目录
- 一、 引言
- 二、问题
- 2.1 什么是Map
- 2.2 使用Map的好处
- 2.3 Map的底层原理
- 2.4 Key和Value的含义
- 2.5 Key值为什么不能重复
- 2.6 Key值和Hash的关系
- 三、 HashMap
- 3.1 初始化HashMap
- 3.2 添加和获取元素
- 3.3 遍历HashMap
- 3.4 删除元素
- 3.5实现原理
- ①HashMap的put()方法
- ②HashMap的get()方法
- 四、 TreeMap
- 4.1 初始化TreeMap
- 4.2 添加和获取元素
- 4.3 遍历TreeMap
- 4.4 删除元素
- 五、 LinkedHashMap
- 5.1 初始化LinkedHashMap
- 5.2 添加和获取元素
- 5.3 遍历LinkedHashMap
- 5.4 删除元素
- 六、二维表总结
一、 引言
Map是Java中常用的数据结构,它提供了一种键值对的存储方式,可以根据键来快速访问值。在本篇文章中,我将学习Java中的Map数据结构
问题是最好的老师,我将从至少以下几个方面阐述,什么是map、使用Map有什么好处、Map的底层原理、map中的key和value分别是什么、以及Map的Key值为什么不能重复、Map中的key值和Hash有什么关系。
以及对HashMap、TreeMap和LinkedHashMap三种常用的Map实现类进行了解。我将逐步解析它们的初始化、添加和获取元素、遍历和删除元素等功能,最后给出一个二维表进行结构化。
二、问题
2.1 什么是Map
Map是Java中的一个接口,它代表了一种键值对的映射关系。它允许我们通过Key来访问Value。在Map中,每个Key都是唯一的,而且与该Key对应的Value是一一对应的关系。
2.2 使用Map的好处
使用Map有很多好处,以下是其中几个重要的好处:
快速访问:通过给定的Key,可以快速地访问对应的Value,无需遍历整个集合。
灵活性:Map不仅可以存储基本数据类型的值,还可以存储自定义对象作为Value,这使得它非常灵活。
动态增长:Map的大小可根据需要动态增长,不需要事先指定容量。
数据分类:Map可以用于对数据进行分类、分组和存储,为后续的检索和处理提供了便利。
2.3 Map的底层原理
在Java中,常用的Map实现类有HashMap、TreeMap和LinkedHashMap。这些实现类在底层的数据组织方式和查找算法上略有不同。
HashMap使用散列表(Hash Table)作为底层数据结构,它通过把Key的Hash值映射到一个数组索引上,并使用链地址法解决Hash冲突。
TreeMap使用红黑树(Red-Black Tree)作为底层数据结构,它会对Key进行排序,并且可以提供有序的遍历。
LinkedHashMap继承自HashMap,它在HashMap的基础上通过维护一个双向链表来保证插入顺序或访问顺序。
根据实际情况选择不同的Map实现类,可以根据需求来平衡时间复杂度和空间复杂度。
下面将会了解这几个实现类的一些方法。
2.4 Key和Value的含义
在Map中,Key用于唯一标识一个键值对,它相当于数据的索引。Value则是与Key相关联的数据。对于同一个Key,只能有一个对应的Value,但是不同的Key可以对应不同的Value。
例如,我们可以创建一个Map,将每个人的名字作为Key,将他们的年龄作为Value。通过Key,我们可以快速地查找到对应的年龄。
2.5 Key值为什么不能重复
Map中要求每个Key都是唯一的,这是因为Map需要通过Key来定位和访问Value。如果出现多个相同的Key,Map无法确定应该返回哪个Value。
当我们使用put方法向Map中添加键值对时,如果Key已经存在,新的Value将会覆盖旧的Value。因此,Key的唯一性保证了在Map中定位Value的准确性。
2.6 Key值和Hash的关系
Java中的HashMap和LinkedHashMap是通过计算Key的Hash值来确定Key在底层数组中的位置的。
在HashMap中,当我们向其中插入一个键值对时,HashMap会首先通过Key的hashCode()方法计算Key的哈希值。然后,HashMap会根据哈希值对数组的长度取模,得到Key在底层数组中的索引位置。如果有多个Key的哈希值映射到同一个索引位置,则HashMap会使用链表或红黑树来处理冲突。
而在LinkedHashMap中,它在HashMap的基础上通过维护一个双向链表来保证插入顺序或访问顺序。HashMap中的Key与链表节点相互关联,实现了按照插入顺序或访问顺序迭代Map的键值对。
由此可见,Hash在Map中起到了定位Key的作用,通过计算Key的哈希值,可以快速地定位到Key在底层数组中的位置,从而提高了查找效率。同时,Hash值的唯一性也保证了Key在Map中的唯一性。
由于Hash值是通过哈希函数计算得出的,存在一定的碰撞概率。因此,在使用自定义对象作为Key时,我们需要重写hashCode()方法来确保生成的Hash值能够准确地表示对象的唯一性,同时也要重写equals()方法来处理碰撞冲突时的比较逻辑。这样可以保证不同的Key对象即使在Hash值相同的情况下,也可以正确地进行比较和查找。
三、 HashMap
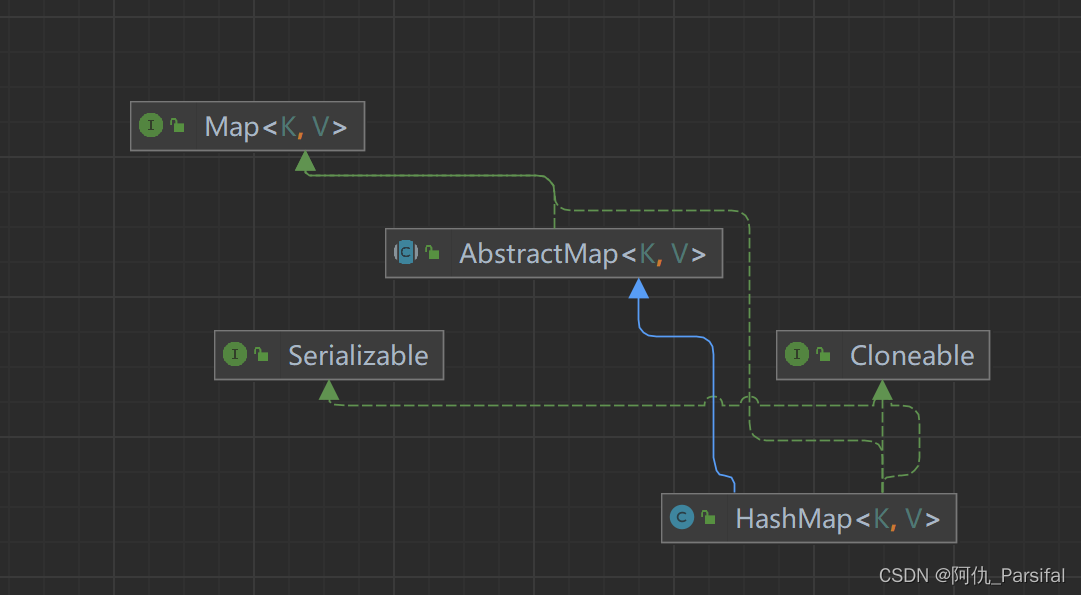
3.1 初始化HashMap
在Java中,我们可以使用HashMap类来创建一个HashMap对象。下面是一些常见的初始化方法:
使用默认构造函数:
HashMap<String, Integer> map = new HashMap<>();
指定初始容量:
HashMap<String, Integer> map = new HashMap<>(16);
指定初始容量和加载因子:
HashMap<String, Integer> map = new HashMap<>(16, 0.75f);
3.2 添加和获取元素
向HashMap中添加元素时,我们需要使用put()方法,并提供键和值。下面是一个示例:
HashMap<String, Integer> map = new HashMap<>();
map.put("apple", 5);
map.put("banana", 10);
map.put("orange", 8);
获取HashMap中的元素可以使用get()方法,并提供键。下面是一个示例:
int appleCount = map.get("apple");
System.out.println("苹果数量:" + appleCount);
3.3 遍历HashMap
遍历HashMap可以使用多种方式,比如使用迭代器、for-each循环或使用Java 8的Lambda表达式。下面是一个使用迭代器遍历HashMap的示例:
Iterator<Map.Entry<String, Integer>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
System.out.println("水果:" + entry.getKey() + ",数量:" + entry.getValue());
}
3.4 删除元素
从HashMap中删除元素可以使用remove()方法,并提供键。下面是一个示例:
map.remove("banana");
3.5实现原理
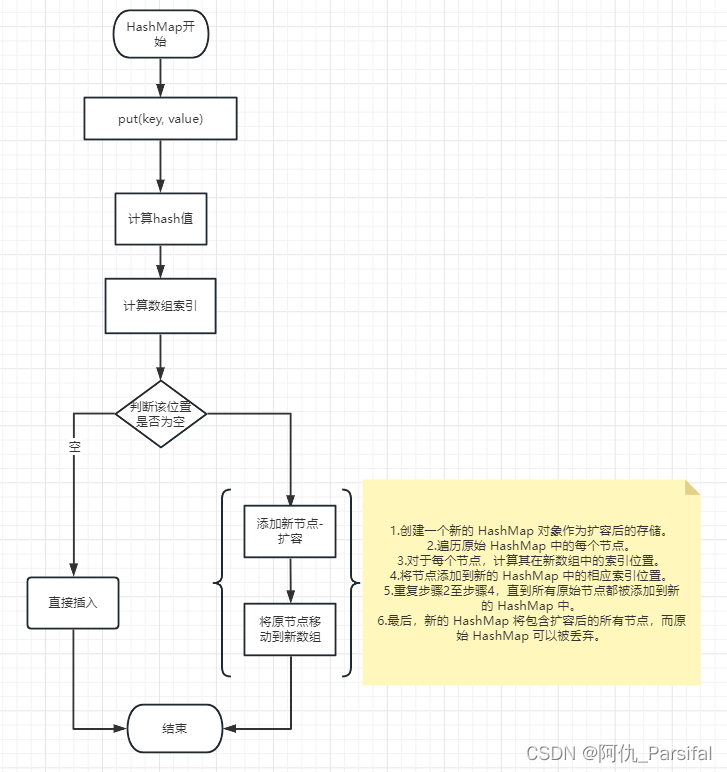
①HashMap的put()方法
实现原理如下:
首先,HashMap将要存储的键值对通过哈希函数进行处理,得到一个哈希码(hash code)。
接下来,HashMap将根据哈希码找到该键值对应在内部数组中的索引位置。
如果该位置上没有其他键值对存在,那么直接将新的键值对存储在该位置上即可。
如果该位置上已经存在其他键值对,那么HashMap将采用链表或者红黑树的方式来处理冲突。它会在该位置上的键值对链表(或树)中依次比较存储的键的哈希码和键值是否与要存储的键值对相等。
如果找到了相等的键,HashMap会替换该键对应的值。
如果没有找到相等的键,HashMap会将新的键值对添加到链表(或树)的末尾。
②HashMap的get()方法
它的实现原理如下:
首先,HashMap通过哈希函数计算键的哈希码。
接下来,HashMap将根据哈希码找到该键对应在内部数组中的索引位置。
如果该位置上没有键值对,那么表示该键不存在于HashMap中,返回null。
如果该位置上存在键值对,HashMap会遍历链表(或树),比较存储的键的哈希码和键值是否与要获取的键值对相等。
如果找到了相等的键,HashMap返回该键对应的值。
如果遍历完链表(或树)都没有找到相等的键,那么表示该键不存在于HashMap中,返回null。
通过这种方式,HashMap可以高效地实现put()和get()方法,快速存储和查找键值对,提供了快速的数据访问能力。
四、 TreeMap
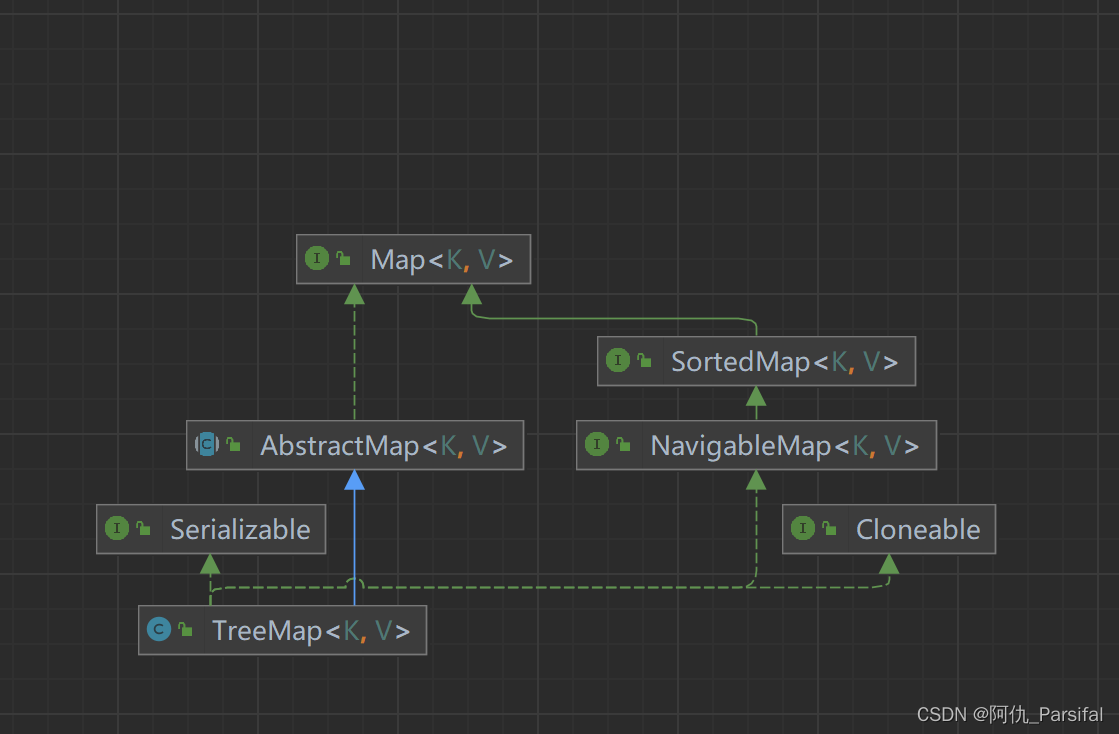
4.1 初始化TreeMap
与HashMap类似,我们可以使用TreeMap类来创建一个TreeMap对象。下面是一些常见的初始化方法:
使用默认构造函数:
TreeMap<String, Integer> map = new TreeMap<>();
使用Comparator初始化:
TreeMap<String, Integer> map = new TreeMap<>(Comparator.reverseOrder());
4.2 添加和获取元素
添加和获取元素的方式与HashMap类似,使用put()方法添加元素,使用get()方法获取元素。
map.put("apple", 1);
map.put("banana", 2);
map.put("orange", 3);
int value = map.get("apple");
System.out.println(value); // 输出:1
4.3 遍历TreeMap
遍历TreeMap的方法与HashMap类似,可以使用迭代器、for-each循环或Lambda表达式。
以下是使用for-each循环遍历TreeMap的例子:
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
int value = entry.getValue();
System.out.println(key + " : " + value);
}
4.4 删除元素
从TreeMap中删除元素的方式与HashMap类似,使用remove()方法。
map.remove("banana");
五、 LinkedHashMap
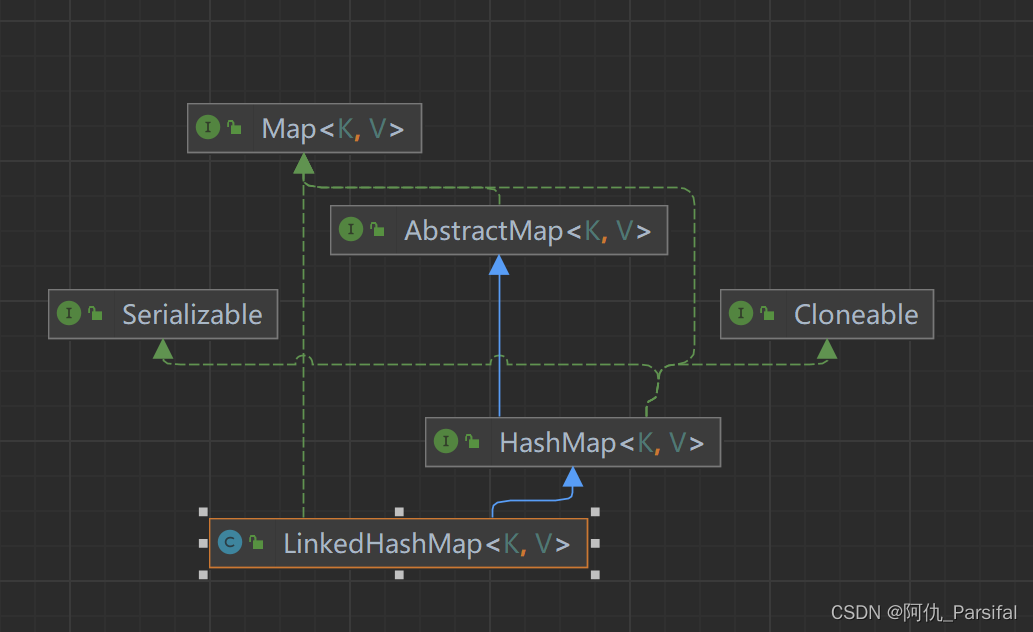
5.1 初始化LinkedHashMap
LinkedHashMap是一个有序的Map实现类,保留了元素的插入顺序。初始化方式与HashMap类似。
使用默认构造函数:
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
5.2 添加和获取元素
添加和获取元素的方式与HashMap类似,使用put()方法添加元素,使用get()方法获取元素。
map.put("apple", 1);
map.put("banana", 2);
map.put("orange", 3);
int value = map.get("apple");
System.out.println(value); // 输出:1
5.3 遍历LinkedHashMap
遍历LinkedHashMap的方法与HashMap类似,可以使用迭代器、for-each循环或Lambda表达式。
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
int value = entry.getValue();
System.out.println(key + " : " + value);
}
5.4 删除元素
从LinkedHashMap中删除元素的方式与HashMap类似,使用remove()方法。
map.remove("banana");
六、二维表总结
| 维度 | HashMap | TreeMap | LinkedHashMap |
|---|---|---|---|
| 底层实现 | 哈希表 | 红黑树 | 哈希表+链表 |
| 插入顺序 | 无序 | 无序(基于键的自然排序或自定义排序) | 保持插入顺序 |
| 查找效率 | O(1) | O(log n) | O(1) |
| 迭代顺序 | 无序 | 有序(基于键的自然排序或自定义排序) | 保持插入顺序或访问顺序 |
| 键的唯一性 | 允许null键和null值 | 允许null键和null值 | 允许null键和null值 |
| 性能 | 在大多数情况下,具有良好的性能 | 相比HashMap,由于排序逻辑,稍稍慢一些 | 相比HashMap,由于维护链表,稍稍慢一些 |
| 空间需求 | 相对较低(无序) | 相对较高(有序) | 相对较高(保持插入顺序或访问顺序) |
我们可以看到HashMap、TreeMap和LinkedHashMap都是非常有用和灵活的Map实现类,每种都适用于不同的使用场景。当我们需要一个无序、高效的Map时,可以选择HashMap;当我们需要一个有序的Map时,可以选择TreeMap;而当我们需要一个保留插入顺序、支持特殊操作的Map时,可以选择LinkedHashMap。
因此,当我们需要使用Map数据结构时,我们可以根据具体需求选择合适的数据结构来解决问题。