文旨在解决生成对抗网络(GAN)中控制生成图像的问题。通过“拖动”图像中的任意点,实现用户交互式精确控制生成图像的姿态、形状、表情和布局。
这个名叫DragGAN的模型,本质上是为各种GAN开发的一种交互式图像操作方法。论文以StyleGAN2架构为基础,实现了点点鼠标、拽一拽关键点就能P图的效果。
通过两个主要组件实现GAN的交互式控制:
1)基于特征的运动监督,驱动手柄点向目标位置移动;
2)新的点跟踪方法,利用辨别式生成器特征来不断定位手柄点的位置。与现有方法相比,DragGAN不需要手动注释训练数据或先验3D模型,具有更高的灵活性、精度和通用性。实验结果表明,DragGAN在图像操纵和点跟踪任务中优于先前的方法。同时,本文还展示了通过GAN反演对真实图像进行操纵的能力。作者开源了代码和数据集,为后续研究提供了便利。
论文地址:
https://vcai.mpi-inf.mpg.de/projects/DragGAN/data/paper.pdf
代码地址:
https://github.com/XingangPan/DragGAN
图像编辑(Image Manipulation)一直以来火热的研究方向,而且具有很广泛的应用场景。现有的图像编辑主要有以下四类:
(1)基于全监督学习的模型,如InterfaceGAN;
(2)基于语义分割图的模型,如SPADE;
(3)基于人体关键点的模型,如HumanGAN;
(4)基于文本引导的模型,如Imagic。然而现有的这些模型缺乏对空间属性编辑的灵活性,准确性,通用性。以皮影戏为例,通过控制皮影人物的关键点,可以做出各种各样的动作。
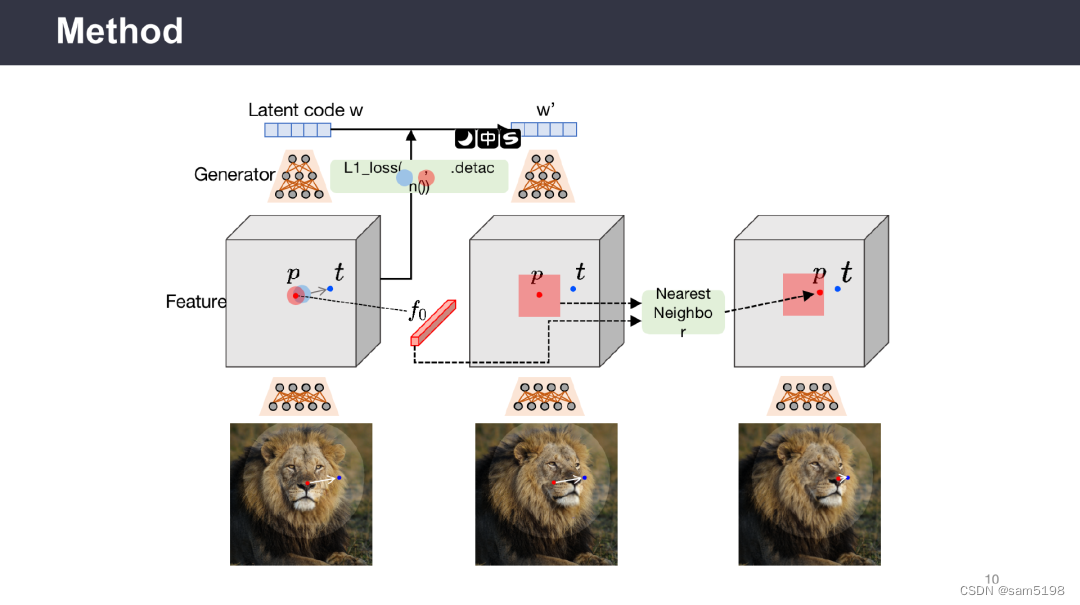
为了让模型在具有利用关键点能力的同时,并可以在编辑图像时推理出被遮挡的区域,潘新钢教授团队提出了一种基于生成对抗网络(Generative Adversarial Networks,GAN)的实时交互式图像编辑模型Drag Your GAN。
用户在图像上确定抓取点(Handle Point)和目标点(Target Point),将图像与点信息一起输入到生成器中获取隐向量(Latent Code),该模型通过使用多步式迭代并在每一步迭代过程中使用动态监督损失函数,逐步优化隐向量,直至抓取点逐步移动到目标点。此外,用户可以选择修改区域,只编辑区域内的部分。通过在多个数据集上验证,展现了Drag Your GAN模型强大的图像编辑能力。

该报告介绍了通过交互式关键点拖拽的方式来编辑图像的生成式模型Drag Your GAN,改模型的核心为关键点动态监督和关键点跟踪。最后,潘新钢教授表示,通过文本引导和拖拽关键点相结合的方式将会引领图像编辑领域的未来。
针对当前的生成模型,Diffusion Model和GAN哪个模型表现更好?
潘新钢教授认为,两个模型各有优劣,但是Diffusion Model的上限更高,随着算力,硬件性能的提高,Diffusion Model的重要性会越来越大。
两个模型主要有以下三点不同:
1. 在计算需求方面,Diffusion Model需要很大的计算量,GAN虽然在生成质量上可能不比Diffusion Model,但是不要特别大的计算量,可以在硬件部署上达到实时生成。
2. 在图像分布连续性方面,由于Diffusion Model的迭代式计算带来的高度非线性,所以在一些任务上,如视频编辑,会出现跳变和抖动。但是GAN是通过单步计算,生成的图像会表现得更加连续。
3. 在可编辑性方面,基于GAN所得到的隐空间表现出更具有上下文语义的特征。通过对该空间进行编辑,使得图像具有很强的可编辑性。但是Diffusion Model是从耦合了空间信息的随机噪声图生成图像, 因此在可编辑性上相对不易控制。
在当今计算资源消耗越来越大,未来几年在学术界,特别是针对大部分高校的老师和学生缺乏计算资源,他们研究重心应该是什么?
有教授认为:
1、方法在大部分情况下是通用的,可以在负担得起的计算资源上验证方法的有效性;
2、有些任务并不依赖大模型,而且并不是所有的问题都要从头开始训练模型;
3、在未来,校企合作可能会成为更广泛的研究方式。