目录
1.什么是序列化
2.JAVA中的序列化
2.1.成员变量必须可序列化
2.2.transient关键字,可避免被序列化
2.3.无法更新状态
2.4.serialVersionUID
3.JDK序列化算法
4.序列化在实际中的一些应用
1.什么是序列化
序列化就是将对象转换为二进制格式的过程。对象转为二进制后,可以方便进行存储或者在网络中传输。要将对象转为二进制,首先就要用一种数据结构来描述对象,这样进行对象的网络传输的时候,发送方和接收方才能按照约定好的格式来序列化、反序列化对象。不同的序列化算法就是用不同的数据结构来描述对象,序列化算法很多,这里举几个常见的:
-
json
-
xml
-
yaml
-
Java Serialization
前三种见名知意,就是分别用json、xml、yaml来描述对象,第四种Java Serialization是JDK默认的序列化算法,其使用了一种称为 Java Object Serialization Stream Protocol 的二进制格式来描述JAVA对象。
2.JAVA中的序列化
JDK种提供了Serializable接口用来声明哪些类可以被序列化,提供了ObjectOutputStream、ObjectOutputStream来进行序列化和反序列化。
JAVA的序列化中有几个注意点:
-
成员变量必须可序列化
-
transient关键字,可避免被序列化
-
无法更新状态
-
serialVersionUID
2.1.成员变量必须可序列化
如果所要序列化的对象的成员属性中含有对其他对象的引用,要求所引用的对象也必须是可序列化的(实现serializable接口),否则会序列化失败。
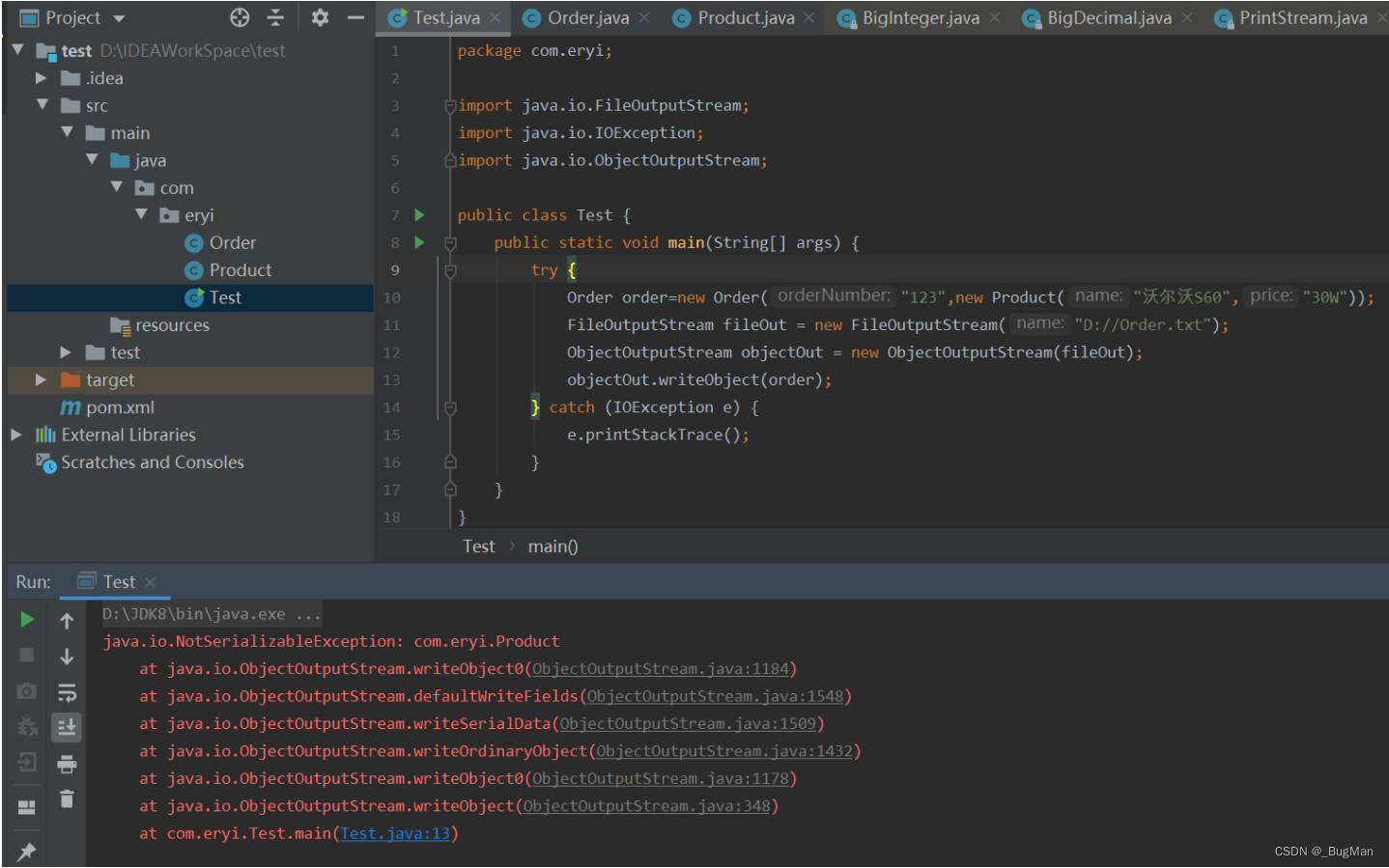
订单对象中包含一个产品对象,Order实现了序列化接口,但是product没有实现序列化接口:
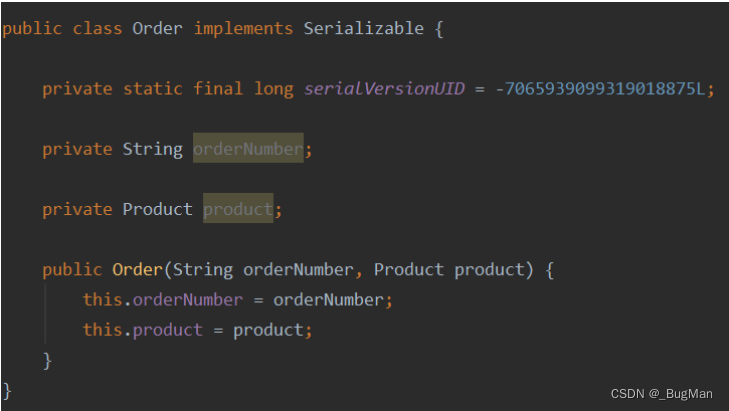
序列化Order的时候会报错:
2.2.transient关键字,可避免被序列化
用transient修饰属性:
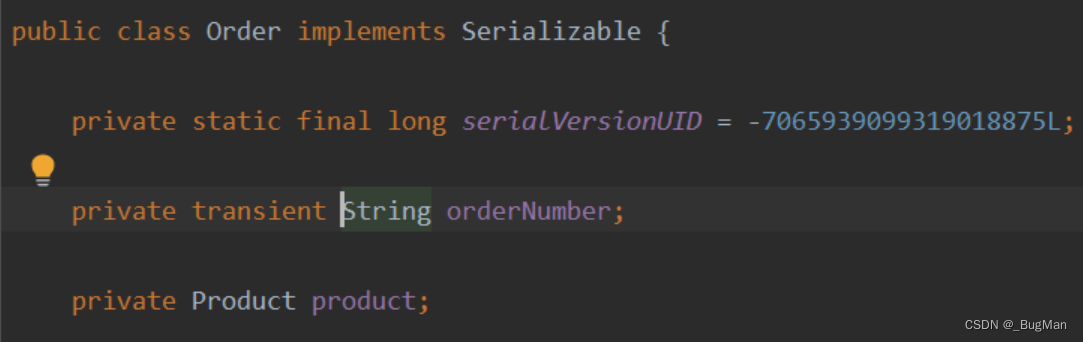
可以看到属性值不会被序列化出去,其会是默认值:
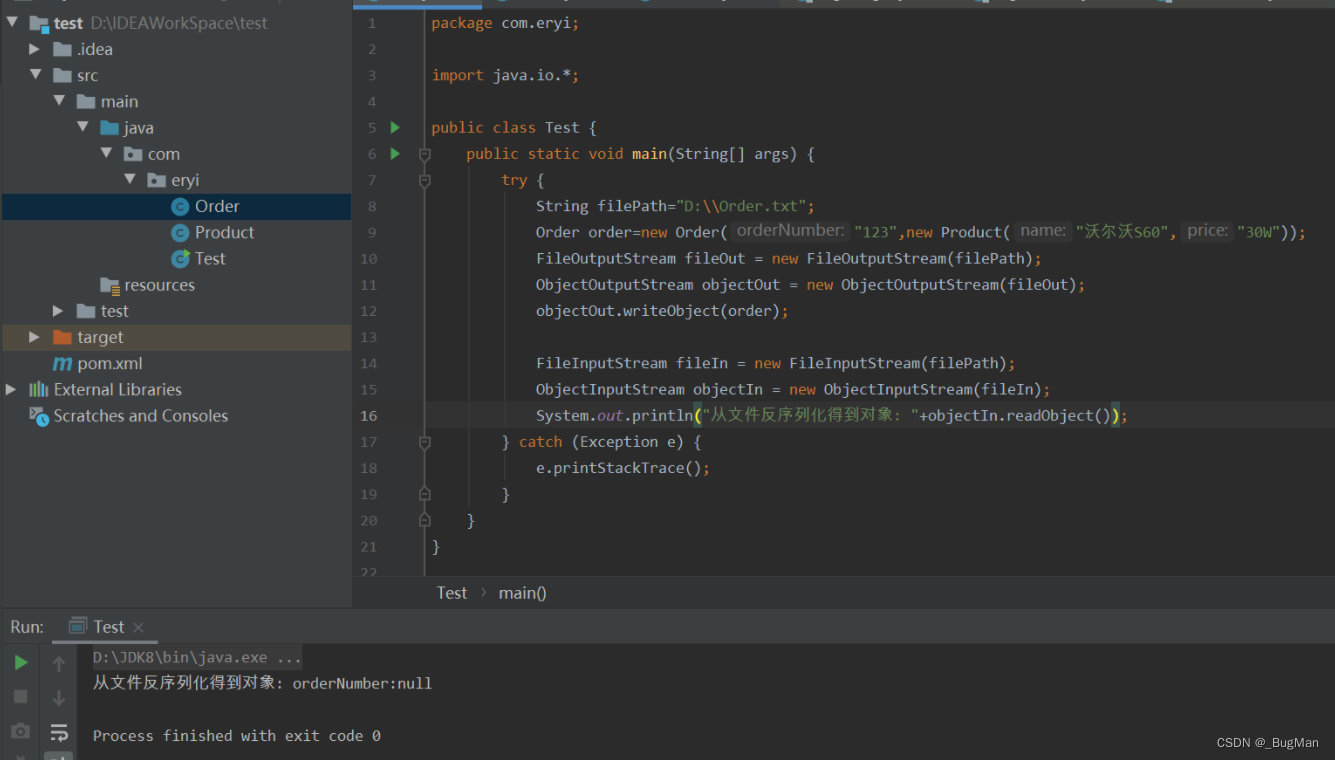
2.3.无法更新状态
由于java序利化算法不会重复序列化同一个对象,如果对象的内容更改后,,再次序列化,并不会再次将此对象转换为字节序列。
我们对同一个对象序列化两次,然后输出其属性值:
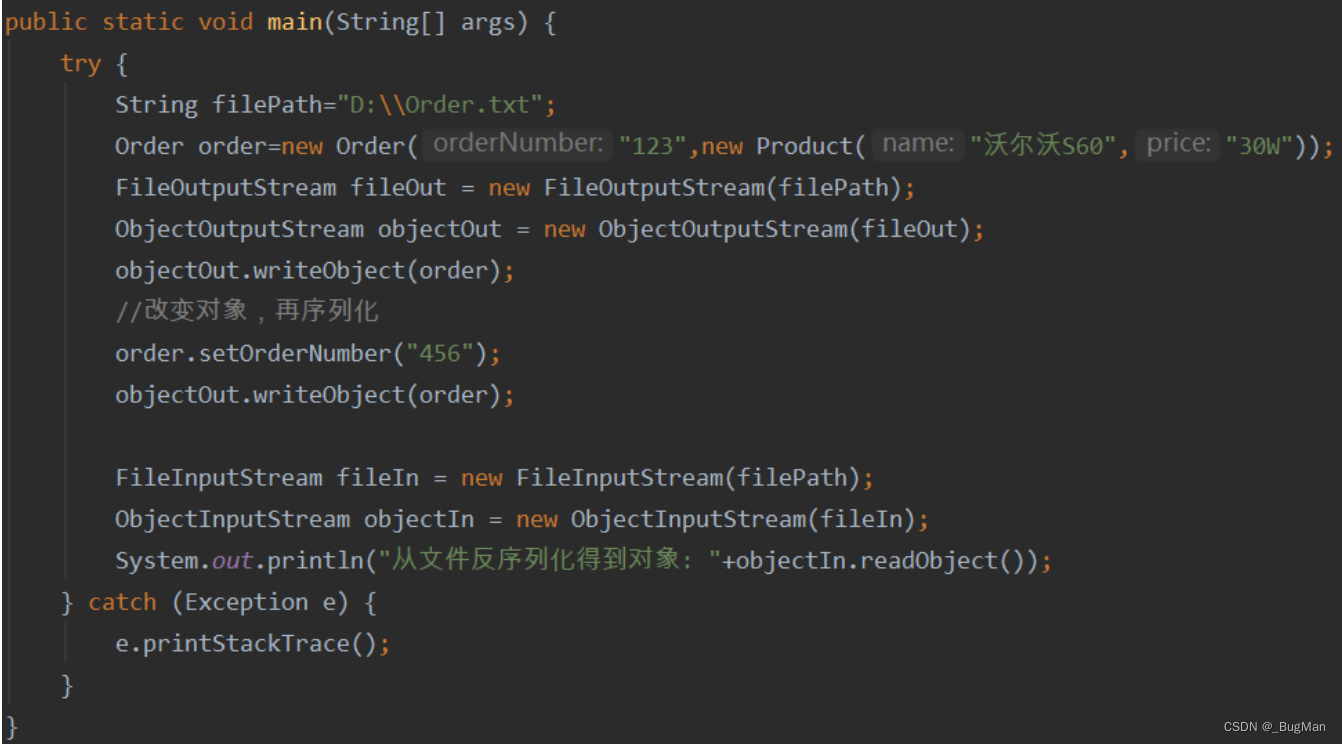
可以看到其实只有第一次序列化是生效的:
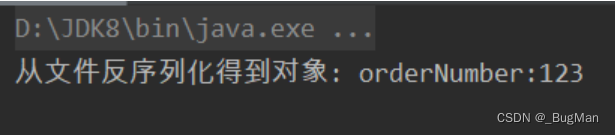
2.4.serialVersionUID
序列化版本号,类似于乐观锁中的版本号,用来保证序列化后的字节序列没有被改动过,反序列化回来后和原来的程序是兼容的。
serialVersionUID不会自动改变,而是留给程序员手动更改的一个版本号标志位。更改了序列化文件的程序员一并更改版本号提示后来的人文件被更改过。
如果在反序列化时,类的 serialVersionUID 与序列化时的版本号不匹配,那么会抛出 InvalidClassException 异常,表示类的版本不兼容,无法进行反序列化。
3.JDK序列化算法
Java Object Serialization Stream Protocol规定整个对象序列化后的文件由三部分组成:
-
头部(Header):包含魔数(Magic Number)和版本号(Version Number)。魔数标识了该流是 Java 序列化流,版本号用于指定序列化协议的版本。
-
类描述符表(Class Descriptor Table):包含了序列化流中所引用的类的描述符信息。每个类描述符包括类的名称、序列化编号、序列化版本号等信息。
-
对象数据(Object Data):按照序列化顺序包含了被序列化对象的状态信息。这包括了对象的实例变量、类信息等。
以上一节我们在D盘下生成了一个名叫Order.txt的序列化文件为例,我们来读一读JAVA的序列化文件。
要注意的是如果直接打开,因为编码的原因看见的会是乱码,需要用16进制的方式,打开它来看看,要注意的是普通的文本工具都没办法用16进制的方式直接打开文件,这里我们用代码来将文本中的内容以16进制的方式输出,代码如下:
public static void main(String[] args) throws IOException {
displayFileInHex("D:\\Order.txt");
}
private static void displayFileInHex(String filePath) throws IOException {
try (FileInputStream fileIn = new FileInputStream(filePath)) {
int bytesRead;
byte[] buffer = new byte[16];
while ((bytesRead = fileIn.read(buffer)) != -1) {
// 打印十六进制内容
for (int i = 0; i < bytesRead; i++) {
System.out.printf("%02X ", buffer[i]);
}
// 填充缺失的位置
if (bytesRead < 16) {
int missingBytes = 16 - bytesRead;
for (int i = 0; i < missingBytes; i++) {
System.out.print(" ");
}
}
System.out.println("\n");
}
}
}输出结果:
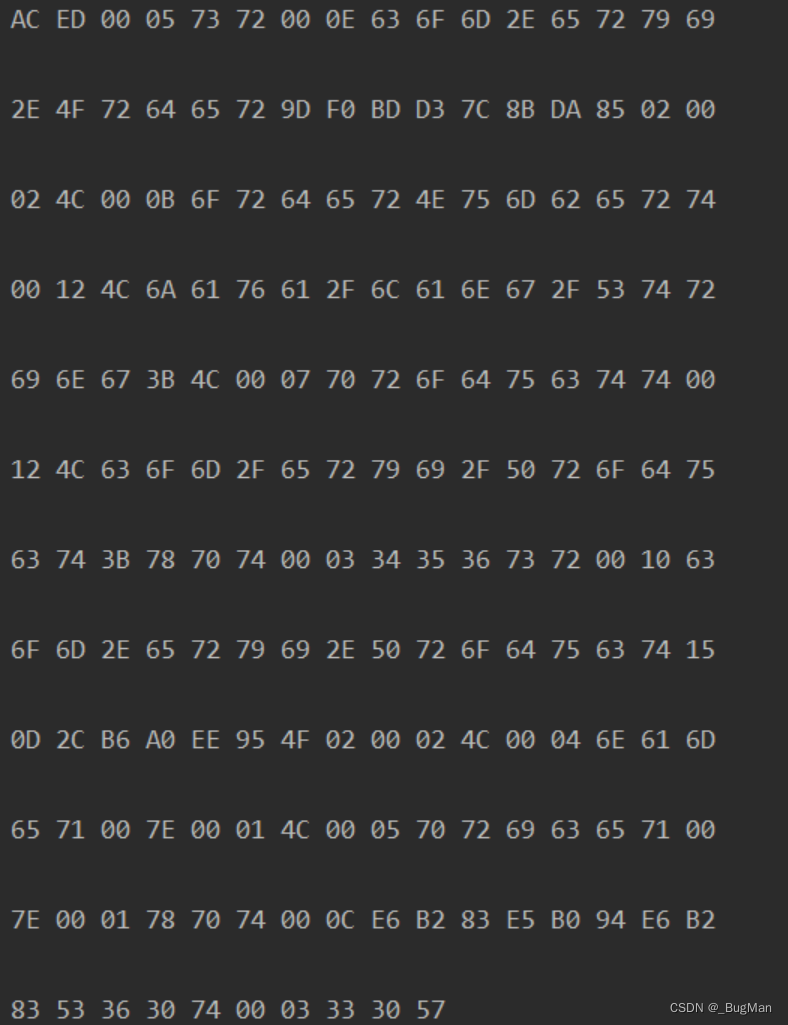
用Java Object Serialization Stream Protocol来解析一下上面的字节内容:
-
头部(Header):
AC ED表示 Java 序列化文件的标识符。 -
版本号:
00 05表示版本号为 5。 -
对象数据:
73 72 00 0E 63 6F 6D 2E 65 72 79 69 2E 4F 72 64 65 72是一个类描述符,指明被序列化对象所属的类为com.eryi.Order。 -
对象数据:
9D F0 BD D3 7C 8B DA 85 02 00 02 4C 00 0B 6F 72 64 65 72 4E 75 6D 62 65 72 74 00 12 4C 6A 61 76 61 2F 6C 61 6E 67 2F 53 74 72 69 6E 67 3B是一个对象的实例数据,包含了对象的状态信息。 -
对象数据:
4C 00 07 70 72 6F 64 75 63 74是一个对象的实例变量的描述符,指明变量名为product。 -
对象数据:
74 00 12 4C 63 6F 6D 2F 65 72 79 69 2F 50 72 6F 64 75 63 74 3B是一个字符串,表示变量值为"com.eryi.Product"。 -
对象数据:
78 70 74 00 03 34 35 36是一个对象的实例变量的描述符,指明变量名为xpt。 -
对象数据:
73 72 00 10 63 6F 6D 2E 65 72 79 69 2E 50 72 6F 64 75 63 74是一个类描述符,指明变量类型为com.eryi.Product。 -
对象数据:
15 0D 2C B6 A0 EE 95 4F 02 00 02是一个对象的实例数据,包含了变量的状态信息。 -
对象数据:
4C 00 04 6E 61 6D 65是一个对象的实例变量的描述符,指明变量名为name。 -
对象数据:
71 00 7E 00 01是一个字符串,表示变量值为"name"。 -
对象数据:
4C 00 05 70 72 69 63 65是一个对象的实例变量的描述符,指明变量名为price。 -
对象数据:
71 00 7E 00 01是一个字符串,表示变量值为"price"。 -
对象数据:
78 70 74 00 0C E6 B2 83 E5 B0 94 E6 B2 83 53 36 30是一个对象的实例变量的描述符,指明变量名为xpt。 -
对象数据:
74 00 03 33 30 57是一个字符串,表示变量值为"30W"。
4.序列化在实际中的一些应用
首先我们要知道序列化是可以跨JVM的,JDK的序列化算法只是规定了数据结构,所以可以在一个JVM上序列化,然后在另一个JVM中进行反序列化,这也就是说序列化可以用来进行通信时的数据传输。并且序列化在进行数据传输上具有很好的性能优势,因为序列化是直接将对象转为了二进制,接收端收到数据后直接反序列化就可以得到对象。如果是以JSON之类的文本结构传输数据,那么接收端收到数据后要首先将二进制数据流转为文本结构,然后再解析文本结构将其转为对象。整个过程比起序列化和反序列化来,多了很多中间步骤,性能上肯定要慢很多。
由于序列化具有上面这样的优势,其被dubbo所采用。dubbo作为以高性能著称的RPC框架,其高性能有一方面就体现在使用了序列化上。dubbo自定义了报文,然后通过序列化的方式将数据直接塞进自定义的报文结构中,接收端收到后直接反序列化就可以得到数据。
所以序列化在追求一些高性能的通信场景下会是作为参数转换的一个不错选择。
同时,序列化又存在安全隐患,由于serialVersionUID和数据没有任何关系,修改属性的数据值后,仍然可以反序列化回来,而且任何JVM拿到序列化的数据都可以进行反序列化,会存在数据被拦截然后恶意修改的风险。不过这个问题并不是序列化所独有的问题,只要是没有加密机制的通信协议都会存在这个问题,相比于同样是透明传输的HTTP来说,用序列化在JAVA EE体系中传数据对象确实性能更优。