目录
需求
多线程TCP服务器
线程池TCP服务器
测试
日志模块
需求
多线程TCP服务器(30分):
设计编写一个TCP服务器端程序,需使用多线程处理客户端的连接请求。客户端与服务器端之间的通信内容,以及服务器端的处理功能等可自由设计拓展,无特别限制和要求。
线程池TCP服务器(30分):
设计编写一个TCP服务器端程序,需使用线程池处理客户端的连接请求。客户端与服务器端之间的通信内容,以及服务器端的处理功能等可自由设计拓展,无特别限制和要求,但应与第1项要求中的服务器功能一致,便于对比分析。
比较分析不同编程技术对服务器性能的影响(20分):
自由编写客户端程序和设计测试方式,对1和2中的服务器端程序进行测试,分析比较两个服务器的并发处理能力。
设计编写可重用的服务器日志程序模块,日志记录的内容和日志存储方式可自定(比如可以记录客户端的连接时间、客户端IP等,日志存储为.TXT或.log文件等),分别在1和2的服务器程序中调用该日志程序模块,使多线程TCP服务器和线程池TCP服务器都具备日志功能,注意线程之间的同步操作处理。(20分)
多线程TCP服务器
这段代码是一个基于Java的多线程服务器实现,用于接收客户端的连接并处理其发送的消息。
-
首先,在
MultithreadingServer类的main方法中:- 创建了一个
ServerSocket对象,并指定它监听的端口号为8888,同时设置最大连接数量为10000。 - 进入一个无限循环,用于持续接受客户端的连接请求。
- 每次循环,当有客户端连接时,创建一个新的
MultiThread实例,并传入对应的Socket对象。 - 同时,创建一个
Logger实例,记录连接的相关信息,包括客户端的IP地址、连接时间和日志文件名。
- 创建了一个
-
在
MultiThread类中:- 继承了
Thread类,并重写了run方法。 - 在
run方法中,通过BufferedReader从Socket的输入流获取一个字符输入流,并通过InputStreamReader将其转换为字符流,然后读取客户端发送的数据。 - 使用一个循环来连续读取,直到达到输入流的末尾(客户端关闭连接)为止。
- 在每次循环中,打印接收到的消息到标准输出。
- 最后,关闭输入流和
Socket连接。
- 继承了
整体而言,这段代码实现了一个简单的多线程服务器,能够接收并处理客户端的连接请求,以及读取和输出客户端发送的消息。日志记录部分使用了自定义的Logger类,但其具体实现不在这段代码中显示。需要注意的是,异常处理方面可能需要根据实际需求进行补充和调整。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Date;
public class MultithreadingServer {
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(8888, 10000);
while (true) {
Socket client = serverSocket.accept();
new MultiThread(client).start();
new Logger(client.getInetAddress().getHostAddress(), new Date(), "LogMultithreadingServer.txt");
}
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
class MultiThread extends Thread {
private Socket socket = null;
public MultiThread(Socket socket) {
this.socket = socket;
}
public void run() {
try {
BufferedReader input = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String message = null;
while ((message = input.readLine()) != null) {
System.out.println(message);
}
input.close();
socket.close();
} catch (IOException error) {
error.printStackTrace();
}
}
}线程池TCP服务器
这段代码是一个使用线程池的多线程服务器实现,与前面的代码相比,在并发处理客户端连接方面进行了改进。
-
在
ThreadPoolServer类的main方法中:- 创建了一个具有200个线程的固定大小线程池
ExecutorService。 - 创建了一个
ServerSocket对象,并指定它监听的端口号为9999,同时设置最大连接数量为10000。 - 进入一个无限循环,用于持续接受客户端的连接请求。
- 每次循环,当有客户端连接时,将一个新的
TheadPoolTask任务提交给线程池进行执行。 - 同时,创建一个
Logger实例,记录连接的相关信息,包括客户端的IP地址、连接时间和日志文件名。
- 创建了一个具有200个线程的固定大小线程池
-
在
TheadPoolTask类中:- 实现了
Runnable接口,并重写了run方法。 - 在
run方法中,通过BufferedReader从Socket的输入流获取一个字符输入流,并通过InputStreamReader将其转换为字符流,然后读取客户端发送的数据。 - 使用一个循环来连续读取,直到达到输入流的末尾(客户端关闭连接)为止。
- 在每次循环中,打印接收到的消息到标准输出。
- 最后,关闭输入流和
Socket连接。
- 实现了
整体而言,这段代码与前一段代码类似,不同之处在于使用了线程池来管理线程资源,提高了并发处理能力。通过将任务提交给线程池执行,可以控制并发线程数,并重复利用线程,避免频繁创建和销毁线程带来的开销。需要注意的是,异常处理方面可能需要根据实际需求进行补充和调整。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Date;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolServer {
public static void main(String[] args) {
ExecutorService executorService= Executors.newFixedThreadPool(200);
try{
ServerSocket serverSocket=new ServerSocket(9999,10000);
while(true){
Socket client=serverSocket.accept();
executorService.execute(new TheadPoolTask(client));
new Logger(client.getInetAddress().getHostAddress(),new Date(),"LogThreadPoolServer.txt");
}
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}finally {
executorService.shutdown();
}
}
}
class TheadPoolTask implements Runnable{
private Socket socket=null;
public TheadPoolTask(Socket socket){
this.socket=socket;
}
public void run(){
try{
BufferedReader input=new BufferedReader(new InputStreamReader(socket.getInputStream()));
String message=null;
while((message=input.readLine())!=null){
System.out.println(message);
}
input.close();
socket.close();
}catch (IOException error){
error.printStackTrace();
}
}
}测试
编写一个压力测试程序,测试多线程服务器和线程池服务器在高并发时的表现,实现run()方法,发起连接请求,为了保证多线程并发访问long类型变量时的线程安全性,使用线程安全的AtomicLong类来记录服务器响应的时间,如图7所示,附件已含源代码。
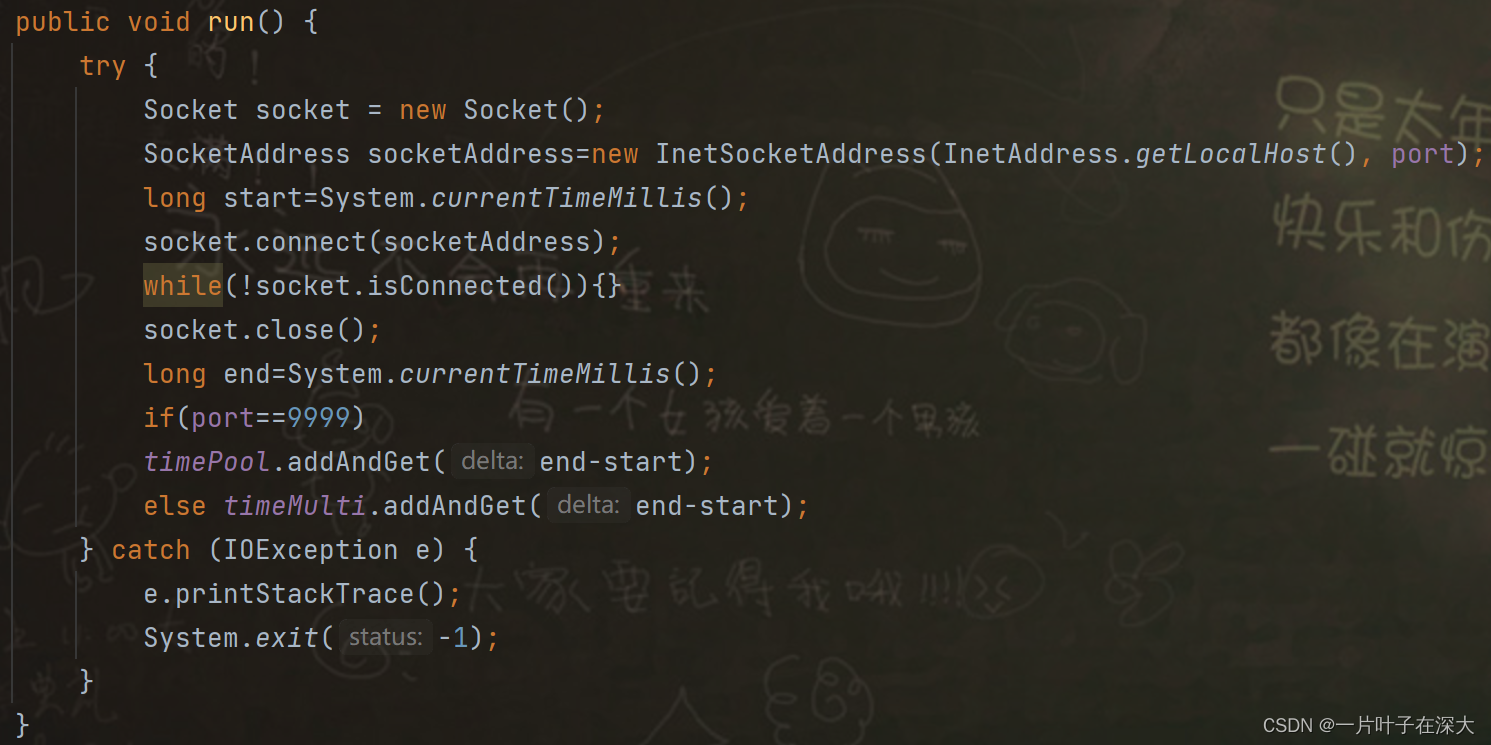
图7
主程序同时向两个服务器发起多个连接,连接规模从1000个连接请求开始一直增加到10000个,通过在短时间内发起大量连接请求来对服务器进行压力测试,如图8所示。
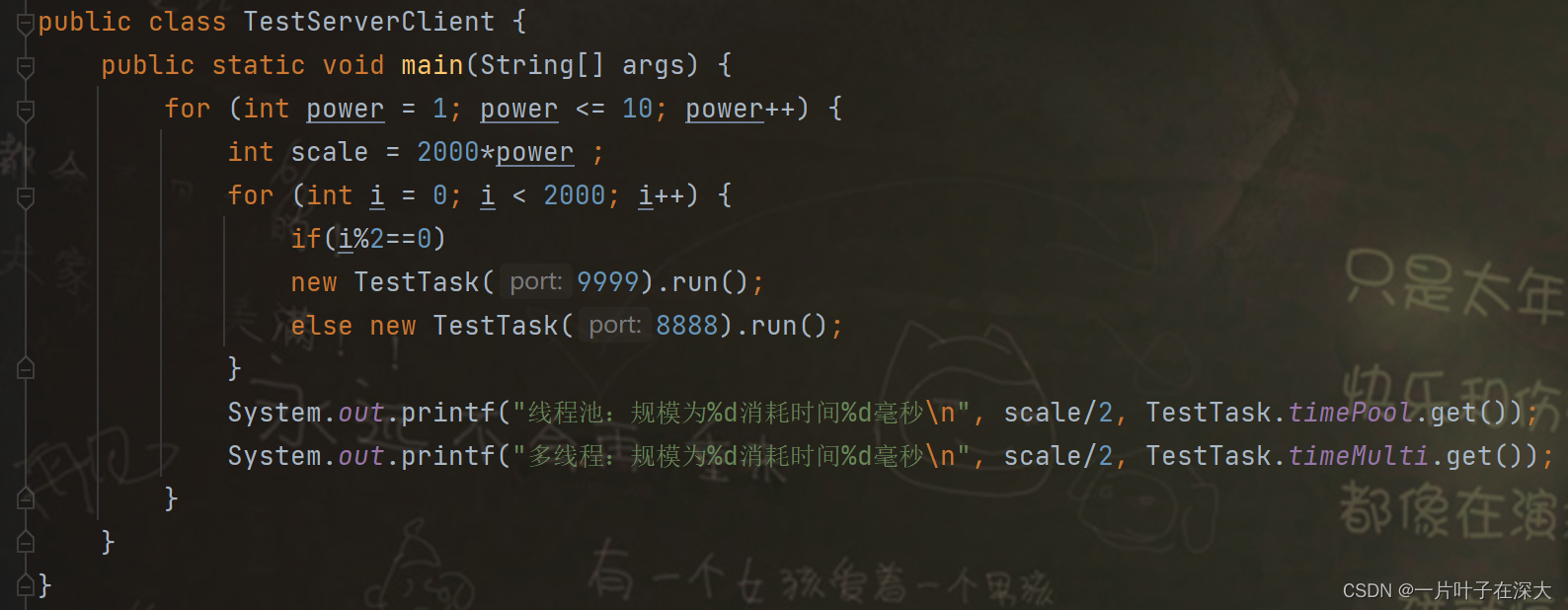
图8
测试过程数据如图9所示。

图9
分析两个服务器的表现情况,如图10所示,可见在处理大量短任务(如处理网络请求)的情况下,使用线程池可以避免频繁地创建、销毁线程所带来的开销,因此会更快一些。
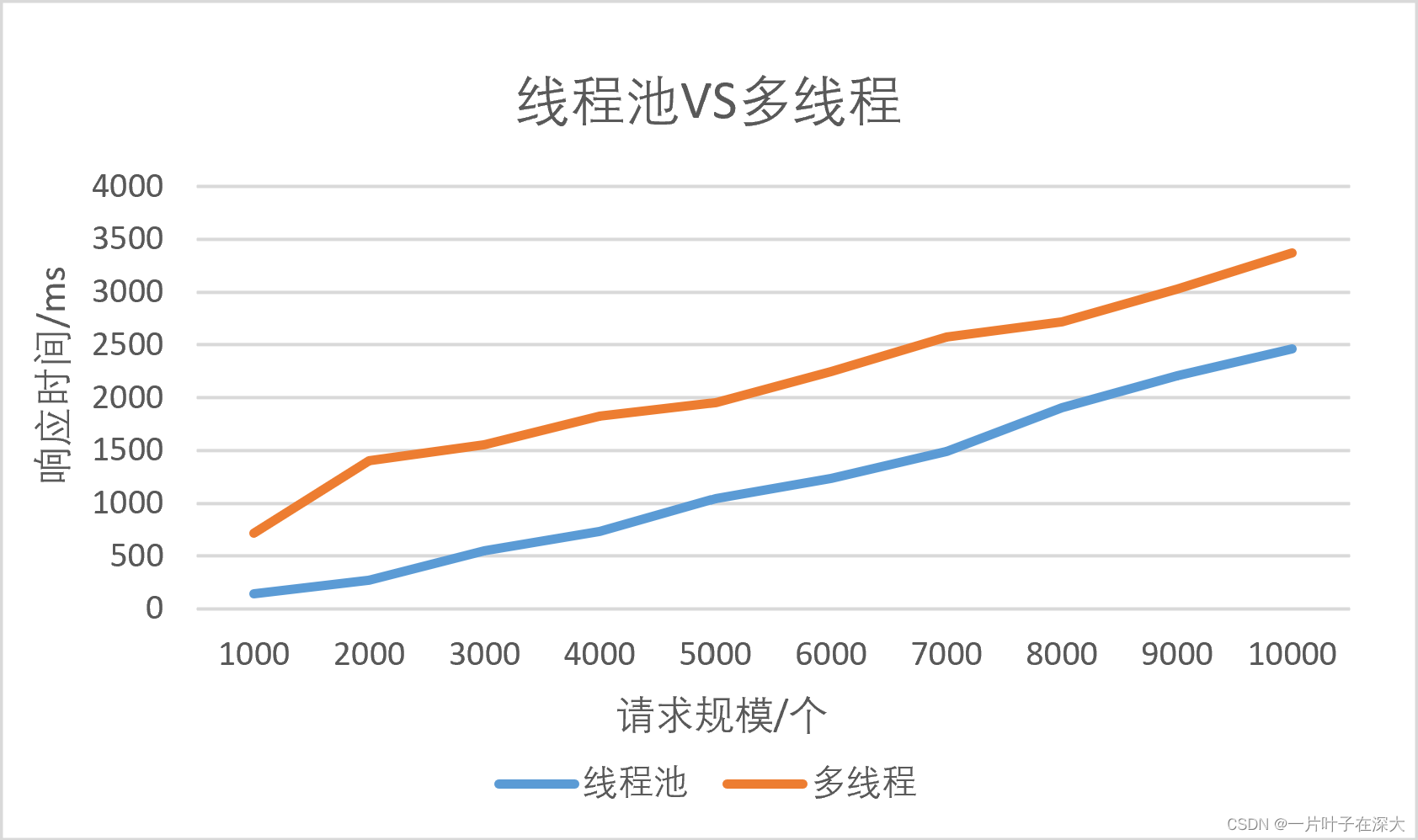
图10
这段代码是一个简单的测试服务器和客户端的程序。
-
在
TestServerClient类的main方法中:- 通过循环来控制不同规模(power)的测试。
- 在每个测试规模下,通过嵌套循环启动一定数量(2000)的测试任务。
- 每个测试任务使用
TestTask类创建一个线程,构造函数传入不同的端口号(9999或8888),然后调用run方法运行测试任务。 - 在每次测试任务完成后,将消耗的时间输出到控制台。
-
在
TestTask类中:- 定义了一个
port变量,表示客户端连接的目标端口。 - 声明了两个静态的
AtomicLong对象timePool和timeMulti,用于记录线程池和多线程方式的测试消耗时间。 - 在构造函数中接收一个端口号,并将其赋值给
port变量。 run方法实现了客户端的测试逻辑:- 创建一个空的
Socket对象。 - 构建
InetSocketAddress对象,指定本地主机地址和目标端口。 - 记录当前时间为起始时间。
- 调用
socket.connect方法与服务器建立连接,等待连接完成。 - 关闭
socket对象。 - 记录当前时间为结束时间。
- 根据不同的端口号,将测试消耗时间累加到相应的
AtomicLong对象中。
- 创建一个空的
- 定义了一个
该程序的主要目的是通过多次连接服务器的测试来比较线程池和多线程方式的性能消耗。它会启动一定数量的测试任务,并分别记录两种方式的测试消耗时间。在每次测试任务完成后,将消耗时间输出到控制台。通过对不同规模测试结果的比较,可以初步评估线程池和多线程方式的性能表现。
import java.io.IOException;
import java.net.*;
import java.util.concurrent.atomic.AtomicLong;
public class TestServerClient {
public static void main(String[] args) {
for (int power = 1; power <= 10; power++) {
int scale = 2000*power ;
for (int i = 0; i < 2000; i++) {
if(i%2==0)
new TestTask(9999).run();
else new TestTask(8888).run();
}
System.out.printf("线程池:规模为%d消耗时间%d毫秒\n", scale/2, TestTask.timePool.get());
System.out.printf("多线程:规模为%d消耗时间%d毫秒\n", scale/2, TestTask.timeMulti.get());
}
}
}
class TestTask{
private final int port;
public static AtomicLong timePool =new AtomicLong();
public static AtomicLong timeMulti=new AtomicLong();
public TestTask(int port) {
this.port = port;
}
public void run() {
try {
Socket socket = new Socket();
SocketAddress socketAddress=new InetSocketAddress(InetAddress.getLocalHost(), port);
long start=System.currentTimeMillis();
socket.connect(socketAddress);
while(!socket.isConnected()){}
socket.close();
long end=System.currentTimeMillis();
if(port==9999)
timePool.addAndGet(end-start);
else timeMulti.addAndGet(end-start);
} catch (IOException e) {
e.printStackTrace();
System.exit(-1);
}
}
}
日志模块
这段代码是一个简单的日志记录器类。它具有以下功能:
-
构造函数:接受一个IP地址、日期和文件路径作为参数,并生成一条以IP地址和日期为内容的日志信息。
-
keep() 方法:该方法使用了 synchronized 关键字,以确保在多线程环境下只有一个线程可以访问该方法。在方法内部,它创建一个 BufferedWriter 对象,并将日志内容写入指定的文件中。
总体来说,这个代码实现了一个基本的日志记录功能,将用户登录的 IP 地址和日期写入指定的文件中。
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Date;
public class Logger {
private final String log;
private final String filePath;
public Logger(String IP, Date date,String filePath){
log=IP+" login at "+date.toString()+'\n';
this.filePath=filePath;
keep();
}
private synchronized void keep(){
try {
BufferedWriter bufferedWriter=new BufferedWriter(new FileWriter(filePath,true));
bufferedWriter.write(log);
bufferedWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}