前言
最近有很多小伙伴找到我,说想要王者荣耀所有英雄皮肤的照片,但是又不想自己去下载,正好借这个机会给大家讲解一下多线程的爬虫实战
由于线程爬虫会对任何服务器都有一定的影响,本文仅供学习交流使用,切勿拿去做什么不好的事情,要做一个合法的爬虫写手。
📝个人主页→数据挖掘博主ZTLJQ的主页
个人推荐python学习系列:
☄️爬虫JS逆向系列专栏 - 爬虫逆向教学
☄️python系列专栏 - 从零开始学python

那么我们进入第一步,写爬虫的第一步永远都是打开要进行爬取的网站,直接打开王者荣耀的官网即可
打开了官网以后我们就要找到我们需要爬的东西究竟是什么,这个一定要理清楚,我们需要的是英雄皮肤图片,官网的图片如下图:

那么我们可以知道这个页面暂时是没有我们需要的照片,只有英雄的照片,那么我们点击英雄进去链接会发现进去的页面是我们需要的东西。
那么我们就按照经验第一步就是看看是不是可以在URL上找到方法,对比多个URL
pvp.qq.com/web201605/herodetail/544.shtml
pvp.qq.com/web201605/herodetail/545.shtml
我们就可以发现,URL只有后面的数字发生了改变,那么我们就可以在URL上做文章,但是还有一个问题,我们并不知道这个数字是从多少开始从多少结束,而且我们也不清楚数字对应的英雄是谁。
于是我就回到了最开始的页面,打开F12,这个是我凭经验进行寻找的,一般这类图片的网站基本上是动态的,所以一定是需要用到抓包工具的,于是我进行抓包,发现了其中的奥秘如下图:
一般来说这类JSON数据里面是包括了很多网站的参数的,并且看这个英文名字,太明显了好吗,herolist这不是直接把答案都告诉你了吗英雄列表。
点击这个json文件下载下来以后,就会发现奥秘,如下是其中的一个参数
[{
"ename": 105,
"cname": "廉颇",
"title": "正义爆轰",
"new_type": 0,
"hero_type": 3,
"skin_name": "正义爆轰|地狱岩魂",
"moss_id": 3627那么我们在对比一下这个ename是不是一个数字,然后用上面的网址pvp.qq.com/web201605/herodetail/545.shtml
把这个后面的545改成105就会发现对应上了是廉颇这个英雄的皮肤网页,那么就简单了,接下来只需要搞定皮肤页面的爬取就可以了,输入网址后的照片如下:
接下来在这个皮肤的网页找到每个皮肤的地址,进行批量下载就好了,打开F12定位到皮肤的位置就会发现可以直接用XPATH进行爬取。如下图:

这个里面用到的也就是ename中的数据,所以现在所有的思路都已经清晰了,只需要进行代码的编写就好了
首先呢我们需要对json文件进行下载解析
response = requests.get('https://pvp.qq.com/web201605/js/herolist.json')
data = json.loads(response.text)接下来就需要把json文件中的ename参数和cname参数用上,因为最后存文件就用得到文件夹命名还有之前构造URL
num = j['ename']
name = j['cname']
res2 = requests.get("https://pvp.qq.com/web201605/herodetail/{}.shtml".format(num))
res2_decode = res2.content.decode('gbk')
_element = etree.HTML(res2_decode)
element_img = _element.xpath('//div[@class="pic-pf"]/ul/@data-imgname')
name_img = element_img[0].split('|')然后进行一个for循环,还有一个文件的写入
for i in range(0,10):
res1 = requests.get("https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{0}/{0}-bigskin-{1}.jpg".format(num,i+1))
if res1.status_code == 200:
aa = name_img[i].find('&')
bb = name_img[i][:aa]
res_img = res1.content
a = './王者荣耀/' + str(name)
b = './王者荣耀/' + str(name)+'/'+bb+'.jpg'
if not os.path.exists('./王者荣耀/'):
os.mkdir('./王者荣耀/')
if not os.path.exists(a):
os.mkdir(a)
with open(b,"wb") as f:
f.write(res_img)
print(name,bb)最后加上一个多线程,开启线程进行爬取就可以了,主体的代码就像下面一样
def pa(j):
num = j['ename']
name = j['cname']
res2 = requests.get("https://pvp.qq.com/web201605/herodetail/{}.shtml".format(num))
res2_decode = res2.content.decode('gbk')
_element = etree.HTML(res2_decode)
element_img = _element.xpath('//div[@class="pic-pf"]/ul/@data-imgname')
name_img = element_img[0].split('|')
for i in range(0,10):
res1 = requests.get("https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{0}/{0}-bigskin-{1}.jpg".format(num,i+1))
if res1.status_code == 200:
aa = name_img[i].find('&')
bb = name_img[i][:aa]
res_img = res1.content
a = './王者荣耀/' + str(name)
b = './王者荣耀/' + str(name)+'/'+bb+'.jpg'
if not os.path.exists('./王者荣耀/'):
os.mkdir('./王者荣耀/')
if not os.path.exists(a):
os.mkdir(a)
with open(b,"wb") as f:
f.write(res_img)
print(name,bb)
else:
break
def duo():
response = requests.get('https://pvp.qq.com/web201605/js/herolist.json')
data = json.loads(response.text)
for j in data:
t = threading.Thread(target=pa,args=(j,))
t.start()
h.append(t)
for k in h:
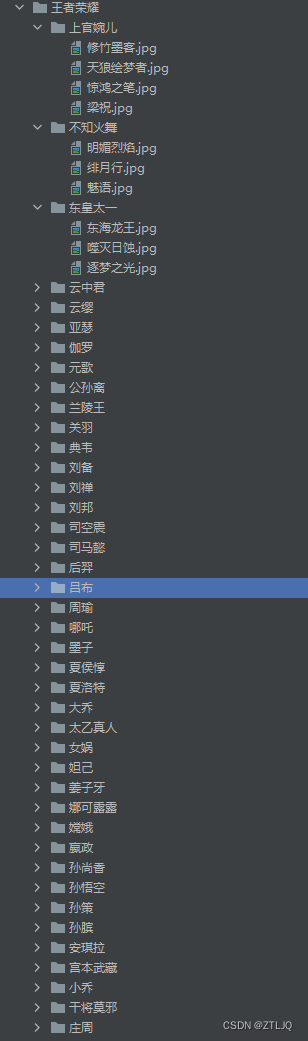
k.join()最后爬出来的效果也是非常好的如下图:



![[补充]托福口语21天——day2 课堂内容](https://img-blog.csdnimg.cn/9e5d18b5b2854a9b91a7d38655da988a.png)