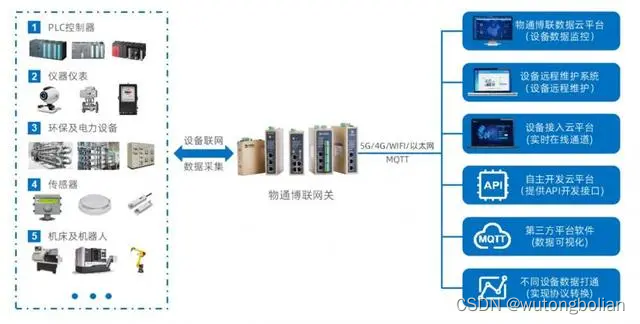
文章目录
- 网络应用基本原理
- 网络应用体系结构~三种结构
- 网络应用进程通信
- 网络应用需求
- WEB应用
- HTTP协议
- Cookie技术
- WEB缓存/代理服务器技术
- Email应用
- SMTP协议
- Email消息格式(SMTP传输消息的格式)
- POP3协议
- IMAP
- DNS应用
- DNS协议
网络应用基本原理
网络应用体系结构~三种结构
C/S结构
C -> Client,即客户机。
- 与服务器通信,访问服务器,请求服务与信息。
- 人是善变的,不定时的去访问服务器。
- 由于网络随处可见,WIFI等子网络分配的网络IP是可变的,因此客户机经常会使用动态的IP地址。
- 在C/S结构中,客户机不会与其他客户机直接通信。
S -> Servlet,即服务器。 - 24 小时提供服务
- 对外提供一个永久性访问的域名地址
- 由于客户的庞大,厂商一般会有大量的服务器,有的可以称为服务器农场。
C/S结构中,最具代表性的就是浏览器与WEB服务器。用户通过浏览器输入域名地址访问服务器,然后希望请求一些信息,然后服务器响应该请求返回对应的信息。
优点:客户可以随时访问服务器,等…
缺点:厂商必须话费大价格去买服务器,否则在客户请求数非常多的时候,仅仅几台服务器会崩溃,等…
P2P结构
- 没有24小时在线的提供请求信息的服务器
- 每一个客户端都可以是服务器,也可以是客户机
- 在P2P结构中每一个端系统都可以直接通讯,即可以相互提供服务相互请求之间服务。
- 同样P2P结构中,结点依旧算是客户机(人),仍旧是善变的,没有固定时间接入网络。
- IP地址同样是动态的。
优点:高度可伸缩,你只与另外一个使用端系统的人说好传输什么文件信息即可十分方便,等…
缺点:比如我下载一个视频的时候突然作为提供视频的端系统服务器下线了不玩了,我下载到一半就不能继续下载了这非常苦恼,对于作为客户机一端是十分自私的,等…
Napster(混合结构)
- 在文件传输方面使用P2P结构
- 在文件搜索方面使用C/S结构
将C/S结构域P2P结构二者的优点结合起来。在厂商的服务器中不用存储大量信息,只需要记录端系统想自己报告的所能共享的信息即可,在端系统作为服务器的时候可以为很多人提供自己所能提供的信息,谁需要就向我请求即可,然后就开始使用P2P结构双方开始传输文件,等…
网络应用进程通信
- 进程:主机运行的程序叫做进程
- 一个主机上多个进程如何通信?
进程之间有通信机制,并且由操作系统提供,实现起来比较简单。 - 不同主机之间的进程如何通信?
通过消息交换,实现起来比较难,计网基本就是解决如何消息交换的,并且需要实现无误可靠快速等细节。
客户机进程:发起通信的进程
服务器进程:时刻等待客户机发起的通信请求,然后发送响应消息。 - 特殊:P2P之间作为提供服务一方为服务器,请求服务一方为客户机。
- 套接字:Socket
在应用层中,都是使用下层提供的服务以及本层实现的服务,所以在应用层一般对于具体如何传输消息的是看不到的,因此我们直接使用高级语言编程即可,网络编程油然而生,利用一个叫做套接字Socket,使用对应的API进行编程即可实现不同主机进程之间的通信。(发送/接收)
类似于寄快递,发送方将物件按照规范协议打包好交给快递员,由快递员将其物件送到对方门口(接收方主机),然后接收方从快递员手中接收到快递。
而快递员如何实现的我们在应用层是看不见的。心中一直很想知道这快递员到底是如何送快递的,起码我要知道他是怎么找到接收方的吧? - 如何寻址?
主机可以通过IP地址区分。
不同进程之间如何区分,在消息来了时候,应该交给哪一个应用进程,所以为了解决这问题,每一个进程必须拥有一个标识符。所以需要额外加一个端口号来区分。但是有一些特殊端口号不可用,比如80端口,是HTTP服务器使用的,25是Mail服务器使用的。
寻址唯一标识:IP地址+端口号。 - 应用层需要遵循很多协议,使用什么功能一般都有对应的协议,可以是公开的:HTTP,SMTP…,可以是私有的:比如P2P文件秘密传输,需要用户自己定义协议不让外人知道。
- 协议简述
协议其实就是你在传输之前你必须要遵循的书写规范,比如寄快递,寄件人收件人基本信息就属于一个规范,这样快递员才能正确无误收到。
比如有:消息的类型,消息语法,各种字段解析出来必须是有对应的含义。
网络应用需求
作为正常的网络用户,我们最基本的需求就是数据不丢失,数据可靠,时间延迟短,一般还有带宽需求(网络)。
不同应用需求不同,比如邮件之类的仅需帮我正确无误送达即可,对时间没有太高要求,可以相对久一点。但是视频与网络电话就不能容忍延迟了,宁可牺牲一些数据的丢失都必须要接近实时通信的要求。
- Internet网络最基本的两种传输协议
TCP:面向连接,可靠传输,有拥塞控制(限制发送方发送快慢),有流量控制(限制发送发送速度不能快于接收方接受能力),没有时间保障,没有带宽保障。 - UDP:无连接,不可靠传输,以及TCP提供的其他服务他都没有。(但是很爽啊,网速快啊)
WEB应用
- 感谢万维网WEB发明者,Tim Berners-Lee。
- WEB应用就是网页互链接
- 网页Page包含很多对象。这些对象就是我们在浏览器向服务器请求的一系列数据。最基本就是一个Html文件。
- 如何请求到对应的对象?
URL:统一资源定位器。就是网址。
网址有一个基本协议,一般开头是HTTP,但可以省略,然后就是能够唯一标识的域名地址,域名往后就是你要请求的项目资源目录。
比如:https://www.baidu.com/newspage… - 万维网WEB遵循的协议
- 超文本传输协议->HTTP(HyperText Transfer Protocol)
- C/S结构:常规的服务器与客户机关系
- 使用TCP进行传输,所以万维网是可靠的传输服务。
- 可选遵循的HTTP版本:1.0/1.1。1.0是非持久性连接,1.1是持久性连接。
- 有无状态连接:服务器是否维护对于客户机的历史请求信息。
HTTP协议
1:HTTP的连接类型
- 1.0版本(非持久性连接)
对于每一个(每一次开启的)TCP连接最多允许传输一个对象 - 1.1版本(持久性连接)
既然提出1.1版本必然是解决1.0的问题,每一个TCP连接都能传输多个对象。(1.1默认使用持久性连接)
非持久性连接与持久性连接的区别
- 非持久性
1:客户端sendTCP连接请求信息 --> 服务器在80端口等待TCP连接,连接成功后send信息通知客户端
2:客户端收到连接成功信息后再发送请求需要的信息–>服务器收到后就发送响应
3:当服务器发送响应信息之后就关闭TCP连接
4:客户端收到响应信息后开始按照规定的协议解析信息就拿到自己的信息了。
这时候双方已经没有任何联系了,如果后续发现有的数据没有请求完全,则继续执行上面几个步骤。这就是非持久性连接。
毋庸置疑的有时候我们要解决这个问题才能达到我们的目的,所以就是必须要有在连接建立之后不断开的操作,就有了1.1的HTTP就是持久性连接。
花费的时间为:(若需要发送两次请求)
2RTT+数据发送的时间
缺点:如果每一个请求都这样,那么给服务器造成的影响非同小可。几乎每一个用户都不断地创建TCPsay hello,服务器会非常的崩溃。
- 持久性连接
客户端发送TCP连接–>服务器在80等待TCP连接,收到后就建立连接,并发送信息通告客户端–>客户端接收到连接成功消息后发送请求信息–>服务器收到后解析请求然后将客户端所需的信息封装到相应消息里面发送然后这时候不关闭TCP连接而是继续保持TCP连接->之后客户端收到后就根据HTTP协议解析对应的响应体。目前为止都是和非持久性连接一模一样的操作,接下来,如果客户端发现有几张图片没有请求到,那么他现在还可以继续用该TCP连接继续发送请求,不用重新开一个TCP连接。
持久性连接两种机制:
1、无流水机制=客户端需要在收到自己发出去请求的相应之后才会继续连着再发另一个所需的请求,每一个引用的对象耗时就是一个RTT,但省去了创建TCP连接的步骤。
花费的时间为:
一次RTT请求连接+每一次引用对象的一个RTT
2、流水线机制=客户端不管你服务器是否发了响应,客户端只要遇到一个引用对象,我只管尽快发出去请求,有几个就发几个,同理也是省去了再次建立TCP连接操作,这种流水线的理想情况下是一个RTT,因为只是做到尽快发送。
花费的时间为:
一次RTT请求连接+每次发送数据时间
优点:1.1就是客户端只要发送了一次TCP连接,当收到服务器的确认连接信息后,会尽快发出请求,都是用一个TCP请求,所以在理想情况下耗时仅需一个RTT。
因此二者的区别就是打完招呼之后是否能够聊下去的事情。持久性就可以,连接TCP后,你还可以继续向服务器请求,不用又建立连接又要say hello。
:2:HTTP的消息格式
分为两类消息:①请求消息②响应消息
- ①:请求消息
ASCII码:方便可读。
第一行:请求行(请求方法,URL,HTTP版本)
第二行:请求服务器的域名
第三行:客户端浏览器,便于服务器根据你的浏览器发送对应的消息相应。(同时也为了防止一些裸爬虫)
第四行:连接是否关闭
第五行:给客户端发送的语言,就是客户端希望收到一个什么语言的HTTP响应对象。
往后还有行的话可能是消息body,比如Cookie等用于发送用户账户密码信息,存放在HTTP请求消息类型body里面,发送给服务器后判断是否为合法用户等功能。

两种版本的请求方法。
HTTP1.0
- GET
- POST
- HEAD(一般用于测试)
目的是请Server不要将请求的对象放入响应消息中。
HTTP1.1 - GET、POST、HESD
- PUT
将消息体中的文件上传到URL字段指定的路径中。 - DELETE
删除URL字段所指定的文件(用于像云空间-百度网盘之类的)
- ②:响应消息
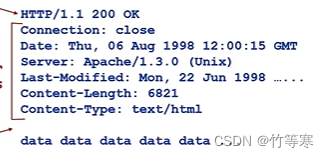
第一行:HTTP版本号+200+ OK (200表示满足请求的信息表示OK,响应成功)
第二行:Connection关闭
第三行:本次相应消息在服务器内部生成的时间
第四行:服务器类型
第五行:最后一次修改的时间。在WEB缓存技术中用于向服务器发送在该时间之后是否有修改过网页(更新网页内容)
第六行:内容长度(大小)
第七行:内容类型
往后行是响应的数据body,客户端解析就是解析这些,根据请求拉过来的这些数据展示网页。
Cookie技术
Cookie的提出是为了解决HTTP无状态协议,无状态不实现记录用户的历史动作,比如登录记住密码问题。这时候就可以根据Cookie将密码缓存下来,在用户下一次进入登录界面之时能够从缓存中将账户密码记住,然后放在登录界面中,无须用户再次输入账户密码。(当然涉及到私人的数据必须要经过加密方可存入Cookie)
Cookie比Session的作用范围更广,Cookie一般存储在浏览器中,只要不清除Cookie数据并且还在存活时间内就一直存在。Cookie是浏览器进行管理的。
还能通携带Cookie记录的一些用户行为发送给服务器,服务器根据这些Cookie行为,计算出用户的偏好然后进行推送。(这就产生隐私问题,我们的一举一动都被监督着,裸奔上网)
WEB缓存/代理服务器技术
为何提出?
为了快速满足用户的HTTP请求,同时也缓解了服务器的负荷。有点像分布式的操作。
-
解释:
用户不是第一次访问服务器的话,并且ISP组织了这种代理服务器,那么用户再一次访问服务器的时候就是在访问代理服务器(前提是代理服务器与服务器的内容之间是一样的,也就是服务器没有更新内容),代理服务器就是缓存了用户访问的网页。
现有一个用户再次访问网页,向代理服务器发送请求,发现HTTP请求的对象被缓存在了代理服务器中,那么直接发送给用户即可,简单快捷。如果没有缓存,就向服务器发送同样的请求,拿到后缓存一份,然后再响应给客户端。
这样看来,缓存服务器既充当了客户端,又充当了服务器,双面人。 -
优点
代理服务器优点真的非同小可,不仅能缓解服务器的压力,还能缓解链路上的压力,又提高了网速。
假如说一个局域网内有代理服务器,边缘路由器的数据运输能够减轻不少,因为大家都是从代理服务器中获取数据,只有在少数情况下要通过边缘路由去往原始服务器请求数据,代理服务器也在本地局域网内,解决了传输距离问题,能将数据快速传输抵达客户机。链路利用率大大减少,很小的几率造成网络拥堵,网络延迟很短。(对于供应商来说成本减少了,不用花大价钱提高带宽,即使提高了也未必能满足愈来愈多的客户) -
代理服务器如何运作
在请求消息中的If-modified-since,就是HTTP请求消息中讲到过的信息,如果代理服务器带着这个信息向原始服务器请求,如果HTTP对象信息未改变,直接将缓存在代理服务器中的HTTP对象发送给客户机,如果该HTTP对象版本与原始服务器版本不一致,就需要向原始服务器请求新的HTTP对象,然后自己缓存一份,发送给客户机。
因此我们浏览网页的时候一般都是向代理服务器发送请求。
Email应用
组成Email的部分:邮件客户端,邮件服务器,SMTP协议
- 邮件客户端
读写Email消息
与服务器进行交互 - 邮件服务器
存储用户发送的邮件
消息队列:存储等待发送的Email,比如设置的定时发送 - SMTP协议
SMTP协议
- 提供给邮件服务器之间的一种协议,按照该协议进行数据的传输与解析
- 使用TCP进行Email的可靠传输。
- 使用25端口号
- 命令/响应交互模式(都是采用ASCII文本,之后出现MIME)
如下命令交互:
如图所示,进行握手之后还能进行多次操作就代表是持久性连接,直到用户输入.表示邮件信息结束,然后使用QUIT命令退出结束连接。
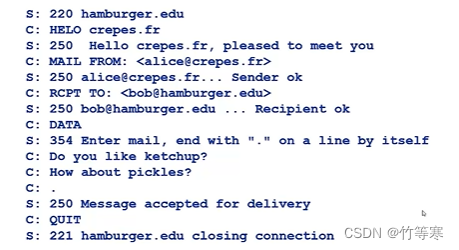
与HTTP协议的区别很明显,HTTP是请求之后,用对象将数据拉回来,展示在自己的浏览器页面上,而SMTP协议是自己一步一步的将数据推出去,即:建立连接之后,输入命令一步一步的将自己的邮件推出去。
Email消息格式(SMTP传输消息的格式)
头部行:
- To
- From
- Subject
消息体
- 消息本身
- ASCII码字符(只允许)
很显然如果只允许ASCII我们是不可能满足的。
MIME:多媒体邮件扩展
在传输消息格式头部中增加一个版本号:MIME-Version:…
这样就可以传输多媒体邮件消息了。

注:Base64是网络传输中常用的编码方式。
POP3协议
通过SMTP协议发完邮件之后,对方通过POP3协议在邮件服务器中读取邮件并进行接收。(同样是命令交互的方式)
首先客户端认证过程(登录步骤):
- User:用户名
- Pass:密码
等待服务器响应(两种响应结果,要么成功要么失败)
- +OK
- -ERR
假设登录,就可以进行功能操作(事务阶段):
- List:列出消息数量
- Retr:用编号获取消息
- Dele:删除消息
- Quit:退出
POP3模式
- “下载并删除”模式
假如用户在办公室将其一封邮件下载下来了,但是回到家之后还想再次获取该邮件,就获取不到了,这就存在一个问题就是一次性的问题,但优点就是邮件服务器空间压力不大。(由于早期的内存非常小,所以该模式是非常有必要的) - “下载并保持”模式
图穷见匕,下载完之后还保存着,不会删除,回到家之后你仍旧可以继续登录POP3,从你的邮箱里面(当然前提是你邮箱内存还有)读取出来,一般都是采用这种,因为现在的内存虽说有限,但是相比早起只有几兆的内存来说已经非常够用了。 - POP3是一个无状态的协议
IMAP
- 所有消息统一存放在服务器中。
- 由于存放在服务器中,所以我们可以进行更多操作:
比如允许用户利用文件夹形式组织邮件(并且可以直接看到一封邮件的信息头) - IMAP支持跨会话(Session)的用户状态
比如:你创建了一个文件夹保存了一些邮件在该文件夹里面,我在数据库中就同步记录,你下次登录的时候依旧是该文件夹对应映射你存放着的邮件(即 跨会话,Session不是同一次也可以实现,说白了就是存你的行为在数据库中)
DNS应用
DNS是一个核心服务(域名解析系统)
方便用户在访问网页的时候不用输入IP地址,而是通过域名来访问更容易记住。DNS就是把域名解析成IP地址返回给用户。(解析成IP地址也是为了路由器识别)
-
域名解析系统是一个分布式的数据库,并且是一个应用层协议,有对应的应用软件实现域名解析。
-
DNS服务
为了翻译域名,转为可访问的IP地址。
给主机起别名
给邮件服务器起别名
负载均衡,Web服务器可以提供多个映射IP地址(因为大的厂商一般拥有多台服务器) -
分层次数据库
Root根域名服务器
↓
顶级域名服务器(国家顶级域名:cn)
↓
权威域名服务器(服务提供商自己提供)
↓
本地域名服务器(ISP提供,比如某高校的本地域名服务器代理) -
DNS查询
①迭代查询
一层一层的查询,每一次都是从自己服务器发起查询,并且是从Root高往下查
②递归查询
只需要查询一个域名服务器,让其他服务器帮你发起查询找。 -
DNS记录(数据库里面如何存储的)
RR(name,value,type,ttl)
- Type = A
Name : 主机域名
Value :IP地址- Type = NS
Name : 域名(edu.cn)
Value : 该域名权威域名解析服务器的主机域名
Type = CNAME
Name : 某一真实域名的别名
Value:真实域名
Type = MX
Value是Name相对应的邮件服务器可以看出Type = A 与Type = NS的这哥两是一对的,注册的时候这两个要一起填(数据库的相关知识)
DNS协议
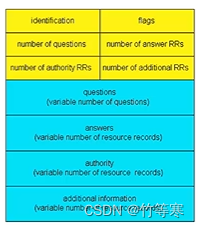
好消息是DNS的消息格式查询与回复消息都一样
- 如何注册域名
向域名管理机构申请,成功后要在数据库中插入两种类型的信息
①(域名,域名解析服务器,NS)
②(域名解析服务器,该域名解析服务器的IP地址,A)
域名解析服务器分层的原因是考虑到用户数量的庞大,所以为了分担Root域名服务器的压力就必须要分层。
首先我们访问的域名解析出来的IP地址其实大部分都存在Local DNS Server,也就是运营商提供的本地DNS服务器,比如在学校的校园网内的本地DNS解析服务器可能就存有大量的域名IP地址,有时候我们浏览器没有访问过就会查看本地主机,若没有缓存记录就会向Local DNS Server查,一般到这就结束了,如果还没有就必须向Root请求了。(中国还未拥有自己的根服务器,所以到国外去比较耗时,我觉得这时候访问根服务器应该是通过卫星操作的)