Sqoop命令执行
常见命令执行参数
通过Sqoop加不同参数可以执行导入导出,通过sqoop help 可以查看常见的命令行
#常见Sqoop参数
[root@qianfeng01 sqoop-1.4.7] sqoop help
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table #导出
help List available commands
import Import a table from a database to HDFS #导入
import-all-tables Import tables from a database to HDFS
import-mainframe Import mainframe datasets to HDFS
list-databases List available databases on a server
list-tables List available tables in a database
version Display version information
复制代码直接执行命令
Sqoop运行的时候不需要启动后台进程,直接执行sqoop命令加参数即可.简单举例如下:
# #通过参数用下面查看数据库
[root@qianfeng01 sqoop-1.4.7] sqoop list-databases --connect jdbc:mysql://localhost:3306 --username root --password 123456;
复制代码注意:可能会出现如下错误
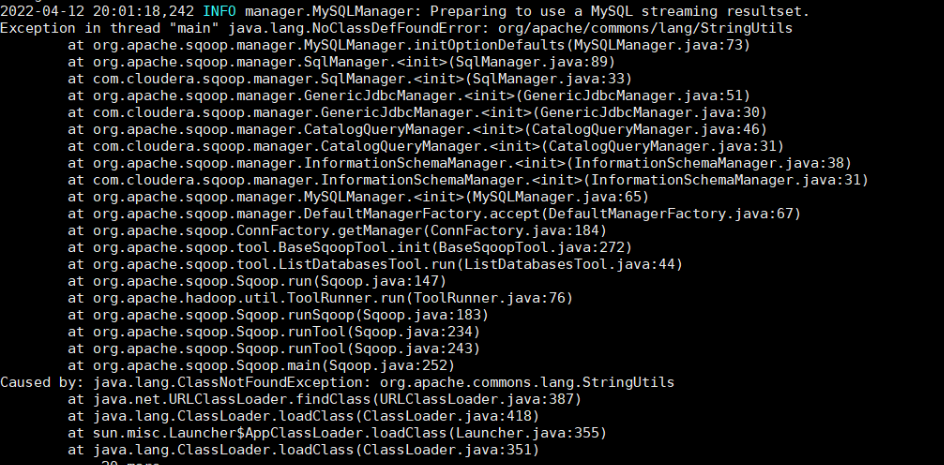
image-20220412174503110
导入==commons-lang-2.6.jar==到lib下即可解决
通过文件传递参数(脚本)
在执行Sqoop命令时,如果每次执行的命令都相似,那么把相同的参数可以抽取出来,放在一个文本文件中,把执行时的参数加入到这个文本文件为参数即可. 这个文本文件可以用--options-file来指定,平时可以用定时任务来执行这个脚本,避免每次手工操作.
把3.2章节中命令中的JDBC连接的参数一般是不变的,可以把它抽取出来放在一个文件中/.../sqoop-1.4.7/config.conf,如下:
list-databases
--connect
jdbc:mysql://localhost:3306
--username
root
--password
123456
复制代码那么上面的执行的命令就可以变为:
[root@qianfeng01 sqoop-1.4.7] bin/sqoop --options-file config.conf
复制代码为了让配置文件config.conf的可读性更强,可以加入空行和注释,不会影响文件内容的读取,如下:
# 指令: 列出mysql中的所有数据库
list-databases
# 指定连接字符串
--connect
jdbc:mysql://localhost:3306
--username
root
--password
123456
复制代码Import 详解
import是从关系数据库导入到Hadoop,下面是一些通用参数介绍:
通用参数
如下:
| Argument | Description |
|---|---|
| ==--connect== | 指定JDBC连接字符串 |
--connection-manager | 指定连接管理类 |
--driver | 指定连接的驱动程序 |
-P | 从控制台读入密码(可以防止密码显示中控制台) |
| ==--password== | 指定访问数据库的密码 |
| ==--username== | 指定访问数据库的用户名 |
连接数据库
Sqoop的设计就是把数据库数据导入HDFS,所以必须指定连接字符串才能访问数据库,这个连接字符串类似于URL,这个连接字符串通过--connect参数指定,它描述了连接的数据库地址和具体的连接数据库,譬如:
[root@qianfeng01 sqoop-1.4.7] sqoop import --connect jdbc:mysql://database.example.com/employees
#指定连接的服务器地址是database.example.com ,要连接的数据库是employees
复制代码上面连接命令只是指定数据库,默认情况下数据库都是需要用户名和参数的,在这里可以用--username 和--password来指定,譬如:
#指定用户名和密码来连接数据库
[root@qianfeng01 sqoop-1.4.7] sqoop import --connect jdbc:mysql://localhost:3306/mysql --username root --password 123456;
复制代码查看数据库
在Sqoop中,可以通过list-databases参数来查看MySql的数据库,这样在导入之前可以得到所有的数据库的名字,具体案例如下:
# 列出所有数据库
[root@qianfeng01 sqoop-1.4.7] sqoop list-databases --connect jdbc:mysql://localhost:3306 --username root --password 123456;
复制代码查看所有表
在得到所有数据库的名字后,也可以查看当前数据库中的所有表,可以使用 list-tables参数来进行查看,查看的时候在url连接中一定要指定数据库的名字.
# 列出数据库中所有表
[root@qianfeng01 sqoop-1.4.7] sqoop list-tables --connect jdbc:mysql://localhost:3306/qfdb --username root --password 123456;
复制代码Import的控制参数
常见import的控制参数有如下几个:
| Argument | Description |
|---|---|
--append | 通过追加的方式导入到HDFS |
--as-avrodatafile | 导入为 Avro Data 文件格式 |
--as-sequencefile | 导入为 SequenceFiles文件格式 |
--as-textfile | 导入为文本格式 (默认值) |
--as-parquetfile | 导入为 Parquet 文件格式 |
--columns | 指定要导入的列 |
--delete-target-dir | 如果目标文件夹存在,则删除 |
--fetch-size | 一次从数据库读取的数量大小 |
-m,--num-mappers | m 用来指定map tasks的数量,用来做并行导入 |
-e,--query | 指定要查询的SQL语句 |
--split-by | 用来指定分片的列 |
--table | 需要导入的表名 |
--target-dir | HDFS 的目标文件夹 |
--where | 用来指定导入数据的where条件 |
-z,--compress | 是否要压缩 |
--compression-codec | 使用Hadoop压缩 (默认是 gzip) |
指定表导入
数据准备
在本地MySql数据库中新建一个qfdb数据库,sql代码在data/qfdb.sql中,如下:
CREATE TABLE emp(
empno INT primary key,
ename VARCHAR(50),
job VARCHAR(50),
mgr INT,
hiredate DATE,
sal DECIMAL(7,2),
comm decimal(7,2),
deptno INT
) ;
INSERT INTO emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp values(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp values(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp values(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp values(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp values(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp values(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp values(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp values(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp values(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp values(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);
INSERT INTO emp values(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp values(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp values(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);
复制代码文末扫码有惊喜
Sqoop的典型导入都是把关系数据库中的表导入到HDFS中,使用--table参数可以指定具体的表导入到HDFS,譬如用 --table emp,默认情况下是全部字段导入.如下:
[root@qianfeng01 sqoop-1.4.7]# bin/sqoop import --connect jdbc:mysql://localhost:3306/qfdb \
--username root --password 123456 \
--table emp \
--target-dir hdfs://qianfeng01:8020/sqoopdata/emp \
--delete-target-dir
复制代码注意:如果使用MySQL8.X版本可能会与到的问题
Caused by: com.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
---------------------------------------------------------------------------
解决:将mysql回收空闲连接的时间变长,mysql默认回收时间是8小时,可以在mysql目录下的/etc/my.cnf中增加下面配置,将时间改为1天。
打开
[root@qianfeng01 sqoop-1.4.7]# vim /etc/my.cnf
# 添加如下两个参数
wait_timeout=31536000
interactive_timeout=31536000
重启服务,即可解决问题
[root@qianfeng01 sqoop-1.4.7]# service mysqld restart
复制代码可以快速使用hdfs的命令查询结果
[root@qianfeng01 sqoop-1.4.7]# hdfs dfs -cat /sqoopdata/emp/par*
复制代码指定列导入
如果想导入某几列,可以使用 --columns,如下:
[root@qianfeng01 sqoop-1.4.7]# bin/sqoop import --connect jdbc:mysql://localhost:3306/qfdb \
--username root --password 123456 \
--table emp \
--columns 'empno,mgr' \
--target-dir hdfs://qianfeng01:8020/sqoopdata/emp \
--delete-target-dir
复制代码可以使用下面hdfs命令快速查看结果
[root@qianfeng01 sqoop-1.4.7]# hdfs dfs -cat /sqoopdata/emp/par*
复制代码指定条件导入
在导入表的时候,也可以通过指定where条件来导入,具体参数使用 --where,譬如要导入员工号大于7800的记录,可以用下面参数:
[root@qianfeng01 sqoop-1.4.7]# bin/sqoop import --connect jdbc:mysql://localhost:3306/qfdb \
--username root --password 123456 \
--table emp \
--columns 'empno,mgr' \
--where 'empno>7800' \
--target-dir hdfs://qianfeng01:8020/sqoopdata/5 \
--delete-target-dir
复制代码用命令查询结果:
[root@qianfeng01 sqoop-1.4.7]# hdfs dfs -cat /sqoopdata/emp/par*
复制代码结果如下:
7839,null
7844,7698
7876,7788
7900,7698
7902,7566
7934,7782
复制代码指定Sql导入
上面的可以通过表,字段,条件进行导入,但是还不够灵活,其实Sqoop还可以通过自定义的sql来进行导入,可以通过--query 参数来进行导入,这样就最大化的用到了Sql的灵活性.如下:
[root@qianfeng01 sqoop-1.4.7]# bin/sqoop import --connect jdbc:mysql://localhost:3306/qfdb \
--username root --password 123456 \
--query 'select empno,mgr,job from emp WHERE empno>7800 and $CONDITIONS' \
--target-dir hdfs://qianfeng01:8020/sqoopdata/emp \
--delete-target-dir \
--split-by empno \
-m 1
复制代码注意:在通过--query来导入数据时,必须要指定--target-dir
如果你想通过并行的方式导入结果,每个map task需要执行sql查询语句的副本,结果会根据Sqoop推测的边界条件分区。query必须包含$CONDITIONS。这样每个Sqoop程序都会被替换为一个独立的条件。同时你必须指定--split-by.分区
-m 1 是指定通过一个Mapper来执行流程
查询执行结果
[root@qianfeng01 sqoop-1.4.7]# hdfs dfs -cat /sqoopdata/emp/par*
复制代码结果如下:
7839,null,PRESIDENT
7844,7698,SALESMAN
7876,7788,CLERK
7900,7698,CLERK
7902,7566,ANALYST
7934,7782,CLERK
复制代码单双引号区别
在导入数据时,默认的字符引号是单引号,这样Sqoop在解析的时候就安装字面量来解析,不会做转移:例如:
--query 'select empno,mgr,job from emp WHERE empno>7800 and $CONDITIONS'
复制代码如果使用了双引号,那么Sqoop在解析的时候会做转义的解析,这时候就必须要加转义字符: 如下:
--query "select empno,mgr,job from emp WHERE empno>7800 and \$CONDITIONS"
复制代码MySql缺主键问题
1如果MySql的表没有主键,将会报错:
19/12/02 10:39:50 ERROR tool.ImportTool: Import
failed: No primary key could be found for table u1. Please specify one with
-- split- by or perform a sequential import with '-m 1
复制代码解决方案:
通过 --split-by 来指定要分片的列
复制代码代码如下:
[root@qianfeng01 sqoop-1.4.7]# bin/sqoop import --connect jdbc:mysql://localhost:3306/qfdb \
--username root --password 123456 \
--query 'select empno,mgr,job from emp WHERE empno>7800 and $CONDITIONS' \
--target-dir hdfs://qianfeng01:8020/sqoopdata/emp \
--delete-target-dir \
--split-by empno \
-m 1
复制代码导入到Hive中
说明
Sqoop的导入工具的主要功能是将数据上传到HDFS中的文件中。如果您有一个与HDFS集群相关联的Hive,Sqoop还可以通过生成和执行CREATETABLE语句来定义Hive中的数据,从而将数据导入到Hive中。将数据导入到Hive中就像在Sqoop命令行中添加--hive-import选项。
如果Hive表已经存在,则可以指定--hive-overwrite选项,以指示必须替换单元中的现有表。在将数据导入HDFS或省略此步骤之后,Sqoop将生成一个Hive脚本,其中包含使用Hive的类型定义列的CREATE表操作,并生成LOAD Data INPATH语句将数据文件移动到Hive的仓库目录中。
在导入Hive之前先要配置Hadoop的Classpath才可以,否则会报类找不到错误,在/etc/profile末尾添加如下配置:
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
#刷新配置
source /etc/profile
复制代码参数说明
具体的参数如下:
| Argument | Description |
|---|---|
--hive-home | 覆盖环境配置中的$HIVE_HOME,默认可以不配置 |
| --hive-import | 指定导入数据到Hive中 |
--hive-overwrite | 覆盖当前已有的数据 |
--create-hive-table | 是否创建hive表,如果已经存在,则会失败 |
--hive-table | 设置要导入的Hive中的表名 |
实际导入案例
具体导入演示代码如下:
提示: 为了看到演示效果,可以先在Hive删除emp表
[root@qianfeng01 sqoop-1.4.7] bin/sqoop import --connect jdbc:mysql://qianfeng01:3306/qfdb \
--username root \
--password 123456 \
--table emp \
--hive-import \
--hive-overwrite \
--hive-table "emp3" \
--hive-database db2 \
-m 1
复制代码在Hive中查看表:
hive> show tables;
#结果如下:
OK
emp
复制代码可以在Hive中查看数据是否导入:
select * from emp;
#结果如下:
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-02-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-02-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-04-02 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-09-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-05-01 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-06-09 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-04-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-09-08 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-05-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-03 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-03 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-01-23 1300.0 NULL 10
更多大数据精彩内容欢迎B站搜索“千锋教育”或者扫码领取全套资料
【千锋教育】大数据开发全套教程,史上最全面的大数据学习视频




![[Orin Nx] 如何跑满GPU和CPU,观察温度和散热性能?](https://img-blog.csdnimg.cn/ea96323b6bdb4d3bb2a5bacb6385230b.png)