结构体
1、结构体类型的声明
1.1、结构的基础知识
结构是一些值得集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
1.2、结构体类型的声明
struct tag
{
member-list;
}variable-list;
//写法一:
struct Stu
{
char name[20];
int age;
};
//写法二:
struct Stu
{
char name[20];
int age;
}s1,s2; //这个s1,s2就是利用上面的结构体类型创建的结构体变量。这个s1/s2里面包含了name和age。
值得说明一下,上面我们写出来的只是一个结构体类型而已。就相当于是int,float,double数据类型。
1.3、结构体变量的创建
结构体变量的创建有两种方法:
//方法一:(全局变量)
struct Stu
{
char name[20];
int age;
}s1,s2; //这个s1和s2是由struct Stu结构体类型创建的结构体变量,但是它们的位置是在main函数外面的,所以s1和s2是全局变量。
int main()
{
return 0;
}
方法二:(局部变量)
struct Stu
{
char name[20];
int age;
};
int main()
{
struct Stu s3; //s3是由struct Stu类型的结构体类型创建的结构体变量,因为这个s3在main函数里面,所以是局部变量。
return 0;
}
1.4、匿名结构体类型
所谓的匿名结构体类型,就是把结构体的tag部分去掉了。如下:
//省略了结构体标签(tag)
struct
{
int a;
int b;
float c;
}s1; //如果是匿名结构体类型,就必须在这里创建结构体变量,并且只能使用一次,因为下次想使用的时候找不到结构体tag,所以无法再次创建结构体变量,所以只能使用s1这一次。
2、结构体的自引用
在结构中包含一个类型为该结构本身的成员是否可以呢?
下面先来简单补充一点数据结构的知识:
数据结构:数据在内存中的存储结构。
数据结构分为:
- 线性数据结构
- 顺序表
- 链表
- …
- 树形数据结构
- 二叉树
- …
我们来看一下线性数据结构:
比如现在我想在内存中存储几个值:1,2,3,4,5。那我们能不能把这几个值在内存中连续存放呢?就像数组那样。答案:可以的。那这样的就叫做顺序表。
那每个数据不连续存放,而是分别分散在内存中的位置,就是链表。那链表如何找到数据呢?
比如存储的数据:1、2、3、4、5。我们可以这样,将1可以找到2,将2可以找到3,将3可以找到4,将4可以找到5。这样就像链子一样将这几个数据链在一起,就能找到全部的数据了。

那具体的链表怎么实现呢?也就是说如何实现1可以找到2,2可以找到3…。这样的操作呢?
现在我们把存放1的位置叫做节点1、存放2的位置叫做结点2…。
那把1节点中包含2节点,是不是就能找到数据2了?那把2节点中包含3节点,是不是就能找到数据3了?
那这样一说好像就能实现链表的功能了。我们先来尝试实现一下:
struct Node
{
//这个存放本节点的数据
int date;
//这个存放下一个节点
struct Node next;
};
这样就行了吗?其实不然,这样写是有问题的!
因为我们不知道这个结构体有多大,因为这个Node里面存放了next,next又存放了date和Node,然后Node里面存放了next…就这样无限套娃下去。所以这是不可取的。
正确的做法应该是:1节点中包含2节点的地址,然后2节点中包含3节点的地址,以此类推。重点:包含的是节点的地址。代码实现:
struct Node
{
//这个存放本节点的数据,叫做数据域。
int date;
//这个存放下一个节点的地址,叫做指针域。
struct Node* next;
};
重点回顾:结构体的自引用:结构体里面包含的指针能够找到自己同类型的一个节点。
以上也是实现链表的基础。
3、结构体变量的定义和初始化
有了结构体类型,那如何定义变量,其实很简单。
struct Point
{
int x;
int y;
}p1 = {2,3}; //定义结构体类型的同时,定义结构体变量p1。
struct Point p2; //定义结构体变量p2
//初始化:定义变量的同时赋值
struct Point p3 = {x,y};
struct Stu //类型声明
{
char name[20]; //名字
int age; //年龄
};
struct Stu s = {"aaa",12}; //初始化
注意:这里声明出结构体类型,是不会在内存中开启空间的。只有当利用结构体类型创建了结构体变量,这个时候此结构体才会在内存中占用空间。
结构体类型就相当于是个盖房子的图纸,而结构体变量才是这个图纸的实体。
4、结构体内存对齐
现在来讨论一个问题:计算结构体的大小。
这也是一个热门的考点:结构体内存对齐。
引入问题:下面我们来计算一个结构体的大小:
#include <stdio.h>
struct S1
{
char c1;
int i;
char c2;
};
int main()
{
//计算一个结构体(变量)的大小。
printf("%d\n", sizeof(struct S1));
return 0;
}
输出:

4.1、对齐规则
考点
如何计算?
首先得掌握结构体的对齐规则。
1、第一个成员变量在与结构体变量偏移量为0的地址处。
2、其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数与该成员大小的较小值。
VS编译器中默认的值为8。
其它大部分编译器没有默认对齐数,那成员变量的对齐数就是其字节大小。
3、结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4、如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处。结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
好的,当我们知道了对齐规则后,我们以上面的示例来分析,结构体大小到底这是怎么计算出来的:
#include <stdio.h>
struct S1
{
char c1;
int i;
char c2;
};
int main()
{
struct S1 s1;
//计算一个结构体(变量)的大小。
printf("%d\n", sizeof(struct S1));
return 0;
}
4.2、计算结构体大小
1、首先使用结构体类型创建出一个结构体变量s1。假设s1在内存中存放的起始位置是(如下图:)

2、偏移量:结构体变量下面的字节相对于起始位置的差值就是偏移量。比如:s1存储的第1个字节相对于s1起始位置的偏移量就是0,那s1存储的第2个字节相对于s1起始位置的偏移量就是1,s1存储的第3个字节相对于s1起始位置的偏移量就是2…以此类推。
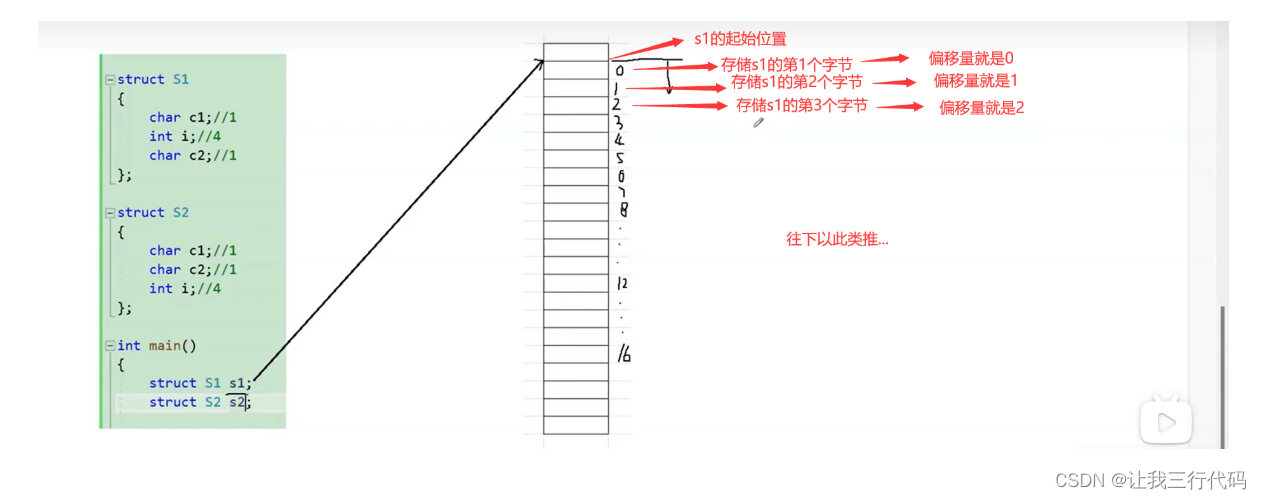
好,在了解了上面的知识后,下面来开始计算每一个成员变量的大小。
3、我们先来看第一个成员变量:char c1;,是如何计算存储大小的。它对应了第一句话:第一个成员变量在与结构体变量偏移量为0的地址处。可以看到第一个成员变量是存储在了与结构体变量偏移量为0的地址处了,并且c1是char类型的数,只占1个字节,那可想而知c1存储的位置,就是(如下图)第一个字节处的位置上:
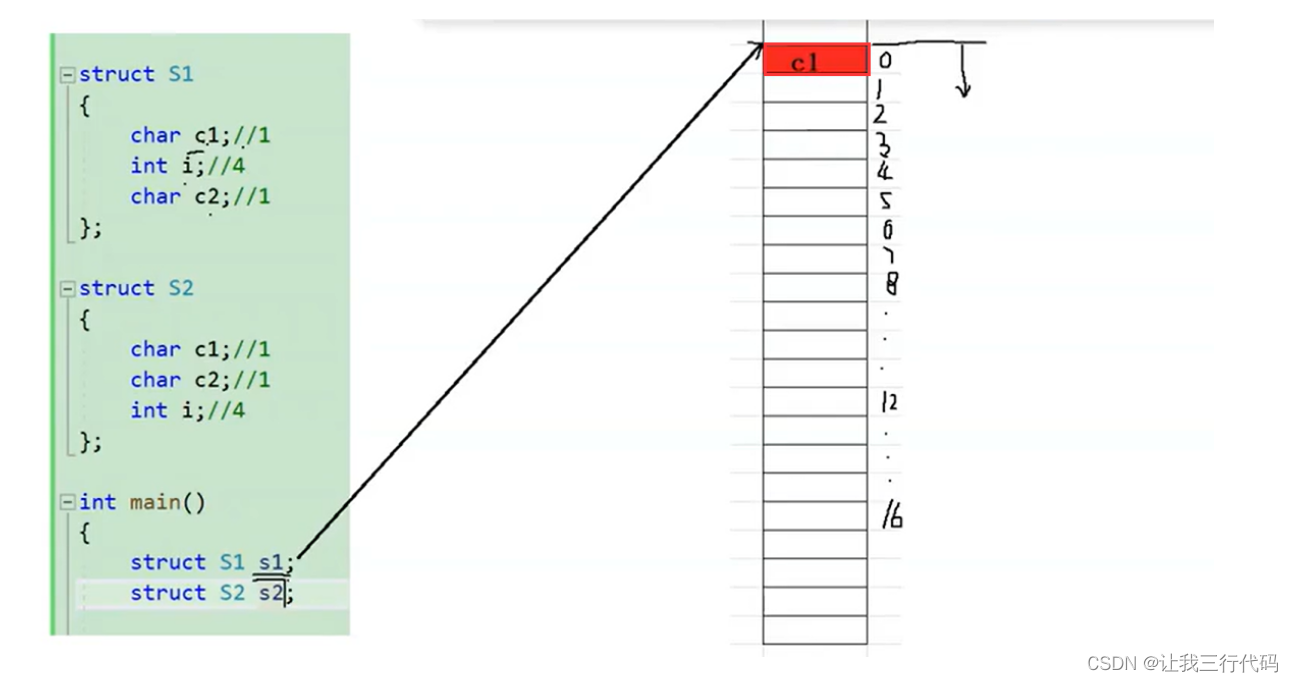
4、计算其它成员变量,它对应了这句话:其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
下面的对齐规则,适用于除了第一个成员变量之外的所有成员变量。
- 对齐数:编译器默认的一个对齐数与该成员大小的较小值。
- VS编译器中默认的值为8。
想要计算出第二个成员变量:int i;的存储大小,前提需要知道它的对齐数。
如何得出对齐数呢?
int i自身大小是4个字节,而VS编译器的对齐数默认是8,4和8相比较,得出最小值为4。所以这个4就是第二个成员变量:int i;的对齐数。
知道了对齐数为4后,我们只需要再找到偏移量是4的倍数处的位置开始存储,就是存储第二个成员变量的地址处。
那因为偏移量0处的位置被c1占用了,并且偏移量1,2,3不是4的倍数。所以最终i被存储在了偏移量为4处的位置上了,又因为i是int类型的,占用4个字节,所以整体还需要往下占用4个字节的空间,如下图:

然后我们来看一下现在的内存占用情况:
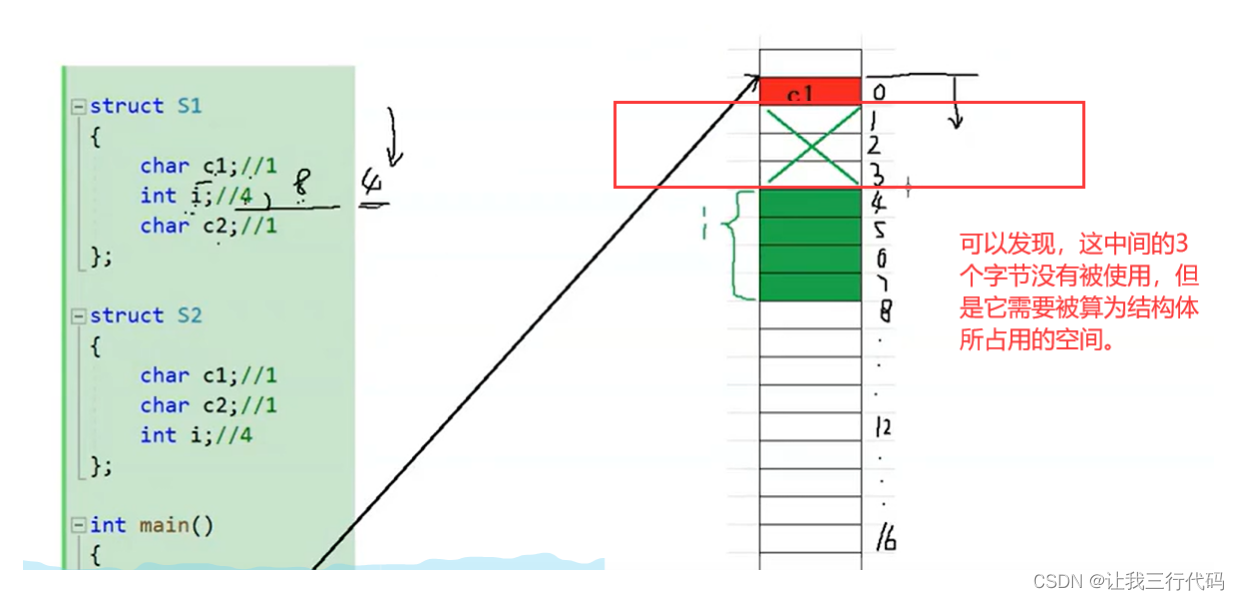
5、计算第三个成员变量。
计算第三个成员变量还是按照上面的规则来。
首先需要得到第三个成员的对齐数。
VS编译器默认的对齐数为8,而第三个成员变量:char c2;的字节大小为1,所以去做较小值为1。
所以第三个成员的对齐数的为1。
对齐数得到后,只需要找偏移量是1的倍数的位置即可。因为每一个数都是1的倍数,所以c2变量直接放在偏移量为8的位置处,如下图:
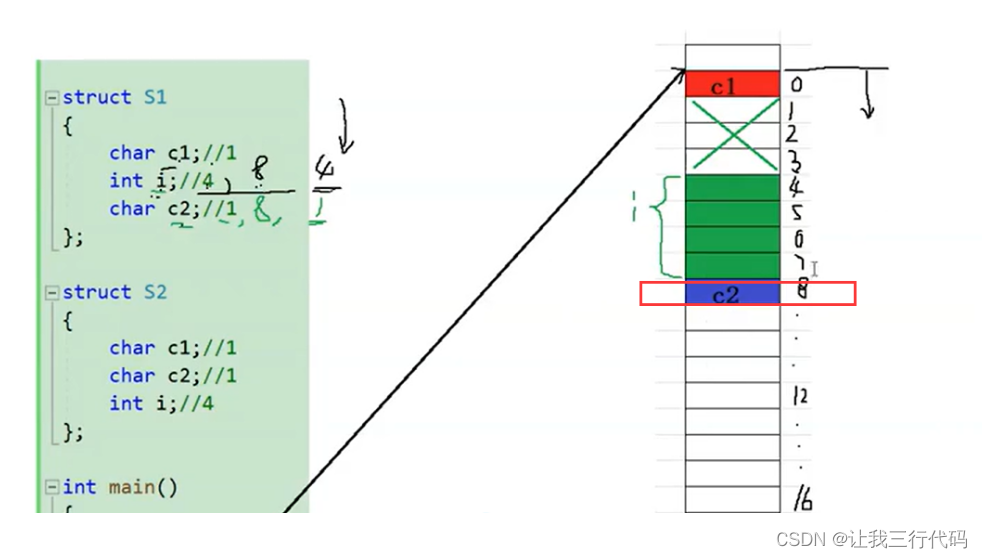
那好现在我们来看一下,这三个成员变量一共占用了9个字节。
但是输出的12个字节怎么来的呢?
别急,下面介绍:
6、计算结构体总本身大小:
它对应这句话:结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
还是需要前提得到结构体本身的对齐数,结构体本身的对齐数如何得到呢?是需要将结构体中所有成员变量所对应的对齐数,一一比较,然后得出的最大值就是,就是结构体对齐数。
注意:这里的对齐数不是字节个数,这个别混淆了。
我们再来计算一下每个成员变量的对齐数:
- 第一个成员变量:
char c1;,字节数为1,VS对齐数为8,相比较得出较小值为1,所以c1的对齐数就是1。 - 第二个成员变量:
int i;,字节数为4,VS对齐数为8,相比较得出较小值为4,所以c1的对齐数就是4。 - 第三个成员变量:
char c2;,字节数为1,VS对齐数为8,相比较得出较小值为1,所以c1的对齐数就是1。
得出每个成员变量的对齐数后,然后将其进行比较(1,4,1)得出最大值,最大值为4。
到这,得出了结构体本身的对齐数,然后再看这句话:结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。,结构体__总__大小是最大对齐数的整数倍。因为现在结构体占用了9个字节(8个偏移量)的大小,(注意:这里开始算倍数是以字节为单位开始算的。不在按照偏移量算了)。9又不是4的倍数,所以向下推,一直到第12字节处,是4的倍数后,才满足这个规则。所以此结构体大小一共是12个字节(11个偏移量)。
这里特殊说明一下:如果结构体里面有个成员变量是数组,比如:char arr[5]。
那在看char arr[5]的对齐数的时候,可以直接把此数组,拆分为5和char类型的数据即可。
但是这里并不能说char arr[5]和5和char类型是等价的。
4.3、验证上述计算结构体大小的结果
怎么去验证呢?这里从偏移量入手。
上面说了,第一个成员变量的偏移量是0,第二个成员变量的偏移量是4,第一个成员变量的偏移量是8。
然这里使用一个库函数offsetof(),来计算以下偏移量,如果匹配,那说明我们分析得对。
offsetof()得使用:
offsetof (type,member);
//第一个参数:是数据类型,这里我们验证结构体,那肯定就是传参结构体类型
//第二个参数:传参,结构体成员变量
如下代码:
#include <stdio.h>
#include <stddef.h>
struct S1
{
char c1;
int i;
char c2;
};
int main()
{
//计算一个结构体(变量)的大小。
printf("%d\n", offsetof(struct S1, c1));
printf("%d\n", offsetof(struct S1, i));
printf("%d\n", offsetof(struct S1, c2));
return 0;
}
输出:

可以看到,变量c1得偏移量是0,变量i得偏移量是4,变量c2得偏移量是8。说明上面分析的没问题。
4.4、计算嵌套结构体大小
如下代码:
#include <stdio.h>
#include <stddef.h>
struct S1
{
char c1;
char c2;
int a;
};
struct S2
{
int a;
struct S1 s1;
char c3;
};
int main()
{
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
return 0;
}
输出:

分析:首先s1,不做过多分析(上面已经分析过了)大小是8个字节。这里说一下s1中每个成员变量的对齐数,因为下面在分析嵌套结构体时,需要使用到。
s1中的第一个成员变量:字节数为1,VS默认对齐数为8,取较小值为1,所以此变量的对齐数为1。
s1中的第二个成员变量:字节数为1,VS默认对齐数为8,取较小值为1,所以此变量的对齐数为1。
s1中的第三个成员变量:字节数为4,VS默认对齐数为8,取较小值为4,所以此变量的对齐数为4。
因此可以得出s1结构体中最大对齐数为4。(这个数据下面会使用到)。
好,下面分析s2(嵌套结构体)
1、先来s2的起始位置和偏移量:
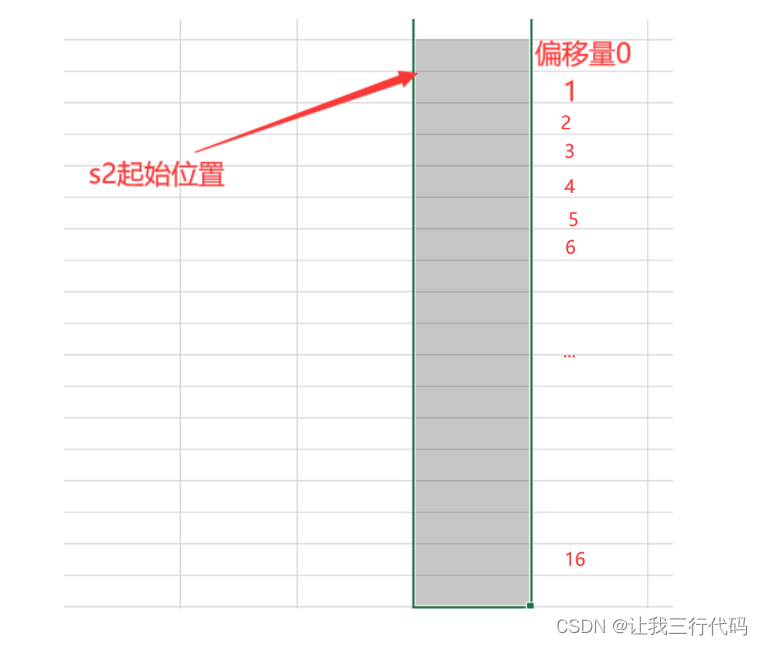
2、看第一个成员变量:int a;,还是按照对齐规则上面的第一句话:第一个成员变量在与结构体变量偏移量为0的地址处。,那a变量肯定就是放在最上面,并且向下占用4个字节。如下图:

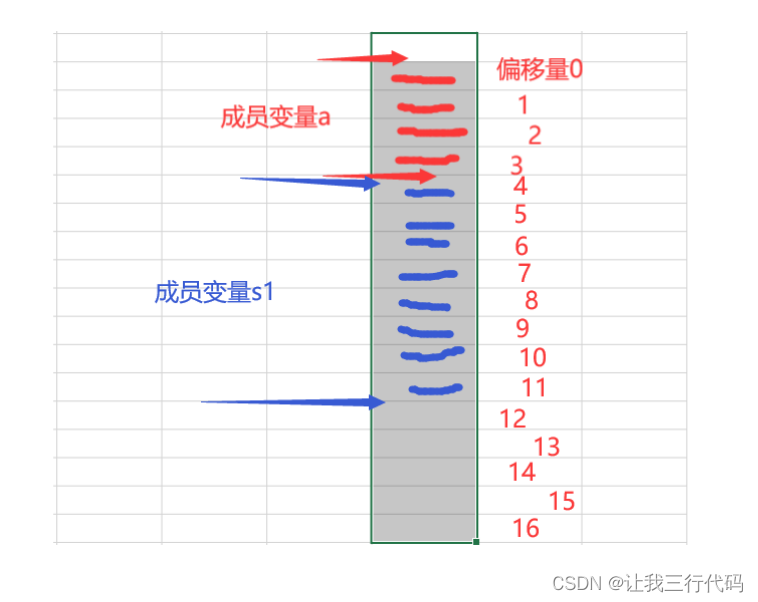
3、看第二个成员变量:struct S1 s1;,重点来了,这个成员变量是结构体,这个所对应的规则是这句话:如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处。,上面分析了,s1大小是8个字节,如何理解这一句话呢?其实这个意思就是说:找到这个嵌套结构体中的最大对齐数,然后可以被偏移量给整除的那个位置,就是这个嵌套结构体开始存储的位置。
s1的最大对齐数是4,因为上面偏移量为4的位置还未被使用,所以现在直接将s1放在偏移量为4的位置上,并向下存储8个字节的位置。
以上就是嵌套结构体的存储方式。
如下图所示:
4、看第三个成员变量:char c3;,首先c3字节大小为1,VS默认对齐数为8,1和8取较小值,较小值为1,所以c3的对齐数就是1。那所以然c3在第二个成员变量下面直接存储即可。如下图:
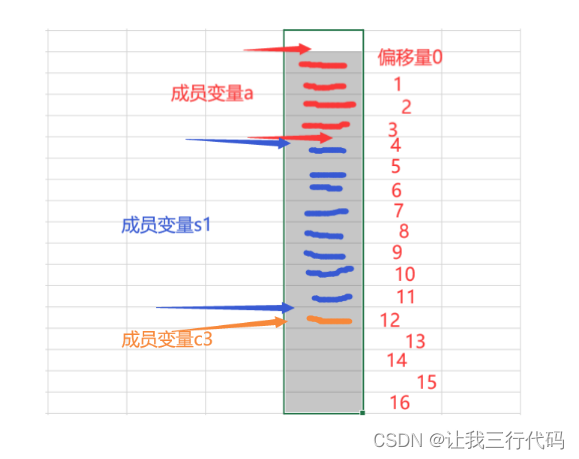
5、计算结构体总大小:这个对应的是这句话:结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
此时我们需要将s2中的三个成员变量的对齐数,拿出来进行比较:
- 变量1的对齐数是:4
- 变量2的对齐数是:4(这个说明一下,结构体的对齐数,就是其结构体内部的每个变量的对齐数相比较出来的最大值。)
- 变量3的对齐数是:1
那所以s2的最大对齐数就是:4。
然后现在s2中的三个成员变量已经占用了13个字节。因为13不能整数4,所以需要向下找能整除4的数。
那就是16了,所以s2的大小就是16字节。
4.5、为什么存在内存对齐?
1、平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2、性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
总体来说:结构体内存对齐是拿空间来换取时间的做法。
4.6、合理设计结构体
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到:
当占用空间的成员尽量集中在一起。
比如:
struct S1
{
char c1;
int i;
char c2;
};
//我们可以将上面两个char类型的变量放在一起
struct S1
{
char c1;
char c2;
int i;
};
4.7、修改编译器默认对齐数
之前我们见过了#pragma这个预处理指令,这里我们再次使用,可以改变我们的默认对齐数。
#include <stdio.h>
#pragma pack(8) //设置默认对齐数为8
struct S1
{
char c1;
char c2;
int i;
};
#pragma pack() //取消设置的默认对齐数,还原为默认
#pragma pack(1) //设置默认对齐数为1,换句话说就是实现内存不对齐 这边修改,等程序运行完,在恢复默认值
struct S1
{
char c1;
char c2;
int i;
};
#pragma pack() //取消设置的默认对齐数,还原为默认
百度笔试题
写一个宏,计算结构体中某变量相对于首地址的偏移,并给出说明。
考察:offsetof宏的实现
我蛮先来看一下offsetof的使用
offsetof (type,member)
- type:传参数据类型
- member:类型成员
#include <stdio.h>
#include <stddef.h>
struct S
{
char c1;
int i;
char c2;
};
int main()
{
struct S s = { 0 };
printf("%d\n", offsetof(struct S, c1));
printf("%d\n", offsetof(struct S, i));
printf("%d\n", offsetof(struct S, c2));
return 0;
}
输出:

那如何模拟实现一个offsetof宏呢?如下思路:
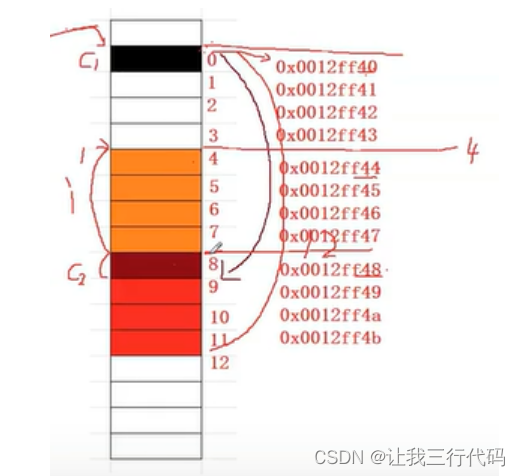
我们将每一个成员的存储首位置减去结构体的起始位置就可以得到偏移量。
那可不可以这样:我们把结构体的起始位置变为0,那么每个成员的首地址,其实就是偏移量了。
下面代码实现:
#include <stdio.h>
#include <stddef.h>
//type*就是struct S*
//(struct S*)0是吧结构体起始位置强制转为从0开始
//(struct S*)0)->m_name 指向每一个成员变量
//(size_t)将每一成员变量的地址强制类型转为int类型的,从而求出偏移量。
#define OFFSETOF(type,m_name) (size_t)&(((type*)0)->m_name)
struct S
{
char c1;
int i;
char c2;
};
int main()
{
struct S s = { 0 };
printf("%d\n", OFFSETOF(struct S, c1));
printf("%d\n", OFFSETOF(struct S, i));
printf("%d\n", OFFSETOF(struct S, c2));
return 0;
}
输出:

5、结构体传参
5.1、传值调用(传结构体对象)
#include <stdio.h>
struct S
{
int data[1000];
int num;
};
void print1(struct S ss)
{
int i = 0;
for (i = 0; i < 3; i++)
{
printf("%d ", ss.data[i]);
}
printf("%d\n", ss.num);
}
int main()
{
struct S s = { {1,2,3},100 };
//传的参数是结构体对象
print1(s);
return 0;
}
输出:

5.2、传址调用(传结构体指针)
#include <stdio.h>
struct S
{
int data[1000];
int num;
};
void print2(struct S* ps)
{
int i = 0;
for (i = 0; i < 3; i++)
{
printf("%d ", ps->data[i]);
}
printf("%d\n", ps->num);
}
int main()
{
struct S s = { {1,2,3},100 };
//传的参数是结构体指针
print2(&s);
return 0;
}
输出:

5.3、如何选择?
优先选择:传址调用。
函数传参的时候,形参是实参的一份临时拷贝。参数是需要压栈,会有时间和空间上的系统开销。
如果传递一个结构体对象的时候,结构体过大,参数压栈的系统开销比较大,所以会导致性能下降。
结论:结构体传参的时候,要传结构体的地址。
6、位段(位段的填充&可移植性)
结构体学完,就得学学结构体实现位段的能力。
位段是由结构体来实现的。所以位段只能在结构体里面使用。
位段:这个
位是比特位。
6.1、什么是位段
位段的声明和结构是类似的,但有两个不同:
1、位段的成员必须是
char,int,unsigned int或signed int。2、位段的成员名后边有一个冒号和一个数字。
比如:
struct A
{
//冒号:后面的数字,代表比特位。
//这个就是只给_a变量2个比特位
int _a:2;
//这个就是只给_b变量3个比特位
int _b:3;
//这个就是只给_c变量4个比特位
int _c:4;
};
//也许我们会有疑惑,_a是int类型的数据,int类型的数据需要32bit啊,为什么这里只给了2个比特位?其实在当_a变量存储的值非常小的时候,比如存储1/0,那就只需要1个bit,就够了。所以说位段在一定的情况下可以节省空间。
A就是一个位段类型。
那位段A的大小是多少呢?
6.2、位段的内存分配
如何计算一个位段大小呢?
下面我们先来看如下代码:
#include <stdio.h>
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main()
{
printf("%d\n", sizeof(struct A));
return 0;
}
输出:

请问这输出的8(字节)是怎么来的呢?
我们先来看下位段的内存分配:
1、位段的成员可以是char,int,unsigned int或signed int(整形家族)类型。
2、位段的空间上是按照需要以4个字节(int)或者一个字节(char)的方式开辟的。
3、位段设计很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
简单说明下:就是位段在开辟空间的时候,一次开辟4个字节的空间,或者一次开辟1个字节的空间,
如果这4个或者1个字节的空间不够分配了,那就在开辟一个4个字节的空间,如果还不够,那在开辟…
分析上面的代码:
首先A位段全部是int类型的,所以先开辟4个字节(32bit)的空间供其使用。
_a变量需要占用2个bit
_b变量需要占用5个bit
_c变量需要占用10个bit
这一共加起来占用了17bit,那一共32bit,所以还剩15个bit。然后在看_d变量,需要30个bit,那剩余的15bit不够分配了,所以又开辟了4个字节(32bit)的空间,供其使用。
但是具体的_d变量,到底是把那剩余的15个bit用了之后然后在从新分配的32个bit里面抽出15个bit使用。还是直接使用此新分配的32个bit呢?
这个是未知的。所以位段也有好多未知因素。
2、在来个例题:
strcut S
{
unsigned char a:4;
unsigned char b:2;
unsigned char c;
unsigned char d:1;
}
int main()
{
printf("%d\n",sizeof(struct S));
return 0;
}
答案:3。
以上结构体大小是3字节。
分析:首先都是char类型的,所以一次只开辟1字节的大小进行分配。首先1byte=8bit,所以满足变量a和b的使用,此时还剩2个bit。但是变量c不再是位段了,所以需要之间分配1字节的大小供其使用。注意:前面还剩的2个bit不在使用了,已经浪费了。然后还剩d变量,现在需要在开辟1字节供其使用。所以一共用了3个字节。
6.3、位段的跨平台问题
6.4、位段的应用
枚举
枚举顾名思义就是------列举
把可能的取值一一列举
比如我们现实生活中:
一周的星期一到星期日是有限的7天,可以一一列举。
性别有:男,女,保密,也可以一一列举。
月份有12个月,也可以一一列举。
这里就可以使用枚举了。
1、枚举类型的定义
enmu是枚举的关键字
enum Day
{
Mon, //枚举常量
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
int main()
{
//给d赋值的值来自上面枚举的常量。
//d变量是enum Day类型的变量
enum Day d = Fri;
return 0;
}
1、每一个枚举常量默认是有值的:而且默认值是从0开始,依次向下加1。
#include <stdio.h>
//把一周中可能的每一天列举出来
enum Day
{
Mon,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
int main()
{
printf("%d\n", Mon);
printf("%d\n", Tues);
printf("%d\n", Wed);
printf("%d\n", Thur);
printf("%d\n", Fri);
return 0;
}
输出:

2、当然我们也可以让默认值从1开始,如下:
#include <stdio.h>
//把一周中可能的每一天列举出来
enum Day
{
Mon=1, //给第一个值赋值为1,就从1开始了。
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
int main()
{
printf("%d\n", Mon);
printf("%d\n", Tues);
printf("%d\n", Wed);
printf("%d\n", Thur);
printf("%d\n", Fri);
return 0;
}
输出:

2、枚举的优点
为什么使用枚举?
我们可以使用#define定义常量,为什么非要使用枚举呢?
枚举的有点:
1、增加代码的可读性和可维护性。
2、和#define定义的标识符比较,枚举有类型检查,更加严谨。
3、防止了命名污染(封装)。
4、便于调式
5、使用方便,一次可以定义多个常量。
3、枚举的使用
enum Color
{
RED=1,
GREEN=2,
BLUE=4
}
enum Color clr = GREEN; //那枚举常量给枚举变量赋值,才不会出现差异。
clr = 5; //这样ok吗? 答案:不ok。因为5是int类型的数据,clr是枚举类型的变量,int类型的数据不可以给枚举类型的变量赋值的。
联合(共用体)
1、联合类型的定义
union是联合类型的关键字
联合也是一种特殊的自定义类型。
这种类型定义的变量也包含一系列的成员,特征是这些成员公用同一块空间(所以联合也叫共用体)。
比如:
//联合类型的声明
union Un
{
char c;
int i;
};
抛出问题,计算如下代码中共用体的大小:
#include <stdio.h>
union Un
{
int a;
char c;
};
int main()
{
union Un u;
printf("%d", sizeof(u));
return 0;
}
输出:

其实这体现出了地址公用的的特性,下面我们来打印以下,变量u,以及u.a和u.c的地址。
#include <stdio.h>
union Un
{
int a;
char c;
};
int main()
{
union Un u;
printf("%p\n", &u);
printf("%p\n", &(u.a));
printf("%p\n", &(u.c));
return 0;
}
输出:

可以发现,它们三个的地址竟然一样!!!。
上面联合体u中有变量a和c,因为它们两是公用一块地址,所以程序不会同时使用这个变量,在使用变量a的时候,不使用变量c,在使用变量c的时候不使用变量a。
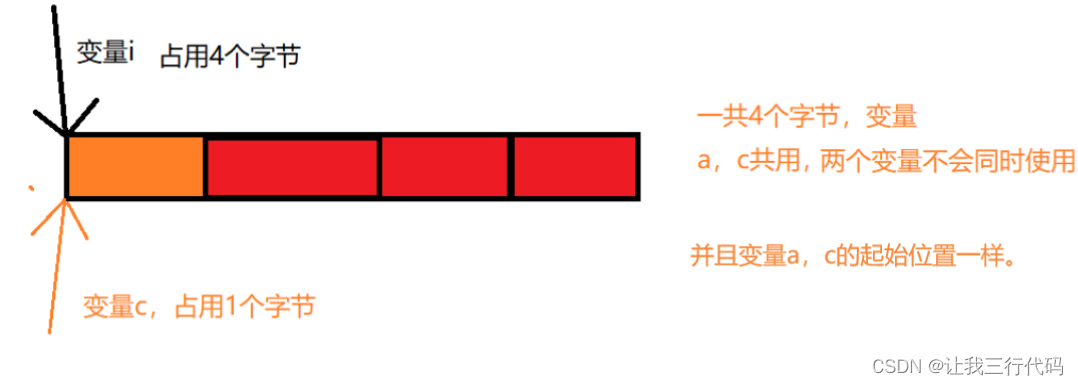
总结:放在联合体里面的成员变量不是每个成员都有自己单独独立的空间,而是共用同一块空间。
类似于生活中的合租现象。
2、联合的特点
联合体的成员是共用同一块内存空间的,这样一个联合体变量的大小,至少是最大成员的大小,(因为联合至少的有能力保存最大的那个成员)。
2.1、判断大小端存储
以前我们写过一个代码:
//封装为函数的写法
#include <stdio.h>
int check_sys()
{
int a = 1;
return *(char*)&a;
}
int main()
{
int a = 1;
int ret = check_sys();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
现在我们用联合体来实现以下(好好体会联合体的巧妙性)
#include <stdio.h>
int check_sys()
{
union Un
{
int i;
char c;
}u;
u.i = 1;
//返回为1是小端,返回为0是大端
return u.c;
}
int main()
{
int a = 1;
int ret = check_sys();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
3、联合大小的计算
- 联合的大小至少是最大成员的大小。
- 当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍。
计算如下联合体的大小:
#include <stdio.h>
union Un
{
char arr[5];
int i;
};
int main()
{
printf("%d\n", sizeof(union Un));
return 0;
}
输出:

联合也涉及到内存对齐。注意计算联合题的大小方法,和计算结构体大小的方法稍微有所不同。
分析:
1、首先char arr[5]; ,我们想要得到数组的对齐数时,可以直接把这个数组拆分为是5个char类型的数据,__但是这里并不能说char arr[5]和5和char类型是等价的。__因为每个char的对齐数是1,所以这个数组的对齐数就是1。并且这个数组占用5个字节。在强调一遍,这里的arr数组占用5个字节,这个下面会使用到这个信息。
2、int i,字节为4,VS默认对齐数为8,4和8取较小值,所以得出i变量的对齐数为4。
3、ok,现在arr是5个字节,i是4个字节,因为联合体是公用地址的特性,所以现在找出来一个最大字节的,就可以存储联合体的成员变量了。因为5>4,所以联合体的存储大小就是5个字节。但是还没完,因为联合体也需要内存对齐,所以还会有为了内存对齐而浪费的内存。但是这里为什么要强调联合体的大小就是5个字节呢?因为下面内存对齐的部分需要从5个字节下面开始分配。
4、求两耳提最大对齐数:4>1,所以最大对齐数就是:4。
5、然后现在需要找到字节数为对打对齐数4的倍数,又因为上面5个char占用了5个字节(也就是上面所说的从第5个字节处开始进行分配),所以只有下面的8字节的符合4的倍数。所以联合体大小为8字节。
但是又因为联合体中的成员变量是共用一块地址,所以如下图是内存占用情况:

2、下面在来个示例:计算来联合体大小
#include <stdio.h
union Un
{
short s[7];
int n;
}
int main()
{
printf("%d\n",sizeof(union Un));
}
答案:16。
分析:
1、数组s占用14个字节,变量n占用4个字节,所以联合体公用的是14字节的大小。
2、short类型的对齐数为2,int类型的对齐数为4,所以联合体的最大对齐数就是4。
3、内存对齐:因为上面已经占用了14字节的,14不是4的倍数,所以只能向下找到是4字节的倍数。所以只能是16字节。
所以最终答案就是16。
通讯录(静态版本)
实现一个通讯录:
人的信息:
- 名字
- 年龄
- 性别
- 电话
- 地址
1、存放100个人的信息
2、增加联系人
3、删除指定联系人
4、查找联系人
5、修改联系人
6、排序
7、显示联系人
文件说明:
- test.c-----------------测试功能
- contact.c---------------通讯录的实现
- contatc.h---------------通讯录的声明
test.c
#include "contact.h"
void menu()
{
printf("**************************************\n");
printf("******** 1.add 2.del *******\n");
printf("******** 3.search 4.modify *******\n");
printf("******** 5.show 6.sort *******\n");
printf("************ 0.exit *******\n");
}
int main()
{
int input = 0;
Contact con;
//初始化通讯录
InitContact(&con);
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
AddContact(&con);
break;
case 2:
DelContact(&con);
break;
case 3:
SearchContact(&con);
break;
case 4:
ModifyContact(&con);
break;
case 5:
ShowContact(&con);
break;
case 6:
SortContact(&con);
break;
case 0:
printf("退出\n");
break;
default:
printf("选择错误\n");
break;
}
} while (input);
return 0;
}
contact.c
#include "contact.h"
void InitContact(Contact* pc)
{
assert(pc);
//对count成员变量初始化
pc->count = 0;
//对PeoInfo初始化,这是个方法,使用memset来初始化,如果不使用memset,那需要循环来初始化。
memset(pc->data, 0, sizeof(pc->data));
}
void AddContact(Contact* pc)
{
assert(pc);
if (pc->count == MAX)
{
printf("通讯录已满,无法添加\n");
return;
}
printf("请输入名字:>");
scanf("%s", pc->data[pc->count].name); //因为name本身就是字符数组的数组名,是首元素地址,所以这里不需要在取地址。
printf("请输入年龄:>");
scanf("%d", &(pc->data[pc->count].age)); //因为age是个变量,所以使用scanf时,在调用age还需要在取地址。
printf("请输入性别:>");
scanf("%s", pc->data[pc->count].sex);
printf("请输入电话:>");
scanf("%s", pc->data[pc->count].tele);
printf("请输入地址:>");
scanf("%s", pc->data[pc->count].addr);
pc->count++;
printf("添加成功\n");
}
void ShowContact(const Contact* pc)
{
assert(pc);
int i = 0;
printf("%20s\t%5s\t%5s\t%12s\t%30s\n", "名字", "年龄", "性别", "电话", "地址");
for (i = 0; i < pc->count; i++)
{
printf("%20s\t%3d\t%5s\t%12s\t%30s\n",
pc->data[i].name,
pc->data[i].age,
pc->data[i].sex,
pc->data[i].tele,
pc->data[i].addr);
}
}
//表示此函数只能在本.c文件中调用
static int FindByName(Contact* pc, char name[])
{
assert(pc);
int i = 0;
for (i = 0; i < pc->count; i++)
{
if (strcmp(pc->data[i].name,name) == 0)
{
return i;
}
}
return -1;
}
void DelContact(Contact* pc)
{
assert(pc);
char name[MAX_NAME];
if (pc->count == 0)
{
printf("通讯录为空,没有信息可以删除\n");
return;
}
printf("请输入要删除人的名字:>");
scanf("%s", name);
//删除
//1.查找,找到了返回下标,没有找到返回-1。
int pos = FindByName(pc, name);
if (pos == -1)
{
printf("要删除的人不存在\n");
return;
}
//2、删除,思路是:把后面的信息往前面覆盖即可。
int i = 0;
for (i = pos; i < pc->count-1; i++)
{
pc->data[i] = pc->data[i + 1];
}
pc->count--;
printf("删除成功\n");
}
void SearchContact(Contact* pc)
{
assert(pc);
char name[MAX_NAME];
printf("请输入要查找人的名字:>");
scanf("%s", name);
//1、查找
int pos = FindByName(pc, name);
if (pos == -1)
{
printf("要查找的人不存在\n");
return;
}
//2、打印
printf("%20s\t%5s\t%5s\t%12s\t%30s\n", "名字", "年龄", "性别", "电话", "地址");
printf("%20s\t%3d\t%5s\t%12s\t%30s\n",
pc->data[pos].name,
pc->data[pos].age,
pc->data[pos].sex,
pc->data[pos].tele,
pc->data[pos].addr);
}
void ModifyContact(Contact* pc)
{
assert(pc);
char name[MAX_NAME];
printf("请输入要修改人的名字:>");
scanf("%s", name);
//1、查找
int pos = FindByName(pc, name);
if (pos == -1)
{
printf("要修改的人不存在\n");
return;
}
printf("请输入名字:>");
scanf("%s", pc->data[pos].name); //因为name本身就是字符数组的数组名,是首元素地址,所以这里不需要在取地址。
printf("请输入年龄:>");
scanf("%s", &(pc->data[pos].age)); //因为age是个变量,所以使用scanf时,在调用age还需要在取地址。
printf("请输入性别:>");
scanf("%s", pc->data[pos].sex);
printf("请输入电话:>");
scanf("%s", pc->data[pos].tele);
printf("请输入地址:>");
scanf("%s", pc->data[pos].addr);
printf("修改成功\n");
}
//比较函数
int cmp_peo_by_name(const void* e1, const void* e2)
{
return strcmp(((PeoInfo*)e1)->name, ((PeoInfo*)e2)->name);
}
void SortContact(Contact* pc)
{
assert(pc);
qsort(pc->data, pc->count, sizeof(pc->data[0]), cmp_peo_by_name);
printf("排序成功\n");
}
contact.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <stdlib.h>
#define MAX 100
#define MAX_NAME 20
#define MAX_SEX 10
#define MAX_TELE 12
#define MAX_ADDR 30
//类型声明
//类型重命名:将struct PeoInfo重名为:PeoInfo
typedef struct PeoInfo
{
char name[MAX_NAME];
int age;
char sex[MAX_SEX];
char tele[MAX_TELE];
char addr[MAX_ADDR];
} PeoInfo;
typedef struct Contact
{
//存放人的信息
PeoInfo data[MAX];
//记录当前通讯录中实际个数。
int count;
} Contact;
//初始化通讯录
void InitContact(Contact* pc);
//添加信息
void AddContact(Contact* pc);
//显示信息
void ShowContact(const Contact* pc);
//删除信息
void DelContact(Contact* pc);
//查找信息
void SearchContact(Contact* pc);
//修改信息
void ModifyContact(Contact* pc);
//排序信息
void SortContact(Contact* pc);
通讯录(动态版本)
初始化3个通讯录,如果不够一次扩容2个。
typedef struct Contact
{
//存放人的信息
PeoInfo* data;
//记录当前通讯录中实际个数。
int count;
//当前通讯录的容量
int cap;
} Contact;
data指向一块空间,先可以存放3个人的信息,如果不够,对data在扩容2个,在不够,在扩容(realloc)…
int InitContact(Contact* pc)
{
assert(pc);
//对count成员变量初始化
pc->count = 0;
//对PeoInfo初始化,这是个方法,使用memset来初始化,如果不使用memset,那需要循环来初始化。
pc-<data = (ProInfo*)calloc(3,sizeof(PeoInfo));
if (pc->data == NULL)
{
printf("%s\n",strerror(errno));
return 1;
}
pc->cap = 3;
return 0;
}
//增容
void CheckCap(Contact* pc)
{
assert(pc);
if (pc->count == pc->cap)
{
PeoInfo* ptr = (PeoInfo*)realloc(pc-data,(pc-cap+2)*szieof(PeoInfo));
if (ptr == NULL)
{
printf("%s\n",strerror(errno));
}
else
{
pc->data = ptr;
pc->cap+=2;
printf("增容成功");
}
}
printf("请输入名字:>");
scanf("%s", pc->data[pc->count].name); //因为name本身就是字符数组的数组名,是首元素地址,所以这里不需要在取地址。
printf("请输入年龄:>");
scanf("%d", &(pc->data[pc->count].age)); //因为age是个变量,所以使用scanf时,在调用age还需要在取地址。
printf("请输入性别:>");
scanf("%s", pc->data[pc->count].sex);
printf("请输入电话:>");
scanf("%s", pc->data[pc->count].tele);
printf("请输入地址:>");
scanf("%s", pc->data[pc->count].addr);
pc->count++;
printf("添加成功\n");
}
//销毁通讯录
void DestroyContact(Contact* pc)
{
assert(pc);
free(pc-data);
pc->data = NULL;
}
通讯录(持久化存储版本)
添加两个模块:
- 在通讯录推出之前,需要保存模块:SaveContact。这个本质是进行写数据。
- 在刚进入通迅如之前,需要查看模块: 。这个本质是进行读数据。这个动作可以在初始化通讯录模块中写。
case 0:
//新添加保存模块
SaveContact(&con);
//这个销毁通讯录模块,是在动态版本新添加的
printf("退出\n");
break;
void SaveContact(const Contact* pc)
{
assert(pc);
FILE* pfWrite = fopen("contact.txt","wb");
if (pc == NULL)
{
perror("SaveContact");
return ;
}
//写入数据
int i = 0;
for(i=0;i<pc->count;i++)
{
//一回只写一个结构体的数据
fwirte(pc->data+i,sizeof(PeoInfo),1,pfWrite);
}
//关闭文件流
fclose(pfWrite);
pfWrite = NULL;
}
void LoadContact(Contact* pc)
{
FILE* pfRead = fopen("contact.txt","rb");
if (pfRead == NULL)
{
perror("LoadContact");
return ;
}
PeoInfo tmp;
while(fread(&tmp,sizeof(PeoInfo),1,pfRead) == 1)
{
//增容模块
CheckCap(Contact* pc);
pc->data[pc->count] = tmp;
pc->count++;
}
fclose(pfRead);
pfRead = NULL;
}
int InitContact(Contact* pc)
{
assert(pc);
//对count成员变量初始化
pc->count = 0;
//对PeoInfo初始化,这是个方法,使用memset来初始化,如果不使用memset,那需要循环来初始化。
pc-<data = (ProInfo*)calloc(3,sizeof(PeoInfo));
if (pc->data == NULL)
{
printf("%s\n",strerror(errno));
return 1;
}
pc->cap = 3;
//加载文件的信息到通讯录中
LoadContact(pc);
return 0;
}