一、论文信息
文章名称:DF-Platter: Multi-Face Heterogeneous Deepfake Dataset
作者团队:

会议:cvpr2023
数据集地址:http://iab-rubric.org/df-platter-database
二、动机与创新
动机
目前大多数研究工作都集中在个人外表受控的高质量图像和视频上。 但是,deepfake 生成算法现在能够创建具有低分辨率、遮挡和操纵多个拍摄对象的 deepfake,这给检测带来了新的挑战。

创新
作者提出了DF-Platter数据集,该数据集模拟了deepfake生成的真实场景。
-
使用多种技术生成的低分辨率和高分辨率深度伪造;
-
带有印度种族面部图像的单主体和多主体深度伪造。
该数据集中的人脸根据性别、年龄、肤色和遮挡等各种属性进行注释。该数据集使用32个GPU和1,800GB的内存准备了116天,它包含三组共133,260个视频。
三、数据集
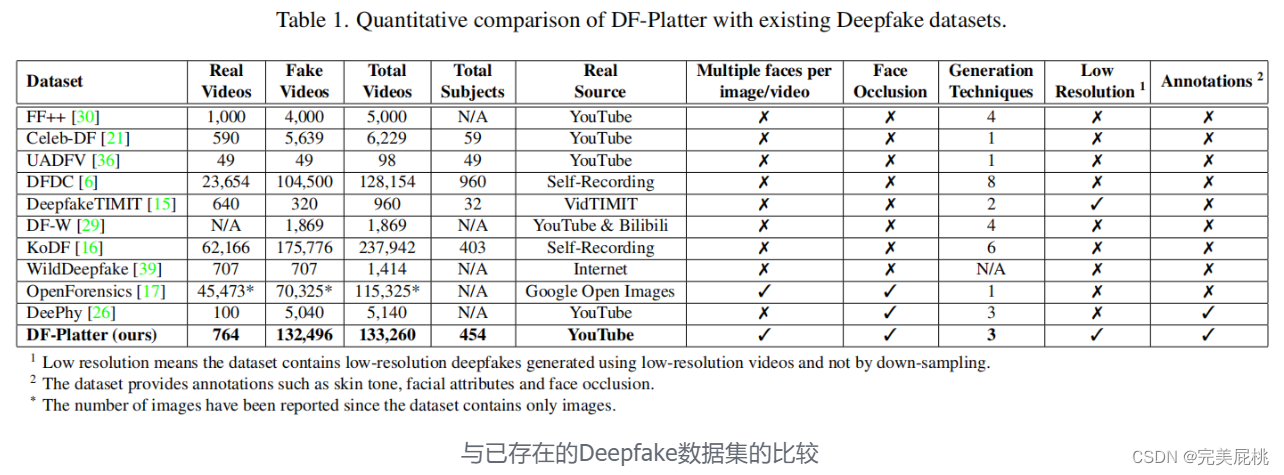
1、DF-Platter数据集,是一个多人脸异构的 deepfake 数据集。
-
该数据集利用低分辨率视频生成 deepfakes,这与使用高分辨率视频合成插值 deepfakes 的现有数据集不同。 通过使用低分辨率视频,可以提高低分辨率 deepfakes 的视觉质量。这是因为deepfake 生成算法针对低分辨率视频进行了优化,从而产生了更高质量的 deepfake。
-
该数据集是包含多个面部的deepfake集合,这意味着每个视频帧中有多个拍摄对象。视频帧中的每张脸都注释为真实或虚假,这样可以对多面部深度伪造进行全面评估。
-
该数据集提供了具有印度种族主题的deepfakes的性别均衡分布。这意味着男性和女性受试者人数相等,而且受试者是印度裔。并根据性别、年龄、肤色和遮挡等各种属性进行注释。
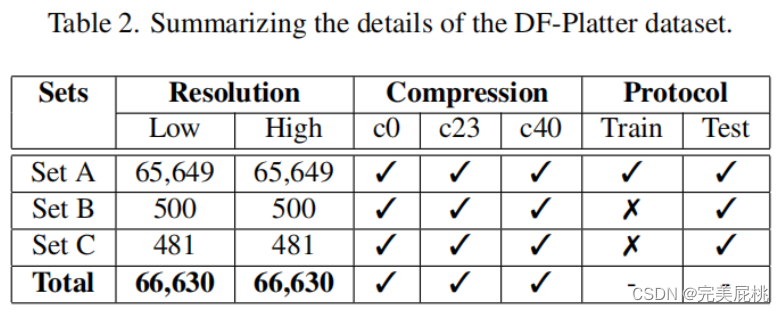
 2、DF-Platter数据集是使用三种不同的技术生成的:FSGAN、FaceShifter和FaceSwap。 DF-Platter数据集在分辨率和性别之间是平衡的,且数据集中的所有视频提供两个压缩级别c23 和 c40。
2、DF-Platter数据集是使用三种不同的技术生成的:FSGAN、FaceShifter和FaceSwap。 DF-Platter数据集在分辨率和性别之间是平衡的,且数据集中的所有视频提供两个压缩级别c23 和 c40。
3、DF-Platter数据集中的视频是从 YouTube 收集的,YouTube 提供的视频种类繁多,包括性别、取向、肤色、脸部大小、光照条件、背景和遮挡等各不相同。 同时,使用Fitzpatrick量表测量肤色,这是一个数字分类系统,根据肤色对紫外线的反应对肤色进行分类。 当手、头发、眼镜或任何其他物体挡住源面部或目标面部的一部分时,就会发生遮挡。
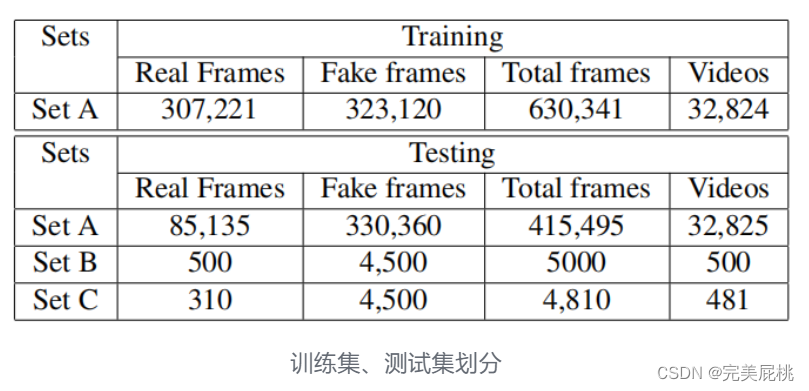
4、真实视频:1)Set A 共包含 602 个用于生成 deepfakes 的真实视频。这些视频的性别和分辨率分布几乎相等,有151个视频针对男性,150个视频针对女性。此外,所有视频都是以低分辨率和高分辨率收集的,每个视频的时长约为20秒。 2)Set B 采用 100 个真实视频来生成 deepfake,低分辨率和高分辨率视频的比例相等。这些视频在视频的一帧内有多个对象,这使得检测deepfakes变得具有挑战性。3)Set C 是使用 62 个真实视频生成的,这些深度伪造是在每帧的多个目标拍摄对象上粘贴名人面孔时生成的,涉及在单个帧中操纵多个面孔。 数据集包含三个压缩级别的所有集合,即 c0、c23 和 c40。
5、虚假视频:1)Set A 包含 130,696 个使用 FSGAN 和 FaceShifter 技术生成的单对象deepfake 视频。有150名女性受试者和151名男性受试者,并包括每个受试者的肤色、面部遮挡和表观年龄的注释。面部遮挡物各不相同,包括胡须、眼镜、帽子/头巾和头发,这些遮挡物存在于不受控制的环境中。 2)Set B 包含 900 个内部深度伪造视频,这些视频是使用 FSGAN、FaceSwap 和 FaceShifter 技术合成的。 Set B 中的每个真实视频至少有 2 个,最多 5 个拍摄对象,其中在生成虚假视频期间,最少 2 个,最多 3 个被交换。 3)Set C 与 Set B 类似,但特别关注印度名人作为deepfake视频中的来源面孔。 Set C 中使用的真实视频与单对象名人面孔交换,其中包含 62 个真实视频和 900 个 deepfake 视频。 DF-Platter 数据集的原始形式约为 417 GB,总共包含 133,260 个视频,每个视频的持续时间约为 20 秒。 4)视频以 MPEG4.0 格式提供,具有高分辨率和相应的低分辨率,所有视频的帧速率均为 25 fps。 该数据集在分辨率、压缩和所使用的生成技术方面始终包含相同的视频。 对于 c23 和 c40 级别的压缩,使用 H.264 视频压缩。
6、数据集使用各种属性进行注释,例如性别、分辨率、遮挡和肤色。

- 性别分为两类,男性或女性。
-
使用Fitzpatrick量表,每个受试者的肤色以1到6的等级进行注释,菲茨帕特里克量表是一种广泛使用的人类肤色分类系统。
-
表观年龄属性分为三类:青少年(18 至 30 岁)、成人(30 至 55 岁)和老年(55 岁以上)。 51.33% 的受试者被归类为 “青少年”,42% 的受试者被归类为 “成人”,6.66% 的受试者被归类为 “老人”。
-
面部遮挡分为八大类:阴影、胡须、眼镜、阴影、麦克风、帽子、头巾/围巾和头发遮挡。 这些属性本质上是二进制的,这意味着受试者要么有遮挡,要么没有遮挡。 胡子是男性中最常见的遮挡类型,大约90%的男性受试者有胡须。
7、数据集分为三组:训练、验证和测试。8:1:1,训练集包含 80% 的视频,而验证和测试集各包含 10% 的视频。 数据集中的视频被随机分配到三个集合,确保每组视频的深度伪造和真实视频的分布均匀。
四、实验
三个问题:1)是否可以检测到被遮挡的深度伪造。2)是否可以检测到视频中的多面部深度伪造。3)是否可以检测到网络和社交媒体上的低分辨率和压缩的deepfakes。
三个协议:1) Occludeepfakes,使用SET A 作为测试集,分为三个子集用于训练、验证和测试。该数据集包含真实视频和虚假视频数量之间的显著差异,这可能会导致数据集出现偏差。为了解决这个问题,在训练不同的架构的同时重复真实的视频,以获得几乎相等数量的真实和虚假样本。然后对最先进的模型进行测试,以检测被遮挡的deepfakes,结果以三种压缩设置(c0、c23 和 c40)提供。
2)Multi-Face Deepfakes 使用SET B 和SET C 作为测试集。SET B 包含 500 个视频,其中 500 个真实帧和 4500 个假帧。每帧可以有一张或多张真面孔或假脸,如果操纵了至少一张脸,则视频被视为假脸。SET C 由481个视频组成,其中31个是真实的,450个是假的。这些模型在SET B 和 C 上进行了性能测试,这两个集合有多个受试者使用各种指标。
3)交叉分辨率和交叉压缩,实验以分析在网络和社交媒体上共享深度伪造的现实环境中现有深度伪造探测器的交叉分辨率和交叉压缩性能。在交叉分辨率实验中,模型在(c0,HR)样本上进行训练,并在(c0,LR)样本上进行测试。在交叉压缩实验中,模型在(c23,HR)样本上进行训练,并在(c40,HR)样本上进行测试。在这两个实验中,训练样本均取自SET A,并在所有三个集合上进行测试。
 这些方法在相同的压缩和分辨率设置下进行了训练和测试,以确保评估过程的一致性和公平性。
这些方法在相同的压缩和分辨率设置下进行了训练和测试,以确保评估过程的一致性和公平性。
-
评估是针对三组进行的:A组(协议1)、B组和C(协议2)。
-
对于SET A,使用的评估指标是准确度 (%) 和 AUC(曲线下区域)。
-
对于SET B 和 C,使用的评估指标是 FaceWA (%)、FaceAuc、FLA (%) 和 VLA (%)。 FaceWA (%) 是指正确识别的 deepfake 人脸的百分比,FaceAuc 是指接收器操作特征 (ROC) 曲线下方的面积,用于人脸水平检测,FLA (%) 是指正确识别的虚假视频的百分比。 -报告了每个集合和协议的评估结果,全面分析了DF-Platter数据集上deepfake检测模型的性能。