注1:本文系“简要介绍”系列之一,仅从概念上对知识蒸馏进行非常简要的介绍,不适合用于深入和详细的了解。
知识蒸馏:轻量级模型的智慧之源
A Gentle Introduction to Hint Learning & Knowledge Distillation | by LA Tran | Towards AI
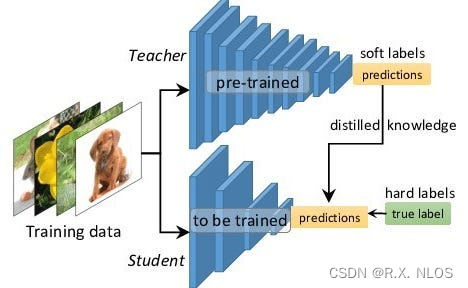
在深度学习领域,使用大型神经网络模型通常能够获得更好的性能。然而,这些模型往往具有 高计算复杂度 ,不适合在边缘设备上部署。知识蒸馏(Knowledge Distillation)是一种将大型模型的知识迁移到小型模型中以提高其性能的技术,具有广泛的应用前景。本文将从背景、原理、研究现状、挑战和未来展望等方面介绍知识蒸馏。
背景介绍
随着人工智能的快速发展,深度学习模型在诸如计算机视觉、自然语言处理等领域取得了显著的成果。然而,这些模型的参数量和计算复杂度往往很高,难以直接应用于资源有限的环境,如手机、嵌入式设备等。因此, 模型压缩 成为了一个重要的研究方向。
知识蒸馏 是一种有效的模型压缩方法,通过训练一个较小的学生模型来模拟大型教师模型的行为,从而在保持较低计算复杂度的同时,提高模型性能。
原理介绍和推导
知识蒸馏的基本原理是让学生模型学习教师模型的输出概率分布。以下是详细的推导过程:
设 x x x 是输入数据, y y y 是真实标签, T T T 是教师模型, S S S 是学生模型。我们用 P T P_T PT 和 P S P_S PS 分别表示教师模型和学生模型预测的概率分布,它们可以通过 softmax 函数计算得到:
P T ( y ∣ x ) = e z T y / T ∑ y ′ e z T y ′ / T , P S ( y ∣ x ) = e z S y / T ∑ y ′ e z S y ′ / T P_T(y|x) = \frac{e^{z_T^y/T}}{\sum_{y'} e^{z_T^{y'}/T}}, \quad P_S(y|x) = \frac{e^{z_S^y/T}}{\sum_{y'} e^{z_S^{y'}/T}} PT(y∣x)=∑y′ezTy′/TezTy/T,PS(y∣x)=∑y′ezSy′/TezSy/T
其中, z T z_T zT 和 z S z_S zS 分别表示教师模型和学生模型的 logits 输出, T T T 是一个温度参数,用于控制概率分布的平滑程度。
知识蒸馏的目标是最小化学生模型和教师模型的概率分布之间的差异,通常使用 KL 散度 来衡量。定义损失函数为:
L K D = ∑ x K L ( P T ( ⋅ ∣ x ) ∣ ∣ P S ( ⋅ ∣ x ) ) L_{KD} = \sum_x KL(P_T(\cdot|x) || P_S(\cdot|x)) LKD=x∑KL(PT(⋅∣x)∣∣PS(⋅∣x))
为了兼顾真实标签信息,我们还可以将知识蒸馏损失和常规的分类损失相结合:
L = ( 1 − α ) L C E + α T 2 L K D L = (1 - \alpha)L_{CE} + \alpha T^2 L_{KD} L=(1−α)LCE+αT2LKD
其中, L C E L_{CE} LCE 是分类损失(如交叉熵损失), α \alpha α 是一个权重参数,用于平衡两者的影响。
研究现状
自 2015 年 Hinton 等人首次提出知识蒸馏以来,该领域的研究取得了丰富的成果。在此,我们将简要介绍一些知识蒸馏的研究方向和关键技术。
-
蒸馏方法: 除了基本的蒸馏方法,还有许多改进和扩展,例如使用额外的监督信息、动态调整温度参数等。
-
自蒸馏: 一种将模型自身的知识迁移到同一模型的方法。通过在不同训练阶段或不同网络层之间进行蒸馏,可以提高模型性能,并有助于泛化。
-
多教师蒸馏: 通过结合多个教师模型的知识,可以进一步提高学生模型的性能。
-
在线蒸馏: 在训练过程中实时生成教师模型,与学生模型共同学习。
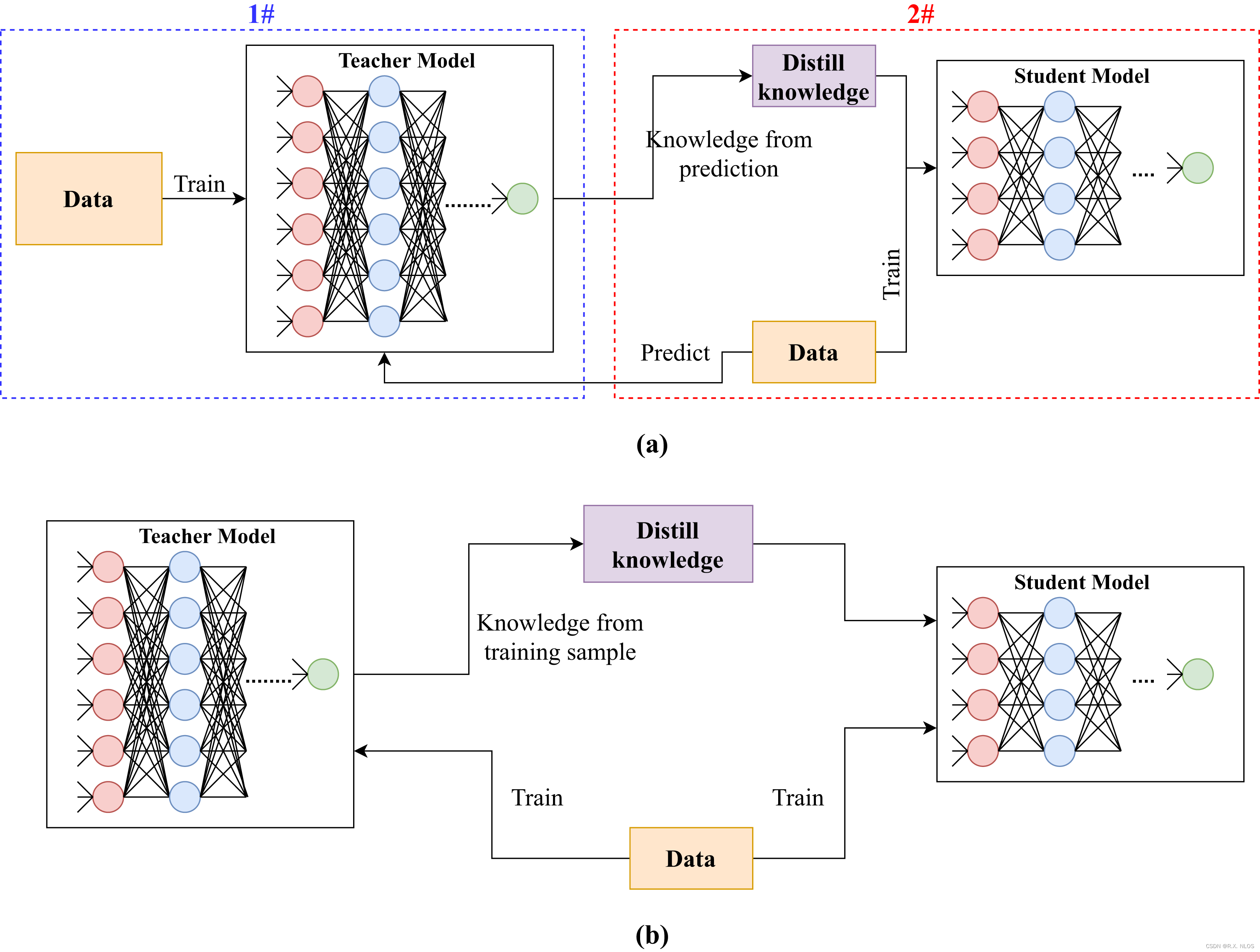
Knowledge distillation in deep learning and its applications [PeerJ]
挑战
尽管知识蒸馏已经取得了一定的成功,但仍面临许多挑战,包括:
-
优化方法: 知识蒸馏涉及到两个或多个模型之间的相互作用,如何有效地优化这些模型仍是一个开放性问题。
-
知识迁移的有效性: 由于教师模型和学生模型的结构差异,部分知识可能难以迁移。如何设计更通用的知识迁移方法仍需进一步研究。
-
计算效率: 知识蒸馏需要训练多个模型,可能导致较高的计算开销。如何减少蒸馏过程的计算成本是另一个重要问题。
未来展望
随着边缘计算和物联网的发展,轻量级模型在实际应用中的需求将越来越大。因此,知识蒸馏等模型压缩技术将持续受到关注。在未来,我们期待以下几个方向的发展:
-
新的蒸馏方法: 探索更高效、更通用的知识蒸馏方法,以适应各种应用场景。
-
跨领域知识迁移: 将知识蒸馏应用于不同领域和任务之间的知识迁移,实现更广泛的泛化能力。
-
自动化模型设计: 结合自动机器学习(AutoML)技术,在知识蒸馏过程中自动搜索最优的学生模型结构和参数。
-
与其他模型压缩技术的融合: 将知识蒸馏与其他模型压缩技术(如剪枝、量化等)相结合,实现更高效的模型压缩和性能提升。
总结
知识蒸馏是一种将大型神经网络模型的知识迁移到小型模型的技术。通过训练一个较小的学生模型来模拟大型教师模型的行为,知识蒸馏旨在在保持较低计算复杂度的同时提高模型性能。尽管知识蒸馏在过去几年中取得了显著的进展,但仍存在许多挑战和未来的研究方向。随着边缘计算和物联网的发展,知识蒸馏等模型压缩技术将在未来继续受到关注,为智能设备和应用提供支持。
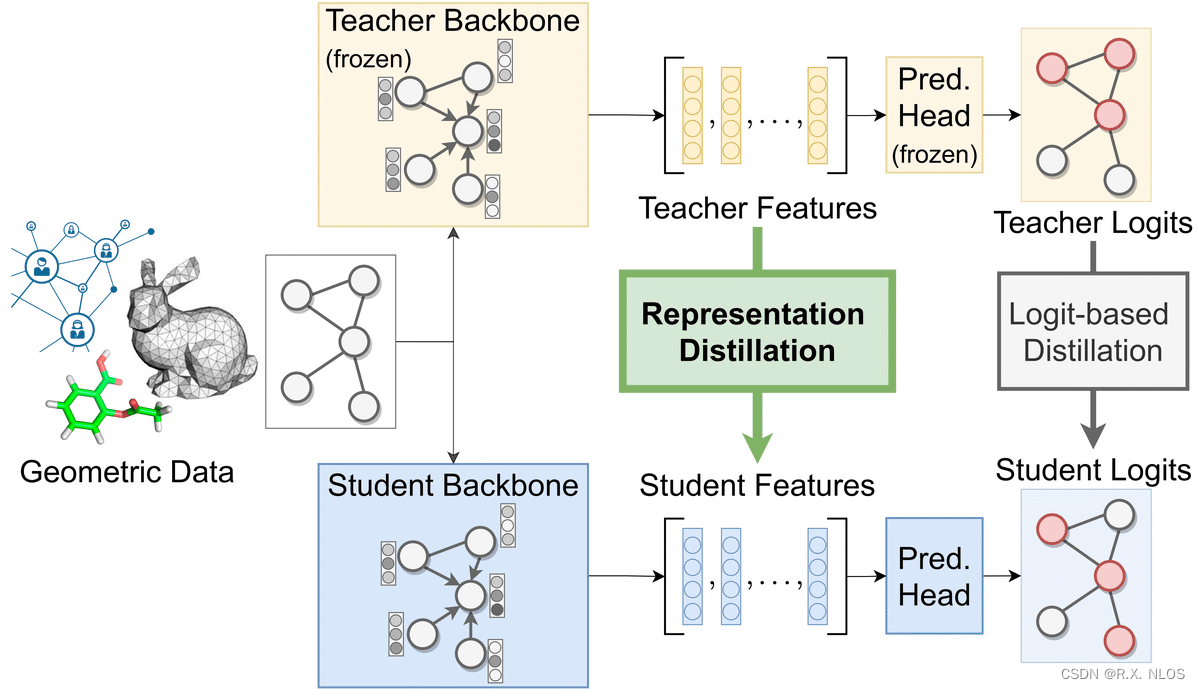
On Representation Knowledge Distillation for Graph Neural Networks | Chaitanya K. Joshi
代码示例
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
# 定义教师模型
class TeacherModel(nn.Module):
def __init__(self):
super(TeacherModel, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 定义学生模型
class StudentModel(nn.Module):
def __init__(self):
super(StudentModel, self).__init__()
self.fc1 = nn.Linear(784, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 计算软目标损失
def soft_target_loss(y_s, y_t, T):
y_s = torch.nn.functional.log_softmax(y_s / T, dim=1)
y_t = torch.nn.functional.softmax(y_t / T, dim=1)
return torch.mean(torch.sum(-y_t * y_s, dim=1))
# 超参数
T = 2.0 # 温度参数
alpha = 0.5 # 软目标损失权重
epochs = 10
learning_rate = 0.001
# 初始化模型、损失函数和优化器
teacher_model = TeacherModel()
student_model = StudentModel()
criterion_hard = nn.CrossEntropyLoss()
optimizer = optim.Adam(student_model.parameters(), lr=learning_rate)
# 模拟训练数据
inputs = Variable(torch.randn(100, 784))
labels = Variable(torch.randint(0, 10, (100,)))
# 开始训练
for epoch in range(epochs):
optimizer.zero_grad()
# 教师模型和学生模型的输出
teacher_output = teacher_model(inputs)
student_output = student_model(inputs)
# 计算硬目标损失和软目标损失
loss_hard = criterion_hard(student_output, labels)
loss_soft = soft_target_loss(student_output, teacher_output, T)
# 计算总损失
loss = (1 - alpha) * loss_hard + alpha * loss_soft
# 反向传播和优化
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}")
以上代码展示了一个简单的知识蒸馏示例,其中一个简化的教师模型将知识传递给一个更小的学生模型。在每次训练迭代中,我们计算硬目标损失(基于真实标签)和软目标损失(基于教师模型的输出)。请注意,这个示例仅用于演示知识蒸馏的基本概念,并未涉及数据加载、模型评估等实际应用中的其他关键步骤。