最近, 清华大学 NLP实验室、面壁智能、知乎联合在 OpenBMB 开源多模态大模型系列VisCPM ,评测显示, VisCPM 在中文多模态开源模型中达到最佳水平。
VisCPM 是一个开源的多模态大模型系列,支持中英双语的多模态对话能力(VisCPM-Chat模型)和文到图生成能力(VisCPM-Paint模型)。VisCPM基于百亿参数量语言大模型 CPM-Bee(10B)训练,融合视觉编码器(Q-Former)和视觉解码器(Diffusion-UNet)以支持视觉信号的输入和输出。VisCPM可以仅通过英文多模态数据预训练,泛化实现优秀的中文多模态能力。

👐 开源使用:VisCPM 可以自由被用于个人和研究用途。我们希望通过开源VisCPM 模型系列,推动多模态大模型开源社区和相关研究的发展。
🌟 涵盖图文双向生成:VisCPM 模型系列较为全面地支持了图文多模态能力,涵盖多模态对话(图到文生成)能力和文到图生成能力。
💫 中英双语性能优异:得益于语言模型基座 CPM-Bee 优秀的双语能力,VisCPM 在中英双语的多模态对话和文到图生成均取得亮眼的效果。
VisCPM-Chat:支持图像双语多模态对话
—
VisCPM-Chat 支持面向图像进行中英双语多模态对话。该模型使用Q-Former作为视觉编码器,使用CPM-Bee(10B)作为语言交互基底模型,并通过语言建模训练目标融合视觉和语言模型。模型训练包括预训练和指令精调两阶段:
预训练:使用约100M高质量英文图文对数据对VisCPM-Chat进行了预训练,数据包括CC3M、CC12M、COCO、Visual Genome、Laion等。在预训练阶段,语言模型参数保持固定,仅更新Q-Former部分参数,以支持大规模视觉-语言表示的高效对齐。
指令精调:采用LLaVA-150K英文指令精调数据,并混合相应翻译后的中文数据对模型进行指令精调,以对齐模型多模态基础能力和用户使用意图。在指令精调阶段,我们更新全部模型参数,以提升指令精调数据的利用效率。有趣的是,我们发现即使仅采用英文指令数据进行指令精调,模型也可以理解中文问题,但仅能用英文回答。这表明模型的多语言多模态能力已经得到良好的泛化。在指令精调阶段进一步加入少量中文翻译数据,可以将模型回复语言和用户问题语言对齐。
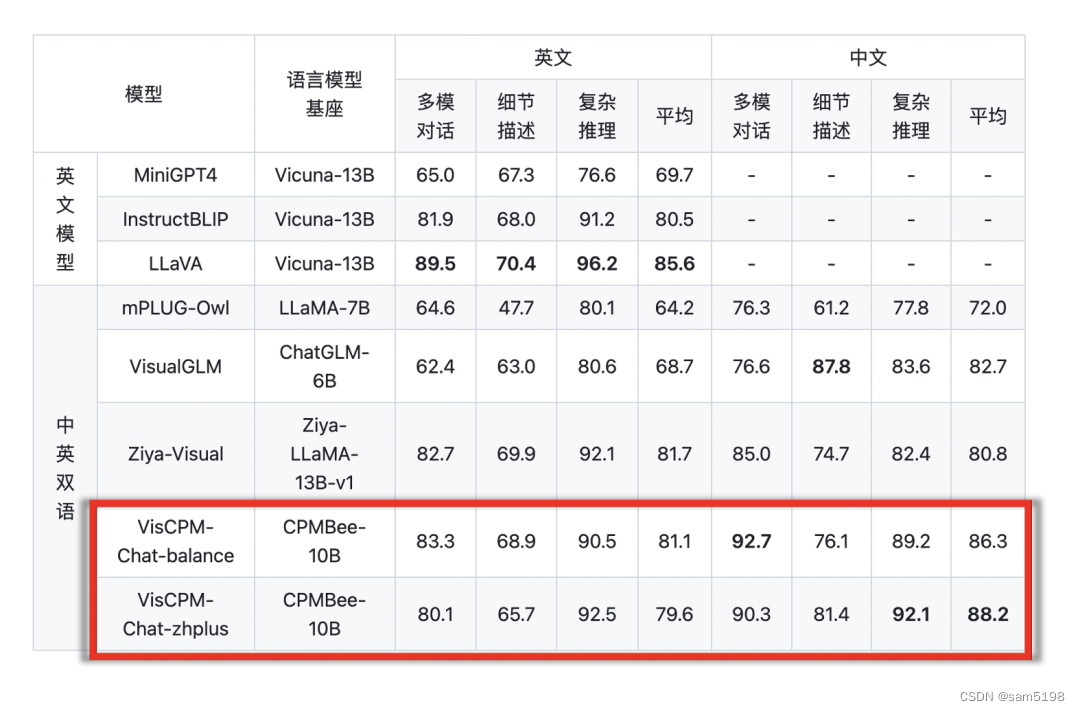
我们在LLaVA标准英文测试集和翻译的中文测试集对模型进行了评测,该评测基准考察模型在开放域对话、图像细节描述、复杂推理方面的表现,并使用GPT-4进行打分。可以观察到,VisCPM-Chat在中文多模态能力方面取得了最佳的平均性能,在通用域对话和复杂推理表现出色,同时也表现出了不错的英文多模态能力。
我们提供了两个模型版本,分别为 VisCPM-Chat-balance 和 VisCPM-Chat-zhplus,前者在英文和中文两种语言上的能力较为平衡,后者在中文能力上更加突出。两个模型在指令精调阶段使用的数据相同,VisCPM-Chat-zhplus 在预训练阶段额外加入了 20M 清洗后的原生中文图文对数据和 120M 翻译到中文的图文对数据。
VisCPM-Paint :支持双语文到图生成
—
VisCPM-Paint 支持中英双语的文到图生成。该模型使用 CPM-Bee(10B)作为文本编码器,使用 UNet 作为图像解码器,并通过扩散模型训练目标融合语言和视觉模型。在训练过程中,语言模型参数始终保持固定。我们使用 Stable Diffusion 2.1 的 UNet 参数初始化视觉解码器,并通过逐步解冻其中关键的桥接参数将其与语言模型融合。该模型在 LAION 2B 英文图文对数据上进行了训练。
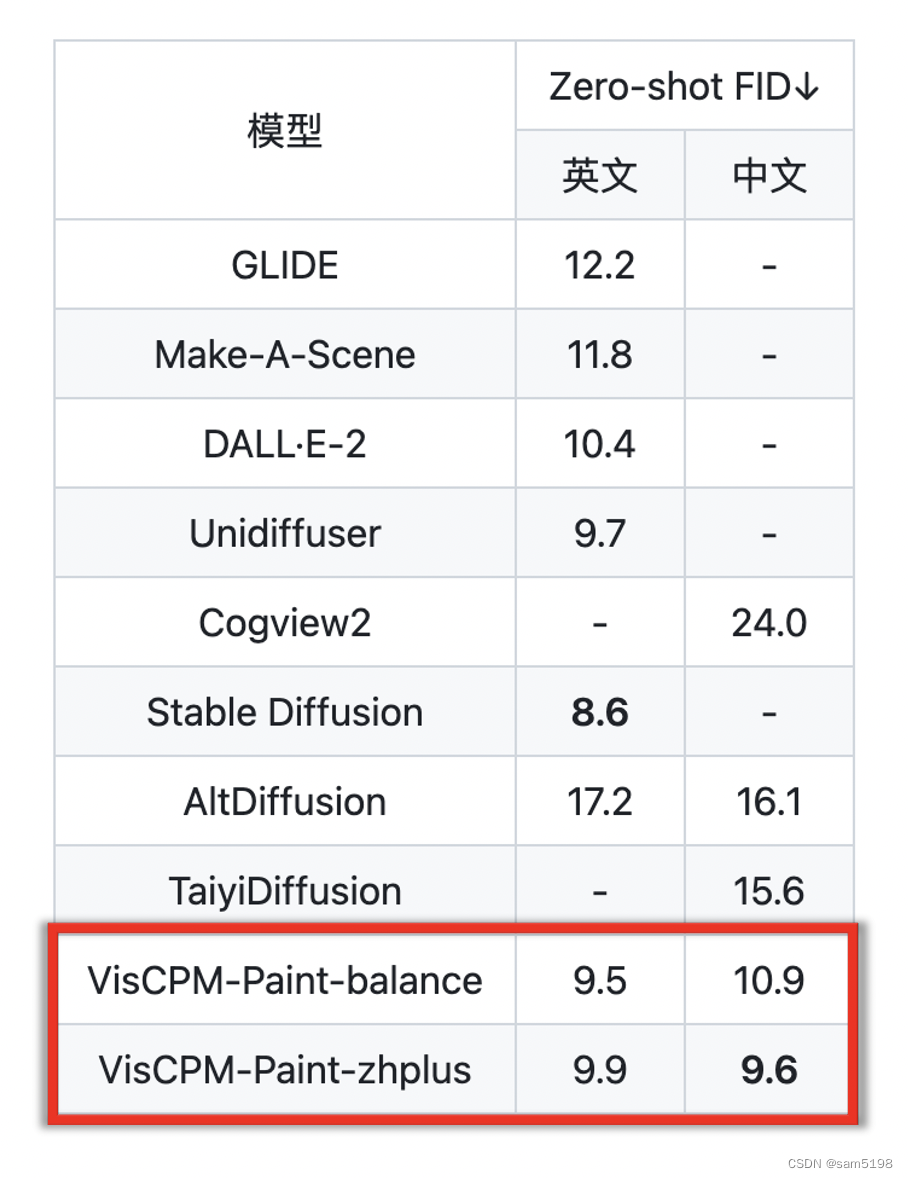
与 VisCPM-Chat 一样,得益于 CPM-Bee 的双语能力,VisCPM-Paint 可以仅通过英文图文对训练,泛化实现良好的中文文到图生成能力,达到中文开源模型的最佳效果。通过进一步加入 20M 清洗后的原生中文图文对数据,以及 120M 翻译到中文的图文对数据,模型的中文文到图生成能力可以获得进一步提升。
同样,VisCPM-Paint 有 balance和 zhplus 两个不同的版本。我们在标准图像生成测试集 MSCOCO 上采样了 3万张图片,计算了常用评估图像生成指标 FID (Fréchet Inception Distance) 评估生成图片的质量。
下面是 VisCPM-Paint 的图片生成效果展示:

VisCPM 提供 不同中英文能力的模版本 供大家下载选择,并且安装和使用简易高效,可以 通过几行代码实现多模态对话,还在代码中默认开启了对输入文本和输出图片的安全检查。