第一部分 基于LangChain + ChatGLM-6B的本地知识库问答的应用实现
1.1 什么是LangChain:连接本地知识库与LLM的桥梁
作为一个 LLM 应用框架,LangChain 支持调用多种不同模型,提供相对统一、便捷的操作接口,让模型即插即用,这是其GitHub地址

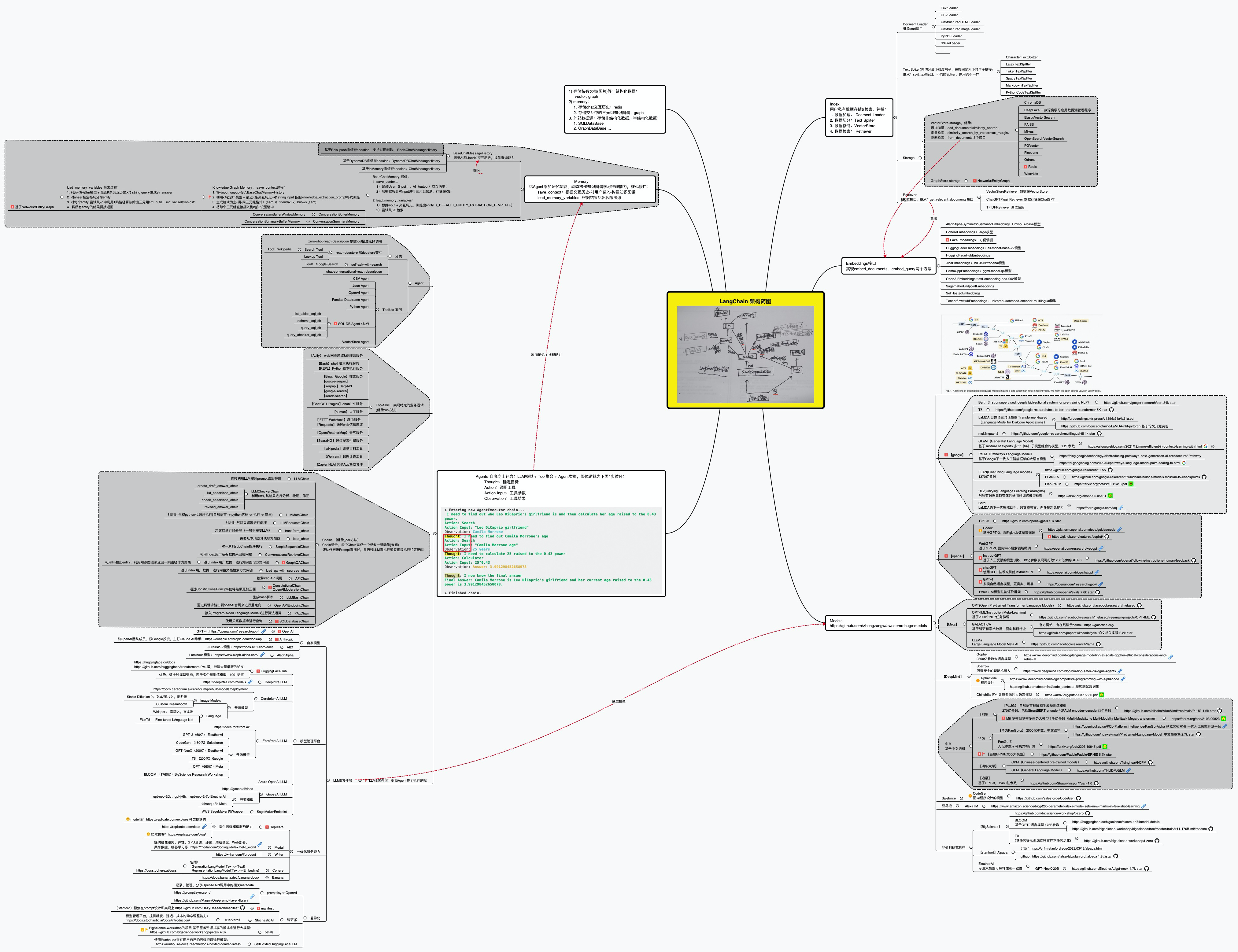
而一个LangChain应用是通过很多个组件实现的,LangChain主要支持6种组件:
- Models:模型,各种类型的模型和模型集成,比如GPT-4
- Prompts:提示,包括提示管理、提示优化和提示序列化
- Memory:记忆,用来保存和模型交互时的上下文状态
- Indexes:索引,用来结构化文档,以便和模型交互
- Chains:链,一系列对各种组件的调用
- Agents:代理,决定模型采取哪些行动,执行并且观察流程,直到完成为止
具体如下图所示(图源)
1.2 通过LangChain+LLM实现本地知识库问答的核心步骤
GitHub上有一个利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案,其项目地址为:GitHub - imClumsyPanda/langchain-ChatGLM: langchain-ChatGLM, local knowledge based ChatGLM with langchain | 基于本地知识库的 ChatGLM 问答
- 💡 受 GanymedeNil 的项目 document.ai,和 AlexZhangji 创建的 ChatGLM-6B Pull Request 启发,建立了全流程可使用开源模型实现的本地知识库问答应用。现已支持使用 ChatGLM-6B、 ClueAI/ChatYuan-large-v2 等大语言模型的接入
- ✅ 本项目中 Embedding 默认选用的是 GanymedeNil/text2vec-large-chinese,LLM 默认选用的是 ChatGLM-6B,依托上述模型,本项目可实现全部使用开源模型离线私有部署
⛓️ 本项目实现原理如下图所示

-
第一阶段:加载文件-读取文本-文本分割(Text splitter)
加载文件:这是读取存储在本地的知识库文件的步骤
读取文本:读取加载的文件内容,通常是将其转化为文本格式
文本分割(Text splitter):按照一定的规则(例如段落、句子、词语等)将文本分割def _load_file(self, filename): # 加载文件 if filename.lower().endswith(".pdf"): loader = UnstructuredFileLoader(filename) text_splitor = CharacterTextSplitter() docs = loader.load_and_split(text_splitor) else: loader = UnstructuredFileLoader(filename, mode="elements") text_splitor = CharacterTextSplitter() docs = loader.load_and_split(text_splitor) return docs -
第二阶段:文本向量化(embedding)-存储到向量数据库
文本向量化(embedding):这通常涉及到NLP的特征抽取,可以通过诸如TF-IDF、word2vec、BERT等方法将分割好的文本转化为数值向量def __init__(self, model_name=None) -> None: if not model_name: # use default embedding model self.embeddings = HuggingFaceEmbeddings(model_name=self.model_name)存储到向量数据库:文本向量化之后存储到数据库vectorstore(FAISS)
def init_vector_store(self): persist_dir = os.path.join(VECTORE_PATH, ".vectordb") print("向量数据库持久化地址: ", persist_dir) if os.path.exists(persist_dir): # 从本地持久化文件中Load print("从本地向量加载数据...") vector_store = Chroma(persist_directory=persist_dir, embedding_function=self.embeddings) # vector_store.add_documents(documents=documents) else: documents = self.load_knownlege() # 重新初始化 vector_store = Chroma.from_documents(documents=documents, embedding=self.embeddings, persist_directory=persist_dir) vector_store.persist() return vector_store其中load_knownlege的实现为
def load_knownlege(self): docments = [] for root, _, files in os.walk(DATASETS_DIR, topdown=False): for file in files: filename = os.path.join(root, file) docs = self._load_file(filename) # 更新metadata数据 new_docs = [] for doc in docs: doc.metadata = {"source": doc.metadata["source"].replace(DATASETS_DIR, "")} print("文档2向量初始化中, 请稍等...", doc.metadata) new_docs.append(doc) docments += new_docs return docments -
第三阶段:问句向量化
这是将用户的查询或问题转化为向量,应使用与文本向量化相同的方法,以便在相同的空间中进行比较 -
第四阶段:在文本向量中匹配出与问句向量最相似的top k个
这一步是信息检索的核心,通过计算余弦相似度、欧氏距离等方式,找出与问句向量最接近的文本向量def query(self, q): """Query similar doc from Vector """ vector_store = self.init_vector_store() docs = vector_store.similarity_search_with_score(q, k=self.top_k) for doc in docs: dc, s = doc yield s, dc -
第五阶段:匹配出的文本作为上下文和问题一起添加到prompt中
这是利用匹配出的文本来形成与问题相关的上下文,用于输入给语言模型。 -
第六阶段:提交给LLM生成回答
最后,将这个问题和上下文一起提交给语言模型(例如GPT系列),让它生成回答
比如知识查询(代码来源)class KnownLedgeBaseQA: def __init__(self) -> None: k2v = KnownLedge2Vector() self.vector_store = k2v.init_vector_store() self.llm = VicunaLLM() def get_similar_answer(self, query): prompt = PromptTemplate( template=conv_qa_prompt_template, input_variables=["context", "question"] ) retriever = self.vector_store.as_retriever(search_kwargs={"k": VECTOR_SEARCH_TOP_K}) docs = retriever.get_relevant_documents(query=query) context = [d.page_content for d in docs] result = prompt.format(context="\n".join(context), question=query) return result
如你所见,这种通过组合langchain+LLM的方式,特别适合一些垂直领域或大型集团企业搭建通过LLM的智能对话能力搭建企业内部的私有问答系统,也适合个人专门针对一些英文paper进行问答,比如比较火的一个开源项目:ChatPDF,其从文档处理角度来看,实现流程如下(图源):

1.3 langchain-ChatGLM项目的深入解读
再回顾一遍langchain-ChatGLM这个项目的架构图(图源)

你会发现该项目主要由以下七大模块组成
- models: llm的接⼝类与实现类,针对开源模型提供流式输出⽀持
- loader: 文档加载器的实现类
- textsplitter: 文本切分的实现类
- chains: 工作链路实现,如 chains/local_doc_qa 实现了基于本地⽂档的问答实现
- content:用于存储上传的原始⽂件
- vector_store:用于存储向量库⽂件,即本地知识库本体
- configs:配置文件存储
5.3.1 langchain-ChatGLM之chains文件夹下的代码解析
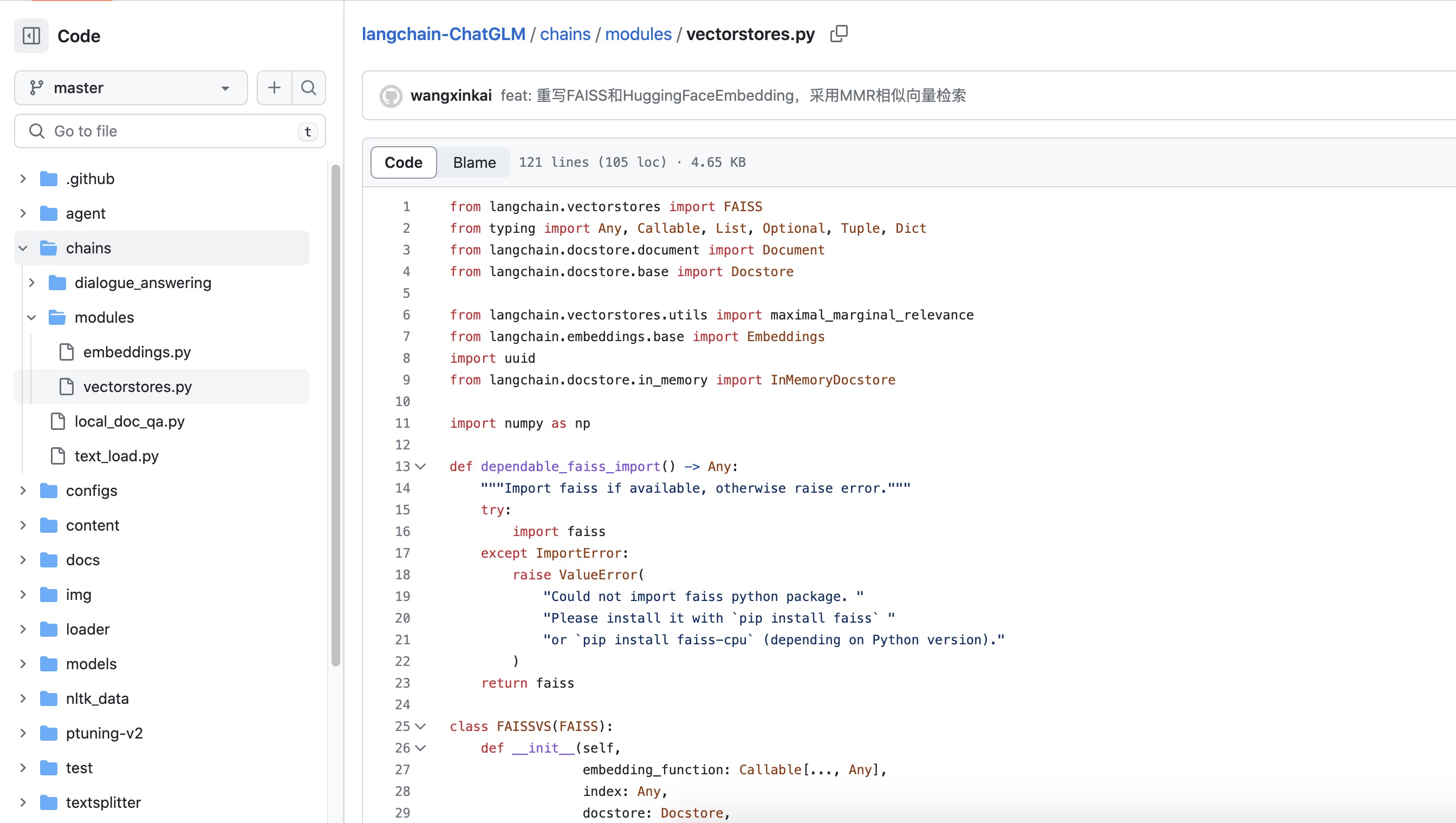
具体而言,上图中的FAISS是Facebook AI推出的一种用于有效搜索大规模高维向量空间中相似度的库。在大规模数据集中快速找到与给定向量最相似的向量是很多AI应用的重要组成部分,例如在推荐系统、自然语言处理、图像检索等领域
这个文件(xlangchain-ChatGLM/vectorstores.py at master · imClumsyPanda/langchain-ChatGLM · GitHub)的代码主要是关于FAISS (Facebook AI Similarity Search)的使用,以及一个FAISS向量存储类(FAISSVS,FAISSVS类继承自FAISS类)的定义,包含以下主要方法:
-
max_marginal_relevance_search_by_vector:通过给定的嵌入向量,使用最大边际相关性(Maximal Marginal Relevance, MMR)方法来返回相关的文档。MMR是一种解决查询结果多样性和相关性的算法。具体来说,它不仅要求返回的文档与查询尽可能相似,而且希望返回的文档集之间尽可能多样。 -
max_marginal_relevance_search:给定查询文本,首先将文本转换为嵌入向量,然后调用max_marginal_relevance_search_by_vector函数进行MMR搜索。 -
__from:这是一个类方法,用于从一组文本和对应的嵌入向量创建一个FAISSVS实例。该方法首先创建一个FAISS索引并添加嵌入向量,然后创建一个文档存储以存储与每个嵌入向量关联的文档
以上就是这段代码的主要内容,通过使用FAISS和MMR,它可以帮助我们在大量文档中找到与给定查询最相关的文档
在这个代码文件下(langchain-ChatGLM/local_doc_qa.py at master · imClumsyPanda/langchain-ChatGLM · GitHub)下
-
导入包和模块: 代码开始的部分是一系列的导入语句,导入了必要的 Python 包和模块,包括文件加载器,文本分割器,模型配置,以及一些 Python 内建模块和其他第三方库。
-
改写 HuggingFaceEmbeddings 类的哈希方法: 代码定义了一个名为
_embeddings_hash的函数,并将其赋值给HuggingFaceEmbeddings类的__hash__方法。这样做的目的是使HuggingFaceEmbeddings对象可以被哈希,即可以作为字典的键或者被加入到集合中。 -
载入向量存储器: 定义了一个名为
load_vector_store的函数,这个函数用于从本地加载一个向量存储器,返回FAISS类的对象。其中使用了lru_cache装饰器,可以缓存最近使用的CACHED_VS_NUM个结果,提高代码效率 -
文件树遍历:
tree函数是一个递归函数,用于遍历指定目录下的所有文件,返回一个包含所有文件的完整路径和文件名的列表。它可以忽略指定的文件或目录。 -
加载文件:
load_file函数根据文件后缀名选择合适的加载器和文本分割器,加载并分割文件 -
生成提醒:
generate_prompt函数用于根据相关文档和查询生成一个提醒。提醒的模板由prompt_template参数提供 -
分割列表:
seperate_list函数接受一个整数列表,返回一个列表的列表,其中每个子列表都包含连续的整数 -
向量搜索:
similarity_search_with_score_by_vector函数用于通过向量进行相似度搜索,返回与给定嵌入向量最相似的文档和对应的分数def similarity_search_with_score_by_vector( self, embedding: List[float], k: int = 4 ) -> List[Tuple[Document, float]]: # 通过输入向量在向量库中进行搜索,返回最相似的 k 个向量的索引和得分 scores, indices = self.index.search(np.array([embedding], dtype=np.float32), k) docs = [] # 用于存储找到的文档 id_set = set() # 用于存储找到的文档的 id store_len = len(self.index_to_docstore_id) # 记录向量库中的向量数量 # 遍历搜索结果的索引和得分 for j, i in enumerate(indices[0]): # 如果索引无效或者得分低于阈值,则忽略该结果 if i == -1 or 0 < self.score_threshold < scores[0][j]: continue _id = self.index_to_docstore_id[i] # 根据索引获取文档的 id doc = self.docstore.search(_id) # 根据 id 在文档库中查找文档 # 如果不需要对文档内容进行分块 if not self.chunk_conent: # 检查查找到的文档是否有效 if not isinstance(doc, Document): raise ValueError(f"Could not find document for id {_id}, got {doc}") doc.metadata["score"] = int(scores[0][j]) # 将得分记录到文档的元数据中 docs.append(doc) # 将文档添加到结果列表中 continue id_set.add(i) # 记录文档的索引 docs_len = len(doc.page_content) # 记录文档的长度 # 对找到的文档进行处理,寻找相邻的文档,尽可能将多个文档的内容组合在一起,直到达到设定的最大长度 for k in range(1, max(i, store_len - i)): break_flag = False for l in [i + k, i - k]: if 0 <= l < len(self.index_to_docstore_id): _id0 = self.index_to_docstore_id[l] doc0 = self.docstore.search(_id0) if docs_len + len(doc0.page_content) > self.chunk_size: break_flag = True break elif doc0.metadata["source"] == doc.metadata["source"]: docs_len += len(doc0.page_content) id_set.add(l) if break_flag: break # 如果不需要对文档内容进行分块,直接返回找到的文档 if not self.chunk_conent: return docs # 如果没有找到满足条件的文档,返回空列表 if len(id_set) == 0 and self.score_threshold > 0: return [] id_list = sorted(list(id_set)) # 将找到的文档的 id 排序 id_lists = seperate_list(id_list) # 将 id 列表分块 # 遍历分块后的 id 列表,将同一块中的文档内容组合在一起 for id_seq in id_lists: for id in id_seq: if id == id_seq[0]: _id = self.index_to_docstore_id[id] doc = self.docstore.search(_id) else: _id0 = self.index_to_docstore_id[id] doc0 = self.docstore.search(_id0) doc.page_content += " " + doc0.page_content # 检查组合后的文档是否有效 if not isinstance(doc, Document): raise ValueError(f"Could not find document for id {_id}, got {doc}") # 计算组合后的文档的得分 doc_score = min([scores[0][id] for id in [indices[0].tolist().index(i) for i in id_seq if i in indices[0]]]) doc.metadata["score"] = int(doc_score) # 将得分记录到文档的元数据中 docs.append(doc) # 将组合后的文档添加到结果列表中 torch_gc() # 清理 PyTorch 的缓存 return docs # 返回找到的文档列表
之后,定义了一个名为 LocalDocQA 的类,主要用于基于文档的问答任务。基于文档的问答任务的主要功能是,根据一组给定的文档(这里被称为知识库)以及用户输入的问题,返回一个答案,LocalDocQA 类的主要方法包括:
-
init_cfg():此方法初始化一些变量,包括将 llm_model(一个语言模型用于生成答案)分配给 self.llm,将一个基于HuggingFace的嵌入模型分配给 self.embeddings,将输入参数 top_k 分配给 self.top_k。 -
init_knowledge_vector_store():此方法负责初始化知识向量库。它首先检查输入的文件路径,对于路径中的每个文件,将文件内容加载到 Document 对象中,然后将这些文档转换为嵌入向量,并将它们存储在向量库中 -
one_knowledge_add():此方法用于向知识库中添加一个新的知识文档。它将输入的标题和内容创建为一个 Document 对象,然后将其转换为嵌入向量,并添加到向量库中 -
get_knowledge_based_answer():此方法是基于给定的知识库和用户输入的问题,来生成一个答案。它首先根据用户输入的问题找到知识库中最相关的文档,然后生成一个包含相关文档和用户问题的提示,将提示传递给 llm_model 来生成答案
且注意一点,这个函数调用了上面已经实现好的:similarity_search_with_scoredef get_knowledge_based_answer(self, query, vs_path, chat_history=[], streaming: bool = STREAMING): # 加载向量库,用于后续的相似度搜索 vector_store = load_vector_store(vs_path, self.embeddings) # 将自定义的 similarity_search_with_score_by_vector 方法赋给 FAISS 的 similarity_search_with_score 方法 FAISS.similarity_search_with_score_by_vector = similarity_search_with_score_by_vector # 设置向量库的 chunk_size 属性 vector_store.chunk_size = self.chunk_size # 设置向量库的 chunk_conent 属性 vector_store.chunk_conent = self.chunk_conent # 设置向量库的 score_threshold 属性 vector_store.score_threshold = self.score_threshold # 通过向量库对查询进行相似度搜索,返回最相关的文档及其得分 related_docs_with_score = vector_store.similarity_search_with_score(query, k=self.top_k) # 清理 PyTorch 的缓存 torch_gc() # 生成用于提问的提示语 prompt = generate_prompt(related_docs_with_score, query) # 通过 LLM(长语言模型)生成回答 for answer_result in self.llm.generatorAnswer(prompt=prompt, history=chat_history, streaming=streaming): # 获取回答的文本 resp = answer_result.llm_output["answer"] # 获取聊天历史 history = answer_result.history # 将聊天历史中的最后一项的提问替换为当前的查询 history[-1][0] = query # 组装回答的结果 response = {"query": query, "result": resp, "source_documents": related_docs_with_score} # 返回回答的结果和聊天历史 yield response, history -
get_knowledge_based_conent_test():此方法是为了测试的,它将返回与输入查询最相关的文档和查询提示 -
get_search_result_based_answer():此方法与 get_knowledge_based_answer() 类似,不过这里使用的是 bing_search 的结果作为知识库def get_search_result_based_answer(self, query, chat_history=[], streaming: bool = STREAMING): # 对查询进行 Bing 搜索,并获取搜索结果 results = bing_search(query) # 将搜索结果转化为文档的形式 result_docs = search_result2docs(results) # 生成用于提问的提示语 prompt = generate_prompt(result_docs, query) # 通过 LLM(长语言模型)生成回答 for answer_result in self.llm.generatorAnswer(prompt=prompt, history=chat_history, streaming=streaming): # 获取回答的文本 resp = answer_result.llm_output["answer"] # 获取聊天历史 history = answer_result.history # 将聊天历史中的最后一项的提问替换为当前的查询 history[-1][0] = query # 组装回答的结果 response = {"query": query, "result": resp, "source_documents": result_docs} # 返回回答的结果和聊天历史 yield response, history如你所见,这个函数和上面那个函数的主要区别在于,这个函数是直接利用搜索引擎的搜索结果来生成回答的,而上面那个函数是通过查询相似度搜索来找到最相关的文档,然后基于这些文档生成回答的
而这个bing_search则是如下定义的#coding=utf8 # 声明文件编码格式为 utf8 from langchain.utilities import BingSearchAPIWrapper # 导入 BingSearchAPIWrapper 类,这个类用于与 Bing 搜索 API 进行交互 from configs.model_config import BING_SEARCH_URL, BING_SUBSCRIPTION_KEY # 导入配置文件中的 Bing 搜索 URL 和 Bing 订阅密钥 def bing_search(text, result_len=3): # 定义一个名为 bing_search 的函数,该函数接收一个文本和结果长度的参数,默认结果长度为3 if not (BING_SEARCH_URL and BING_SUBSCRIPTION_KEY): # 如果 Bing 搜索 URL 或 Bing 订阅密钥未设置,则返回一个错误信息的文档 return [{"snippet": "please set BING_SUBSCRIPTION_KEY and BING_SEARCH_URL in os ENV", "title": "env inof not fould", "link": "https://python.langchain.com/en/latest/modules/agents/tools/examples/bing_search.html"}] search = BingSearchAPIWrapper(bing_subscription_key=BING_SUBSCRIPTION_KEY, bing_search_url=BING_SEARCH_URL) # 创建 BingSearchAPIWrapper 类的实例,该实例用于与 Bing 搜索 API 进行交互 return search.results(text, result_len) # 返回搜索结果,结果的数量由 result_len 参数决定 if __name__ == "__main__": # 如果这个文件被直接运行,而不是被导入作为模块,那么就执行以下代码 r = bing_search('python') # 使用 Bing 搜索 API 来搜索 "python" 这个词,并将结果保存在变量 r 中 print(r) # 打印出搜索结果
__main__部分的代码是 LocalDocQA 类的实例化和使用示例。它首先初始化了一个 llm_model_ins 对象,然后创建了一个 LocalDocQA 的实例并调用其 init_cfg() 方法进行初始化。之后,它指定了一个查询和知识库的路径,然后调用 get_knowledge_based_answer() 或 get_search_result_based_answer() 方法获取基于该查询的答案,并打印出答案和来源文档的信息。
chain这个文件夹下 还有最后一个项目文件(langchain-ChatGLM/text_load.py at master · imClumsyPanda/langchain-ChatGLM · GitHub),如下所示
import os
import pinecone
from tqdm import tqdm
from langchain.llms import OpenAI
from langchain.text_splitter import SpacyTextSplitter
from langchain.document_loaders import TextLoader
from langchain.document_loaders import DirectoryLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
#一些配置文件
openai_key="你的key" # 注册 openai.com 后获得
pinecone_key="你的key" # 注册 app.pinecone.io 后获得
pinecone_index="你的库" #app.pinecone.io 获得
pinecone_environment="你的Environment" # 登录pinecone后,在indexes页面 查看Environment
pinecone_namespace="你的Namespace" #如果不存在自动创建
#科学上网你懂得
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
#初始化pinecone
pinecone.init(
api_key=pinecone_key,
environment=pinecone_environment
)
index = pinecone.Index(pinecone_index)
#初始化OpenAI的embeddings
embeddings = OpenAIEmbeddings(openai_api_key=openai_key)
#初始化text_splitter
text_splitter = SpacyTextSplitter(pipeline='zh_core_web_sm',chunk_size=1000,chunk_overlap=200)
# 读取目录下所有后缀是txt的文件
loader = DirectoryLoader('../docs', glob="**/*.txt", loader_cls=TextLoader)
#读取文本文件
documents = loader.load()
# 使用text_splitter对文档进行分割
split_text = text_splitter.split_documents(documents)
try:
for document in tqdm(split_text):
# 获取向量并储存到pinecone
Pinecone.from_documents([document], embeddings, index_name=pinecone_index)
except Exception as e:
print(f"Error: {e}")
quit()1.3.2 langchain-ChatGLM之____文件夹下的代码解析
待更..
至于该项目的部署教程请见我司同事杜老师写的博客:Langchain-ChatGLM:基于本地知识库的问答
第二部分 LLM与知识图谱的结合
// 待更..