目录
1. 主要思想
2. 训练和推理过程
3. 编码器和解码器的结构
4. 主要用途
5. 相较于 auto-encoder 的优劣
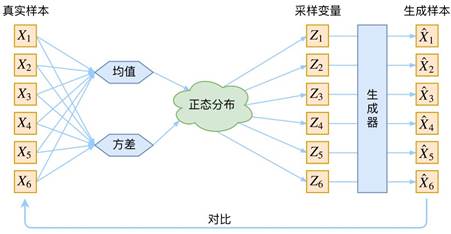
1. 主要思想
变分自编码器(Variational AutoEncoder,简称VAE)是一种生成模型,它通过对数据的隐含表示(latent representation)进行概率建模,能够生成与训练数据类似的新数据。在深度学习中,VAE结合了深度神经网络和贝叶斯推理的概念。
VAE的主要思想是:假设存在一个可以生成我们观察到的数据的隐含变量,并且我们可以通过学习这个隐含变量的分布来生成新的数据。VAE的核心是一个编码器网络和一个解码器网络。
-
编码器(Encoder):编码器部分的作用是学习输入数据(比如图片)到隐含空间的映射。在这个过程中,编码器试图将输入数据压缩为一个潜在空间中的点,这个点的坐标由潜在向量(latent vector)表示。这个潜在向量不是一个确定的点,而是一个分布(通常假设是正态分布),由均值和标准差决定。
-
解码器(Decoder):解码器部分的作用是学习从隐含空间到输入数据的反向映射。解码器从编码器产生的潜在向量中采样,然后试图将这个采样点恢复(或者说解码)为原始的输入数据。
VAE的优化目标包括两部分:一部分是重构损失,即解码的数据与原始输入数据的差异;另一部分是KL散度损失,即编码器得到的潜在变量分布与事先假设的分布(比如标准正态分布)的差异。
2. 训练和推理过程
训练过程:
-
编码:首先,输入数据(如一张图片)被送入编码器网络,编码器会为这些输入数据生成一个潜在向量的分布,通常是高斯分布,有其均值和方差。潜在分布是预先设定的,通常为标准正态分布。
-
采样:接着,在这个分布中采样一个潜在向量。为了使采样过程可微,采样过程通常使用“重参数化技巧”实现,即潜在向量等于其均值加上标准差乘以一组随机噪声。
-
解码:将采样得到的潜在向量送入解码器,解码器将潜在向量解码为重建的输入数据。
-
计算损失函数:损失函数通常由两部分组成,一部分是重建损失,即重建的输入数据与原始输入数据的差异;另一部分是KL散度损失,即编码器生成的潜在向量的分布与预先设定的潜在分布(通常是标准正态分布)之间的差异。
-
反向传播:计算损失函数的梯度,然后用优化算法(如SGD、Adam等)更新模型的参数。
-
重复以上步骤:不断重复以上步骤,直到模型参数收敛,或者达到预设的训练轮数。
推理过程:
-
编码:输入数据被送入训练好的编码器网络,编码器为输入数据生成一个潜在向量的分布。
-
采样:在这个分布中采样一个潜在向量。
-
解码:将采样得到的潜在向量送入解码器,解码器将潜在向量解码为重建的输入数据。
也可以不输入任何数据,而是在潜在空间中随机采样一个潜在向量,然后通过解码器生成新的数据,这是VAE的生成能力。
3. 编码器和解码器的结构
编码器和解码器可以是各种形式的神经网络,其结构可以根据任务的具体需求来选择。通常,如果输入数据是结构化数据,可以使用全连接网络(即密集网络)作为编码器和解码器;如果输入数据是图像,通常会使用卷积神经网络(CNN)作为编码器,使用反卷积神经网络(或称转置卷积网络)作为解码器。
-
编码器:编码器的目的是将输入数据编码成潜在向量的分布(通常是高斯分布),所以编码器的最后一层通常是全连接层,输出潜在向量的均值和(对数)方差。如果输入数据是图像,编码器通常由多层卷积层和全连接层组成,卷积层用于从图像中提取特征,全连接层用于将特征映射到潜在向量的分布(均值向量和(对数)方差向量)。
-
解码器:解码器的目的是将潜在向量解码成重建的输入数据,所以解码器的最后一层通常是全连接层(如果输入数据是结构化数据)或转置卷积层(如果输入数据是图像),输出重建的输入数据。如果输入数据是图像,解码器通常由全连接层和多层转置卷积层组成,全连接层用于将潜在向量映射到图像特征,转置卷积层用于将特征解码为重建的图像。
需要注意的是,编码器和解码器的结构并不一定要对称,可以根据任务的具体需求来选择。同时,随着深度学习的发展,也有许多新的网络结构被用于编码器和解码器,如残差网络、注意力机制等。
4. 主要用途
-
生成新的数据:由于VAE是生成模型,所以一旦训练完成,我们可以通过在潜在空间内随机选择点并通过解码器生成新的数据。例如,如果我们在MNIST数字数据集上训练VAE,我们可以生成新的手写数字。
-
数据压缩:VAE的训练过程本质上是在学习一个压缩和解压的机制,将高维的输入数据压缩到低维的潜在空间,然后从潜在空间解压缩回原始的高维空间。
-
数据去噪:VAE也可以用来对输入数据进行去噪,即从带噪声的输入数据中恢复出原始的无噪声数据。
-
探索数据的隐含结构:通过观察和分析潜在空间的结构,我们可以了解数据的隐含结构或模式。
-
强化学习:在强化学习中,VAE可以用来学习一个环境的模型,从而用于模型预测或模型优化。
-
样式迁移:VAE也可以用于样式迁移,将一种样式的特征应用到另一种样式的内容上。
5. 相较于 auto-encoder 的优劣
优势:
-
潜在空间的连续性和平滑性:在AE中,潜在空间的特性(比如连续性和平滑性)取决于训练数据和网络结构,并没有明确的保证。在VAE中,由于我们显式地将潜在变量的分布约束为特定的分布(如标准正态分布),这使得VAE的潜在空间具有良好的连续性和平滑性。这意味着在VAE的潜在空间中,接近的点会被解码成相似的输出,这对于很多任务(如生成任务、插值任务)都非常有利。
-
生成新样本:由于VAE的潜在空间的连续性和平滑性,我们可以通过在潜在空间中进行采样,然后通过解码器生成新的数据样本,这在AE中往往无法做到。
-
更丰富的表示学习:VAE通过引入随机性,可以学习到数据的更丰富的表示。在VAE中,潜在向量不仅仅是一个确定的点,而是一个分布,这使得VAE可以更好地模拟数据的复杂性和不确定性。
-
解释性:因为VAE对潜在空间有明确的概率模型,我们可以更好地理解和解释潜在变量与数据的关系。
劣势:
- AE的训练通常需要更多的计算资源,因为需要进行随机梯度变分推理。
- VAE的重构效果通常不如AE,特别是当数据复杂度高或者噪声大的时候。
参考材料:
VAE变分自动编码_vae 李宏毅_Dongxue_NLP的博客-CSDN博客
GPT-4 from OpenAI


![[conda]tf_agents和tensorflow-gpu安装傻瓜式教程](https://img-blog.csdnimg.cn/81cfb8a4deb3411daa838aeae61d517a.png)








![[RocketMQ] Consumer消费者启动主要流程源码 (六)](https://img-blog.csdnimg.cn/70d00419aa744d6a8f7bfe8c684a47d7.png)
