上一篇文章说的是普通进程的调度但同时还有实时进程在linux上面进行运行
这边来看看实时进程在linux里面怎么调度 同时linux操作系统对实时任务的处理方式和设计思想
实时调度类
Linux进程分为两大类:实时进程和普通进程。
实时进程与普通进程根本不同之处,如果系统中有一个实时进程且可运行,那么调度器总是会选择它,除非另有一个优
先级更高的实时进程。
SCHED_ FIFO: 没有时间片,在被调度器选择之后,可以运行任意长的时间;
SCHED_ RR:有时间片,其值在进程运行时会减少。
实时调度中表达一个任务的结构体
实时调度的代码比较多用到的再继续从这个头文件分析结构体和作用
struct sched_rt_entity {
struct list_head run_list;
unsigned long timeout;主要用于判断当前进程时间是否超过RLIMIT_ RTTIME
unsigned long watchdog_stamp;
unsigned int time_slice;针对RR调度策略的调度时隙
struct sched_rt_entity *back;
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity *parent;//指向上层调度实体
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;//当前实时调度实体所在的就绪队列
/* rq "owned" by this entity/group: */
struct rt_rq *my_q;当前实时调度实体的子调度实体所在就绪队列
#endif
};
const struct sched_ class rt_ sched_ class = {
.next = &fair_ sched_ class,
..enqueue_ task = enqueue_ task_ rt, // 将一个task放入到就绪队列头部或者尾部
.dequeue_ task = dequeue_ task_ rt, // 将一个task从就绪队列末尾
.yield_ task = yield_ task_ rt,
// 主动放弃执行
.check_ preempt_ curr = check_ preempt_ curr_ rt,
.pick_ next_ task.pick_ next_ task_ rt, // 核心调度器选择就绪队列那个任务被调度,
.put_ prev_ task = put_ prev_ task_ rt, // 当一个任务将要被调度出时执行
#ifdef CONFIG SMP
.select_ task_ rq = select_ task_ rq_ rt, // 核心调度器给任务待定CPU,用于将任务分发到不同CPU上执行
.set_ cpus_ al lowed = set_ cpus_ allowed_ common,
.rq_ onl ine = rq_ online_ rt,
.rq_ offline = rq_ offline_ rt,
.task_ woken = task_ woken_ rt,
.switched from = switched_ from_ rt,
#endif
}
处理器结构
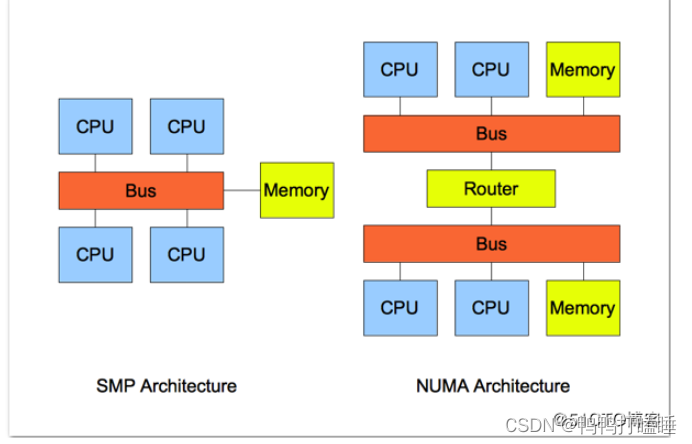
对称多处理器SMP
多处理器系统的工作方式分为非对称多处理(asym-metrical mulit-processing)和对称多处理(symmetrical mulit-processing,SMP)两种。
在对称多处理器系统中,所有处理器的地位都是相同的,所有的资源,特别是存储器、中断及I/O空间,都具有相同的可访问性,消除结构上的障碍。
多处理器系统上,内核必须考虑几个额外的问题,以确保良好的调度。
CPU负荷必须尽可能公平地在所有的处理器上共享。
进程与系统中某些处理器的亲合性(affinity)必须是可设置的。
内核必须能够将进程从一个CPU迁移到另一个。
linux SMP调度就是将进程安排/迁移到合适的CPU中去,保持各CPU负载均衡的过程。
NUMA
所谓物理内存,就是安装在机器上的,实打实的内存设备(不包括硬件cache),被CPU通过总线访问。在多核系统中,如果物理内存对所有CPU来说没有区别,每个CPU访问内存的方式也一样,则这种体系结构被称为Uniform Memory Access
如果物理内存是分布式的,由多个cell组成(比如每个核有自己的本地内存),那么CPU在访问靠近它的本地内存的时候就比较快,访问其他CPU的内存或者全局内存的时候就比较慢,这种体系结构被称为Non-Uniform Memory Access(NUMA)。
linux针对对称多处理器的负载调度均衡
在多处理器系统当中,内核必须考虑几个额外的问题,主要以确保良好的调度。
➢CPU负荷必须尽可能公平地在所有的处理器上共享。
➢进程与系统中某些处理器的亲合性(affinity) 必须是可设置的。
➢内核必须能够将进程从一个CPU迁移到另-一个。
启动加载
Linux 内核编译时,CONFIG_SMP 配置项用于控制内核是否支持SMP。

Linux 系统中SMP 模式的启动流程如图所示,复位之后,CPU0 和CPU1 同时执行ROM code 中的代码,此时的CPU0 和CPU1 运行的是一模一样的指令,此后ROM code 引导CPU0 去执行Bootloader(包括tfa 和uboot)的代码和内核代码
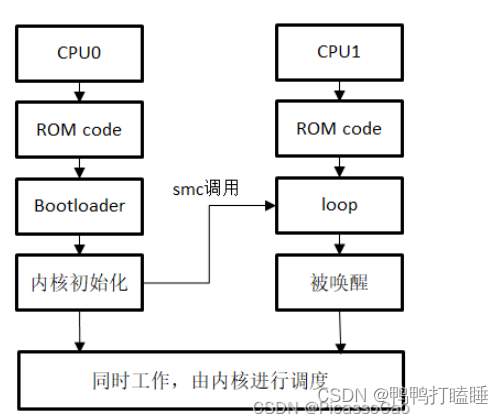
如果你曾经留意过内核启动的输出,你就会发现如图所示的打印信息,提示我们当前内核是在CPU0 上运行的
而CPU1 则进入循环,直到收到CPU0 发来的唤醒信号,在这个过程中,CPU0 已经为CPU1 创建空闲任务,CPU1 则被唤醒,开始执行空闲任务。
内核识别CPU
上面只是简单介绍了整个启动流程,实际上,内核是如何识别到芯片中有几个CPU 核的呢?CPU0又是如何唤醒CPU1 的呢?首先,为了描述当前系统中各个CPU 核心的工作状态,内核在kernel/cpu.c 中定义四个cpumask 类型的结构体变量,
__cpu_possible_mask:记录物理存在且可能被激活的CPU 核心对应的编号,由设备树解析CPU 节点获得;
__cpu_online_mask:记录当前系统正在运行的CPU 核心的编号;
__cpu_present_mask:动态地记录了当前系统中所有CPU 核心的编号,如果内核配置了CONFIG_HOTPLUG_CPU,那么这些CPU 核心不一定全部处于运行状态,因为有的CPU 核心可能被热插拔了;
__cpu_active_mask:用于记录当前系统哪些CPU 核心可用于任务调度;
用户空间的操作
在/sys/devices/system/cpu 目录下,记录了系统中所有的CPU 核以及上述各变量的内容,例如文件present,对应于__cpu_present_mask 变量,执行以下命令,可以查看当前系统中所有的CPU 核编号。
cat /sys/devices/system/cpu/present
此外,我们可以通过文件/sys/devices/system/cpu/cpu1/online 在用户空间控制一个CPU 核运行与否。
# 关闭CPU1
echo 0 > /sys/devices/system/cpu/cpu1/online
# 打开CPU1
echo 1 > /sys/devices/system/cpu/cpu1/online
接下来,看看内核是如何建立CPU 之间的关系的。在设备树根节点下有个/cpus 的子节点,其内容如下
cpus {
#address-cells = <1>;
#size-cells = <0>;
cpu0: cpu@0 {
compatible = "arm,cortex-a7";
device_type = "cpu";
reg = <0>;
clocks = <&rcc CK_MPU>;
clock-names = "cpu";
operating-points-v2 = <&cpu0_opp_table>;
nvmem-cells = <&part_number_otp>;
nvmem-cell-names = "part_number";
};
cpu1: cpu@1 {
compatible = "arm,cortex-a7";
device_type = "cpu";
reg = <1>;
clocks = <&rcc CK_MPU>;
clock-names = "cpu";
operating-points-v2 = <&cpu0_opp_table>;
};
};
该节点描述了当前硬件上存在两个CPU,分别是CPU0 和CPU1,内核代码通过解析该节点,便可以获得当前系统的CPU 核心个数,并且我们可以看到该节点还包含了“operating-points-v2”属性,指向了cpu0_opp_table 节点,该节点是用于配置CPU 核心支持的频率。