索引基础介绍
索引是什么
MySQL官方:索引(INDEX)是帮助MySQL高效获取数据的数据结构。
面试官问,回:索引是排好序的快速查找数据结构
索引的目的在于提高查询效率,可以类比字典的目录。如果要查mysql这个这个单词,我们肯定要先定位到m字母,然后从上往下找y字母,再找剩下的sql。如果没有索引,那么可能需要a---z,这样全字典扫描,如果我想找Java开头的单词呢?如果我想找Oracle开头的单词呢???
重点:索引会影响到MySQL查找(WHERE的查询条件)和排序(ORDER BY)两大功能!
除了数据本身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。下图是一种索引方式,
为了加快Co12的查找,可以维护一个右边所示的二又查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在一定的复杂度内获取到相应数据,从而快速的检索出符合条件的记录,找91这条数据,只需要比较三次即可找到。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GE8CGamd-1687609486394)(assets/1687609375117-10.png)]](https://img-blog.csdnimg.cn/085d815a711c42378b1205a70838fa0d.png#pic_center)
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
数据表使用逻辑删除有两个好处:
- 没有物理删除的数据后面可以给数据部门分析使用
- 真正删除数据需要重整索引
我们平时所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。当然,除了B+树这种数据结构的索引之外,还有哈希索引(Hash Index)等。
索引优缺点
优势:
- 查找:类似大学图书馆的书目索引,提高数据检索的效率,降低数据库的IO成本。
- 排序:通过索引対数据进行排序,降低数据排序的成本,降低了CPU的消耗。
劣势:
- 实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的。
- 虽然索引大大提高了查询速度,但是同时会降低表的更新速度,例如对表频繁的进行
INSERT、UPDATE和DELETE。因为更新表的时候,MySQL不仅要保存数据,还要更新一下索引文件。 - 索引只是提高效率的一个因素,如果MySQL有大数据量的表,就需要花时间研究建立最优秀的索引(如根据客户的组合查询习惯来不断调整索引)。
建议:一张表建的索引最好不要超过5个!
索引分类
- 单值索引:一个索引只包含单个列,一个表可以有多个单列索引。
- 唯一索引:索引列的值必须唯一(如用户的身份证号),但是允许有多个空值。
- 复合索引:一个索引包含多个字段。
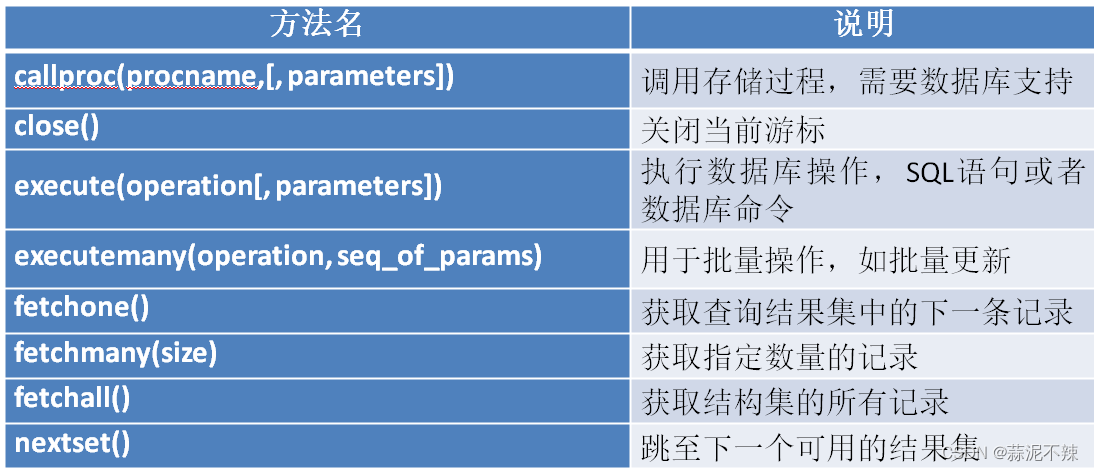
索引常用命令
-- 创建索引 [UNIQUE] 可以省略,如不省略,创建的是唯一索引
-- 如果columnName(length)只写一个字段就是单值索引,写多个字段就是复合索引
CREATE [UNIQUE] INDEX indexName ON tabName(columnName(length));
-- 删除某张表的某个索引
DROP INDEX [indexName] ON tabName;
-- 查看索引(加上\G就可以以列的形式查看了 不加\G就是以表的形式查看)
SHOW INDEX FROM tabName \G;
表形式:
mysql> show index from article;
+---------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| article | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | | YES | NULL |
| article | 1 | idx_article_cv | 1 | category_id | A | 2 | NULL | NULL | | BTREE | | | YES | NULL |
| article | 1 | idx_article_cv | 2 | views | A | 3 | NULL | NULL | | BTREE | | | YES | NULL |
+---------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
3 rows in set (0.01 sec)
列形式:
mysql> show index from article\G;
*************************** 1. row ***************************
Table: article
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 3
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: article
Non_unique: 1
Key_name: idx_article_cv
Seq_in_index: 1
Column_name: category_id
Collation: A
Cardinality: 2
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 3. row ***************************
Table: article
Non_unique: 1
Key_name: idx_article_cv
Seq_in_index: 2
Column_name: views
Collation: A
Cardinality: 3
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
3 rows in set (0.00 sec)
使用ALTER命令来为数据表添加索引
-- 该语句添加一个主键,这意味着索引值必须是唯一的,并且不能为NULL -
ALTER TABLE tabName ADD PRIMARY KEY(column_list);
-- 该语句创建索引的键值必须是唯一的(除了NULL之外,NULL可能会出现多次) -
ALTER TABLE tabName ADD UNIQUE indexName(column_list);
-- 该语句创建普通索引,索引值可以出现多次
ALTER TABLE tabName ADD INDEX indexName(column_list);
-- 该语句指定了索引为FULLTEXT,用于全文检索
ALTER TABLE tabName ADD FULLTEXT indexName(column_list);
Mysql索引结构
索引数据结构:
BTree索引。Hash索引。Full-text全文索引。R-Tree索引。
BTree索引检索原理:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uElmKyG4-1687609486395)(assets/1687609375086-9.png)]](https://img-blog.csdnimg.cn/6ddb42af1fc04df9838dccdaca1a9870.png#pic_center)
【查找过程举例】
如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。
真实的情况是,
3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次10,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高.
哪些情况需要建索引
- 主键自动建立主键索引(唯一 + 非空)
- 频繁作为查询条件的字段应该创建索引(如银行系统的银行账号、电信系统的手机号)
- 查询中与其他表关联的字段,外键关系建立索引(如员工表的部门id)
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段(group by也和索引有关)
- 使用单键还是组合索引,高并发场景下倾向于创建组合索引
那些情况不要建索引
- 表记录太少
- 经常增删改的表(更新表的时候,不但要保存数据,还要更新索引文件)
- 频繁更新的字段不适合创建索引
- 值包含大量重复值的字段不推荐创建索引(如性别只有两个值,不是男就是女。假如一个表有10万行记录,有一个字段A只有true和false两种值,并且每个值的分布概率大约为50%,那么对A字段建索引一般不会提高数据库的查询速度。索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99。一个索引的选择性越接近于1,这个索引的效率就越高)
- Where条件里用不到的字段不创建索引