一、前言
此示例演示如何使用 pix2pixHD 条件生成对抗网络 (CGAN) 从语义分割映射生成场景的合成图像。
Pix2pixHD [1] 由两个同时训练的网络组成,以最大限度地提高两者的性能。
-
生成器是一种编码器-解码器风格的神经网络,可从语义分割图生成场景图像。CGAN 网络训练生成器生成一个场景图像,鉴别器将其错误地分类为真实图像。
-
鉴别器是一个完全卷积的神经网络,它将生成的场景图像和相应的真实图像进行比较,并尝试将它们分别分类为假图像和真实图像。CGAN 网络训练鉴别器正确区分生成的图像和真实图像。
生成器和鉴别器网络在训练期间相互竞争。当两个网络都无法进一步改进时,训练就会收敛。
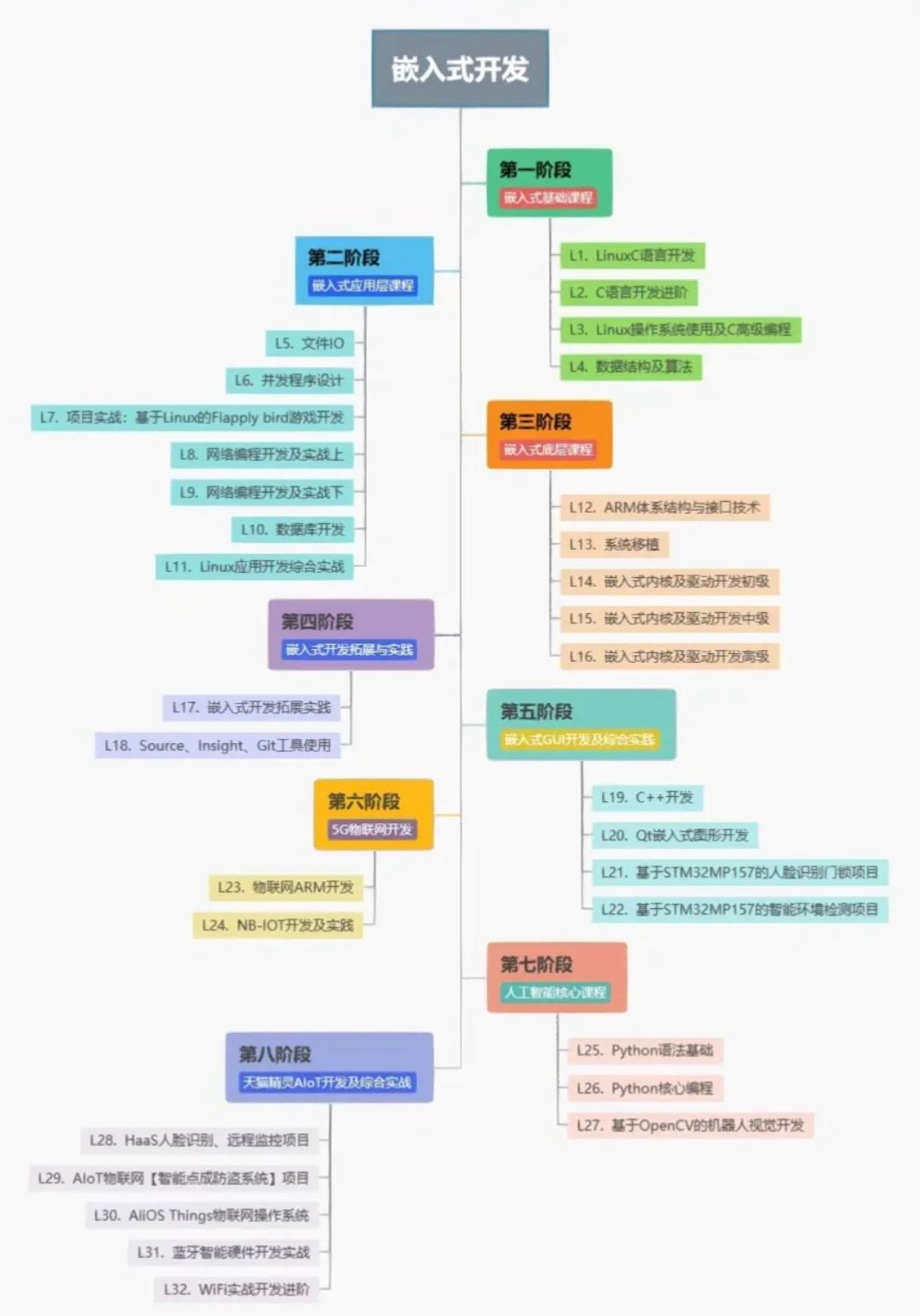
二、下载视频数据集
此示例使用剑桥大学的 CamVid 数据集 [2] 进行训练。该数据集是 701 张图像的集合,其中包含驾驶时获得的街道视图。该数据集为 32 个语义类提供像素标签,包括汽车、行人和道路。从这些 URL 下载 CamVid 数据集。下载时间取决于您的互联网连接。
三、预处理训练数据
创建一个图像数据存储,以将图像存储在CamVid数据集中。
使用辅助函数定义数据集中 32 个类的类名和像素标签 ID。使用辅助函数获取数据集的标准颜色图。创建像素标签数据存储以存储像素标签图像。
预览像素标签图像和相应的真实地面场景图像。使用 label2rgb 函数将标签从分类标签转换为 RGB 颜色,然后在蒙太奇中显示像素标签图像和真实图像。

使用帮助程序函数将数据划分为训练集和测试集。此函数作为支持文件附加到示例。帮助程序函数将数据拆分为 648 个训练文件和 32 个测试文件。
使用组合函数将像素标签图像和真实地面场景图像合并到单个数据存储中。通过将转换函数与帮助程序函数指定的自定义预处理操作一起使用来扩充训练数据。此帮助程序函数作为支持文件附加到示例。该函数执行以下操作:将真实数据缩放到范围 [-1, 1]。此范围与生成器网络中最终 tanhLayer(深度学习工具箱)的范围相匹配。将图像和标注调整为网络的输出大小(576 x 768 像素),分别使用双三次和最近邻缩减采样。使用 onehotencode(深度学习工具箱)函数将单通道分割图转换为 32 通道独热编码分割图。在水平方向上随机翻转图像和像素标签对。
在蒙太奇中预览独热编码分割图的通道。每个通道代表一个对应于唯一类像素的热图。

四、创建发电机网络
定义一个 pix2pixHD 发生器网络,该网络从深度一级的独热编码分割图生成场景图像。此输入具有与原始分割图相同的高度和宽度,以及与类相同的通道数。
显示网络架构。请注意,此示例显示了如何使用 pix2pixHD 全局生成器生成大小为 576 x 768 像素的图像。要创建以更高分辨率(如 1152 x 1536 像素甚至更高)生成图像的本地增强器网络,可以使用函数。本地增强器网络有助于以非常高的分辨率生成精细的细节。
五、创建鉴别器网络
定义将输入图像分类为真实 (1) 或虚假 (0) 的补丁 GAN 鉴别器网络。此示例使用不同输入尺度的两个鉴别器网络,也称为多尺度鉴别器。第一个比例与图像大小的大小相同,第二个比例是图像大小的一半。
判别器的输入是独热编码分割图和待分类场景图像的深度串联。将输入到鉴别器的通道数指定为标记类和图像颜色通道的总数。
指定第一个鉴别器的输入大小。将第二个鉴别器的输入大小指定为图像大小的一半,然后创建第二个补丁 GAN 鉴别器。可视化网络。
六、定义模型梯度和损失函数
帮助器函数计算生成器和鉴别器的梯度和对抗损失。
七、加载特征提取网络
此示例修改了预训练的 VGG-19 深度神经网络,以提取真实图像和生成图像在各个层的特征。这些多层特征用于计算发生器的感知损耗。
八、指定训练选项
指定 Adam 优化的选项。训练60个时代。为生成器和鉴别器网络指定相同的选项。
-
指定相等的学习率 0.0002。
-
使用 初始化尾随平均梯度和尾随平均梯度平方衰减率。
-
使用梯度衰减因子 0.5,梯度衰减因子平方为 0.999。
-
使用 1 的小批量大小进行训练。
九、训练网络
默认情况下,该示例使用帮助程序函数为 CamVid 数据集下载 pix2pixHD 发生器网络的预训练版本。
十、评估从测试数据生成的图像
这种经过训练的Pix2PixHD网络的性能是有限的,因为CamVid训练图像的数量相对较小。此外,某些图像属于图像序列,因此与训练集中的其他图像相关。为了提高Pix2PixHD网络的有效性,请使用具有大量没有相关性的训练图像的不同数据集来训练网络。
由于这些限制,此Pix2PixHD网络为某些测试图像生成比其他图像更逼真的图像。为了演示结果的差异,请比较第一个和第三个测试图像的生成图像。第一个测试图像的相机角度具有不常见的有利位置,其面向比典型训练图像更垂直于道路的视角。相比之下,第三个测试图像的相机角度具有沿道路面向的典型有利位置,并显示带有车道标记的两条车道。与第一个测试图像相比,网络为第三个测试图像生成逼真的图像的性能明显更好。
从测试数据中获取第一个地面实况场景图像。使用双三次插值调整图像大小。
从测试数据中获取对应的像素标签图像。使用最近邻插值调整像素标签图像的大小。创建将数据输入生成器的对象。如果支持的 GPU 可用于计算,则通过将数据转换为对象在 GPU 上执行推理。发电机网络的最后一层产生 [-1, 1] 范围内的激活。对于显示,将激活重新缩放到范围 [0, 1]。以蒙太奇形式显示 RGB 像素标签图像、生成的场景图像和真实场景图像。

十一、评估从自定义像素标签图像生成的图像
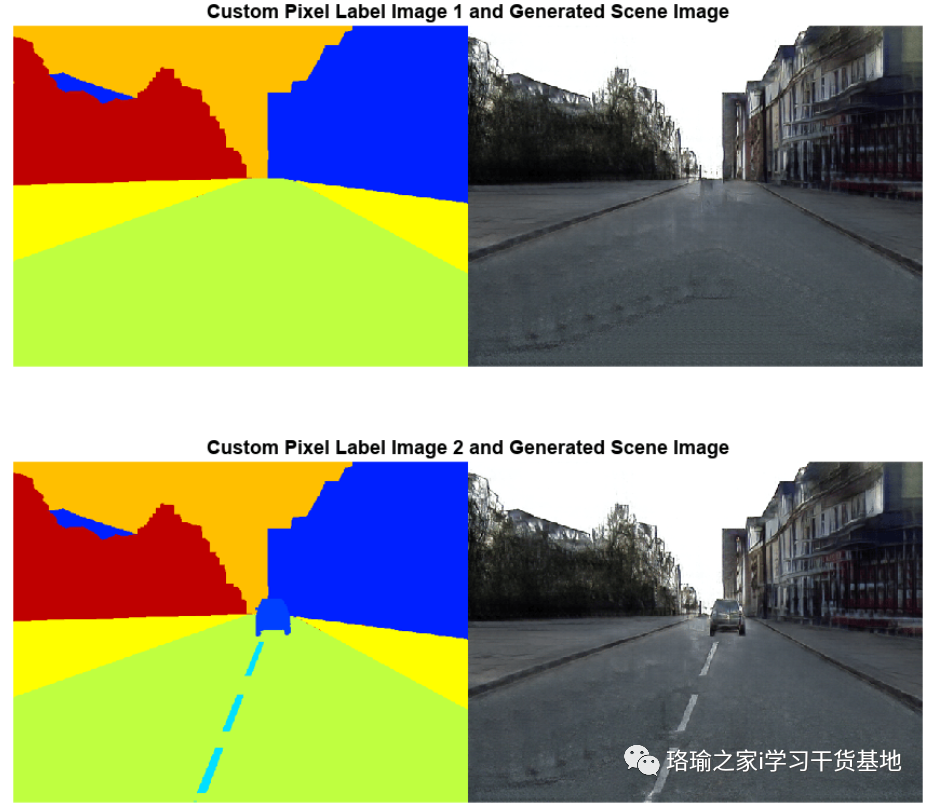
要评估网络对 CamVid 数据集之外的像素标签图像的泛化程度,请从自定义像素标签图像生成场景图像。像素标签图像作为支持文件附加到示例中。没有可用的地面实况图像。
创建一个像素标签数据存储,用于读取和处理当前示例目录中的像素标签图像。
对于数据存储中的每个像素标签图像,使用帮助程序函数生成场景图像。
十二、程序
使用Matlab R2022b版本,点击打开。(版本过低,运行该程序可能会报错)
程序下载:基于matlab使用深度学习从分割图生成图像资源-CSDN文库