可能得错误一:
今天使用docker创建容器的时候总是出错,最后锁定问题在“--gpus all”这里:
不加--gpu all可以运行,加入了--gpus all就出错:
docker: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running hook #0: error running hook: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: mount error: file creation failed: /var/lib/docker/overlay2/dca2e2fe6aa996e1ed327118af5a3881e416728029d306612b32afe861a82b67/merged/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1: file exists: unknown.
ERRO[0000] error waiting for container:
安装网上的做法:
在WSL2子系统上无法用导入的Docker镜像启动容器_Leeoo_lyq的博客-CSDN博客
一直不行,最后才知道源镜像使用的CUDA10,而我的电脑是CUDA11,所以创建GPU容器就一直错误,我服了,所以在一直错误的时候建议先使用下面的方法将依赖打印出来,看看使用的是CUDA版本:将当前conda环境导出为yaml文件_HealthScience的博客-CSDN博客
需要注意的是如果使用纯docker启动该镜像的容器则不报错,命令:
sudo docker run -it -v /home/devil/shareData:/shareData -p 127.0.0.1:3333:22 30acf12ceadb /bin/bash
也就是说只有使用nvidia-docker启动该镜像下的容器才会报错【--gpus all】。
重点:
如果同一个镜像的容器在非WSL下,即纯物理机Ubuntu环境下使用nvidia-docker启动是不会报错的【--gpus all】。
也就是说该种错误只有在WSL下使用nvidia-docker启动某个镜像下的容器才会如此报错。
故障原因:
nvidia-docker最古老的容器内nvidia gpu的调用是需要在镜像(或容器)中安装与宿主机nvidia显卡驱动兼容的驱动版本,但是这一要求比较难以满足,因为如果宿主机的nvidia驱动略低于docker容器下nvidia驱动版本就很容易出现forward compatibility错误,而比较可行的就是容器内的nvidia驱动版本略低于宿主机版本。正是因为最早的nvidia-docker这个难以保证宿主机和容器的nvidia驱动版本匹配,因此现在的nvidia-docker使用的方案是在制作docker镜像时不安装nvidia driver和cuda,而是在nvidia-docker容器启动时自动把宿主机中的nvidia driver和cuda映射给容器,对应的nvidia-docker启动容器时附加参数为 --gpus all,但是有一些人对这个原理并不是很了解因此在制作镜像的时候依旧会把nvidia driver和cuda打包进去【应该是在做镜像的时候不应该把--gpus all参数加进去】。由于wsl下对物理机的nvidia显卡是使用模拟的方式,这时的wsl中使用的nvidia驱动其实是wsl-nvidia-driver,也正是由于该驱动的一些特性导致在wsl中如果使用nvidia-docker启动自身带有nvidia driver和cuda的容器就会在启动时报错。其报错的故障具体点为wsl使用nvidia-docker启动容器时在自动创建/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1文件和/usr/lib/x86_64-linux-gnu/libcuda.so.1文件时会判断镜像中是否有相同的文件,如果有则报错,也就是本文开头说提的报错信息,而在ubuntu物理机上使用nvidia-docker首次启动容器时即使镜像中存在/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1文件和/usr/lib/x86_64-linux-gnu/libcuda.so.1文件也会对其进行强制覆盖(强制映射)(该种覆盖并不会影响容器的保存,比如在使用docker commit时对应的文件依旧是原镜像中的文件,而不是nvidia-docker映射给的宿主机中对应的文件)。
解决方案:
1. 使用docker而不是nvidia-docker启动原始镜像下的容器,
sudo docker run --rm -it 14.14.15.100:5000/pytorch/pytorch:20.08-py3-cuda11
2、在该容器下,手动删除或改名文件/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1和文件/usr/lib/x86_64-linux-gnu/libcuda.so.1 ,
mv /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1 /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1.bak
mv /usr/lib/x86_64-linux-gnu/libcuda.so.1 /usr/lib/x86_64-linux-gnu/libcuda.so.1.bak
或者运行下面的三行命令也行
rm /usr/lib/x86_64-linux-gnu/libnvidia-*
rm /usr/lib/x86_64-linux-gnu/libcuda.so*
rm /usr/lib/x86_64-linux-gnu/libnvcuvid.so.*
3、然后在另开一个终端执行,把此时的容器打包为镜像,具体操作:
使用下面的命令得到ID:
docker ps -a

打包该容器为新的镜像:
sudo docker commit 72f081acebae new:v1
4. 使用nvidia-docker启动上一步打包的镜像,变为新的带有GPU的容器:
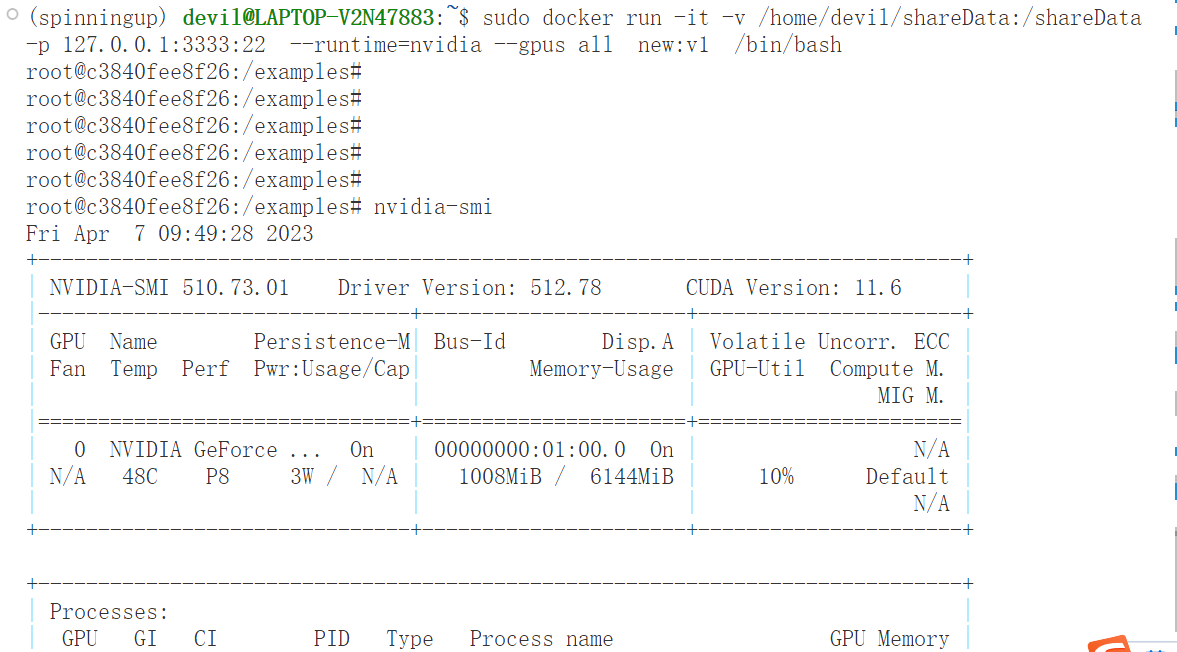
sudo docker run -it -v /home/devil/shareData:/shareData -p 127.0.0.1:3333:22 --gpus all new:v1 /bin/bash
5、使用nvidia-smi看看是否成功
成功运行,故障解决,运行效果如下:
如有问题可参考下面的博客
在WSL2子系统上无法用导入的Docker镜像启动容器_Leeoo_lyq的博客-CSDN博客
https://www.cnblogs.com/devilmaycry812839668/p/17296525.html