一.数据采集
1.采集逻辑

2.数据schema
招聘信息Schema
{
"岗位名称": "财务会计主管",
"薪资":"1.3-2万",
"地址": "*******",
"经验要求": "5-7年",
"公司名": "********",
"公司类型": "民营",
"人员规模": "少于50人",
"发展领域": "*******",
"工作福利": "****************",
"发布时间":"06-09发布"
}
3.数据爬取
1.下载相关库并导入
#下载相关库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
pip install undetected_chromedriver
#导入相关库
import csv
import random
import time
import re
from time import sleep
from selenium import webdriver
import undetected_chromedriver as uc
from selenium.webdriver import ActionChains
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.by import By2.实例化浏览器对象
# # 实例化一个浏览器对象
driver=uc.Chrome()注:使用selenium时可能会被检测,因此使用undetected_chromedriver 可以防止浏览器特征被识别,并且可以根据浏览器版本自动下载驱动。(建议浏览器更新到最新版本,避免不必要问题)
3.发起请求
#发起请求
driver.get("https://www.51job.com/")
sleep(3)设置休眠时间,避免网络卡顿等问题。
4.键入关键词并搜索
#键入关键词并搜索
driver.find_element(By.XPATH, '//*[@id="kwdselectid"]').click()
driver.find_element(By.XPATH, '//*[@id="kwdselectid"]').clear()
driver.find_element(By.XPATH, '//*[@id="kwdselectid"]').send_keys('会计')
driver.find_element(By.XPATH, '/html/body/div[3]/div/div[1]/div/button').click()
sleep(5)利用send_keys方法传入关键词,并通过xpath定位输入框和确定按钮,完成搜索工作。
5.数据提取
data=driver.page_source
sleep(3)
jobName=re.findall('class="jname at">(.*?)</span>',data,re.S)
jobSalary=re.findall('class="sal">(.*?)</span>',data,re.S)
address=[]
experience=[]
education=[]
for req in re.findall('class="d at">(.*?)</p>',data,re.S):
require=("".join(re.findall('<span data-v-b4bd26a2="">(.*?)</span>',req,re.S))).split('|')
if len(require)==2:
require.append('无学历要求')
address.append(require[0])
experience.append(require[1])
education.append(require[2])
companyName=re.findall('class="cname at">(.*?)</a>',data,re.S)
companyType=[]
companySize=[]
for comp in re.findall('class="dc at">(.*?)</p>',data,re.S):
#中间变量m
m=("".join(comp).split('|'))
if len(m)==2:
companyType.append(m[0].strip())
companySize.append(m[1].strip())
else:
companyType.append(m[0].strip())
companySize.append("无公司规模数据")
companyStatus=re.findall('class="int at">(.*?)</p>',data,re.S)
jobWelf=[]
for tag in re.findall('class="tags">(.*?)</p>',data,re.S):
#中间变量n
n=re.findall('<i data-v-b4bd26a2="">(.*?)</i>',tag,re.S)
if len(n)==0:
jobWelf.append('无工作福利数据')
else:
jobWelf.append(" ".join(n))
updatetime = re.findall('class="time">(.*?)</span>', data, re.S)其中,data为当前页的源代码,后续利用正则对数据进行提取(注:随着时间推移,源代码可能有稍微变动,需注意并修改正则表达式中的pattern)
6.页面跳转
driver.find_element(By.XPATH, '//*[@id="jump_page"]').click()
sleep(random.randint(10, 30) * 0.1)
driver.find_element(By.XPATH, '//*[@id="jump_page"]').clear()
sleep(random.randint(10, 40) * 0.1)
driver.find_element(By.XPATH, '//*[@id="jump_page"]').send_keys(page)
sleep(random.randint(10, 30) * 0.1)
driver.find_element(By.XPATH,
'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[3]/div/div/span[3]').click()
sleep(random.randint(10, 40) * 0.1) 定位页码输入框并输入数字,点击跳转按钮实现跳转。在这个过程,每一步设置随机时间的休眠,防止被检测。
4.数据存储
本例中将数据导入csv文件:
#创建csv文件
with open('无忧-会计.csv', 'a', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['岗位名称','薪资','地址','经验要求','学历要求','公司名','公司类型','人员规模','发展领域','工作福利','发布时间'])
with open('无忧-会计.csv', 'a', newline='') as csvfile:
writer = csv.writer(csvfile)
for i in list(zip(jobName,jobSalary,address,experience,education,companyName,companyType,companySize,companyStatus,jobWelf,updatetime)):
writer.writerow(i)上述是数据采集模块的代码,需要大家充分理解各部分的功能从而完成采集工作。
二.可视化分析
1.数据预览
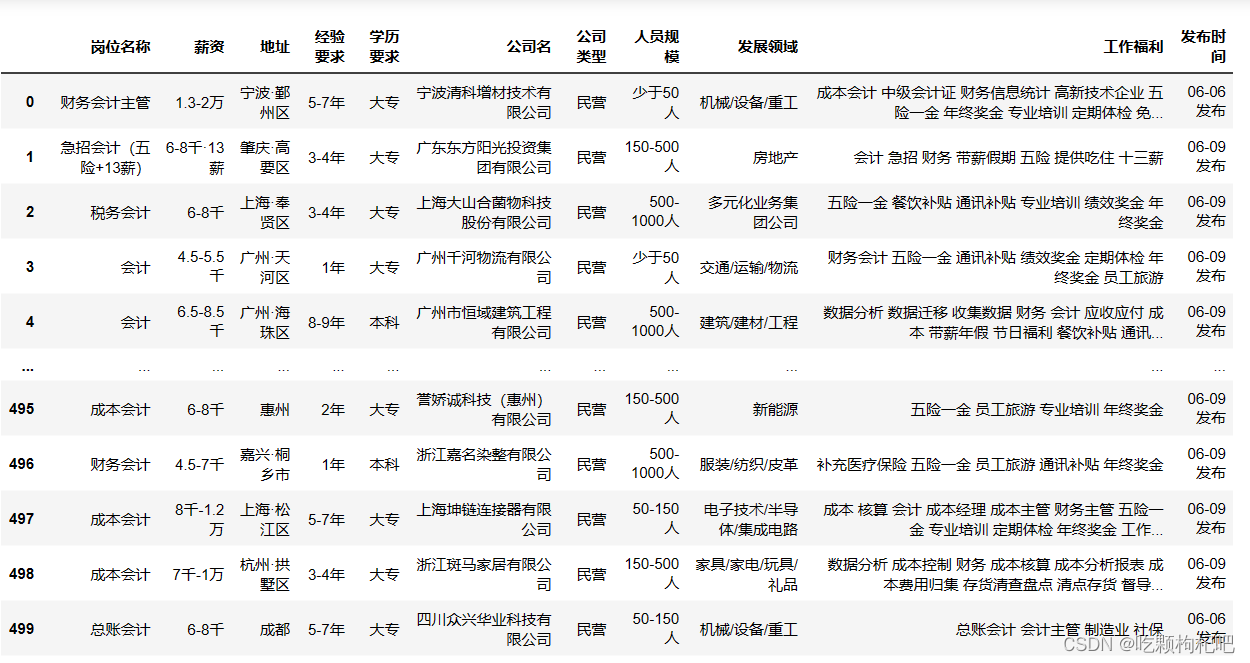
2.导入库及数据
import pandas as pd
import numpy as np
from pyecharts.charts import Pie
from pyecharts.charts import Funnel
from pyecharts.globals import ThemeType
import pyecharts.options as opts
#读取数据
df=pd.read_csv('无忧-会计.csv',encoding='gbk')3.不同类型公司占比饼状图
companyType_valuecount=list(zip(df['公司类型'].value_counts().index,df['公司类型'].value_counts().values.tolist()))
#饼状图
pie=(
Pie()
.add(series_name="",data_pair=companyType_valuecount,radius=["20%","65%"])
.set_global_opts(title_opts=opts.TitleOpts(title="公司类型占比图",subtitle="--饼状图"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
)
pie.render_notebook()
由上图可知:绝大多数公司为民营企业,占比为80.8%,...........(读者自由发挥)
4.各公司的人员规模占比饼状图
companySize_valuecount=list(zip(df['人员规模'].value_counts().index,df['人员规模'].value_counts().values.tolist()))
#饼状图
pie=(
Pie()
.add(series_name="",data_pair=companySize_valuecount,rosetype="area",radius=["15%","80%"])
.set_global_opts(title_opts=opts.TitleOpts(title="人员规模占比图",subtitle="--饼状图",pos_top='bottom',pos_left='right'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}家"))
)
pie.render_notebook()
由上图可知:................................
5.学历需求度分析--漏斗图
education_valuecount=list(zip(df['学历要求'].value_counts().index,df['学历要求'].value_counts().values.tolist()))
#漏斗图
funnel=(
Funnel()
.add(series_name="学历",data_pair=education_valuecount,sort_="ascending")
.set_global_opts(title_opts=opts.TitleOpts(title="学历需求度",subtitle="--漏斗图"),
legend_opts=opts.LegendOpts(pos_left="left",pos_top="middle",orient = 'vertical'))
)
funnel.render_notebook()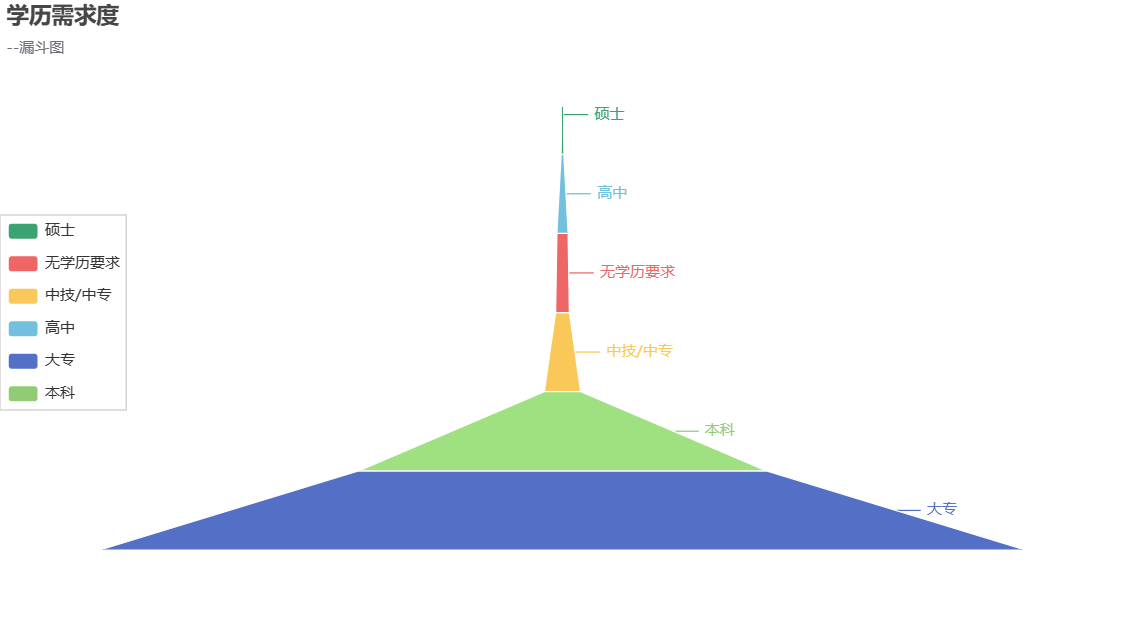
由上图可知:....................






![【玩转Linux操作】详细讲解expr,read,echo,printf,test,[]等命令](https://img-blog.csdnimg.cn/435ac06145bc478ba4e7a7fa70623766.png)