目录
1.GCT介绍
实验结果
2.GCT引入到yolov5
2.1 加入common.py中:
2.2 加入yolo.py中:
2.3 yolov5s_GCT.yaml
2.4 yolov5s_GCT1.yaml

1.GCT介绍

论文:https://openaccess.thecvf.com/content/CVPR2021/papers/Ruan_Gaussian_Context_Transformer_CVPR_2021_paper.pdf
浙江大学等机构发布的一篇收录于CVPR2021的文章,提出了一种新的通道注意力结构,在几乎不引入参数的前提下优于大多SOTA通道注意力模型,如SE、ECA等。这篇文章虽然叫Gaussian Context Transformer,但是和Transformer并无太多联系,这里可以理解为高斯上下文变换器。
LCT(linear context transform)观察所得,如下图所示,SE倾向于学习一种负相关,即全局上下文偏离均值越多,得到的注意力激活值就越小。为了更加精准地学习这种相关性,LCT使用一个逐通道地变换来替代SE中的两个全连接层。然而,实验表明,LCT学得的这种负相关质量并不是很高,下图中右侧可以看出,LCT的注意力激活值波动是很大的。
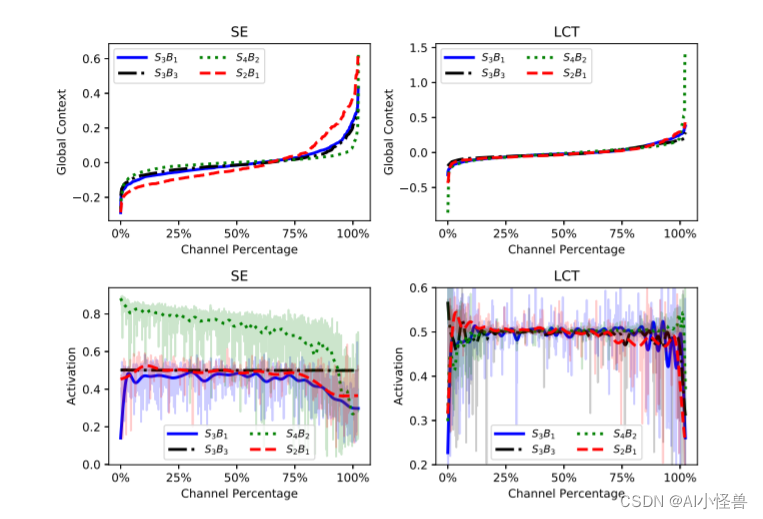
在本文中,我们假设这种关系是预先确定的。基于这个假设,我们提出了一个简单但极其有效的通道注意力块,称为高斯上下文Transformer (GCT),它使用满足预设关系的高斯函数实现上下文特征激励。

实验结果
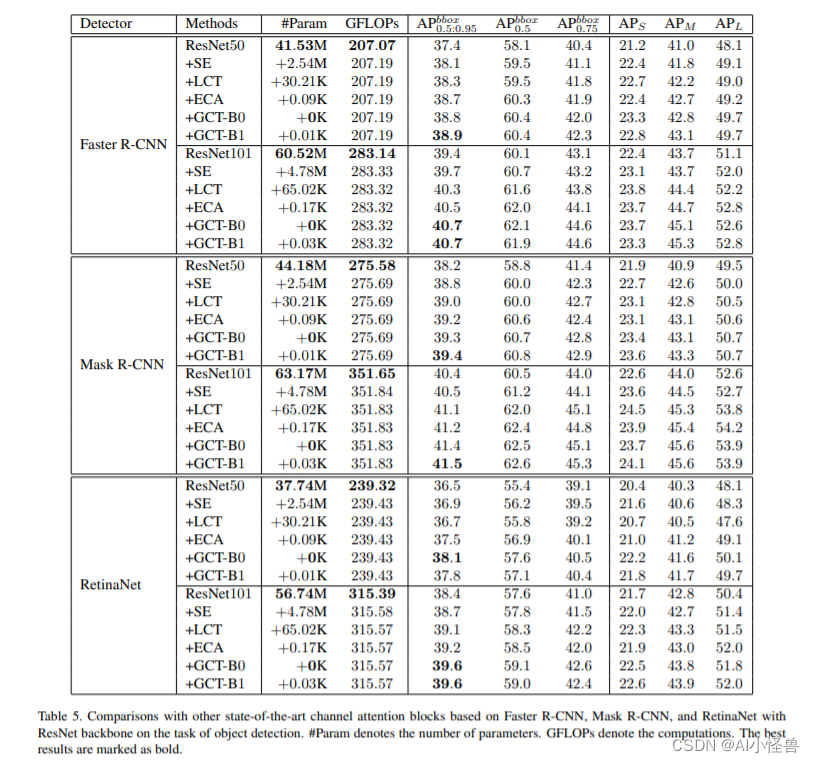
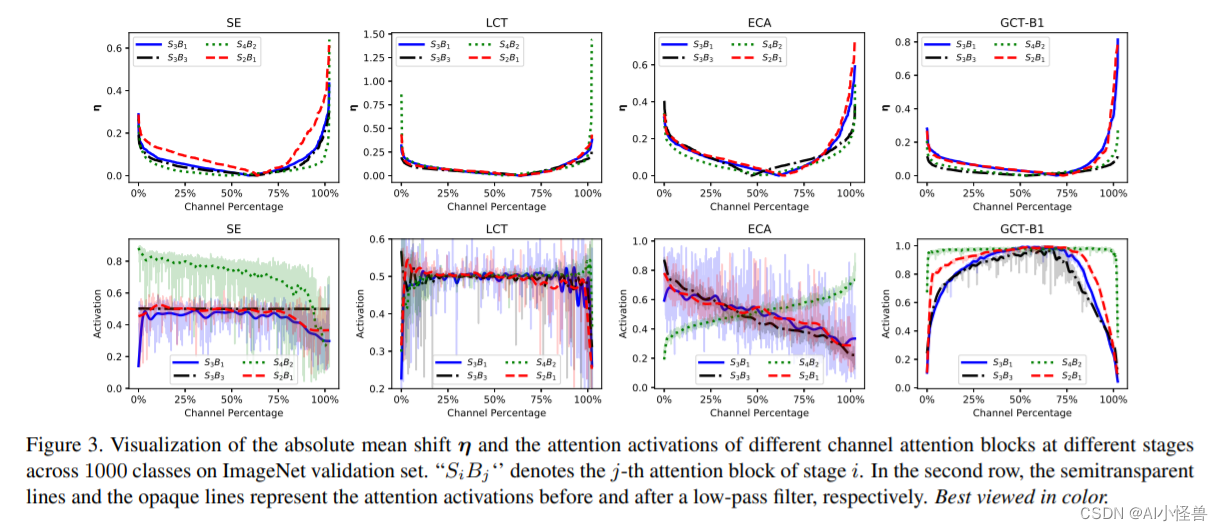
在ImageNet 和 MS COCO 基准测试的大量实验表明,我们的 GCT 导致各种深度 CNN 和检测器的持续改进。与一系列最先进的通道注意力块(例如 SE 和 ECA)相比,我们的 GCT 在有效性和效率方面更为出色。
2.GCT引入到yolov5
2.1 加入common.py中:
###################### Gaussian Context Transformer attention #### END by AI&CV ###############################
"""
PyTorch implementation of Gaussian Context Transformer
As described in http://openaccess.thecvf.com//content/CVPR2021/papers/Ruan_Gaussian_Context_Transformer_CVPR_2021_paper.pdf
Gaussian Context Transformer (GCT), which achieves contextual feature excitation using
a Gaussian function that satisfies the presupposed relationship.
"""
import torch
from torch import nn
class GCT(nn.Module):
def __init__(self, channels, c=2, eps=1e-5):
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.eps = eps
self.c = c
def forward(self, x):
y = self.avgpool(x)
mean = y.mean(dim=1, keepdim=True)
mean_x2 = (y ** 2).mean(dim=1, keepdim=True)
var = mean_x2 - mean ** 2
y_norm = (y - mean) / torch.sqrt(var + self.eps)
y_transform = torch.exp(-(y_norm ** 2 / 2 * self.c))
return x * y_transform.expand_as(x)
###################### Gaussian Context Transformer attention #### END by AI&CV ###############################2.2 加入yolo.py中:
def parse_model(d, ch): # model_dict, input_channels(3)
添加以下内容
if m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF,DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, CNeB, nn.ConvTranspose2d, DWConvTranspose2d, C3x, C2f,GCT}:2.3 yolov5s_GCT.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, GCT, [1024]], # 24
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.4 yolov5s_GCT1.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, GCT, [256]], # 18
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, GCT, [512]], # 22
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large)
[-1, 1, GCT, [1024]], # 26
[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
3.YOLOv5/YOLOv7魔术师专栏介绍
💡💡💡YOLOv5/YOLOv7魔术师,独家首发创新(原创),持续更新,最终完结篇数≥100+,适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络
💡💡💡重点:通过本专栏的阅读,后续你也可以自己魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
专栏介绍:
✨✨✨原创魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀小目标、遮挡物、难样本性能提升
🍉🍉🍉持续更新中,定期更新不同数据集涨点情况
本专栏提供每一步改进步骤和源码,开箱即用,在你的数据集下轻松涨点
通过注意力机制、小目标检测、Backbone&Head优化、 IOU&Loss优化、优化器改进、卷积变体改进、轻量级网络结合yolo等方面进行展开点
专栏链接如下:
https://blog.csdn.net/m0_63774211/category_12240482.html