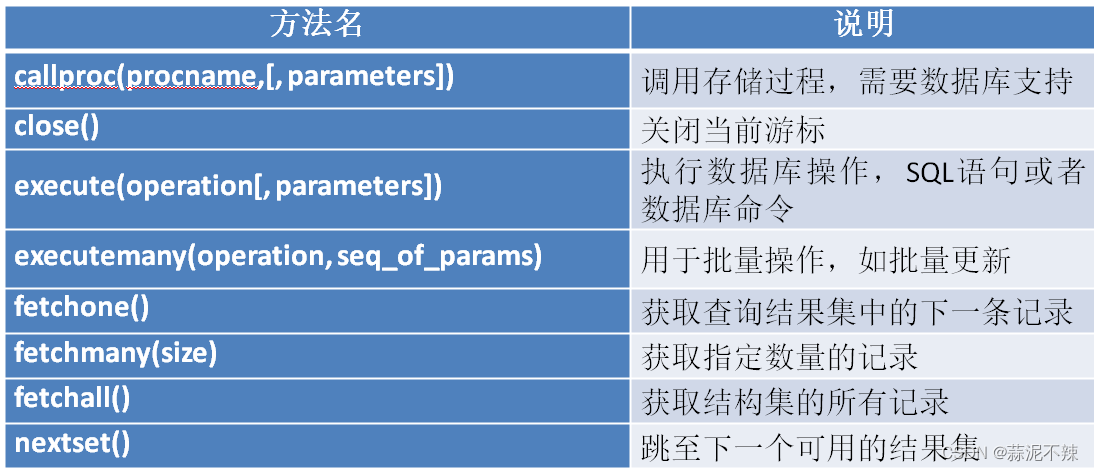
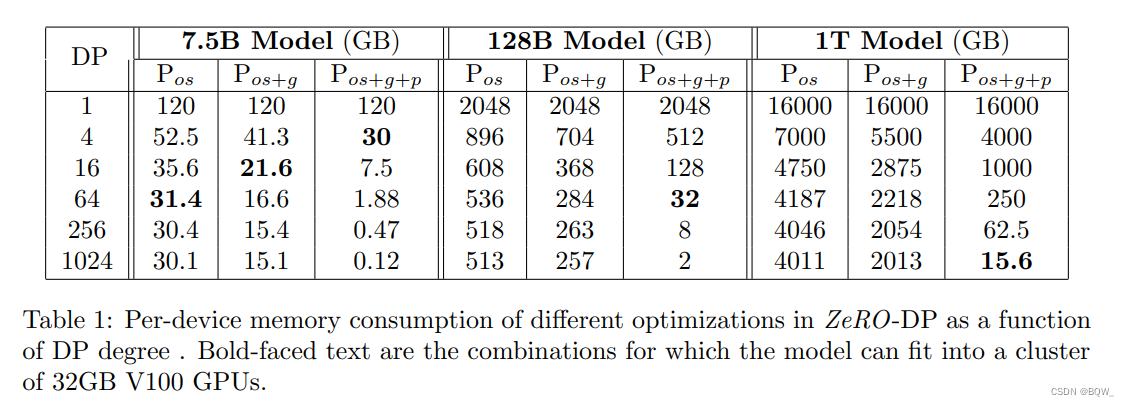
模型的构建: tf.keras.Model 和 tf.keras.layers
模型的损失函数: tf.keras.losses
模型的优化器: tf.keras.optimizer
模型的评估: tf.keras.metrics
模型(Model)与层(Layer)
Keras 有两个重要的概念: 模型(Model) 和 层(Layer) 。层将各种计算流程和变量进行了封装(例如基本的全连接层,CNN 的卷积层、池化层等),而模型则将各种层进行组织和连接,并封装成一个整体,描述了如何将输入数据通过各种层以及运算而得到输出
import tensorflow as tf
X = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
y = tf.constant([[10.0], [20.0]])
class Linear(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense = tf.keras.layers.Dense(
units=1,
activation=None,
kernel_initializer=tf.zeros_initializer(),
bias_initializer=tf.zeros_initializer()
)
def call(self, input):
output = self.dense(input)
return output
model = Linear()
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
for i in range(100):
with tf.GradientTape() as tape:
y_pred = model(X) # 调用模型 y_pred = model(X) 而不是显式写出 y_pred = a * X + b
loss = tf.reduce_mean(tf.square(y_pred - y))
grads = tape.gradient(loss, model.variables) # 使用 model.variables 这一属性直接获得模型中的所有变量
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
print(model.variables)多层感知机(MLP)
-
使用
tf.keras.datasets获得数据集并预处理 -
使用
tf.keras.Model和tf.keras.layers构建模型 -
构建模型训练流程,使用
tf.keras.losses计算损失函数,并使用tf.keras.optimizer优化模型 -
构建模型评估流程,使用
tf.keras.metrics计算评估指标
Tensorflow 图像数据格式
在 TensorFlow 中,图像数据集的一种典型表示是 [图像数目,长,宽,色彩通道数] 的四维张量。
import tensorflow as tf
import numpy as np
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = mnist.load_data()
# MNIST中的图像默认为uint8(0-255的数字)。以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1) # [60000, 28, 28, 1]
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1) # [10000, 28, 28, 1]
self.train_label = self.train_label.astype(np.int32) # [60000]
self.test_label = self.test_label.astype(np.int32) # [10000]
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
# 从数据集中随机取出batch_size个元素并返回
index = np.random.randint(0, self.num_train_data, batch_size)
return self.train_data[index, :], self.train_label[index]
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten() # Flatten层将除第一维(batch_size)以外的维度展平
self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs): # [batch_size, 28, 28, 1]
x = self.flatten(inputs) # [batch_size, 784]
x = self.dense1(x) # [batch_size, 100]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
num_epochs = 5
batch_size = 50
learning_rate = 0.001
model = MLP()
data_loader = MNISTLoader()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
"""
在 tf.keras 中,有两个交叉熵相关的损失函数 tf.keras.losses.categorical_crossentropy 和 tf.keras.losses.sparse_categorical_crossentropy 。其中 sparse 的含义是,真实的标签值 y_true 可以直接传入 int 类型的标签类别。具体而言:
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
与
loss = tf.keras.losses.categorical_crossentropy(
y_true=tf.one_hot(y, depth=tf.shape(y_pred)[-1]),
y_pred=y_pred
)
"""
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
for epoch in range(num_epochs):
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
num_batches = int(data_loader.num_test_data // batch_size)
for batch_index in range(num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict(data_loader.test_data[start_index: end_index])
sparse_categorical_accuracy.update_state(y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
卷积神经网络(CNN)
import tensorflow as tf
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs) # [batch_size, 28, 28, 32]
x = self.pool1(x) # [batch_size, 14, 14, 32]
x = self.conv2(x) # [batch_size, 14, 14, 64]
x = self.pool2(x) # [batch_size, 7, 7, 64]
x = self.flatten(x) # [batch_size, 7 * 7 * 64]
x = self.dense1(x) # [batch_size, 1024]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
input=tf.random.normal((1,28,28,1))
model=CNN()
output=model(input)
model.summary()
print(output.shape)import tensorflow as tf
import tensorflow_datasets as tfds
num_epoch = 5
batch_size = 50
learning_rate = 0.001
dataset = tfds.load("tf_flowers", split=tfds.Split.TRAIN, as_supervised=True)
dataset = dataset.map(lambda img, label: (tf.image.resize(img, (224, 224)) / 255.0, label)).shuffle(1024).batch(batch_size)
model = tf.keras.applications.MobileNetV2(weights=None, classes=5)
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
for e in range(num_epoch):
for images, labels in dataset:
with tf.GradientTape() as tape:
labels_pred = model(images, training=True)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=labels, y_pred=labels_pred)
loss = tf.reduce_mean(loss)
print("loss %f" % loss.numpy())
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.trainable_variables))
print(labels_pred)tensorflow实现卷积操作
import numpy as np
import tensorflow as tf
# TensorFlow 的图像表示为 [图像数目,长,宽,色彩通道数] 的四维张量
# 这里我们的输入图像 image 的张量形状为 [1, 7, 7, 1]
image = np.array([[
[0, 0, 0, 0, 0, 0, 0],
[0, 1, 0, 1, 2, 1, 0],
[0, 0, 2, 2, 0, 1, 0],
[0, 1, 1, 0, 2, 1, 0],
[0, 0, 2, 1, 1, 0, 0],
[0, 2, 1, 1, 2, 0, 0],
[0, 0, 0, 0, 0, 0, 0]
]], dtype=np.float32)
image = np.expand_dims(image, axis=-1)
W = np.array([[
[ 0, 0, -1],
[ 0, 1, 0 ],
[-2, 0, 2 ]
]], dtype=np.float32)
b = np.array([1], dtype=np.float32)
"""
在 tf.keras.layers.Conv2D 中,当我们将 padding 参数设为 same 时,会将周围缺少的部分使用 0 补齐,使得输出的矩阵大小和输入一致。
"""
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(
filters=1, # 卷积层神经元(卷积核)数目
kernel_size=[3, 3], # 感受野大小
kernel_initializer=tf.constant_initializer(W),
bias_initializer=tf.constant_initializer(b)
)]
)
output = model(image)
print(output)
print(tf.squeeze(output))循环神经网络(RNN)
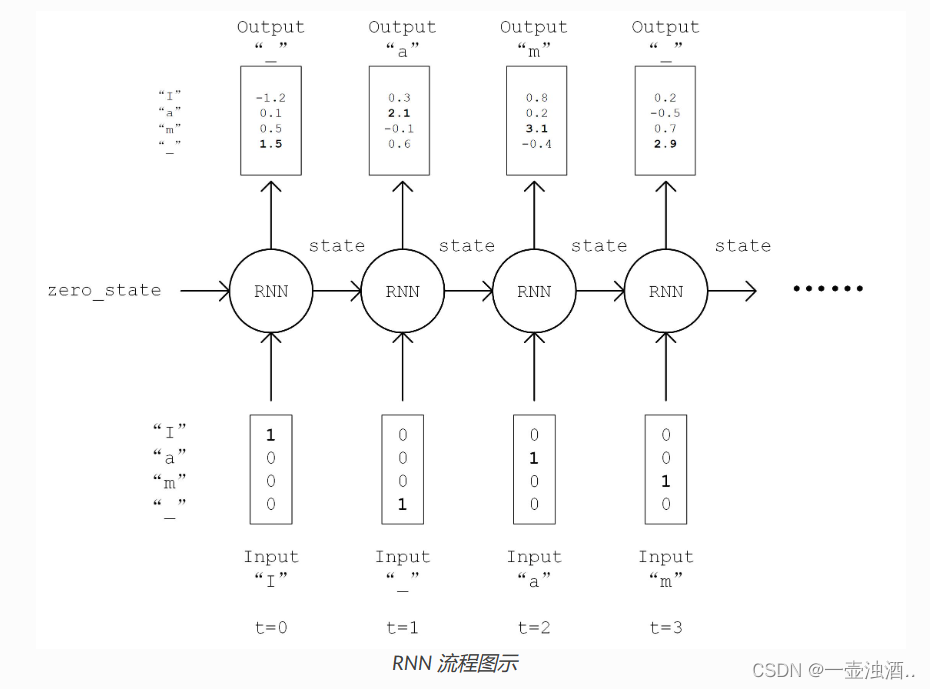
import numpy as np
import tensorflow as tf
class DataLoader():
def __init__(self):
path = tf.keras.utils.get_file('nietzsche.txt',
origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
with open(path, encoding='utf-8') as f:
self.raw_text = f.read().lower()
self.chars = sorted(list(set(self.raw_text)))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
self.text = [self.char_indices[c] for c in self.raw_text]
def get_batch(self, seq_length, batch_size):
seq = []
next_char = []
for i in range(batch_size):
index = np.random.randint(0, len(self.text) - seq_length)
seq.append(self.text[index:index+seq_length])
next_char.append(self.text[index+seq_length])
return np.array(seq), np.array(next_char) # [batch_size, seq_length], [num_batch]
dataset=DataLoader()
hh=dataset.get_batch(100,2)
print(hh)
hhh=[]
for i in hh[0][0]:
c=dataset.indices_char[i]
hhh.append(c)
print(c)
print(hhh)
class RNN(tf.keras.Model):
def __init__(self, num_chars, batch_size, seq_length):
super().__init__()
self.num_chars = num_chars
self.seq_length = seq_length
self.batch_size = batch_size
self.cell = tf.keras.layers.LSTMCell(units=256)
self.dense = tf.keras.layers.Dense(units=self.num_chars)
def call(self, inputs, from_logits=False):
inputs = tf.one_hot(inputs, depth=self.num_chars) # [batch_size, seq_length, num_chars]
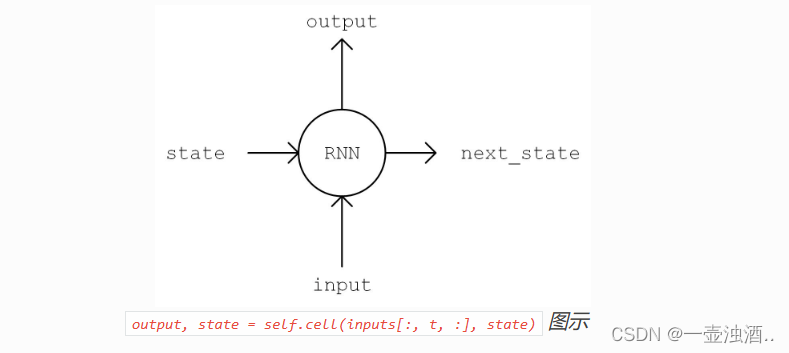
state = self.cell.get_initial_state(batch_size=self.batch_size, dtype=tf.float32) # 获得 RNN 的初始状态
for t in range(self.seq_length):
output, state = self.cell(inputs[:, t, :], state) # 通过当前输入和前一时刻的状态,得到输出和当前时刻的状态
logits = self.dense(output)
if from_logits: # from_logits 参数控制输出是否通过 softmax 函数进行归一化
return logits
else:
return tf.nn.softmax(logits)
def predict(self, inputs, temperature=1.):
batch_size, _ = tf.shape(inputs)
logits = self(inputs, from_logits=True) # 调用训练好的RNN模型,预测下一个字符的概率分布
prob = tf.nn.softmax(logits / temperature).numpy() # 使用带 temperature 参数的 softmax 函数获得归一化的概率分布值
return np.array([np.random.choice(self.num_chars, p=prob[i, :]) # 使用 np.random.choice 函数,
for i in range(batch_size.numpy())]) # 在预测的概率分布 prob 上进行随机取样
num_batches = 1000
seq_length = 40
batch_size = 50
learning_rate = 1e-3
num_epoch=1
data_loader = DataLoader()
model = RNN(num_chars=len(data_loader.chars), batch_size=batch_size, seq_length=seq_length)
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
for epoch in range(num_epoch):
for batch_index in range(num_batches):
X, y = data_loader.get_batch(seq_length, batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
X_, _ = data_loader.get_batch(seq_length, 1)
for diversity in [0.2, 0.5, 1.0, 1.2]: # 丰富度(即temperature)分别设置为从小到大的 4 个值
X = X_
print("diversity %f:" % diversity)
for t in range(400):
y_pred = model.predict(X, diversity) # 预测下一个字符的编号
print(data_loader.indices_char[y_pred[0]], end='', flush=True) # 输出预测的字符
X = np.concatenate([X[:, 1:], np.expand_dims(y_pred, axis=1)], axis=-1) # 将预测的字符接在输入 X 的末尾,并截断 X 的第一个字符,以保证 X 的长度不变
print("\n")
Pipline
"""
tf.keras.Sequential模型可以让你通过堆叠tf.keras.layers的方式定义Kears模型
用Keras模型的compile和fit方法来分别构建训练循环并执行
"""
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
(train_x, train_y), (test_x, test_y) = fashion_mnist.load_data()
# Scale input in [-1, 1] range
train_x = tf.expand_dims(train_x, -1)
train_x = (tf.image.convert_image_dtype(train_x, tf.float32) - 0.5) * 2
train_y = tf.expand_dims(train_y, -1)
test_x = test_x / 255.0 * 2 - 1
test_x = (tf.image.convert_image_dtype(test_x, tf.float32) - 0.5) * 2
test_y = tf.expand_dims(test_y, -1)
model=tf.keras.Sequential(
[
tf.keras.layers.Conv2D(
32, (5, 5), activation=tf.nn.relu, input_shape=(28, 28, 1)
),
tf.keras.layers.MaxPool2D((2, 2), (2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation=tf.nn.relu),
tf.keras.layers.MaxPool2D((2, 2), (2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10),
]
)
model.summary()
model.compile(
optimizer=tf.keras.optimizers.Adam(1e-5),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.fit(train_x,train_y,epochs=10)
model.evaluate(test_x,test_y)使用 Keras Model 的 compile 、 fit 和 evaluate 方法训练和评估模型
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)tf.keras.Model.compile 接受 3 个重要的参数:
oplimizer:优化器,可从tf.keras.optimizers中选择;
loss:损失函数,可从tf.keras.losses中选择;
metrics:评估指标,可从tf.keras.metrics中选择。
model.fit(data_loader.train_data, data_loader.train_label, epochs=num_epochs, batch_size=batch_size)tf.keras.Model.fit 接受 5 个重要的参数:
x:训练数据;
y:目标数据(数据标签);
epochs:将训练数据迭代多少遍;
batch_size:批次的大小;
validation_data:验证数据,可用于在训练过程中监控模型的性能。
最后,使用 tf.keras.Model.evaluate 评估训练效果,提供测试数据及标签
自定义层、损失函数和评估指标
自定义层
自定义层需要继承 tf.keras.layers.Layer 类,并重写 __init__ 、 build 和 call 三个方法
class MyLayer(tf.keras.layers.Layer):
def __init__(self):
super().__init__()
# 初始化代码
def build(self, input_shape): # input_shape 是一个 TensorShape 类型对象,提供输入的形状
# 在第一次使用该层的时候调用该部分代码,在这里创建变量可以使得变量的形状自适应输入的形状
# 而不需要使用者额外指定变量形状。
# 如果已经可以完全确定变量的形状,也可以在__init__部分创建变量
self.variable_0 = self.add_weight(...)
self.variable_1 = self.add_weight(...)
def call(self, inputs):
# 模型调用的代码(处理输入并返回输出)
return outputclass LinearLayer(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
self.units = units
def build(self, input_shape): # 这里 input_shape 是第一次运行call()时参数inputs的形状
self.w = self.add_weight(name='w',
shape=[input_shape[-1], self.units], initializer=tf.zeros_initializer())
self.b = self.add_weight(name='b',
shape=[self.units], initializer=tf.zeros_initializer())
def call(self, inputs):
y_pred = tf.matmul(inputs, self.w) + self.b
return y_pred自定义损失函数和评估指标
自定义损失函数需要继承 tf.keras.losses.Loss 类,重写 call 方法即可,输入真实值 y_true 和模型预测值 y_pred ,输出模型预测值和真实值之间通过自定义的损失函数计算出的损失值。下面的示例为均方差损失函数:
class MeanSquaredError(tf.keras.losses.Loss):
def call(self, y_true, y_pred):
return tf.reduce_mean(tf.square(y_pred - y_true))自定义评估指标需要继承 tf.keras.metrics.Metric 类,并重写 __init__ 、 update_state 和 result 三个方法
class SparseCategoricalAccuracy(tf.keras.metrics.Metric):
def __init__(self):
super().__init__()
self.total = self.add_weight(name='total', dtype=tf.int32, initializer=tf.zeros_initializer())
self.count = self.add_weight(name='count', dtype=tf.int32, initializer=tf.zeros_initializer())
def update_state(self, y_true, y_pred, sample_weight=None):
values = tf.cast(tf.equal(y_true, tf.argmax(y_pred, axis=-1, output_type=tf.int32)), tf.int32)
self.total.assign_add(tf.shape(y_true)[0])
self.count.assign_add(tf.reduce_sum(values))
def result(self):
return self.count / self.total
参考文献
TensorFlow 模型建立与训练 — 简单粗暴 TensorFlow 2 0.4 beta 文档 (tf.wiki)