目录
缓存
缓存更新策略
定期生成
实时生成
缓存问题
缓存预热(Cache preheating)
缓存穿透(Cache penetration)
缓存雪崩(Cache avalanche)
缓存击穿(Cache breakdown)
分布式锁
分布式锁基础实现
引入过期时间
引入校验id
引入lua脚本
引入watch dog(看门狗)
引入Redlock算法
缓存
缓存的核心思路就是把常用的数据放入访问速度更快的地方,方便随时读取。使用Redis作为缓存,数据是直接存储在内存上的,对于关系型数据库例如MySql来说速度更快。
为什么说关系型数据库性能不高?
1.数据库将数据存储在硬盘上,硬盘的IO速度没有内存快。
2.如果查询不能命中索引,就需要进行表的遍历,这就会大大增加硬盘IO次数。
3.关系型数据库会对SQL的执行做一系列的解析,校验,优化工作。
4.复杂查询更加消耗效率。(笛卡尔积)
如果全部请求直接访问数据库,对于数据库压力很大,很容易使数据库服务器宕机。使用Redis缓存可以加快读操作,写操作还是得写在数据库中。
缓存更新策略
定期生成
每隔一定时间,对访问数据频次较高的数据进行统计,挑选出访问频次最高的前N%的数据,导入到Redis中。实时性比较低,面对突发情况不友好。如春节期间,“春节”的搜索频率变高,在平时搜索频率比较低。
实时生成
用户查询数据,如果没有在Redis中命中,就在数据库中查询,然后将结果更新到Redis中。如果Redis缓存满了,就可以使用内存淘汰策略进行删除:
FIFO(First In First Out)先进先出
将缓存中存在时间最久的数据淘汰。
LRU(Least Recently Used)淘汰最久未使用的
记录每个key的最近访问时间,把最近访问时间最老的key淘汰。
LFU(淘汰访问次数最少的)
记录每个key最近一段时间的访问次数,淘汰访问次数最少得到。
Random随机淘汰
随机淘汰缓存中的key。
缓存问题
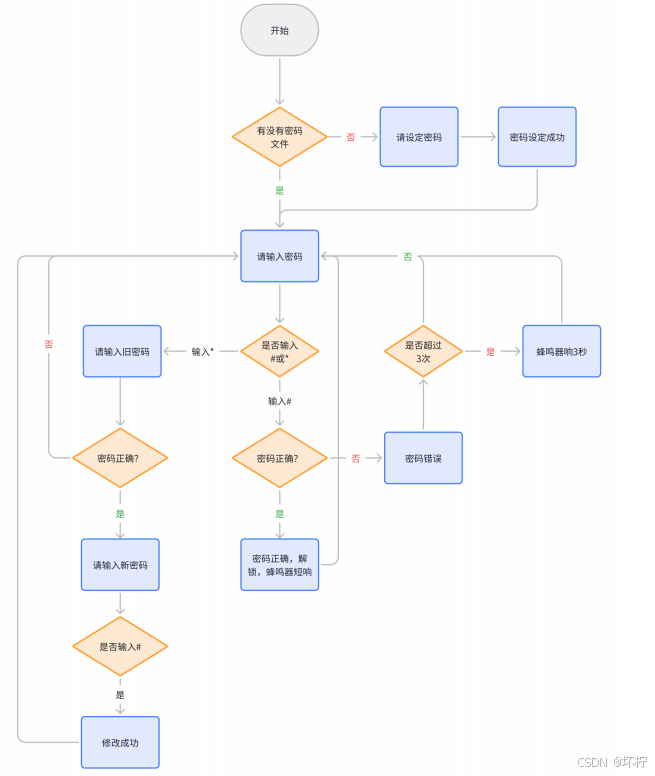
缓存预热(Cache preheating)
刚刚启动Redis作为MySQL缓存时,Redis自身为空,所有请求都会直接直接访问数据库,从而对数据库造成很大的压力。
提前准备热点数据导入Redis中,使Redis更快提供服务,解决缓存预热问题。
缓存穿透(Cache penetration)
访问的key在Redis和MySQL中都不存在,此时key不会放入缓存中,后续如果接着访问这个key,依然会访问到数据库。这样会给数据库造成压力。
针对查询的key进行校验,如要查询的key为手机号,首先对key的格式进行校验。
针对数据库不存在的key也放入redis中。
使用布隆过滤器,判定key是否存在。
缓存雪崩(Cache avalanche)
短时间内,大量的key失效(Redis挂了/大量key同时过期),导致数据库压力增大。
部署高可用的Redis系统,完善监控报警体系。
不给key设置过期时间,或者设置过期时间时加入随机因子。
缓存击穿(Cache breakdown)
热点key突然过期,大量请求直接访问MySQL数据库。
将这些热点key设置为永不过期。
分布式锁
分布式系统中,当不同节点访问统一资源时,就需要通过锁进行互斥控制,避免出现类似“线程 安全”问题。在分布式这种多进程,多主机的的场景中,就需要有一台服务器进行记录加锁操作。
分布式锁基础实现
使用Redis实现分布式锁,本质上就是通过设置一个键值对,然后通过键值对来判定是否已有其他进程加锁。
例如在网上买票的时候,车站提供了多个服务器处理买票的请求,客户端每次买票需要查询车票数量,判断车票数量是否大于1,满足条件车票数量减一。在高并发情况下,可能会导致超卖情况,此时引入分布式锁。
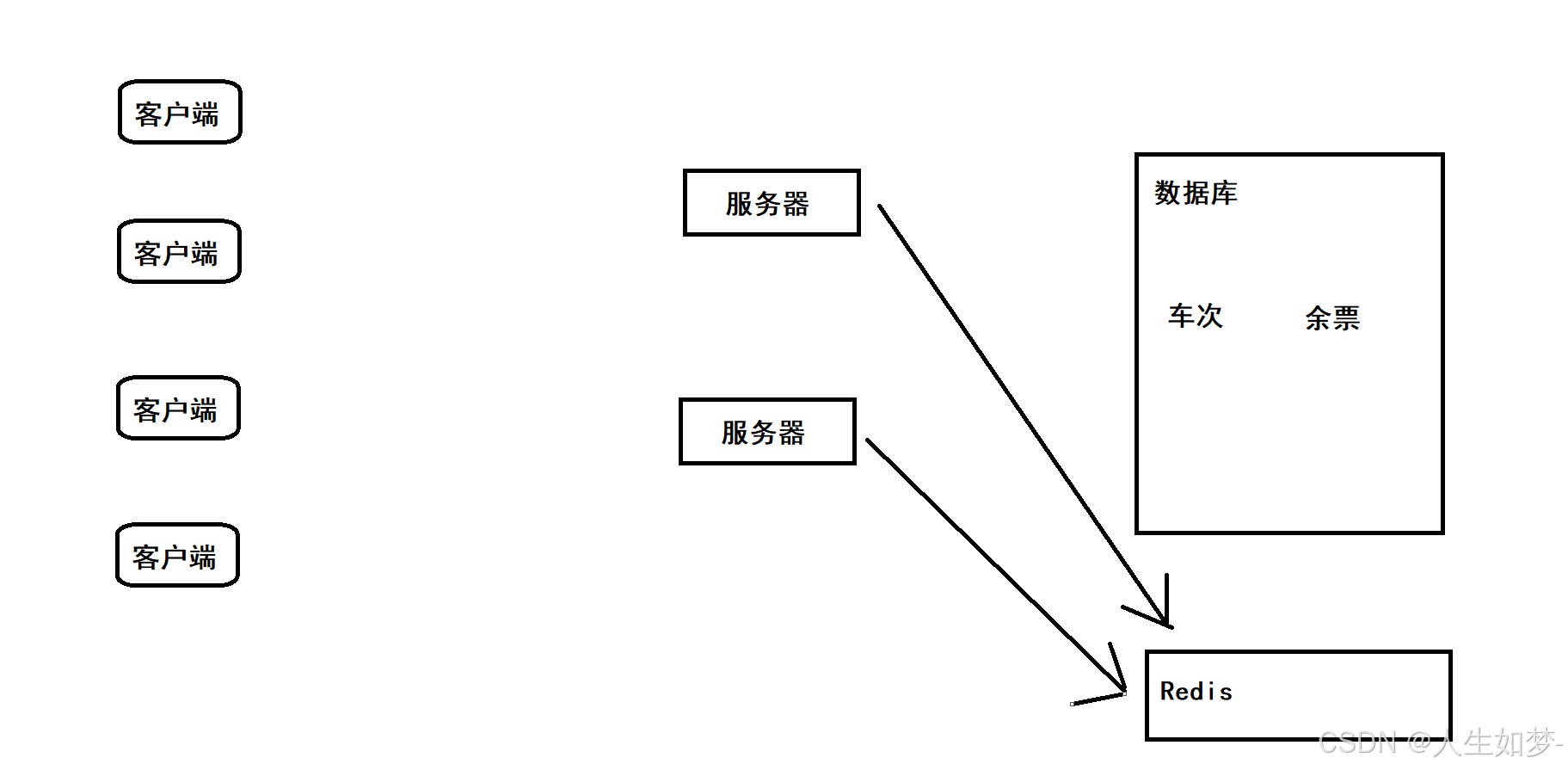
此时服务器对数据库进行操作时,就会先判断Redis中是否有加锁的键值对,Redis中的key就可以代表车次,表示该车次的票正在其他进程中进行操作。Redis中提供了setnx操作,当key设置成功,则代表加锁成功,反之就代表已经有其他进程进行加锁了。设置成功后,就可以对数据库进行读写操作了,操作完成之后再把Redis上刚刚的key进行删除。
但是这个方案并不完整,当加锁的进程在执行删除key操作之前遇到问题(如宕机),此时删除操作不能进行,其他进程也不能获取锁。
引入过期时间
为解决加锁后加锁进程意外宕机的情况,在设置key时顺便设置过期时间,表示进程持有锁的最大时间,达到时间后就会自动删除key,使用set ex nx命令进行设置,不能分开设置,由于Redis事务不能保证两个操作都能成功执行,可能就会出现set nx操作成功,但是expire失败的情况。此时任然会出现无法正确释放锁的问题。
但是仍然存在问题,其他进程也可以操作Redis删除key,此时加锁就失去了意义。
引入校验id
为解决其他进程删除key,引入校验机制,在设置键值对时,value设置为可以识别加锁服务器的身份。在执行解锁操作时,先根据value判断是否为加锁的服务器。该逻辑用伪代码表示:
String key = "要加锁的资源id"; String serverId = "服务器的编号"; //加锁,设置过期时间为10s redis.set(key,serverId,"NX","EX","10s"); //执行各种逻辑,如数据库的增删查改 select(); update(); delete(); insert(); //解锁,先判断是否为加锁进程 if(redis.get(key) == serverId) { redis.del(key); }
在执行解锁操作时,解锁的逻辑是分为两步的,不是原子操作。一个服务器内部,可能是多线程的,同一个服务器内部,两个线程都在执行解锁操作,就可能导致del操作被重复执行,然后将其他加锁线程的锁给删除了。
引入lua脚本
为了使解锁操作变为原子的,使用Redis支持的lua脚本,将查询和删除操作打包为原子操作,可以将上述代码编写成一个.lua后缀的文件,一个lua脚本会被Redis服务器以原子的方式进行执行。
引入watch dog(看门狗)
设置key过期时间后,任然存在当前任务没有执行完,key就过期了的情况,导致锁提前失效。引入watch dog,本质上是加锁的服务器上一个单独的线程,通过这个线程来对锁的过期时间进行“续约”。这个线程并不是Redis提供,而是业务服务器上的线程。
假设设置一个key,过期时间为10s,设定看门狗线程没3s检测一次。
当3s时间到的时候,看门狗就会判定当前任务是否完成。
如果完成,可通过lua脚本直接释放锁。
未完成,则将过期时间重新设置为10s(续约)。
这样就不用担心锁提前失效的问题。如果该服务器挂了,那么看门狗线程也随之挂了,没人给锁续约,到达过期时间后key就会过期,让其他服务器能够获取锁。
引入Redlock算法
实践中Redis一般是以集群的方式部署的(至少是主从结构),Redis成为分布式锁可能会遇到一些极端情况:负责加锁的master节点刚刚进行加锁操作,然后就挂了,此时slave节点成了新的master节点,由于此时的key并没有同步给slave节点,导致加锁操作形同虚设。
解决办法:引入一组Redis节点,每一组Redis节点都包含master节点和slave节点,组与组之间的数据都是一致的,相互之间为“备份”关系。在进行加锁操作时,设置加锁操作的超时时间,比如设置为30ms,超过30ms没有加锁,则视为加锁失败。如果当前节点加锁失败。就立即尝试下一个节点,当加锁成功的节点超过总结点的一半,则视为加锁成功。即使某些节点挂了也不会影响锁的正确性。
文章结束,感谢观看!







![[ctfshow web入门]burpsuite的下载与使用](https://i-blog.csdnimg.cn/direct/cffb49d3ab3a495e9baaf5853dfb92c5.png)




![P1125 [NOIP 2008 提高组] 笨小猴](https://i-blog.csdnimg.cn/direct/dec3c528bcca405db6008fc45d31bef1.png)

