目录
页面结构的简单认识
爬虫概念理解
urllib库使用
爬虫解析工具xpath
JsonPath
Selenium
requests基本使用
scrapy
页面结构的简单认识
如图是我们在pycharm中创建一个HTML文件后所看到的内容
这里我们需要认识的是上图的代码结构,即html标签包含了head标签与body标签
table标签
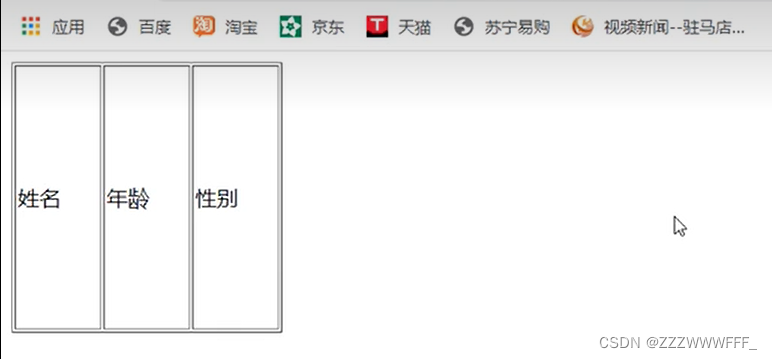
table标签代表了一个网页页面中的表格,其包含了行和列,其中行标签我们使用tr标签,在行中我们可以定义列,列我们使用的是td标签
如图我们在body标签中 编写了上图代码,即定义了一个一行三列的表格
在浏览器中运行可以看到
如果想要表格的结构更明确,我们可以这样
为表格添加一些属性,运行结果如下
ul标签
ul标签代表的是网页中的无序列表,我们可以往列表中添加我们想要的元素,这些元素我们使用li标签进行定义
ol标签
ol标签代表的是网页中的有序列表,其中的元素也是使用li标签定义
a标签
a标签代表的是网页中的超链接,即点击后可以进行页面的跳转,我们使用href属性指定想要的跳转到的域名
点击即跳转到百度








爬虫概念理解
我们一般有以下两种理解
- 通过一个程序,根据url进行爬取网页,获取有用信息
- 使用程序模拟浏览器,去向服务器发送请求,获取相应信息
爬虫核心
- 爬取网页:爬取整个网页,包含了网页中所有的内容
- 解析数据:将你得到的数据进行解析
- 难点:爬虫与反爬虫之间的博弈

urllib库使用
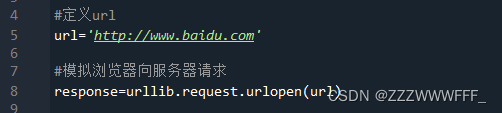
urllib是python自带的库,我们可以直接使用,无需下载,下面演示使用urllib爬取baidu首页源码
先导入该库
再使用urlopen()函数去向参数url发出请求,返回值为服务器的响应对象 ,其中包含了关于该网页的内容,也包括源码,我们使用read()方法即可得到源码,但是注意得到的是二进制形式的数据,因此我们需要将其解码,这里使用编码为utf8的decode()方法进行解码
再打印出解码后的数据即可
一个类型与六个方法
- 一个类型即我们上面样例中urlopen()的返回值为HTTPResponse类型
六个方法如下:
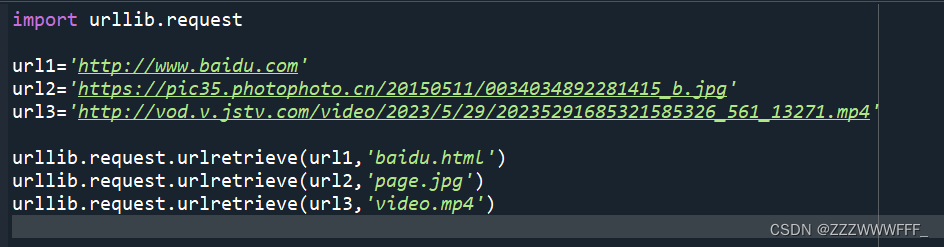
将爬取到的网页、图片、视频下载到本地
这里主要使用的函数是urlretrieve(参数1,参数2)
其中参数1是需要下载的对象地址,参数2是想要下载到的本地位置,上图中我没有指定位置,因此直接下载到的该python文件的目录下
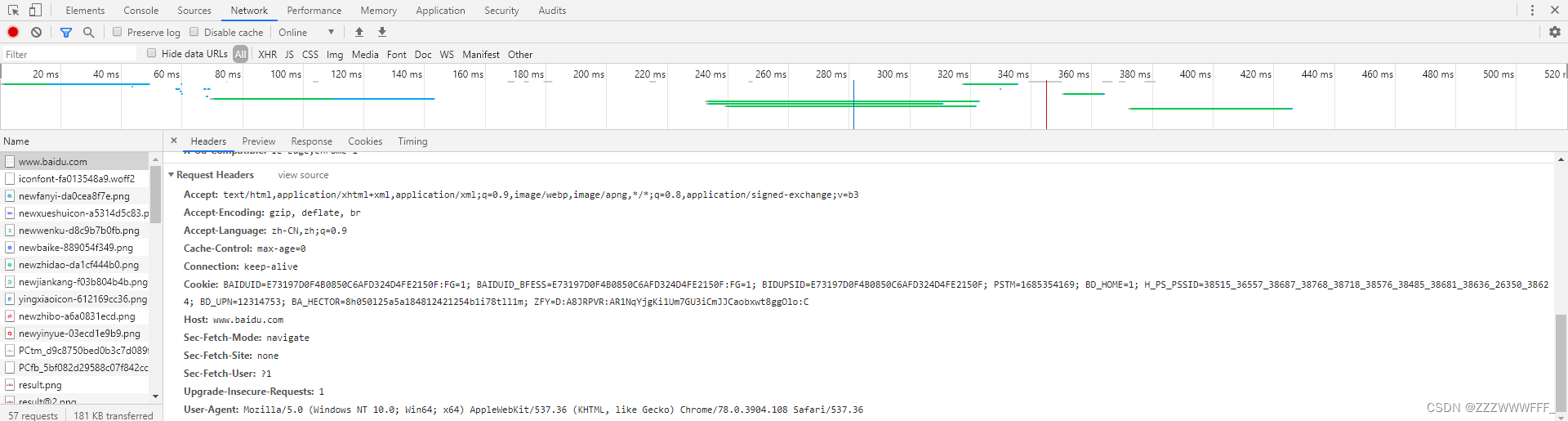
反爬手段User-Agent
User Agent中文名为用户代理,简称 UA。
它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等等。
也就是说,假设:一个平台,设置了UA权限,必须以浏览器进行访问
当你使用爬虫脚本去访问该网站的时候,就会出现,访问失败、没有权限 、或者没有任何资源返回的结果等错误信息。
那么我们应该如何克服它呢??
我们需要在爬虫时添加一个User-Agent请求头即可
具体怎么做呢?
如上图所示,我们在爬取协议为https的百度首页时发现得到的源码很少,就是遇到了反爬手段UA
下面是对url知识的补充
https协议比http协议更为安全
好了继续解决UA
如上,我们在最下面可以看到我们的UA
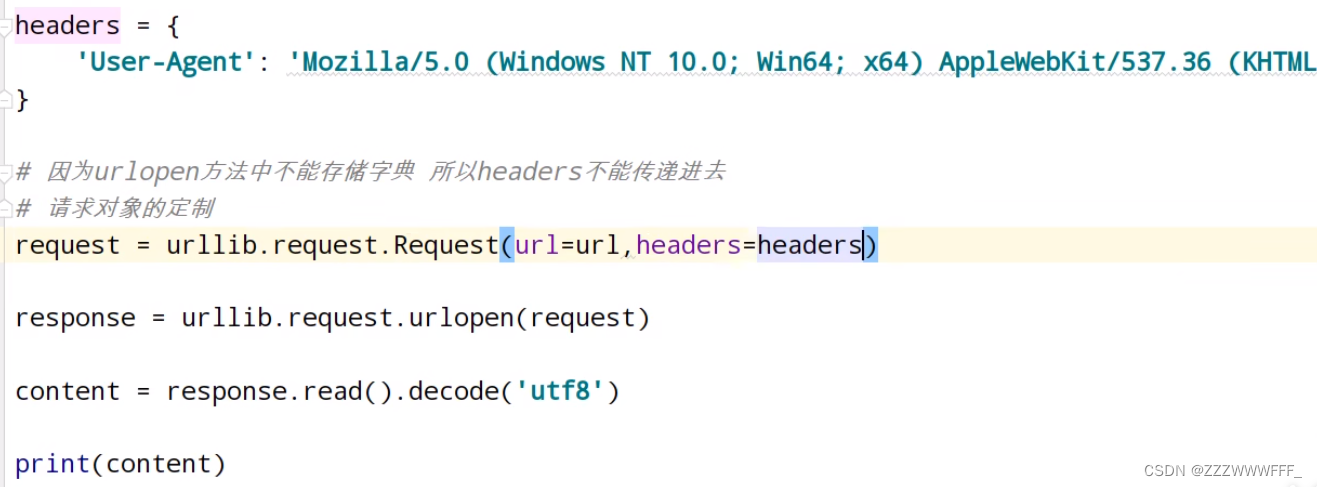
我们将其复制下来,在代码中存储为一个字典,然后使用Request得到一个带有UA的请求头的url,然后按照前面所学即可爬取内容啦
需要强调的是,这里因为Request()方法的参数第二个参数并非headers因此我们需要使用关键字传参
get请求的quote方法
在前面我们在代码中输入一个url时,我们可能会输入包含有中文字符的url
例如
此时如果我们直接就这样按照前面所学去爬取该域名内的源码,会出现编码报错问题,因此我们需要将“周杰伦”进行编码,这里就使用到了urllib.parse.quote()方法,该方法可以将中文字符编码为Unicode,再将其拼接到我们将被输入的url上即可
get请求的urlencode()方法
有时候我们会需要将多个参数拼接到我们的url上,但是此时再去使用quote方法便会变得麻烦,因此就有了urlencode方法,它用于拼接多个参数的url
如下我们将我们需要的参数wd与sex与location拼接到了我们的url上同时实现了爬虫
post请求
post是相对于前面所学的get请求的另外一种请求,二者的区别在于post请求的url参数并不是直接拼接在url后面的,而是在进行 请求对象的定制中 进行传参赋值
下面通过百度翻译例子进行解析
在百度翻译中输入python进行翻译后刷新,其实不难发现,页面上马上就发生了改变,其实这是浏览器快速对服务器进行了请求,我们通过查看这些请求,发现上图中该请求实现了翻译
在获取到该请求的url地址后,我们希望将kw参数传给它
正如上面所说,我们在进行请求对象定制的时候将参数data传给了url,这里需要注意的是data在作为参数传递时必须是编码后的形式,而urlencode得到的是字符串类型是不能直接作为data传给Request的,因此需要encode('utf-8')
反爬手段之header
有时候请求头中仅仅包含UA是不够的,我们需要得到更多的请求头参数
样例演示(爬取百度翻译的详细翻译):
首先在百度翻译的网络请求中找到下面这一条
再得到它的URL
得到对应参数
写入代码
然后按照前面所学的进行爬虫即可

得到结果如下:
我们发现这与我们想要的结果并不同
这是因为网站有另外一种反爬虫手段,即header参数要求更多
我们只需在网站上的请求头所有参数给到 对象的定制里面即可
再次运行 即可
将json文件下载到本地
样例演示(豆瓣动作电影排行榜第一页的爬取)
首先需要找到有效的网络请求
得到对应的URL及其UA
输入代码
需要注意的是这里对于open方法默认是使用gbk编码,我们需要传参时指定为utf-8
如果想要爬取多页数据我们则需要观察网络请求中每一页请求的url
还是上面的例子
我们在找到前三页的网络请求便很容易得到其中的规律
然后遍历我们想要的页数 ,得到对应的url,循环前面的操作即可
多页数据的post爬取
在面对爬取多页数据的需求上,还是一样的步骤
- 在网络请求中找到页面数据的那个请求,对比每一页的请求的URL,找到规律
- 循环遍历每一页,对每一页操作即可
我们观察发现因为网页时post类型的,所以参数并没有直接包含在URL里,因此需要到payload中寻找
对比多页数据不难发现其规律,即每一页的页码即参数中的pageIndex
因此我们循环遍历页数page,每次构建对象的定制时传入对应的page,然后后续按照post的爬虫步骤来即可
urllib中的异常
主要包含以下两类
- URLError
- HTTPError该异常时URLRError的子类
它们都属于urllib.error这个包
其中http异常可能是针对浏览器无法链接到服务器所产生的错误提示
url异常则可能是主机名上出现的错误
我们都可以采用try-except对上述两类异常进行捕获
cookie登录
只要我们拥有某个需要登录才能进入的页面的cookie,我们就可以爬进这个页面,就可以携带者cookie进入到任何页面
因为cookie中包含着登录信息
此外还有一个header参数referer是用来制作图片的防盗链的,即它会判断当前路径是不是由上一个路径进来的
因此如果想要进入一些需要登陆才能进入的页面则一般需要上面两个header参数
Handler处理器
随着业务逻辑的复杂,请求对象的定制已经满足不了我们的需求,例如动态cookie和代理不能仅仅使用urlopen()函数来解决
因此这里提出Handler处理器来处理一些复杂的需求
基本步骤如下:
- 获取Handler对象
- 获取opener对象
- 调用open方法
如上图所示,我们使用Handler来爬取百度首页的源码
代理服务器
我们还可以使用代理IP来实现爬虫
- 代理可以帮助我们突破自身IP限制,访问国外站点
- 访问一些单位或团体内部资源
- 提高访问速度
- 隐藏自身真实IP
具体实现步骤如下:
- 创建request对象
- 创建ProxyHandler对象
- 使用handler对象创建opener对象
- 使用opener.open()函数发送请求
实际上步骤与前面所学类似的,只不过这里使用的是ProxyHandler函数来创建一个handler对象,之后步骤与前面所学一致























爬虫解析工具xpath
首先需要先安装xpath插件到你的浏览器中,这样方便后续使用
然后我们需要下载python的库lxml
可以使用如下命令进行安装
pip install lxml -i https://pypi.douban.com/simple下面是xpath的一些基本语法
xpath可以用于本地的文件解析,也可以对服务器的页面进行解析
但是我们更多地使用xpath对服务器的网页进行解析
下面我们进行简单的样例演示
如上图所示,我们在本地创建一个简单的HTML页面,然后使用xpath对其进行解析
需要注意的是 逻辑运算中的或操作只能针对标签操作
xpath中严格要求标签的成对出现,因此对于单个标签我们需要在其末尾加上/
下面演示解析网页页面(获取百度页面的百度一下)
解析网页页面与本地页面的差别只在于我们在获取页面的tree时,网页页面用的时etree.HTML方法且其参数为网页响应的内容,而本地用的是etree.parse方法且参数为html文件的路径
from lxml import etree import urllib.request #关于爬取图片网站并下载到本地 def create_request(page): if page==1: url = 'https://sc.chinaz.com/tupian/QiCheTuPian.html' else: url = 'https://sc.chinaz.com/tupian/QiCheTuPian_'+str(page)+'.html' header={ 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57' } req=urllib.request.Request(url=url,headers=header) return req def getContent(req): response=urllib.request.urlopen(req) content=response.read().decode('utf-8') return content def download(content): print(content) tree=etree.HTML(content) name_list=tree.xpath('//div[@class="item"]/img/@alt') src_list=tree.xpath('//div[@class="item"]/img/@data-original') for i in range(len(name_list)): name=name_list[i] src='https:'+src_list[i] # print(name,src) urllib.request.urlretrieve(src,'./img/'+name+'.jpg') if __name__=='__main__': st=int(input()) ed=int(input()) for page in range(st,ed+1): #获取对象的定制 req=create_request(page) #获取页面响应内容 content=getContent(req) #下载图片 download(content)
懒加载
需要注意的是,在一些需要加载大量图片的网页中常常会使用到一种策略名为懒加载,即是一种将资源标识为非阻塞(非关键)资源并仅在需要时加载它们的策略
这种策略在我们爬虫时需要注意的是,页面在加载出来的时候的标签可能是错误的,因此我们常常需要在页面加载后查看页面观察页面标签的变化,但是我们的选择是刚开始的标签而非懒加载后的标签!



















JsonPath
需要注意的是JsonPath只能对本地文件进行操作
具体语法可参考JSONPath-简单入门
下面是样例演示
这里是爬取淘票票网站的城市信息
首先在其页面请求得到对应的JSON对象的URL
这里为了验证其是否存在反爬,我们输入其URL,发现并没有得到其数据,因此它有反爬
因此我们需要在header中添加更多的请求头来解决反爬
这样我们就得到JSON文件了
爬取成功






Selenium
Selenium是一个可以帮助我们更好地模拟浏览器功能,避免爬取的内容缺失的一个工具
这里所谓的驱动与浏览器版本之间的映射表实际用处不大
演示样例
此时content中便是页面的源码了
下面是对于页面元素的获取(参考这里)
首先找到想要的标签及其属性
from selenium import webdriver from selenium.webdriver.common.by import By url = 'https://www.baidu.com' path = r'chromedriver.exe' # 得到浏览器对象 browser = webdriver.Chrome() browser.get(url) #通过ID查找 # ele=browser.find_elements(By.ID,'kw') #通过CSS选择器查找 # ele=browser.find_elements(By.CSS_SELECTOR,'#kw') #通过XPATH查找 # ele=browser.find_elements(By.XPATH,'//input[@id="kw"]') #通过属性name查找 # ele=browser.find_elements(By.NAME,'wd') #通过class查找 # ele=browser.find_elements(By.CLASS_NAME,'s_ipt') #通过标签文本查找 # ele=browser.find_elements(By.LINK_TEXT,'贴吧') #通过标签名查找 # ele=browser.find_elements(By.TAG_NAME,'input') print(ele)
元素信息的获取
按照前面所学获取到目标标签之后使用其方法及属性即可获取该标签的信息
selenium的交互
我们在使用selenium操作浏览器的时,还可以与浏览器进行交互
如下:我们打开百度首页后操作浏览器输入“周杰伦”,并搜索,之后操作滚动条到底部点击下一页,再回退到上一页,再进入下一页
import selenium.webdriver import time from selenium.webdriver.common.by import By url='https://www.baidu.com' browser=selenium.webdriver.Edge() #打开页面 browser.get(url) time.sleep(2) inputEle=browser.find_element(By.ID,"kw") #输入周杰伦 inputEle.send_keys("周杰伦") time.sleep(2) baiduEle=browser.find_element(By.ID,"su") #点击百度一下 baiduEle.click() time.sleep(2) #JS脚本 js="document.documentElement.scrollTop=100000" browser.execute_script(js) #滑动到底部 time.sleep(2) next=browser.find_element(By.XPATH,"//a[@class='n']") #点击下一页 next.click() time.sleep(2) #回到上一页 browser.back() time.sleep(2) #回到下一页 browser.forward() time.sleep(2) #退出浏览器 browser.quit() input()
无界面浏览器handless的使用
from selenium import webdriver from selenium.webdriver.chrome.options import Options def share_browser(): chrome_option = Options() chrome_option.add_argument('--headless') chrome_option.add_argument('--disable-gpu') # path是你自己的chrome浏览器的文件路径 path = r'C:\Program Files\Google\Chrome\Application\chrome.exe' chrome_option.binary_location = path browser = webdriver.Chrome(options=chrome_option) return browser获取浏览器对象的代码是固定的,具体的模板如上
后面我们得到浏览器对象browser后即可正常按照前面所学进行爬虫操作





requests基本使用
requests的get请求
import requests url='https://www.baidu.com/s' header={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.43' } data={ 'wd':'北京' } # get方法有三个参数 # url为请求资源路径 # params为参数 # kwargs为字典 response=requests.get(url=url,params=data,headers=header) print(response.text)对比urllib的使用,我们可以发现,requests不需要请求对象的定制,且参数无需进行urlencode编码,而参数是使用params进行传递
requests的post请求
import requests url='https://fanyi.baidu.com/v2transapi?from=en&to=zh' header={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36" } data={ 'from': 'en', 'to': 'zh' } response=requests.post(url=url,headers=header,data=data) content=response.text import json obj=json.loads(content) print(obj)上面的代码是对百度翻译的某个请求进行爬取的代码示例
可以看到post请求无需编解码,且post请求的参数是data,也无需请求对象的定制
requests的代理使用
import requests url='http://www.baidu.com/s?' header={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.43' } data={ 'wd':'周杰伦' } proxy={ 'http':'183.236.232.160:8080' } #直接在参数中加入我们的代理ip字典即可 response=requests.get(url=url,headers=header,params=data,proxies=proxy) print(response.text)requests只需将我们的ip作为字典传入get方法中即可
古诗文网登录样例(requests的cookie登录)
需求为越过登录页面进入到个人信息页面
首先我们需要找到“登录”的请求
这里有个技巧即我们故意输入错误的信息
这样我们就捕获到了上图所示的登录请求
可以观察到该POST请求的参数如上图所示,
观察到前面两个参数我们并不认识并且它们是可变的,这里的技巧是“一般这种我们不认识的参数可能是页面源码中的隐藏标签”
可以看到我们在页面源码中找到了这两个标签,因此这两个参数的值我们可以使用解析工具Xpath得到即可
接着我们只需要再得到验证码参数的值即可,首先再页面源码中得到验证码的来源
接着下载图片即可
注意这里不能使用urllib的urlretrieve方法,因为这样会导致其向服务器发送一次请求,导致验证码改变,即我们获取的验证码不是当前的验证码了,而我们后面使用获取的参数登录时也会失败
这里要使用requests的session方法,该方法可以使得请求变为一个对象
参考
import requests from lxml import etree url='https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx' header={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.43' } response=requests.post(url=url,headers=header) content=response.text tree=etree.HTML(content) #得到隐藏标签属性值 value1=tree.xpath("//input[@id='__VIEWSTATE']/@value")[0] value2=tree.xpath("//input[@id='__VIEWSTATEGENERATOR']/@value")[0] img_url='https://so.gushiwen.cn/RandCode.ashx' session=requests.session() #发送请求 response_img=session.get(img_url) #注意这里是图片,因此要使用content存储二进制 content_img=response_img.content with open('code.jpg','wb') as fp: fp.write(content_img) code=input() data={ '__VIEWSTATE': value1, '__VIEWSTATEGENERATOR': value2, 'from': 'http://so.gushiwen.cn/user/collect.aspx', 'email': 你的正确账号, 'pwd': 你的正确密码, 'code': code, 'denglu': '登录' } response_post = session.post(url=url,headers=header,data=data) content_post=response_post.text with open('res.html','w',encoding='utf-8') as fp: fp.write(content_post)实际上在企业的开发中我们并不会像上面那样自己人为输入验证码,而是我们会自己实现图像识别或者是外包给第三方进行图像识别







scrapy
什么是scrapy?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,可以应用在包括数据挖掘,信息处理或存储历史数据等一系列程序中
安装scrapy
pip install scrapy
创建爬虫的项目
scrapy startproject 项目的名字注意:项目的名字不能以数字开头且不能包含中文
项目结构具体如下:
创建爬虫文件
要在spiders文件夹中去创建爬虫文件
scrapy genspider 爬虫文件的名字 要爬取的网页
运行爬虫代码
scrapy crawl 爬虫的名字










![[Orin Nx] 如何跑满GPU和CPU,观察温度和散热性能?](https://img-blog.csdnimg.cn/ea96323b6bdb4d3bb2a5bacb6385230b.png)