前文介绍了非功能性需求的各个指标和一些业界的标准。
非功能性需求里有一项可靠性,与之关联的一个指标叫可用性
本文对非功能性需求里的可用性、可靠性,进行一些详细的说明。
概念
我们在网上的云服务商处,经常看到产品介绍里会有这种字样:我们的服务可用性高达 99.99%
这个可用性的含义是什么?
- 定义:
指系统在一段时间内,正常运行和可正常使用的时间占比。
例如:一年内,某系统正常运行364天,故障累计时长1天,则可用性为364/365 ≈ 99.7% - 与可靠性的区别:
可靠性是考察两次故障的平均间隔时长。 - 通常情况下,两者是有关联的,即可靠性好,通常可用性也高。
但是也存在例外情况,如下面2个场景对比:- 可用性高但可靠性不好
每分钟都会宕机一次,1秒就恢复正常了,可用性比较好≈ 98.3%
但是故障概率高,连续正常服务时间仅为59秒,所以可靠性差 - 可靠性好但可用性不高
每天宕机一次,每次2小时,可用性比上面的场景要差≈ 91.7%
但是比上一个场景,可靠性好,它的连续正常服务时间为22小时
- 可用性高但可靠性不好
度量
对一个软件系统的可用性,度量方法通常有两种:
基于时间
Uptime / (Uptime+Downtime)
即正常工作的时长,除以总时长
基于请求
Success / Total
即成功响应次数,除以总请求次数
下面2张图,左边是列举一个系统达到该可用性时,每年的平均故障时间,右边是常见云服务对外承诺的可用性:
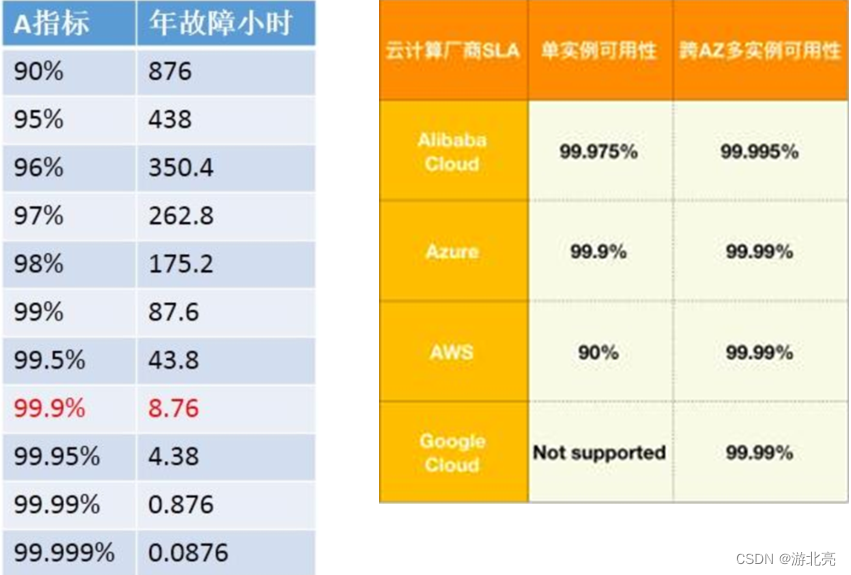
从上面的图,可以看出:
- 越低的可用性,对用户的影响越大,故障多了,用户抱怨、投诉、流失的概率就越大
- 云服务厂商承诺的可用性,有的也并不高,你的系统在设计时,一定也要考虑云服务厂商的故障影响
参考:- 阿里云SLA服务等级协议声明:https://help.aliyun.com/document_detail/56773.htm
短信服务的可用性只承诺95%,存储的可用性可以达到99.995% - 微软云Azure: https://azure.microsoft.com/zh-cn/support/legal/sla/
- 阿里云SLA服务等级协议声明:https://help.aliyun.com/document_detail/56773.htm
题外话:
-
云厂商出现故障时,只要时长不超出承诺的可用性,基本上只是道歉;即使超出了,一般也只是赔偿对应的故障时长,比如故障1小时,赔偿你3小时的云服务使用时长,仅此而已。
所以,你数据丢了,如果没闹大,一般就只能自己想办法了。
可以搜索:2018年发生的 前沿数控在腾讯云数据丢失事件,索赔千万,只赔付13万。 -
我以前公司的SaaS服务,部署在阿里云上,在服务出故障时,市场人员先跟用户说:阿里云又挂了,然后才是对老板投诉研发人员
-
绝大多数的Web服务,其可用性都在3个9,甚至以下的水平
如何提升可用性
案例分析
假设某系统,有一个登录请求,需要访问4个DB数据库(mysql/mongodb/cassandra/redis),已知每个DB的可用性是99.9%,如图:
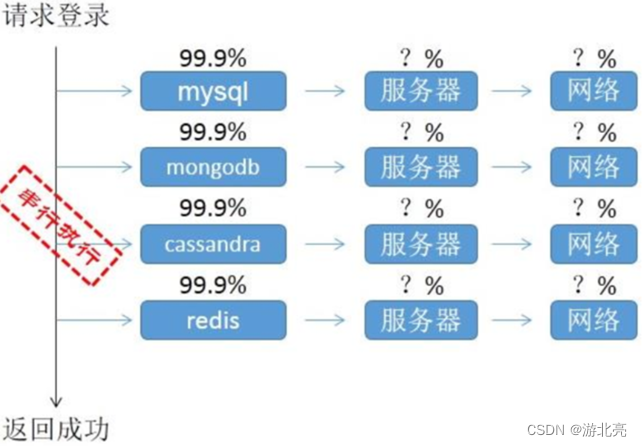
那么这个请求的可用性是多少?
这个串联系统请求的实际可用性:99.9%的4次方 = 99.6%,这意味着:
单个DB,是99.9%的可用性,即全年会有8.76小时不可用;
但是4个DB进行串行请求后,变为全年35.04小时不可用,故障概率翻了4倍。
而且图中还有其它服务器、网络,假设网络不稳定,导致每个DB的可用性降低到了99.5%,则:
这个串联系统请求的可用性降低为:99.5%的4次方 = 98%
相当于全年有175.2小时不可用,平均每个月宕机14.6小时
提升可用性的方法
从上面的案例,可以得出,一个系统里涉及的模块(微服务)、中间件(数据库、消息队列等)越多,可用性越低。
那么如何提升可用性呢?
唯一的答案是使用 并联,即服务冗余,也就是我们常说的负载均衡;
- 串联系统(2个节点)的可用性计算: A = p1 * p2
如2个节点的可用性都是99%,则 A = 99% * 99% = 98.01% - 并联系统(2个节点)的可用性计算: A = 1-(1-p1)*(1-p2)
如2个节点的可用性都是99%,则 A = 1-(1-99%) * (1-99%) = 99.99%
冗余一个节点,可用性就能从99%提升到99.99%,从年故障87.6小时,降低到52分钟
如何实现系统并联:
- 对于每个服务,都部署在多台独立的服务器上;
- 前端有一个网关,接收请求,根据服务的每个节点状态,发送到健康节点上
- 网关自身也要做冗余,通常会通过一套选举机制来保证网关自身健康状态,选举机制常见的有Paxos算法、Raft算法,可以自行搜索
困难点:
- 架构设计复杂,且涉及旧系统改造,有的系统不支持并联,比如用了内存缓存、用了Session等;
- 成本翻倍,需要综合考虑产品的市场与开发成本、部署成本、后续的运维成本;
- 使用容器,如K8S时,要注意同一个服务的多个实例(Pod),要部署在不同的工作节点上;
我就碰到过一个服务的2个pod,在同一个node上,结果这个node宕机了,整个服务都不可用了。
确定优化目标
要提升系统的可用性,不是盲目的为每个服务、每个中间件去增加并联处理,而应该遵循一定的步骤:
- 1、确定合适的可用性目标
- 调研用户期望
- 确定公司的商业目标(ToB产品至少99.9%以上)
- 参考竞品规模及服务水平
- 2、度量我们的系统
常见的度量,确定指标,进行埋点和数据收集(如Proetheus),然后进行统计计算,统计结果:
avg、max、min、dev(平均差(∑|x-x‘|)÷n )、长尾(95分位、99分位)
可用性结语
参考下图,指示了一个产品运营的三个阶段:

通过这张图,我想说:
再牛X的架构、中间件,都是逐步演化、一步步沉淀出来的,一开始大家都很人肉。。。
持续重构……
下一篇,介绍一下性能相关概念,以及如何发现性能问题的一些方法