*免责声明:
1\此方法仅提供参考
2\搬了其他博主的操作方法,以贴上路径.
3*
场景一: Attention is all you need
场景二: VIT
场景三: Swin v1
场景四: Swin v2
场景五: SETR
场景六: TransUNet
场景七: SegFormer
场景八: PVT
场景九: Segmeter
…
场景一:Attention is all you need
论文地址
强推–》国外学者的解读
强推–》国内学者对国外学者解读的翻译
1.1 概述
强推先看–> 《场景三:seq2seq与attention机制》

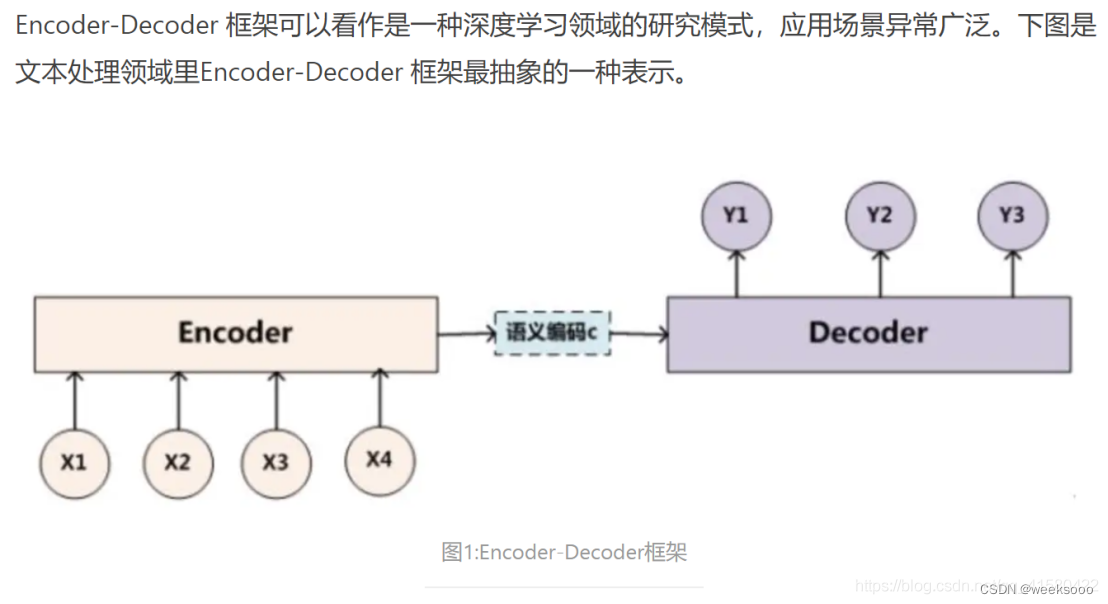



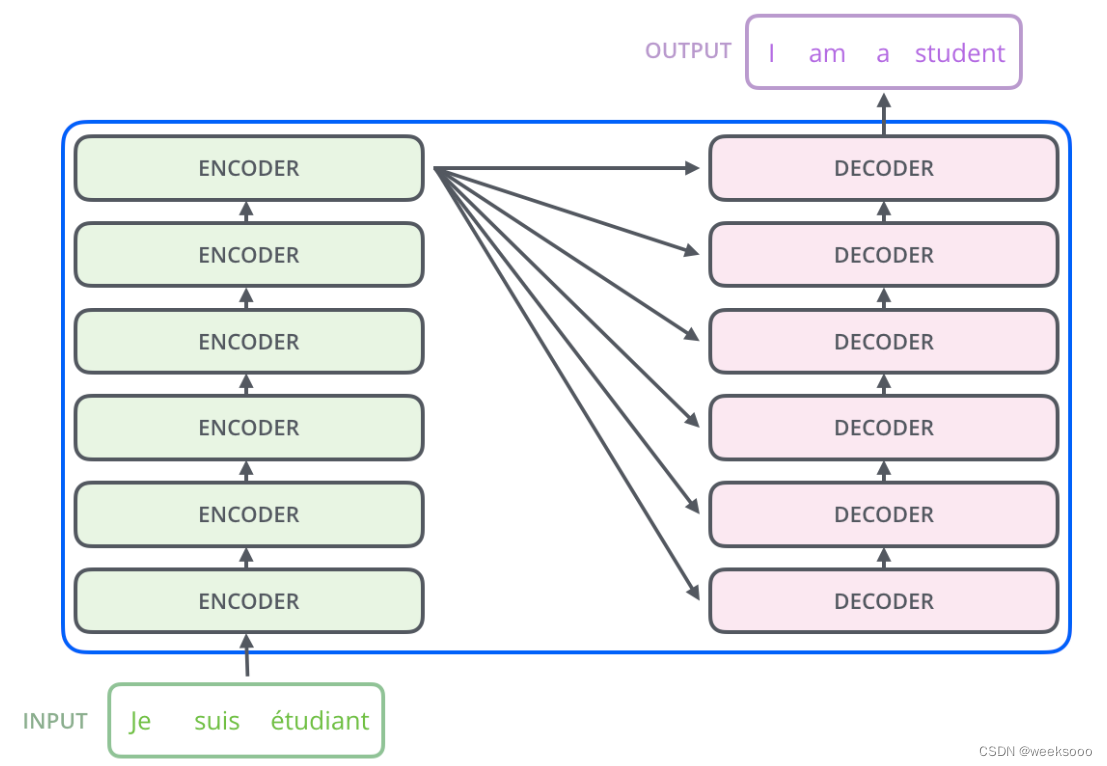
1.2 transformer网络结构
细讲 | Attention Is All You Need

1.3 encoder









1.4 decoder
tarnsformer里面的decoder阶段的mask的作用与数学描述

1.5 输入端 (位置编码)


1.6 encoder与decoder的交互形式

…
场景二: VIT (Vision Transformer)
论文地址
Vision Transformer详解
ViT(Vision Transformer)解析
【机器学习】详解 Vision Transformer (ViT)
1.1 概述
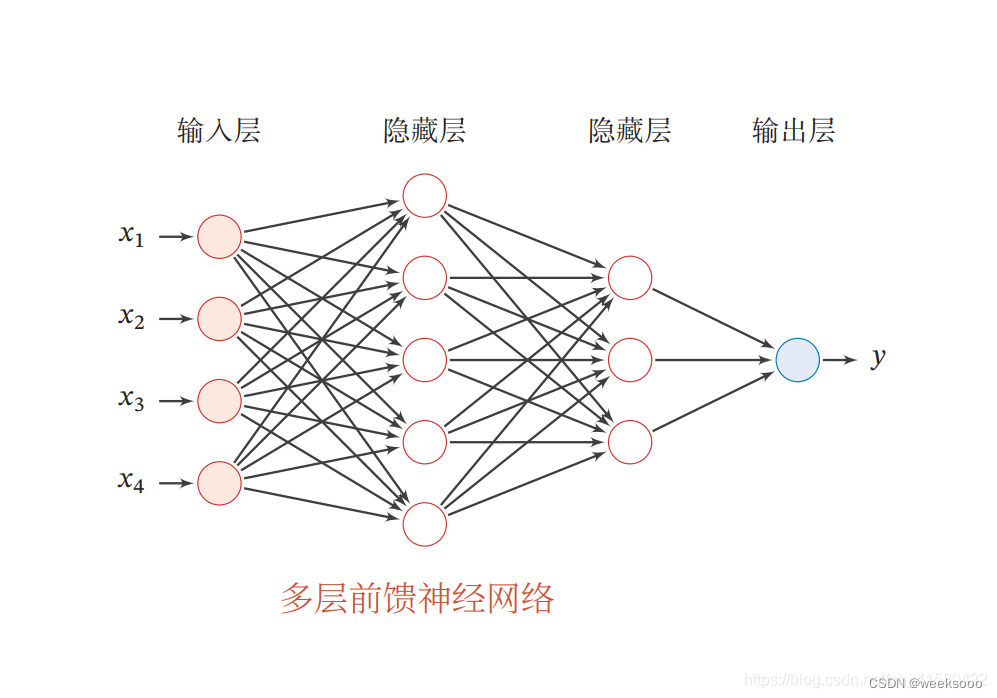
MLP更多请看–> 《场景六:神经网络》


1.2 VIT网络结构

1.3 输入端编码处理
图片编码

用于分类的class编码

位置编码



1.4 encoder
强推–>transformer系列基础知识先导篇
【正则化】DropPath/drop_path用法

1.5 MLP Head
强推–>MLP更多知识可查看 《场景五1.4 与场景六》

1.6 ViT-B/16结构图

1.7 hybrid model (cnn与transformer结合的混合模型)



1.8 参数调节

1.9 实验结果



…
场景三:swin v1
Swin Transformer 论文地址
github工程项目地址
参考一:Swin-Transformer网络结构详解
参考二:论文详解:Swin Transformer
参考三:详解Swin Transformer核心实现,经典模型也能快速调优
1.1 前言

1.2 网络结构


1.3 输入端编码处理

1.4 W-MSA ( Window Mutil-head Attention )




1.5 SW-MSA ( Shifted Window Mutil-head Attention)



1.6 Patch Merging

1.7 相对位置偏置





1.8 模型结构图


1.9 性能



…
…
you did it