基础语言模型
概念
基础语言模型是指只在大规模文本语料中进行了预训练的模型,未经过指令和下游任务微调、以及人类反馈等任何对齐优化。
如何理解
-
只包含纯粹的语言表示能力,没有指导性或特定目标。
-
只在大量无标注文本上进行无监督预训练,用于学习语言表示。
-
仅依靠大量文本中的统计信息来学习语言规律(语法、语义等)。
-
未进行任何下游任务微调或优化,也没有使用任何人类注释的数据。
举个例子
-
比如GPT模型,第一代GPT仅仅在大量书籍文本上进行了预训练,学习了语言表示。它只是一个生成模型,未进行下游任务微调。所以它可以看做是一个基础语言模型。
-
而BERT模型则不同,BERT在预训练的基础上又进行了下游任务的微调,比如分类任务。所以BERT就不仅仅是一个基础语言模型。可以用于分类和检测这类任务。
-
基础语言模型更偏向于纯粹的语言学习,专注于语言本身的规律,而非特定的应用。而下游任务微调则考虑了特定任务的需求,不再纯粹。
模型结构
Decoder-only
- 绝大部分的语言模型都是Decoder-only 自回归语言模型的模型结构
- 为什么?
- 总结原因:LLM之所以主要都用Decoder-only架构,除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。
- 典型代表是:GPT系列
- 理解
-
通常情况下, Encoder和Decoder是分开训练的。
-
Decoder-only就是只有Decoder部分,而没有Encoder部分。
-
这意味着:
-
输入序列不需要编码为fixed-length向量。
-
Decoder直接以序列(如句子)为输入,开始解码。
-
-
Decoder-only的优点是:
-
简单直接。只需要训练Decoder部分就可以,不需要单独训练Encoder。
-
效率高。省去了Encoder的编码过程。
-
依赖更少。不依赖Encoder提供的上下文。
-
-
Encoder-Decoder
- 典型代表:GOOGLE开源的T5模型
- 理解
- 对比decoder-only,该结构需要训练encoder
- 优点:
- Encoder和Decoder分开训练,可以复用Encoder,也可以替换Decoder
- 缺点:
- 需要单独训练Encoder和Decoder。
- 依赖Encoder提供的向量表示,效率较低。
- 因使用固定向量表示,信息损失较多。
- 用途两种差不多,但是效率decoder-only更高,更简单易用
GLM
典型代表:清华开源模型GLM-130B
- 理解
-
GLM(General Language Model) 是泛指通用语言模型,包括各种预训练大规模语言模型。
-
采用Transformer Encoder作为模型主体
-
通过自上而下的预训练策略,在大量文本数据上进行自 supervised 学习
-
主要通过Masked LM和第三方信息(如句子顺序)作为预训练任务
-
主要用途偏句子顺序预测任务
-
Multi-task
典型代表:百度模型-ERNIE3.0-Titan,未开源
百家大模型
| 模型名称 | 发布时间 | 发布机构 | 语言 | 参数 | Tokens规模 | 模型机构 | 是否开源 |
|---|---|---|---|---|---|---|---|
| T5 | Oct-19 | 英 | 13B | 无 | T5-style | √ | |
| GPT-3 | May-20 | OpenAI | 英 | 175B | 300B | GPT-style | × |
| LaMDA | May-21 | 英 | 137B | 2.8T | GPT-style | × | |
| Jurass1c | Aug-21 | AI21 | 英 | 178B | 300B | GPT-style | × |
| MT-NLG | Oct-21 | Microsoft.NVIDIA | 英 | 530B | 270B | GPT-style | × |
| ERNIE 3.0 Titan | Dec-21 | Baidu | 中 | 260B | 300B | Multi-task | × |
| Gopher | Dec-21 | DeepMMind | 英 | 280B | 300B | GPT-style | × |
| Chinchilla | Apr-22 | DeepMind | 英 | 70B | 1.4T | GPT-style | × |
| PaLM | Apr-22 | 多语言 | 540B | 780B | GPT-style | × | |
| OPT | May-22 | Meta | 英 | 125M-175B | 180B | GPT-style | √ |
| BLOOM | Jul-22 | BigScience | 多语言 | 176B | 366B | GPT-style | √ |
| GLM-130B | Aug-22 | Tsinghua | 中、英 | 130B | 400B | GPT-style | √ |
| LLaMA | Feb-23 | Meta | 多语言 | 7B-65B | 1.4T | GPT-style | √ |
大模型示例
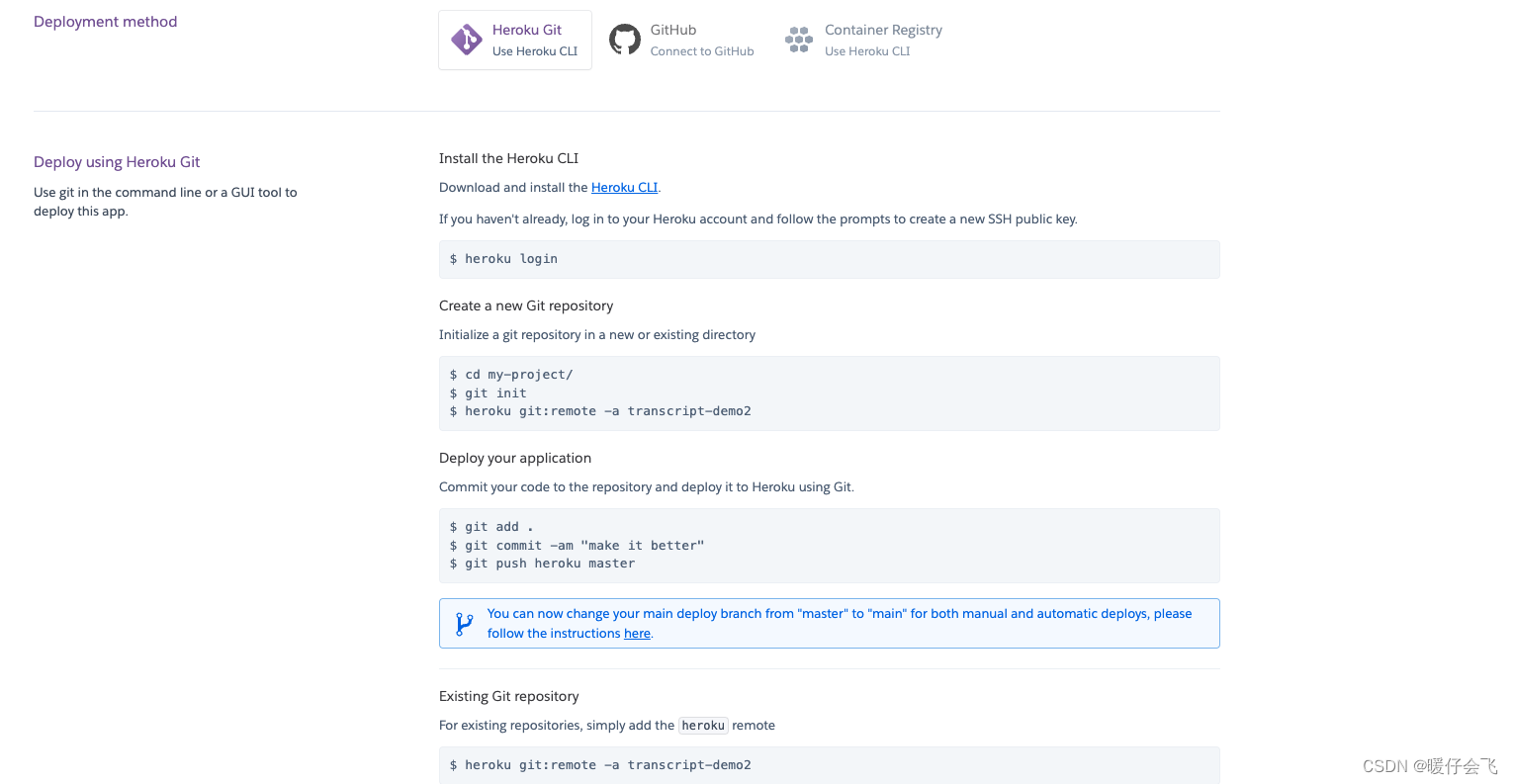
GPT3
- GPT由OpenAI公司从2018年开始陆续提出的一系列预训练模型,目前一共有三个版本:GPT-1、GPT-2和GPT-3,不同版本的GPT模型结构相差不大,但是模型参数规模却不断变大,比如GPT-3就有1750亿个参数,是GPT-2的100倍,性能也逐渐变得强大,支持few-shot、one-shot和zero-shot等下游任务
GPT1论文
- 采用“预训练-微调”的模式,在大规模无标记的文本语料上进行无监督的预训练,然后再在特定任务上进行有监督的微调

GPT2论文
- GPT-2模型结构和GPT-1相同是自回归语言模型,仍然使用Transformer的Decoder组成,预训练使用的数据以及模型参数规模但相比GPT-1变得更大,GPT-2模型参数规模大约是GPT-1的10倍左右,同时GPT-2采用多任务学习的预训练,对于下游任务主打zero-shot,不再需要微调即可使用
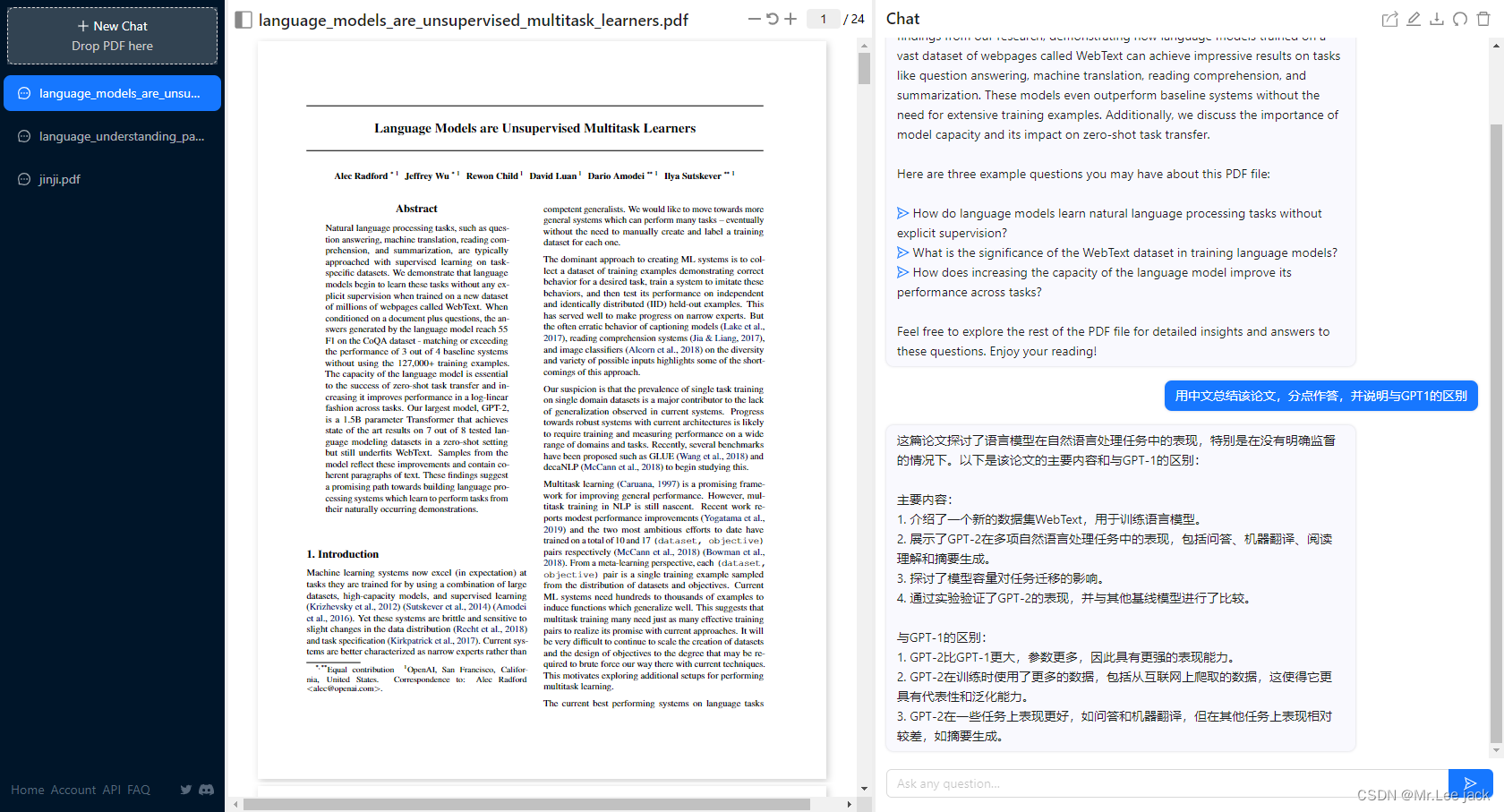
GPT3论文
- GPT-3延续了GPT-2的单向Transformer的自回归语言模型结构,但将模型参数规模是GPT-2的100倍,1750亿个参数。GPT-3不在追求zero-shot的设定,而是在下游任务中给定少量标注的样本让模型学习再进行推理生成。因此,GPT-3主要展示了超大规模语言模型的小样本学习能力
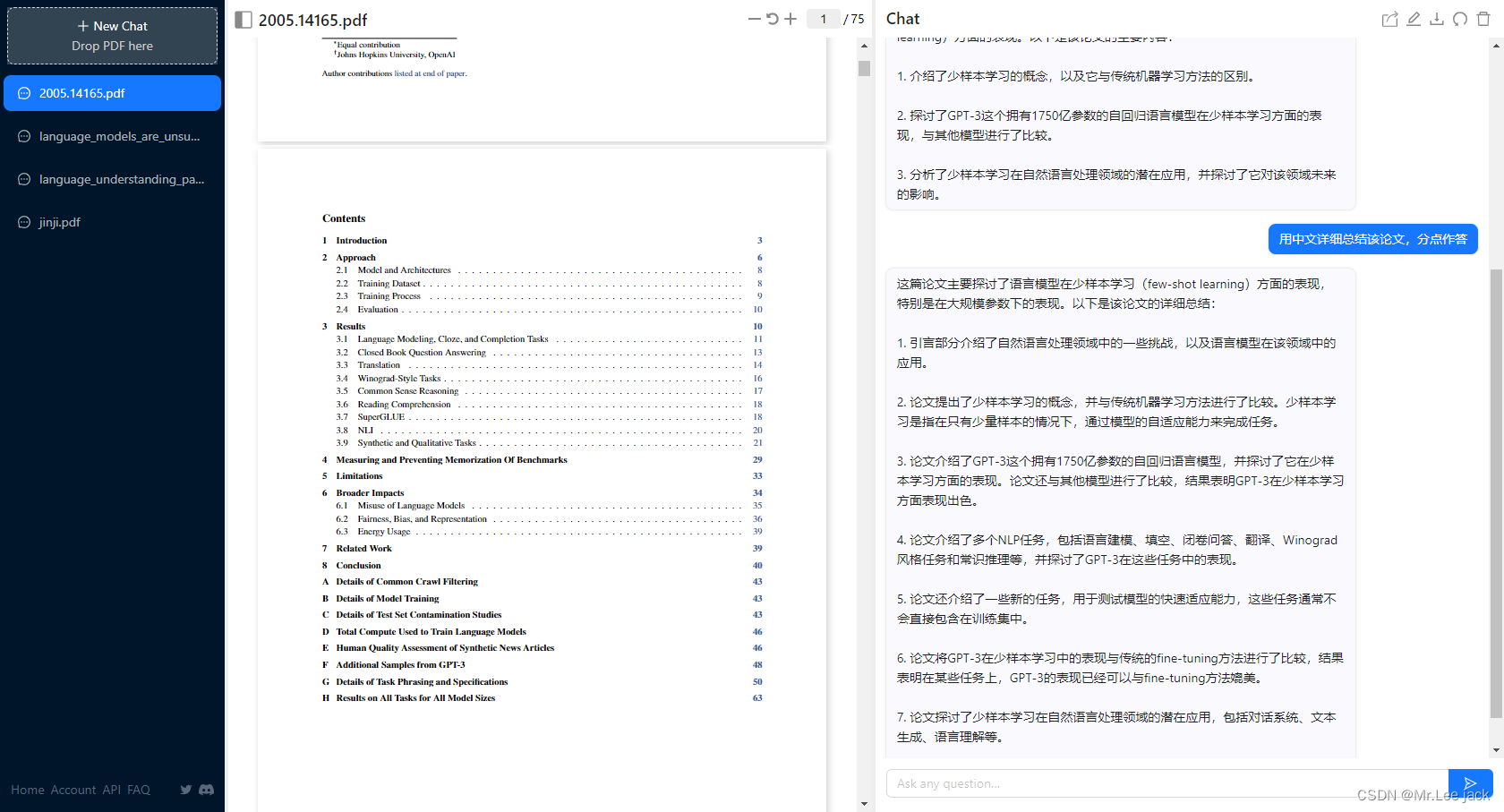
微调方式

- 论文通过大量的实验证明,在zero-shot、one-shot 和few-shot设置下,GPT-3 在许多 NLP 任务和基准测试中表现出强大的性能。GPT-3模型不需要任何额外的微调,就能够在只有少量目标任务标注样本的情况下进行很好的泛化,证明大力出奇迹,做大模型的必要性
GLM系列
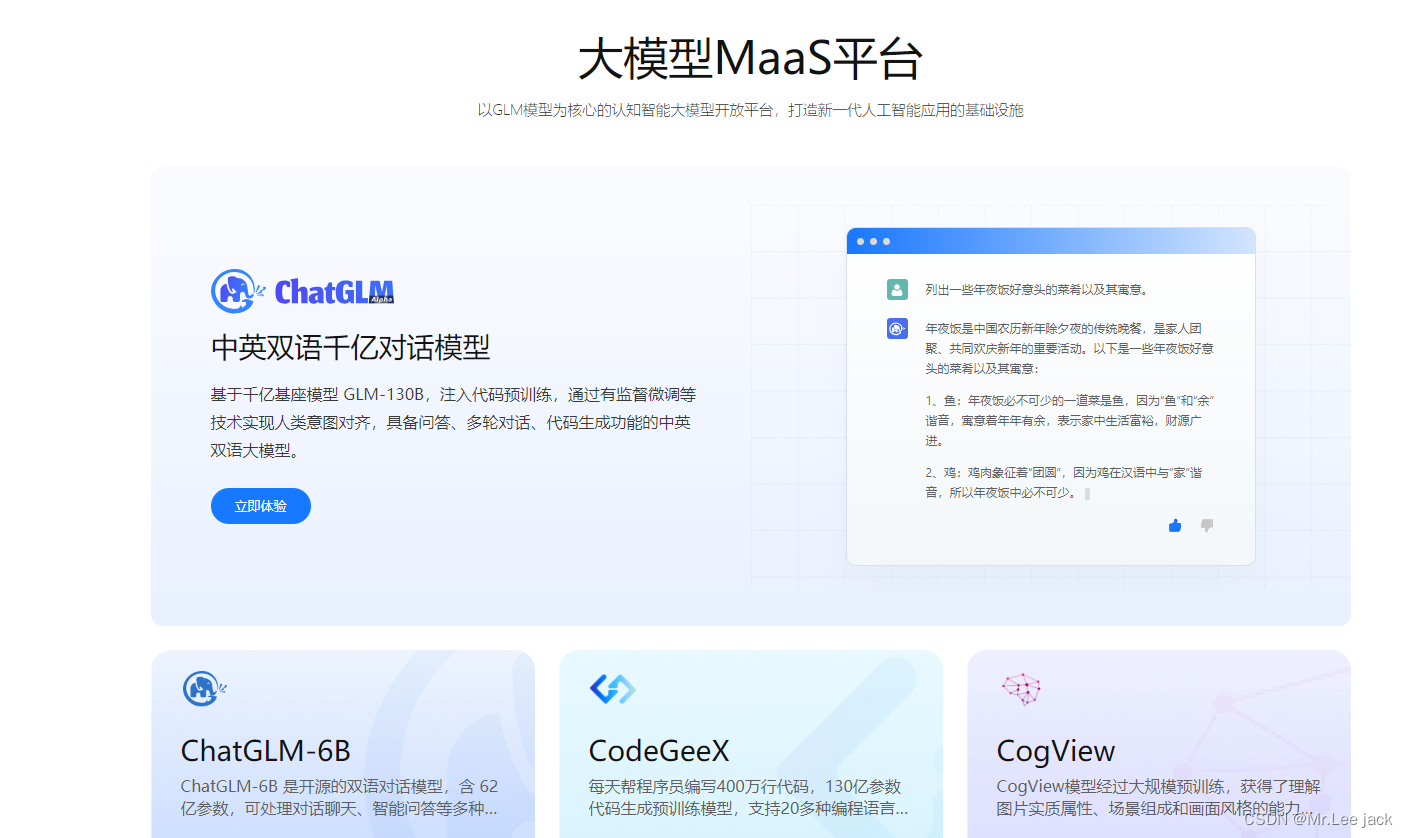
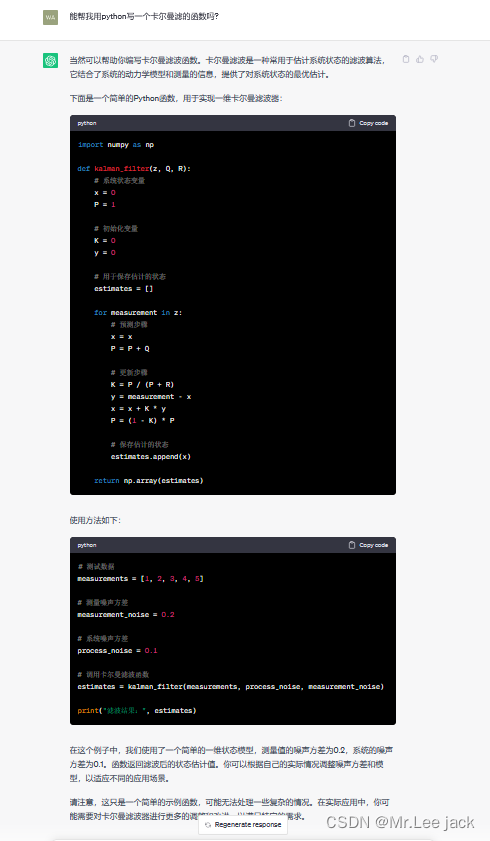
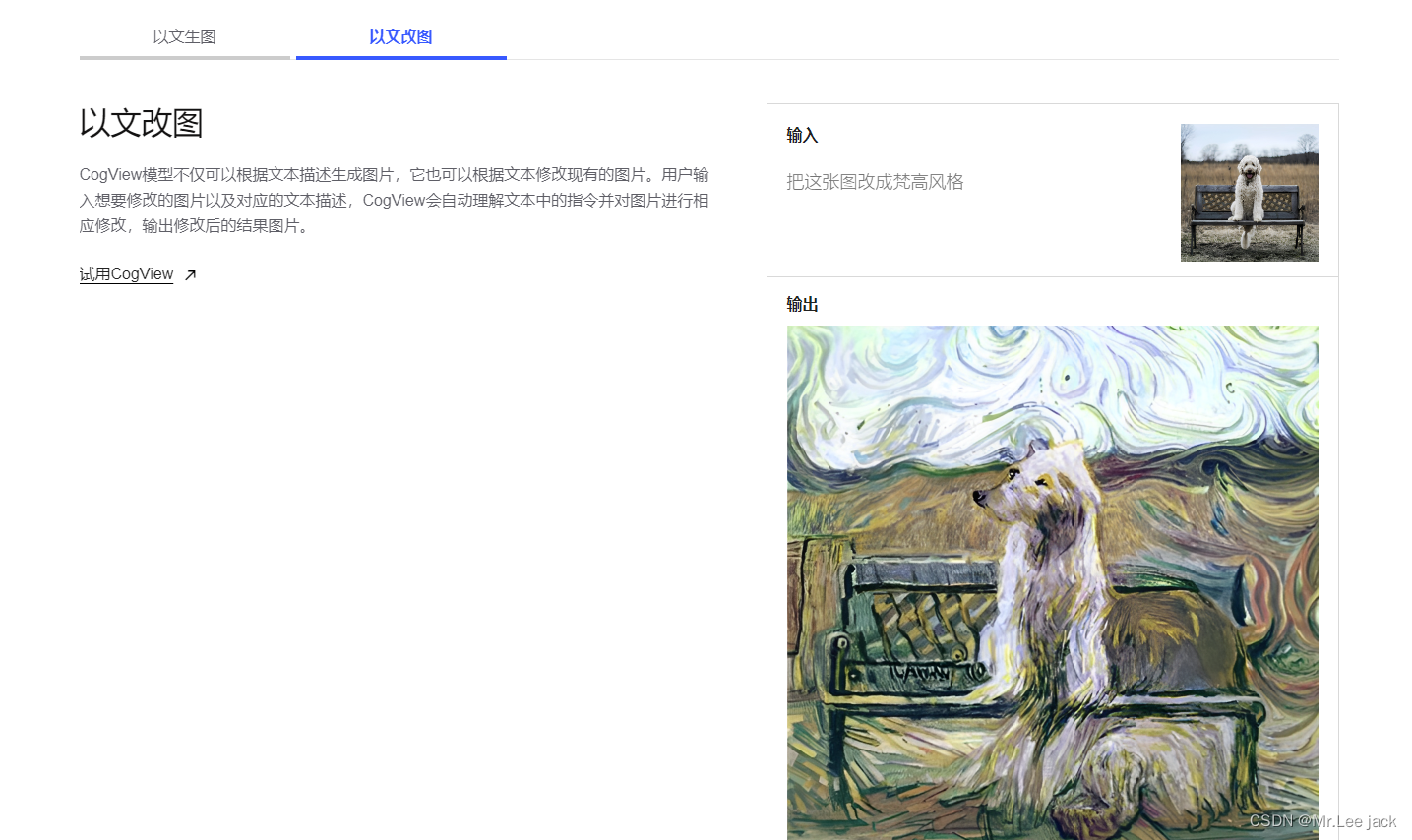
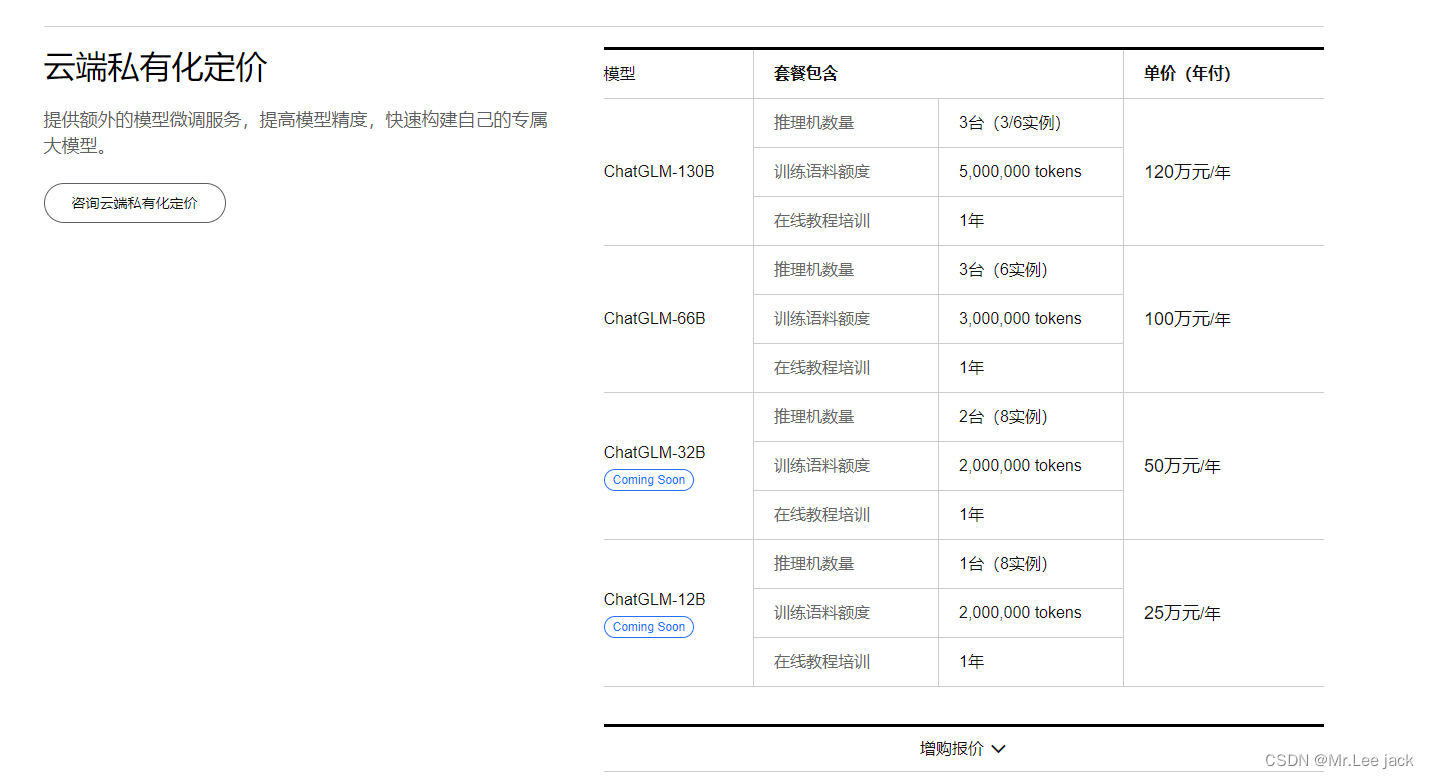
- GLM-130B 是清华大学与智谱AI共同研制的一个开放的双语(英汉)双向密集预训练语言模型,拥有 1300亿个参数,使用通用语言模型(General Language Model, GLM)的算法进行预训练。 2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。GLM-130B 在广泛流行的英文基准测试中性能明显优于 GPT-3 175B(davinci)
- 智谱AI是由清华大学计算机系技术成果转化而来的公司,致力于打造新一代认知智能通用模型。公司合作研发了双语千亿级超大规模预训练模型GLM-130B,并构建了高精度通用知识图谱,形成数据与知识双轮驱动
- https://github.com/THUDM/GLM-130B
- 智谱
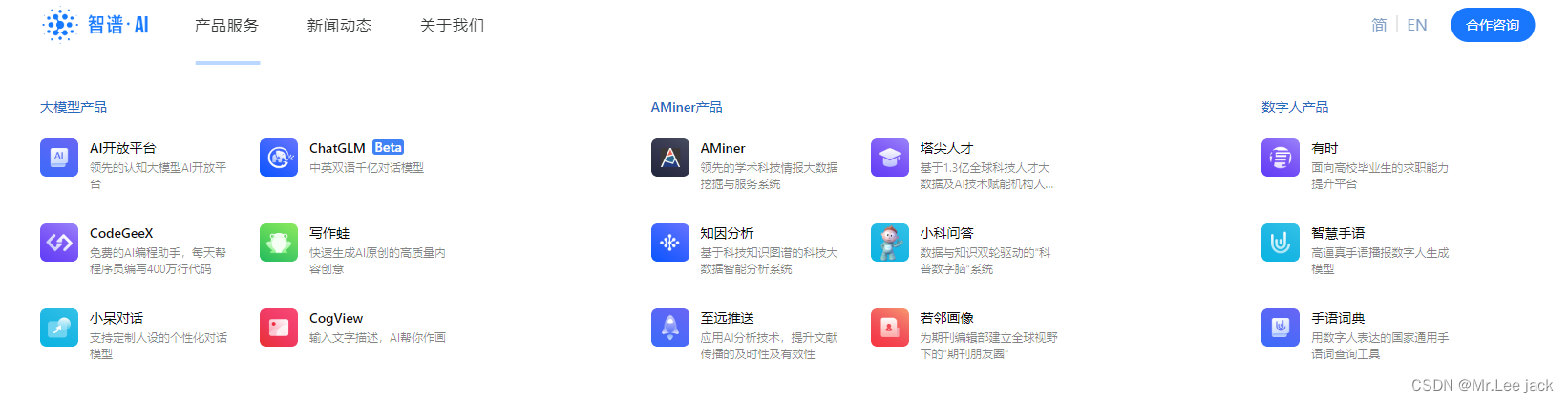
与chatGPT对比


LLaMA
- LLaMA 是 Meta AI 发布的包含 7B、13B、33B 和 65B 四种参数规模的基础语言模型集合,LLaMA-13B 仅以 1/10 规模的参数在多数的 benchmarks 上性能优于 GPT-3(175B),LLaMA-65B 与业内最好的模型 Chinchilla-70B 和 PaLM-540B 比较也具有竞争力
- 使用比通常更多的 tokens 训练一系列语言模型,在不同的推理预算下实现最佳的性能,也就是说在相对较小的模型上使用大规模数据集训练并达到较好性能。Chinchilla 论文中推荐在 200B 的 tokens 上训练 10B 规模的模型,而 LLaMA 使用了 1.4T tokens 训练 7B的模型,增大 tokens 规模,模型的性能仍在持续上升
- https://github.com/facebookresearch/llama
指示学习
- Instruction(指令)是指通过自然语言形式对任务进行描述。对于翻译任务,在对需要翻译的句子 “I Love You.” 前加入任务指令 “Translate the given English utterance to French script.”
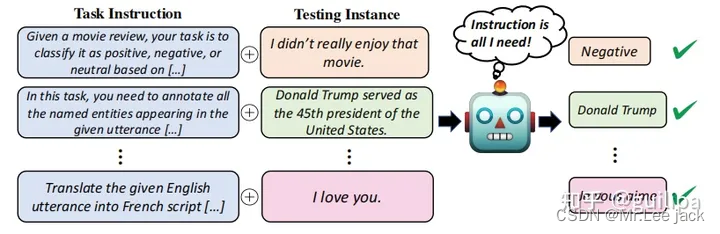

- 指示微调大模型
| 模型名称 | 发布时间 | 发布机构 | 语言 | 模态 | 参数规模 | 基础模型 | 是否开源 |
|---|---|---|---|---|---|---|---|
| GPT-3.5 | Jun-21 | OpenAI | 多语言 | 文本 | 175B | GPT-3 | × |
| FLAN | Sep-21 | 英 | 文本 | 137B | LaMDA | × | |
| T0 | Oct-21 | Hugging Face | 英 | 文本 | 13B | T5 | √ |
| Flan-PaLM | Oct-22 | 多语言 | 文本 | 540B | PaLM | × | |
| BLOOMZ | Nov-22 | Hugging Face | 多语言 | 文本 | 176B | BLOOM | √ |
| mT0 | Nov-22 | Hugging Face | 多语言 | 文本 | 13B | mT5 | √ |
| ChatGPT | Nov-22 | OpenAI | 多语言 | 文本 | 173B | GPT3.5 | × |
| Alpaca | 2023/3/14 | StandFord | 英 | 文本 | 7B | LLaMA | √ |
| ChatGLM | 2023/3/14 | Tsinghua | 中、英 | 文本 | 6B,130B | GLM | √ |
| GPT-4 | 2023/3/14 | OpenAI | 多语言 | 文本、图像 | GPT-4 | × | |
| ERNIE Bot | 2023/3/15 | Baidu | 中 | 文本、图像 | ERNIE | × | |
| Bard | 2023/3/21 | 英 | 文本 | 137B | LaMDA | × |
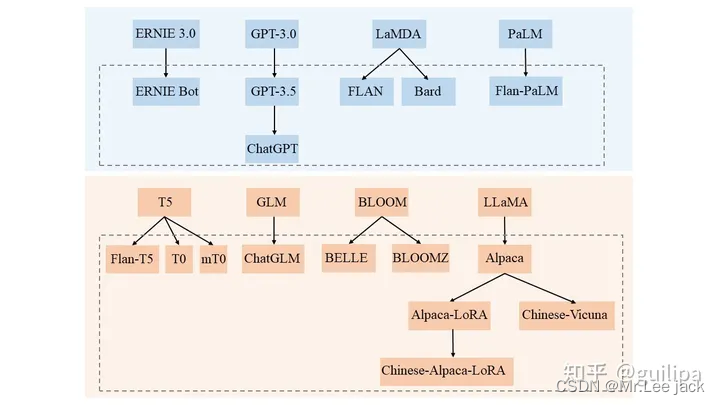
GPT-3.5 & ChatGPT 由来
- 参考
历史
- 2020年7月,发布GPT-3,最原始的 GPT-3 基础模型主要有 davinci、curie、ada 和 babbage 四个不同版本,其中 davinci 是功能最强大的,后续也都是基于它来优化的;
- 2021年7月,发布Codex[25],在代码数据上对 GPT-3 微调得到,对应着 code-davinci-001 和 code-cushman-001 两个模型版本;
- 2022年3月,发布 InstructGPT[26] 论文,对 GPT-3 进行指令微调 (supervised fine-tuning on human demonstrations) 得到 davinci-instruct-beta1 模型;在指令数据和经过标注人员评分反馈的模型生成样例数据上进行微调得到 text-davinci-001,InstructGPT 论文中的原始模型对应着 davinci-instruct-beta;
- 2022年6月,发布 code-davinci-002,是功能最强大的 Codex 型号,在文本和代码数据上进行训练,特别擅长将自然语言翻译成代码和补全代码;
- 2022年6月,发布 text-davinci-002,它是在code-davinci-002 基础上进行有监督指令微调得到;
- 2022年11月,发布 text-davinci-003 和 ChatGPT[27], 它们都是在 text-davinci-002 基础上利用人类反馈强化学习 RLHF 进一步微调优化得到
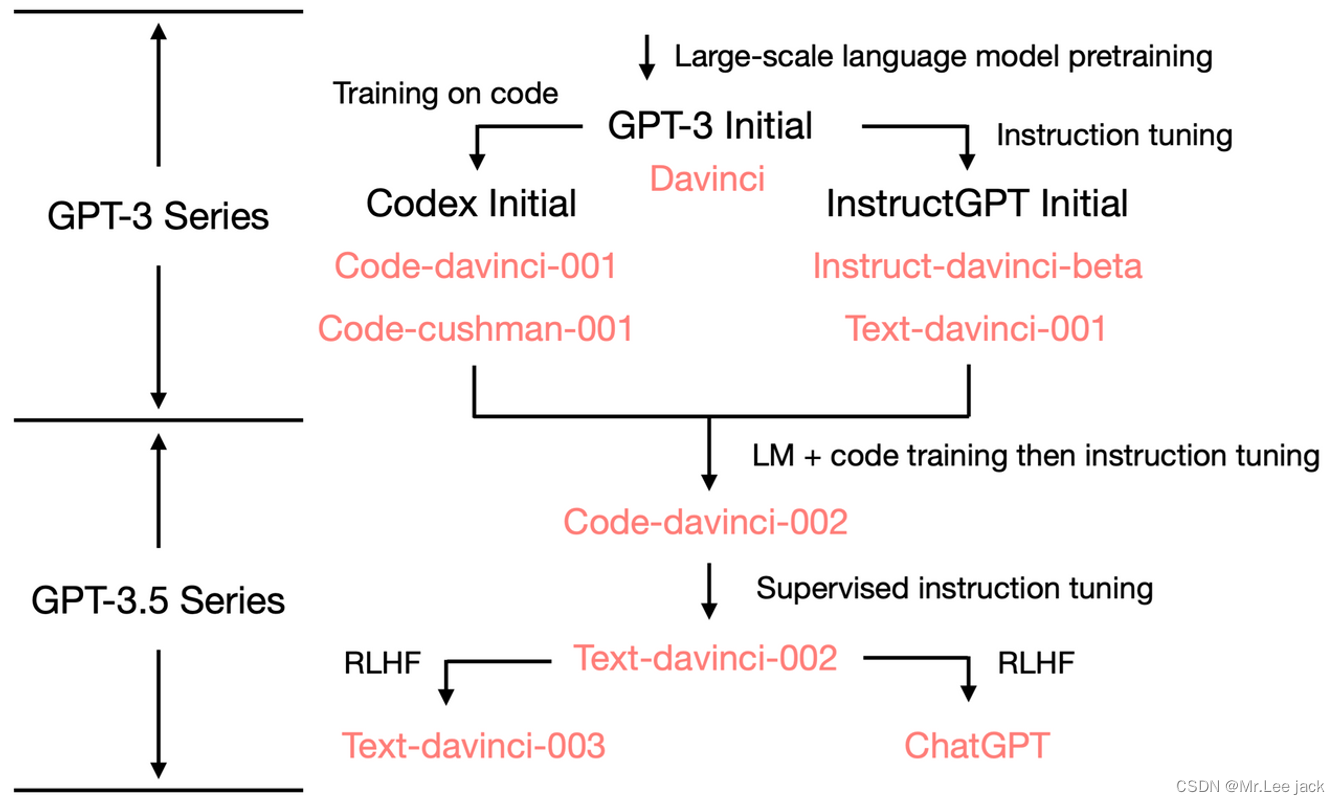
- ChatGPT 是在 GPT-3.5 基础上进行微调得到的,微调时使用了从人类反馈中进行强化学习的方法(Reinforcement Learning from Human Feedback,RLHF),这里的人类反馈其实就是人工标注数据,来不断微调 LLM,主要目的是让LLM学会理解人类的命令指令的含义(比如文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于给定的prompt输入指令(用户的问题),什么样的答案输出是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)
Alpaca
由来
- Alpaca(羊驼)模型是斯坦福大学基于 Meta 开源的 LLaMA-7B 模型微调得到的指令遵循(instruction-following)的语言模型。在有学术预算限制情况下,训练高质量的指令遵循模型主要面临强大的预训练语言模型和高质量的指令遵循数据两个挑战,作者利用 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 的指令遵循样本数据,利用这些数据训练以有监督的方式训练 LLaMA-7B 得到 Alpaca 模型。在测试中,Alpaca 的很多行为表现都与 text-davinci-003 类似,且只有 7B 参数的轻量级模型 Alpaca 性能可与 GPT-3.5 这样的超大规模语言模型性能媲美
- https://github.com/tatsu-lab/stanford_alpaca
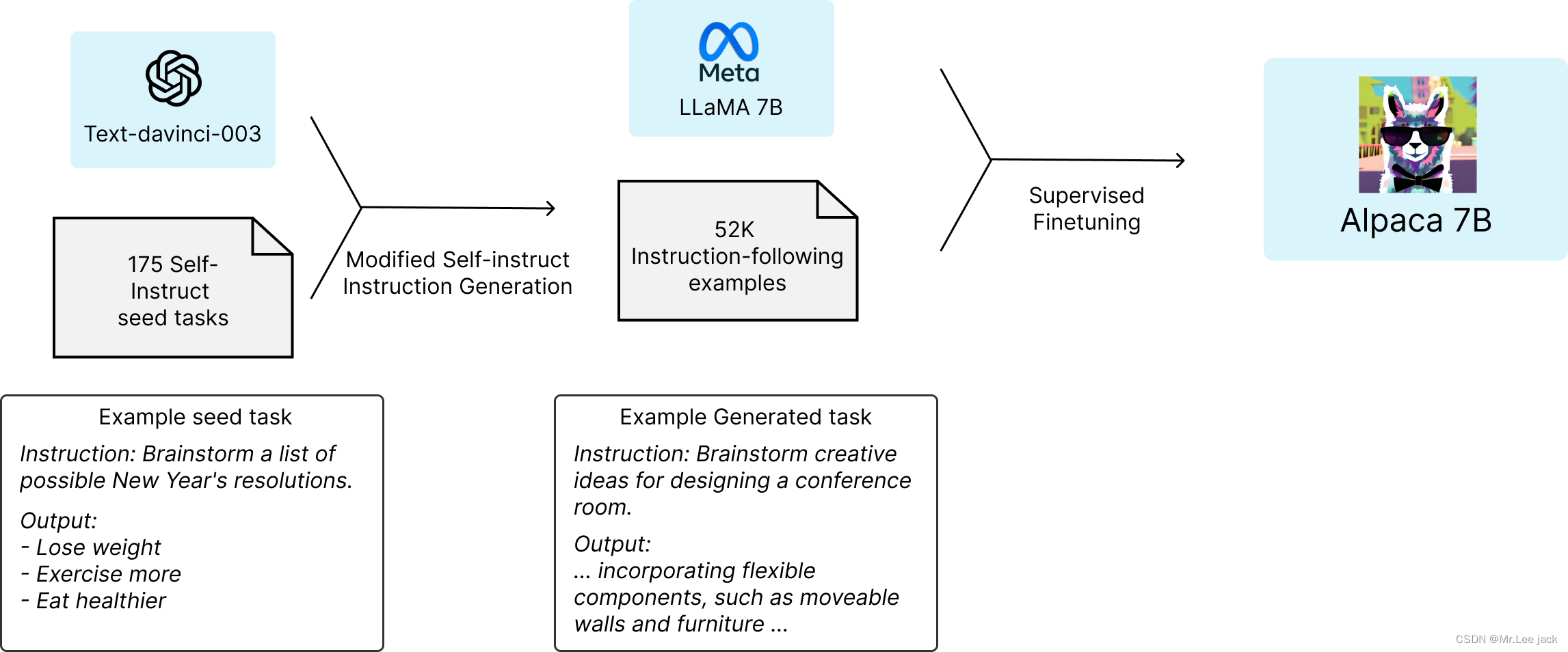
- 演进
- https://github.com/Facico/Chinese-Vicuna
- https://github.com/masa3141/japanese-alpaca-lora
- https://github.com/LC1332/Chinese-alpaca-lora
- https://github.com/Beomi/KoAlpaca
总结
- 模型结构
- 基础模型特点
- 指示模型演变
参考
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer https://arxiv.org/pdf/1910.10683.pdf
- mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer https://arxiv.org/pdf/2010.11934.pdf
- Language Models are Few-Shot Learners https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2005.14165.pdf
- LaMDA: Language Models for Dialog Applications https://arxiv.org/pdf/2201.08239.pdf
- Jurassic-1: Technical Details and Evaluation https://uploads-ssl.webflow.com/60fd4503684b466578c0d307/61138924626a6981ee09caf6_jurassic_tech_paper.pdf
- Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model https://arxiv.org/pdf/2201.11990.pdf
- Scaling Language Models: Methods, Analysis & Insights from Training Gopher https://storage.googleapis.com/deepmind-media/research/language-research/Training%20Gopher.pdf
- Training Compute-Optimal Large Language Models https://arxiv.org/pdf/2203.15556.pdf
- PaLM: Scaling Language Modeling with Pathways https://arxiv.org/pdf/2204.02311.pdf
- Pathways: Asynchronous Distributed Dataflow for ML https://arxiv.org/pdf/2203.12533.pdf
- Transcending Scaling Laws with 0.1% Extra Compute https://arxiv.org/pdf/2210.11399.pdf
- UL2: Unifying Language Learning Paradigms https://arxiv.org/pdf/2205.05131.pdf
- OPT: Open Pre-trained Transformer Language Models https://arxiv.org/pdf/2205.01068.pdf
- LLaMA: Open and Efficient Foundation Language Models https://arxiv.org/pdf/2302.13971v1.pdf
- BLOOM: A 176B-Parameter Open-Access Multilingual Language Model https://arxiv.org/pdf/2211.05100.pdf
- GLM-130B: An Open Bilingual Pre-Trained Model https://arxiv.org/pdf/2210.02414.pdf
- ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation https://arxiv.org/pdf/2112.12731.pdf
- ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation https://arxiv.org/pdf/2107.02137.pdf
- Is Prompt All You Need? No. A Comprehensive and Broader View of Instruction Learning https://arxiv.org/pdf/2303.10475v2.pdf
- T0 Multitask Prompted Training Enables Zero-Shot Task Generalization https://arxiv.org/pdf/2110.08207.pdf
- Finetuned Language Models Are Zero-shot Learners https://openreview.net/pdf?id=gEZrGCozdqR
- Scaling Instruction-Finetuned Language Models https://arxiv.org/pdf/2210.11416.pdf
- Crosslingual Generalization through Multitask Finetuning https://arxiv.org/pdf/2211.01786.pdf
- GPT-3.5 https://platform.openai.com/docs/models/gpt-3-5
- Evaluating Large Language Models Trained on Code https://arxiv.org/pdf/2107.03374.pdf
- Training language models to follow instructions with human feedback https://arxiv.org/pdf/2203.02155.pdf
- OpenAI Blog: Introducting ChatGPT https://openai.com/blog/chatgpt
- OpenAI Blog: Introducing ChatGPT https://openai.com/blog/chatgpt
- OpenAI Blog: GPT-4 https://openai.com/research/gpt-4
- Alpaca: A Strong, Replicable Instruction-Following Model https://crfm.stanford.edu/2023/03/13/alpaca.html
- ChatGLM:千亿基座的对话模型开启内测 https://chatglm.cn/blog
![[前端]JS——join()与split()的使用](https://img-blog.csdnimg.cn/ff8dcc9677444395921ee0eac6dd121e.png)