目录
🍯1.6 引用
🥝1. 引用的概念
🥝2. 引用的特性
1、引用在定义时必须初始化
2、一个变量可以有多个引用
3、引用一旦引用一个实体,再不能引用其他实体
🥝3. 常引用
1、取别名的原则:对原引用的读写权限只能缩小,不能放大。
2、常量取别名
3、转换与截断
🥝4. 使用场景与效率
1、用作函数形参(减少拷贝,提高效率)
2、做返回值
2.1 传值返回
2.2 传引用返回
🍯1.6 引用
🥝1. 引用的概念
引用就是给对象起另外一个名字,例如我的名字叫kiko,家里人给我取一个别名叫k,k和kiko都代表我这个对象;值得注意的是,定义了引用,程序就会把引用和该对象绑定在一起,并不是将该对象的值赋值给引用对象,我们可以通过下面几个例子来验证一下:
int main() { int a = 10; //先取了一个名字为a int& b = a; //b叫做a的引用,也叫做b是a的别名 int& c = b; //给别名b再取一个别名c int* p = &b; //p存放的是别名b的地址 return 0; }
由上述取地址可以得知,并不是将a的值赋值给了变量b,而是将a和b绑定在一起,b是a的别名,b就是a,因此当然其取地址的结果会是相同啦!同理,c是b的别名,b是a的别名,因此c也是a的别名,故a\b\c三个变量bind在一起,存储的都是10,具有相同的逻辑地址;
接下来我们看一个利用引用传参的例子:
void Swap(int& r1, int& r2) //形参r1与r2是实参x和y的别名,修改后的值可以直接传回 { int tmp = r1; r1 = r2; r2 = tmp; } int main() { int x = 1, y = 2; Swap(x, y); cout << "x=" << x << ";y=" << y << endl; return 0; }
以往我们Swap函数都是用指针接收,这里采用引用接收,好处是形参r1是x的别名,形参r2是y的别名,此时函数内交换r1和r2的值,其本质就是交换x和y的值,其结果相当于是可以直接传递回去的!为了更形象地体现这点,我们再写一个交换两个一级指针的例子:
#include<iostream> using namespace std; void swap(int& a, int& b) { int tmp = a; a = b; b = tmp; } void change_c(int** a, int** b) //交换两个指针的内容 //此时a是二级指针,我们想要修改一级指针的值,就要*a //可以类比我们交换两个整型值(0级指针),就要接收两个一级指针,要对其解引用 { int* tmp = *a; *a = *b; *b = tmp; } void change_cpp(int*& a, int*& b) //c++交换两个指针的内容,修改a的值会直接传递给dx //这里的int*表明接收的是一级指针,后面跟了一个&,表明用引用接收这个一级指针 //即这里相当于指针a是dx的别名,指针b是dy的别名 { int* tmp = a; a = b; b = tmp; } int main() { int x = 9, y = 8; swap(x, y); cout << "x=" << x << endl << "y=" << y << endl; int* dx = &x; int* dy = &y; cout << "dx=" << dx << endl << "dy=" << dy << endl; change_c(&dx, &dy); //想要修改一级指针的值,采用C语言的方法,必须要传二级指针 //想要修改两个int型的值(可视为0级指针),需要传一级指针 cout << "修改一轮后的地址\n" << "dx=" << dx << endl << "dy=" << dy << endl; change_cpp(dx, dy); cout << "修改二轮后的地址\n" << "dx=" << dx << endl << "dy=" << dy << endl; }
Q1:使用别名相比使用指针有什么好处呢?
A1:比如我们在创建一个不带哨兵位的单链表尾插时,由于头指针的值(*pphead)可能会发生改变,因此需要使用一个二级指针来接收头指针的地址(**pphead),其相关代码如下:
void SListPushBack(SListNode** pphead, DataType x) { assert(pphead); SListNode* newnode = BuySListNode(x); if (*pphead == NULL) //如果是空链表,即头指针指向NULL时 { *pphead = newnode; //头指针直接指向新结点即可 } else //如果不是空链表,即头指针指向的不是NULL时 { SListNode* tail = *pphead; //用一个指向空链表的结点的指针tail指向表头元素 while (tail->next != NULL) //让tail去找尾 { tail = tail->next; } tail->next = newnode; //将最后一个元素指向newnode即完成了尾插操作 } } int main() { struct SListNode* slist=NULL; SListPushBack(&slist,1); //传入头指针的地址 }但当我们使用C++时,我们可以不用二级指针来接收,但由于头指针的值(&pphead)会改变,修改头指针的别名本质就是在修改头指针的值。为了能将修改后的值传回去,就需要让一个指针通过引用的方式来接收这个别名,即使用SListNode*& pphead来进行接收。
void SListPushBack(SListNode* &pphead, DataType x) //slist是一个指针,因此SListPushBack要接收一个指针,所以SListNode* //这里用&pphead别名来代替slist,好处在于直接修改pphead的值可以传递给slist //不需要使用二级指针接收,然后通过修改pphead就能将修改的值传回给slist { assert(pphead); SListNode* newnode = BuySListNode(x); if (pphead == NULL) //如果是空链表,即头指针指向NULL时 { pphead = newnode; //头指针直接指向新结点即可 } else //如果不是空链表,即头指针指向的不是NULL时 { SListNode* tail = pphead; //用一个指向空链表的结点的指针tail指向表头元素 while (tail->next != NULL) //让tail去找尾 { tail = tail->next; } tail->next = newnode; //将最后一个元素指向newnode即完成了尾插操作 } } int main() { struct SListNode* slist=NULL; SListPushBack(slist,1); //传入头指针即可,因为此时的SListPushBack是用别名接收 //此时修改函数内的别名pphead,修改后的值可以传回给slist }
🥝2. 引用的特性
1、引用在定义时必须初始化
int main() { int a = 10; //先取了一个名字为a int& b = a; //引用b时将其初始化为a的别名 int e; int& f = e; cout << "&e: "<<&e <<endl << "&f: " << &f <<endl; return 0; }
需要注意的是,引用类型的初始值必须是一个对象,不能是常量;
2、一个变量可以有多个引用
说人话就是,一个对象可以取多个别名,例如kiko这个对象可以取一堆小名kiki、kaka等;
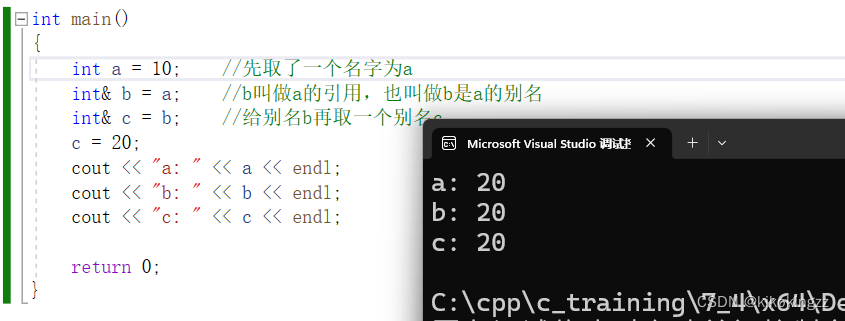
int main() { int a = 10; //先取了一个名字为a int& b = a; //b叫做a的引用,也叫做b是a的别名 int& c = b; //给别名b再取一个别名c c = 20; cout << "a: " << a << endl; cout << "b: " << b << endl; cout << "c: " << c << endl; return 0; }需要注意的是,引用是为一个已经存在的对象起的另一个名字,因此我们对引用的操作,其本质是对与之绑定的对象进行操作,如上面代码所示,我们修改了引用c的值,其本质就是修改了对象a的值,而由于b也是a的引用,因此输出引用b的值也会同a\c一样。
3、引用一旦引用一个实体,再不能引用其他实体
int main() { int a = 10; //先取了一个名字为a int& b = a; //引用b时将其初始化为a的别名 int c = 20; b = c; //该操作是赋值操作,将c的值赋值给b return 0; }
🥝3. 常引用
1、取别名的原则:对原引用的读写权限只能缩小,不能放大。
int main() { const int x = 20; int& y = x; //error:权限放大,由const int放大为int const int& z = x; //权限不变 int c = 30; const int& d = c; //权限的缩小,由int 缩小为 const int,d只能读不能写 cout << d << endl; d=20; //error:d是const int类型,不能进行写操作 }
2、常量取别名必须用const修饰
int main() { int& a = 10; //无法直接对常量取别名 const int& b = 10; //可以用const来对常量取别名 }
3、转换与截断
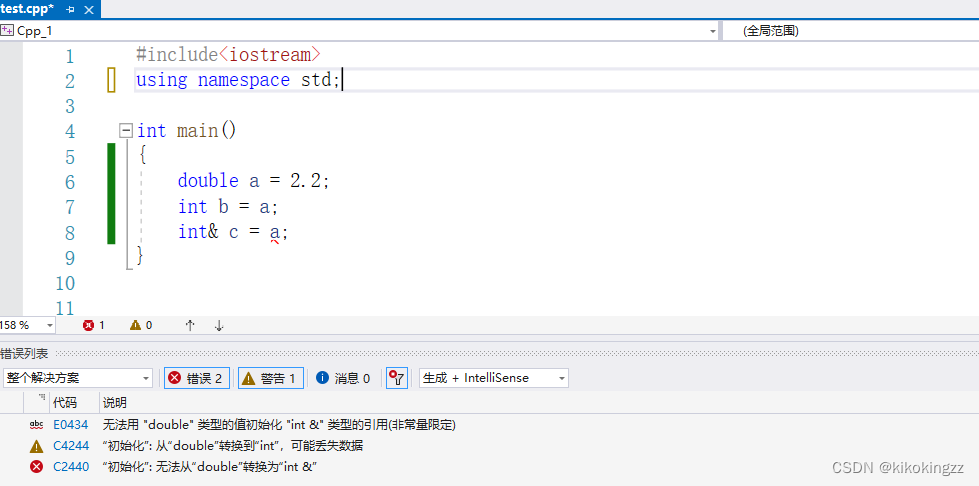
int main() { double c = 2.2; int& d = c; //error:无法直接用int型引用来对double类型变量取别名 const int& e = c; //可以用一个常引用来对double类型取别名,但是会发生截断 }
需要注意的是,此时的e并不是c的别名,而是临时变量的别名,浮点数c在赋值给e的过程中,会先将整数部分赋给一个临时变量,再由临时变量赋值给e,我们也可以通过下面这段代码检验一下:
int main() { double c = 2.2; const int& e = c; cout << "e的地址:" << &e << endl; cout << "c的地址:" << &c << endl; }
由上述结果可见,变量c的地址和引用e的地址并不相同,可见引用e并不是c的别名,而是c的临时变量的别名!
Q1:为什么使用int&不能通过编译,而使用int就能通过编译呢?
A1:这是因为临时变量具有常性,需要注意的是这里的别名c引用的并不是a,而是a的临时变量,临时变量具有常量性,而对于常量的引用我们在第二点中有说明要通过const修饰;但是对于 int b = a;该操作只是将a的值拷贝给b,b的修改并不会影响a的值。
关于临时变量可以再看一下这位博主所言:临时变量
🥝4. 使用场景与效率
1、用作函数形参(减少拷贝,提高效率)
#include<iostream> using namespace std; void Swap(int& x, int& y) //用作函数形参直接接收 { int tmp = x; x = y; y = tmp; } void Swap(double& x, double& y) { double tmp = x; x = y; y = tmp; } int main() { int a = 0, b = 2; Swap(a, b); double c = 3.14, d = 5.28; Swap(c, d);//使用函数重载加引用真的好爽呀! }以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
#include<iostream> #include<time.h> using namespace std; struct A { int a[10000]; }; void TestFunc1(struct A a) {} //传值 void TestFunc2(A& a){} //引用传参 void TestFunc3(A* a){} //传指针 void TestRefAndValue() { struct A x={0}; size_t begin1 = clock(); for (size_t i = 0; i < 1000000; ++i) TestFunc1(x); // 以值作为函数参数 size_t end1 = clock(); size_t begin2 = clock(); for (size_t i = 0; i < 1000000; ++i) TestFunc2(x); // 以引用作为函数参数 size_t end2 = clock(); size_t begin3 = clock(); for (size_t i = 0; i < 1000000; ++i) TestFunc3(&x); // 以指针作为函数参数 size_t end3 = clock(); // 分别计算两个函数运行结束后的时间 cout << "TestFunc1(A)-time:" << end1 - begin1 << endl; cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl; cout << "TestFunc3(A*)-time:" << end3 - begin3 << endl; }
通过结果可见使用数值进行传参花费的时间几乎是使用引用传参的720倍。
2、做返回值
2.1 传值返回
首先,我们先研究最普通的传值返回,在传值返回时,返回值中间会通过一个临时变量来辅助其将返回值送回。之所以需要这个临时变量是因为,大多数情况下返回值在出了作用域后就会被销毁,因此需要先将其保存在一个临时变量中,这样就算返回值在被调用函数中销毁了,还可以通过临时变量再赋值回去。
当然,上述的返回值n在出了count()函数的作用域后依然不会被销毁,因为n是一个静态变量,它不存放在栈中,而是存放于程序的全局变量区域,它的生存周期存在于程序的整个运行期;但是并不是每一个程序中返回值都是static类型,例如下面这种:
讲到这里,我们可以逐渐将本节的内容关联起来,我们可以通过下面的代码来验证一下,在返回值返回的时候,是否借助了临时变量的帮助:
修改方式也比较简单,我们可以用const来进行修饰即可:
2.2 传引用返回
接下来我们对函数加引用,对函数加引用相当于借助了一个别名来辅助返回,即返回的是n的别名,这里的ret就是count函数中n的别名。
为此,我们也可以检验一下ret和n的地址,看看它们是否是bind在一起的:
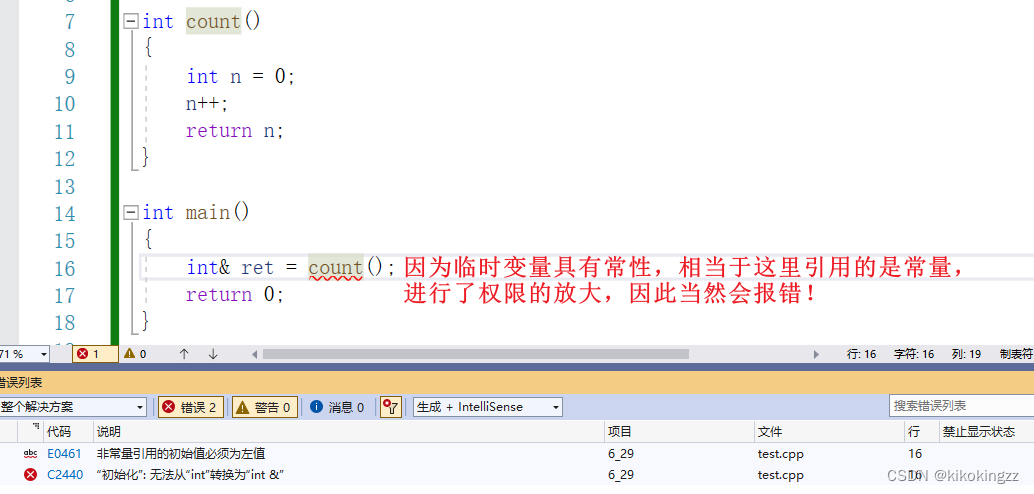
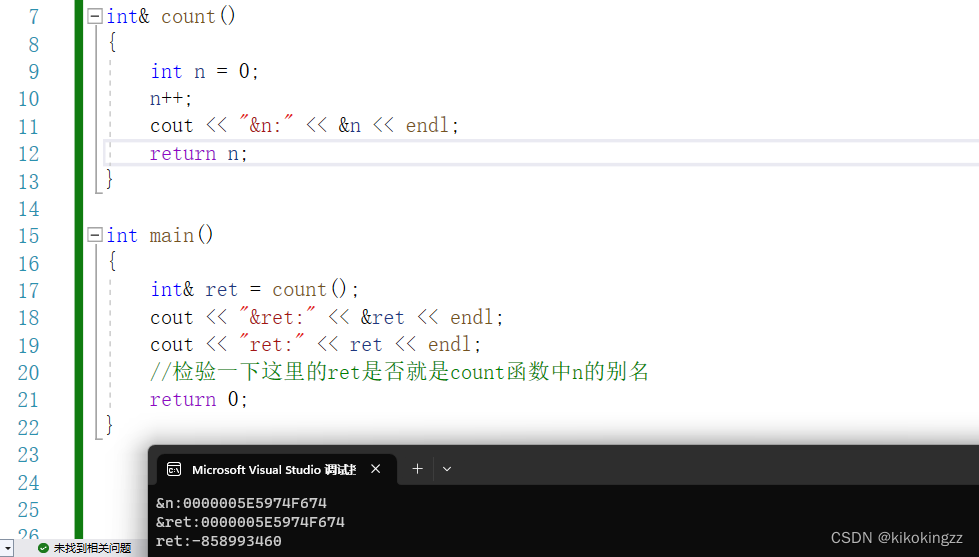
int& count() { int n = 0; n++; cout << "&n:" << &n << endl; return n; } int main() { int& ret = count(); cout << "&ret:" << &ret << endl; //检验一下这里的ret是否就是count函数中n的别名 return 0; }
可见ret的地址与n的地址一样,再次证明ret就是n的别名!
传值返回:会有一个拷贝; 传引用返回:没有这个拷贝,函数直接返回变量的别名;但是上面这个程序真的对吗?虽然我们能证明ret就是n的别名,但是count()函数运行完后,变量n已经被销毁了,我们即使可以通过别名ret得到n,但是这时属于访问越界了!我们这时去输出一下ret的值,它的结果将会是随机值:
因此想要解决这个问题,我们就要保证变量n不随着函数的结束而被销毁,我们就可以将其设定为静态变量,其代码如下:
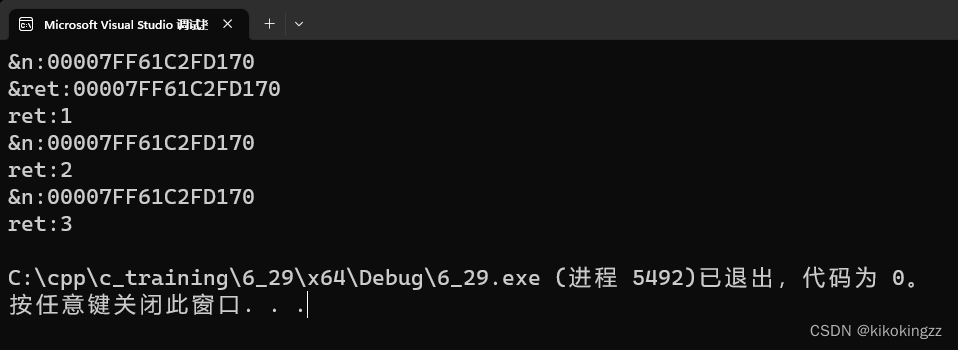
int& count() { static int n = 0; n++; cout << "&n:" << &n << endl; return n; } int main() { int& ret = count(); cout << "&ret:" << &ret << endl; cout << "ret:" << ret << endl; ret = count(); cout << "ret:" << ret << endl; ret = count(); cout << "ret:" << ret << endl; return 0; }
Q1:为什么上面这种情况必须在static情况下才能使用引用返回?
A1:由上图可见ret和n的地址相同,这就意味着ret就是n的别名;但是不使用静态变量static修饰时,当Count函数销毁了,n就销毁了,这时ret这个别名还存在吗?存在,但是会导致一个引用的野指针问题。
但如果我们将上述的int n = 0更改为 static int n = 0,这时就不会导致野指针。
当然,我们也可以使用传值返回,但是在传值返回的过程中会产生一个临时变量,如果这个变量小,这个临时变量会用寄存器替代,如果大,这个临时变量就不会被寄存器替代。
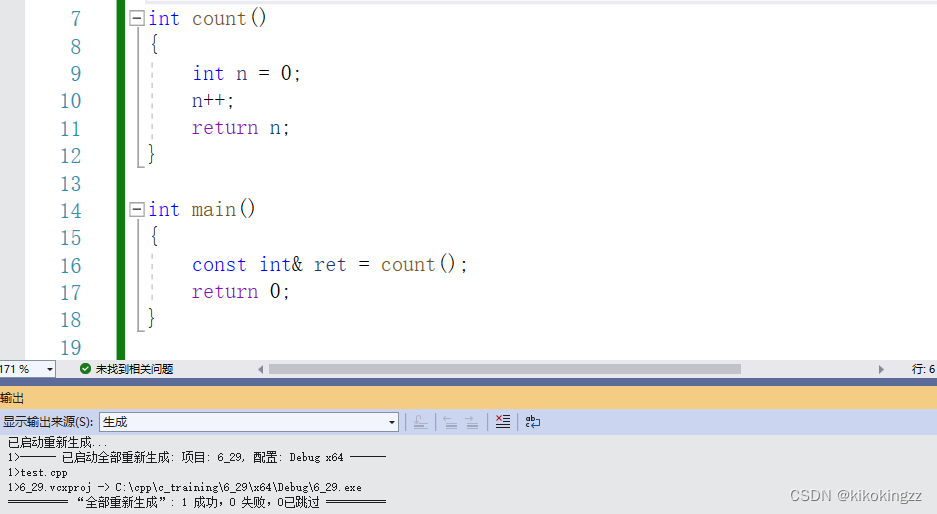
int Count() { static int n = 0; //静态变量的作用 n++; // ... return n; } int main() { int a = Count(); int& b = Count(); //error:Count的返回值是一个临时变量,所以需要使用常引用 const int& c = Count(); }
通过上述的比较我们得出了传值返回与传引用返回的区别:
- 传值返回:会有一个拷贝,即会在返回过程中创建一个临时变量。
- 传引用返回:没有这个拷贝了,不会开辟临时变量空间,函数返回的直接就是返回变量的别名;但并不是在任何场景下都可以使用,当返回值会随着函数销毁时,就无法使用传引用返回,必须使用传值返回,否则可能会出现越界问题。
考考你,下面的代码输出结果是什么?
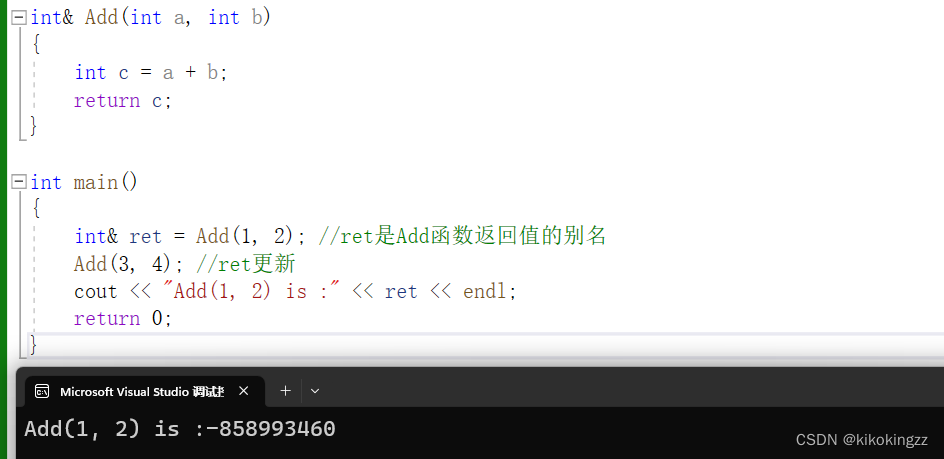
//情况1 int& Add(int a, int b) { int c = a + b; return c; } int main() { int& ret = Add(1, 2); //ret是Add函数返回值的别名 Add(3, 4); //ret更新 cout << "Add(1, 2) is :" << ret << endl; return 0; }对于情况1,由于未使用static修饰,按道理来说是不应该使用传引用返回的,可能会导致越界问题,因此这个ret可能会导致越界,所以这个输出值应当是随机值。
//情况2 int& Add(int a, int b) { static int c = a + b; return c; } int main() { int& ret = Add(1, 2); //ret是Add函数返回值的别名 Add(3, 4); cout << "Add(1, 2) is :" << ret << endl; return 0; }对于情况2,这里使用了static,限制了C这个初始化语句只能执行一次,也就是 c=a+b这个语句只能执行一次,之后如果再进入Add函数会直接跳过这一句,因此ret的值在进行Add(1,2)后就不再改变,其最后的输出值应当为3。
//情况3 int& Add(int a, int b) { static int c = 0; //这一句代码只会执行一次,就再也不执行了 c = a + b; return c; } int main() { int& ret = Add(1, 2); //ret是Add函数返回值的别名 Add(3, 4); //ret更新 cout << "Add(1, 2) is :" << ret << endl; return 0; }对于情况3,static仅仅限制 int c = 0;这个初始化语句只能执行一次,而 c = a + b 则可以执行多次,同时由于对c是static静态变量,因此可以不随函数销毁而销毁。ret的值会在执行Add(3,4)后发生更新,输出值变为7。
🥝5. 引用和指针的区别
1.引用没有独立空间,指针具有独立空间;
在语法概念上而言,引用就是一个对象的别名,没有独立空间,和其引用实体共用同一块空间,我们可以通过下面代码来检验一下:
int main() { int a = 10; int& b = a; int* c = &a; cout << "&a:" << &a << endl; cout << "&b:" << &b << endl; cout << "c:" << c << endl; cout << "&c:" << &c << endl; }
由上述结果可见,引用变量b的地址就是其对象a的地址,而指针c具有自己独立的空间。
2.sizeof(引用)结果是引用类型的大小,sizeof(指针)在同一硬件平台下结果固定;
通过第一条我们知道引用没有独立空间,那此时sizeof()对引用的结果是什么呢?我们不妨通过下面的代码来实验一下:
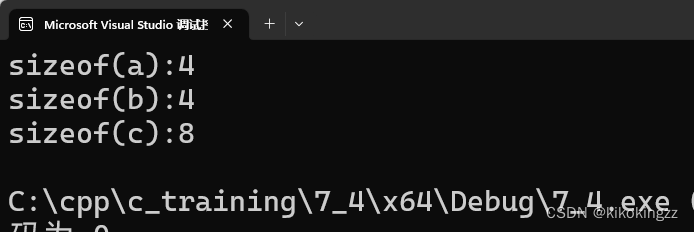
int main() { int a = 10; int& b = a; int* c = &a; cout << "sizeof(a):" << sizeof(a) << endl; cout << "sizeof(b):" << sizeof(b) << endl; cout << "sizeof(c):" << sizeof(c) << endl; }
通过上面的结果可知,虽然引用b不具有独立的空间,但其sizeof()仍可运算,此时sizeof的含义不同:
- sizeof(引用):结果为引用类型的大小,如果引用类型是int,则结果为4字节;
- sizeof(指针):表示指针地址空间所占字节个数,如果是32位机器,结果为4字节;如果是64位机器(如上图),结果为8字节;
3.引用和指针在底层是一样方式实现的,即引用时按照指针方式实现的;
int main() { int a = 10; int& ra = a; //语法而言:ra是a的别名,没有额外开空间 ra = 20; //底层角度:它们是一样方式实现的 int* pa = &a; //语法角度:pa存储a的地址,pa开了4/8字节空间 *pa = 20; //底层角度:它们是一样方式实现的 return 0; }
引用和指针的不同点小总结
- 引用概念上定义一个变量的别名,指针存储一个变量地址;
- 引用在定义时必须初始化,指针没有要求;
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体;
- 没有NULL引用,但有NULL指针;
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占 4个字节);
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小;
- 有多级指针,但是没有多级引用;
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理;
- 引用比指针使用起来相对更安全;