如果你看了上一篇《Go语言开发者的Apache Arrow使用指南:数据类型》[1]中的诸多Go操作arrow的代码示例,你很可能会被代码中大量使用的Retain和Release方法搞晕。不光大家有这样的感觉,我也有同样的feeling:**Go是GC语言[2],为什么还要借助另外一套Retain和Release来进行内存管理呢**?
在这一篇文章中,我们就来探索一下这个问题的答案,并看看如何使用Retain和Release,顺便再了解一下Apache Arrow的Go实现原理。
注:本文的内容基于Apache Arrow Go v13版本(go.mod中go version为v13)的代码。
1. Go Arrow实现中的builder模式
看过第一篇文章中的代码的童鞋可能发现了,无论是Primitive array type还是嵌套类型的诸如List array type,其array的创建套路都是这样的:
首先创建对应类型的Builder,比如array.Int32Builder;
然后,向Builder实例中append值;
最后,通过Builder的NewArray方法获得目标Array的实例,比如array.Int32。
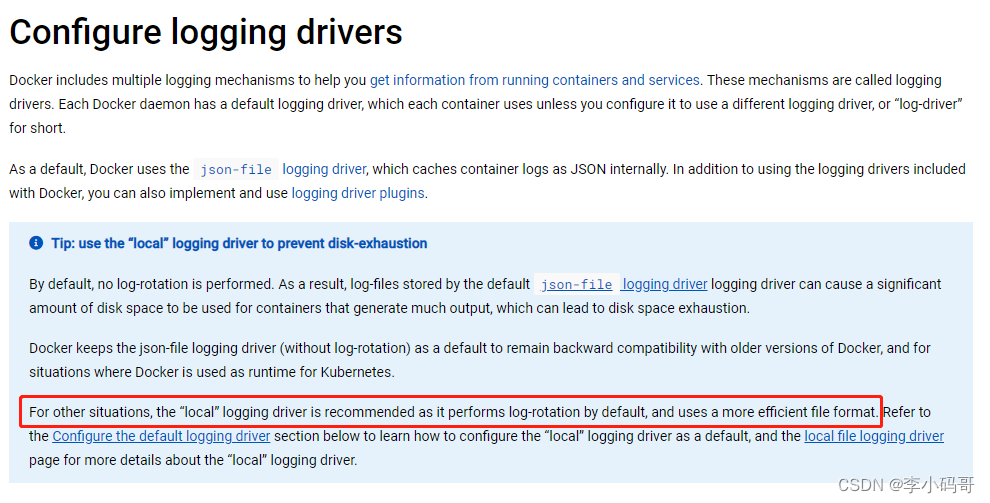
据说这个builder模式是参考了Arrow的C++实现。这里将Go的builder模式中各个类型之间的关系以下面这幅示意图的形式呈现一下:
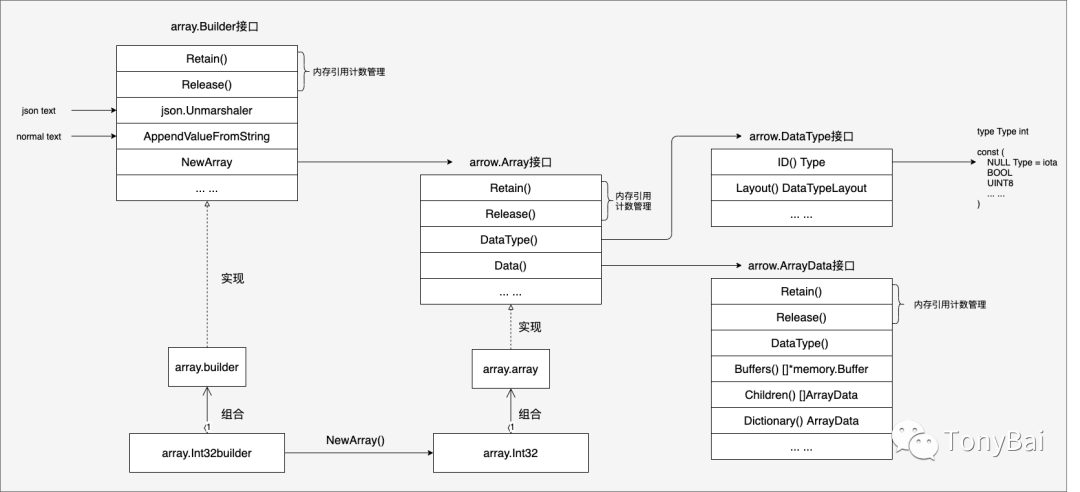
当然这幅图也大概可以作为Go Arrow实现的原理图。
从图中,我们可以看到:
Arrow go提供了Builder、Array、ArrayData接口作为抽象,在这些接口中都包含了用作内存引用计数管理的Retain和Release方法;
array包提供了Builder接口的一个默认实现builder类型,所有的XXXBuilder都组(内)合(嵌)了这个类型,这个类型实现了Retain方法,Release方法需要XXXBuilder自行实现。
array包提供了Array接口的一个默认实现array类型,所有的array type(比如array.Int32)都组(内)合(嵌)了这个array类型。该类型实现了Retain和Release方法。
// github.com/apache/arrow/go/arrow/array/array.go
type array struct {
refCount int64
data *Data
nullBitmapBytes []byte
}
// Retain increases the reference count by 1.
// Retain may be called simultaneously from multiple goroutines.
func (a *array) Retain() {
atomic.AddInt64(&a.refCount, 1)
}
// Release decreases the reference count by 1.
// Release may be called simultaneously from multiple goroutines.
// When the reference count goes to zero, the memory is freed.
func (a *array) Release() {
debug.Assert(atomic.LoadInt64(&a.refCount) > 0, "too many releases")
if atomic.AddInt64(&a.refCount, -1) == 0 {
a.data.Release()
a.data, a.nullBitmapBytes = nil, nil
}
}下面以Int64 array type为例:
// github.com/apache/arrow/go/arrow/array/numeric.gen.go
// A type which represents an immutable sequence of int64 values.
type Int64 struct {
array // “继承”了array的Retain和Release方法。
values []int64
}通过XXXBuilder类型的NewArray方法可以获得该Builder对应的Array type实例,比如:调用Int32Builder的NewArray可获得一个Int32 array type的实例。一个array type实例对应的数据是逻辑上immutable的,一旦创建便不能改变。
通过Array接口的Data方法可以得到该array type的底层数据layout实现(arrow.ArrayData接口的实现),包括child data。
arrow包定义了所有的数据类型对应的ID值和string串,这个与arrow.DataType接口放在了一个源文件中。
另外要注意,XXXBuilder的实例是“一次性”的,一旦调用NewArray方法返回一个array type实例,该XXXBuilder就会被reset。如果再次调用其NewArray方法,只能得到一个空的array type实例。你可以重用该Builder,只需向该Builder实例重新append值即可(见下面示例):
// reuse_string_builder.go
func main() {
bldr := array.NewStringBuilder(memory.DefaultAllocator)
defer bldr.Release()
bldr.AppendValues([]string{"hello", "apache arrow"}, nil)
arr := bldr.NewArray()
defer arr.Release()
bitmaps := arr.NullBitmapBytes()
fmt.Println(hex.Dump(bitmaps))
bufs := arr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
// reuse the builder
bldr.AppendValues([]string{"happy birthday", "leo messi"}, nil)
arr1 := bldr.NewArray()
defer arr1.Release()
bitmaps1 := arr1.NullBitmapBytes()
fmt.Println(hex.Dump(bitmaps1))
bufs1 := arr1.Data().Buffers()
for _, buf := range bufs1 {
if buf != nil {
fmt.Println(hex.Dump(buf.Buf()))
}
}
fmt.Println(arr1)
}输出上面示例运行结果:
$go run reuse_string_builder.go
00000000 03 |.|
00000000 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 00 00 00 05 00 00 00 11 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 68 65 6c 6c 6f 61 70 61 63 68 65 20 61 72 72 6f |helloapache arro|
00000010 77 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |w...............|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
["hello" "apache arrow"]
00000000 03 |.|
00000000 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 00 00 00 0e 00 00 00 17 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 68 61 70 70 79 20 62 69 72 74 68 64 61 79 6c 65 |happy birthdayle|
00000010 6f 20 6d 65 73 73 69 00 00 00 00 00 00 00 00 00 |o messi.........|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
["happy birthday" "leo messi"]想必到这里,大家对Arrow的Go实现原理有了一个大概的认知了。接下来,我们再来看Go arrow实现的内存引用计数管理。
2. Go Arrow实现的内存引用计数管理
在上面图中,我们看到Go Arrow实现的几个主要接口Builder、Array、ArrayData都包含了Release和Retain方法,也就是说实现了这些接口的类型都支持采用引用计数方法(Reference Counting)进行内存的跟踪和管理。Retain方法的语义是引用计数加1,而Release方法则是引用计数减1。由于采用了原子操作对引用计数进行加减,因此这两个方法是并发安全的。当引用计数减到0时,该引用计数对应的内存块就可以被释放掉了。
Go Arrow实现的主页[3]上对引用计数的使用场景和规则做了如下说明:
如果你被传递了一个对象并希望获得它的所有权(ownership),你必须调用Retain方法。当你不再需要该对象时,你必须调用对应的Release方法。"获得所有权"意味着你希望在当前函数调用的范围之外访问该对象。
你通过名称以New或Copy开头的函数创建的任何对象,或者在通过channel接收对象时,你都将拥有所有权。因此,一旦你不再需要这个对象,你必须调用Release。
如果你通过一个channel发送一个对象,你必须在发送之前调用Retain,因为接收者将拥有该对象。接收者有义务在以后不再需要该对象时调用Release。
有了这个说明后,我们对于Retain和Release的使用场景基本做到心里有谱了。但还有一个问题亟待解决,那就是:Go是GC语言,为何还要在GC之上加上一套引用计数呢?
这个问题我在这个issue[4]中找到了答案。一个Go arrow实现的commiter在回答issue时提到:“理论上,如果你知道你使用的是默认的Go分配器,你实际上不必在你的消费者(指的是Arrow Go包 API的使用者)代码中调用Retain/Release,可以直接让Go垃圾回收器管理一切。我们只需要确保我们在库内调用Retain/Release,这样如果消费者使用非Go GC分配器,我们就可以确保他们不会出现内存泄漏”。
下面是默认的Go分配器的实现代码:
package memory
// DefaultAllocator is a default implementation of Allocator and can be used anywhere
// an Allocator is required.
//
// DefaultAllocator is safe to use from multiple goroutines.
var DefaultAllocator Allocator = NewGoAllocator()
type GoAllocator struct{}
func NewGoAllocator() *GoAllocator { return &GoAllocator{} }
func (a *GoAllocator) Allocate(size int) []byte {
buf := make([]byte, size+alignment) // padding for 64-byte alignment
addr := int(addressOf(buf))
next := roundUpToMultipleOf64(addr)
if addr != next {
shift := next - addr
return buf[shift : size+shift : size+shift]
}
return buf[:size:size]
}
func (a *GoAllocator) Reallocate(size int, b []byte) []byte {
if size == len(b) {
return b
}
newBuf := a.Allocate(size)
copy(newBuf, b)
return newBuf
}
func (a *GoAllocator) Free(b []byte) {}我们看到默认的Allocator只是分配一个原生切片,并且切片的底层内存块要保证64-byte对齐。
但为什么Retain和Release依然存在且需要调用呢?这位commiter给出了他理解的几点原因:
允许用户控制buffer和内部数据何时被设置为nil,以便在可能的情况下提前标记为可被垃圾收集;
如果用户愿意,允许正确使用不依赖Go垃圾收集器的分配器(比如mallocator实现,它使用malloc/free来管理C内存而不是使用Go垃圾收集来管理);
虽然用户可以通过SetFinalizer来使用Finalizer进行内存释放,但一般来说,我们建议最好有一个显式的释放动作,而不是依赖finalizer,因为没有实际保证finalizer会运行。此外,finalizer只在GC期间运行,这意味着如果你的分配器正在分配C内存或其他东西,而Go内存一直很低,那么你有可能在任何finalizer运行以实际调用Free之前,就被分配了大量的C内存,从而耗尽了你的内存。
基于这些原因,Go Arrow实现保留了Retain和Release,虽然有上门的一些场景使用方法,但这两个方法的加入一定程度上增加了Go Arrow API使用的门槛。并且在重度使用Go Arrow实现的程序中,大家务必对程序做稳定性长测试验证,以确保memory没有leak。
3. 如何实现ZeroCopy的内存数据共享
《In-Memory Analytics with Apache Arrow》[5]一书在第二章中提到了采用Arrow实现zerocopy的内存数据共享的原理,这里将其称为“切片(slice)原理”,用书中的例子简单描述就是这样的:假设你想对一个有数十亿行的非常大的数据集进行一些分析操作。提高这种操作性能的一个常见方法是对行的子集进行并行操作,即仅通过对数组和数据缓冲区进行切分,而不需要复制底层数据。这样你操作的每个批次都不是一个副本--它只是数据的一个视图。书中还给出了如下示意图:
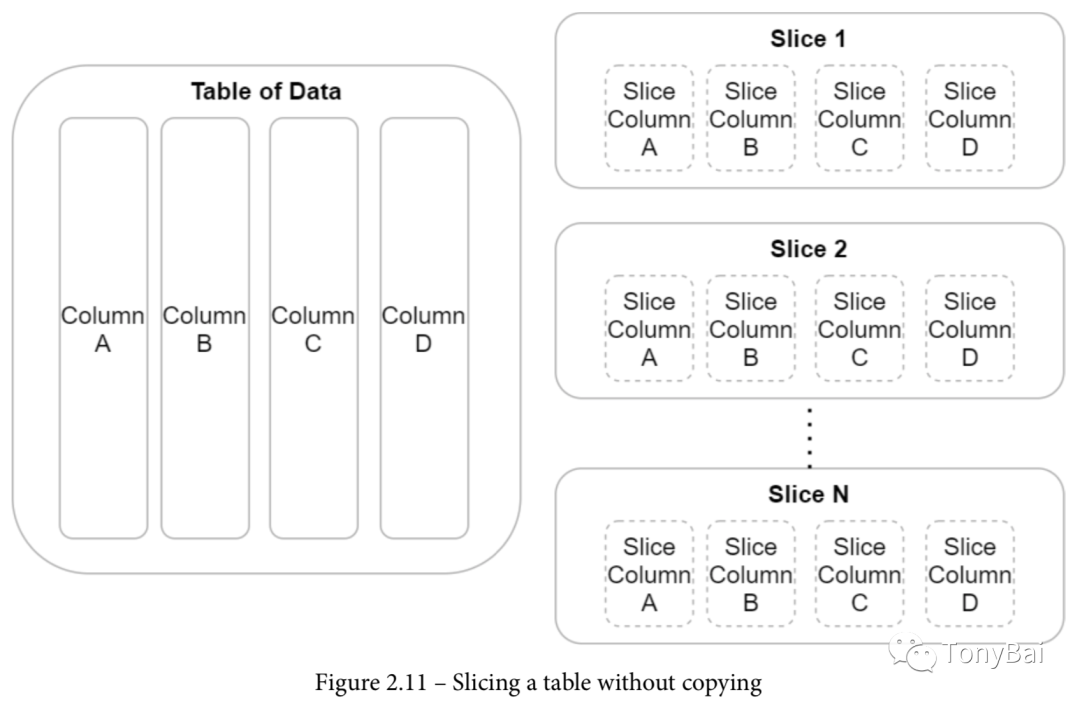
右侧切片列中的每个切片的虚线表示它们只是各自列中的数据子集的视图,每个切片都可以安全地进行并行操作。
array type是逻辑上immutable的,底层data buffer一旦建立后,便可以通过切片的方式来以zerocopy方式做内存数据共享,极大提高了数据操作的性能。
4. 小结
本文介绍了Go arrow实现的主要结构以及实现模式:builder模式,并结合Go arrow官方资料说明了采用引用计数进行内存管理的原因与使用方法,最后介绍了Arrow实现ZeroCopy的内存数据共享的原理。这些将为后续继续深入学习Arrow高级数据类型/结构奠定良好的基础。
注:本文涉及的源代码在这里[6]可以下载。
“Gopher部落”知识星球[7]旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2023年,Gopher部落将进一步聚焦于如何编写雅、地道、可读、可测试的Go代码,关注代码质量并深入理解Go核心技术,并继续加强与星友的互动。欢迎大家加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址[8]:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 - https://github.com/bigwhite/gopherdaily
我的联系方式:
微博(暂不可用):https://weibo.com/bigwhite20xx
微博2:https://weibo.com/u/6484441286
博客:tonybai.com
github: https://github.com/bigwhite

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。
参考资料
[1]
《Go语言开发者的Apache Arrow使用指南:数据类型》: https://tonybai.com/2023/06/25/a-guide-of-using-apache-arrow-for-gopher-part1
[2]Go是GC语言: https://tonybai.com/2023/06/13/understand-go-gc-overhead-behind-the-convenience
[3]Go Arrow实现的主页: https://github.com/apache/arrow/tree/main/go
[4]这个issue: https://github.com/apache/arrow/issues/35232
[5]《In-Memory Analytics with Apache Arrow》: https://book.douban.com/subject/35954154/
[6]这里: https://github.com/bigwhite/experiments/blob/master/arrow/memory-management
[7]“Gopher部落”知识星球: https://wx.zsxq.com/dweb2/index/group/51284458844544
[8]链接地址: https://m.do.co/c/bff6eed92687