
函数实现
void SPI_Write_Nbytes(void /* u32 addr, u8* buffer, u8 size */)
{
if (app.un.uart_cmd_test_pm25.SPI_Write_Nbytessize == 0) {
return;
}
if (!app.un.uart_cmd_test_pm25.B_FlashOK) {
return;
}
while (CheckFlashBusy() > 0); //Flash忙检测
FlashWriteEnable(); //使能Flash写命令
SPI_CE_Low(); // enable device
app.un.uart_cmd_test_pm25.SPI_WriteByteout = SFC_PAGEPROG;
SPI_WriteByte(); // 发送页编程命令
不过, 对于MCU这种内存, 寸土寸金的地方, 牺牲一些直观性, 来保证内存用量可控, 还是值得的(暂时想不到其他方法可以大规模的降低内存用量).
![[附源码]计算机毕业设计的4s店车辆管理系统Springboot程序](https://img-blog.csdnimg.cn/0832d5be63614c3ca2e2458be749311b.png)

![[Go] go基础4](https://img-blog.csdnimg.cn/16d706db4f664c77a1ab4fd497f8e2dc.png)
![[附源码]JAVA毕业设计网络饮品销售管理系统(系统+LW)](https://img-blog.csdnimg.cn/10985da17bfd47ee99e1fd6350e9801b.png)