目录
1、从csv和txt文件中读取数据
pandas中可使用read_csv读取csv或txt文件中的数据
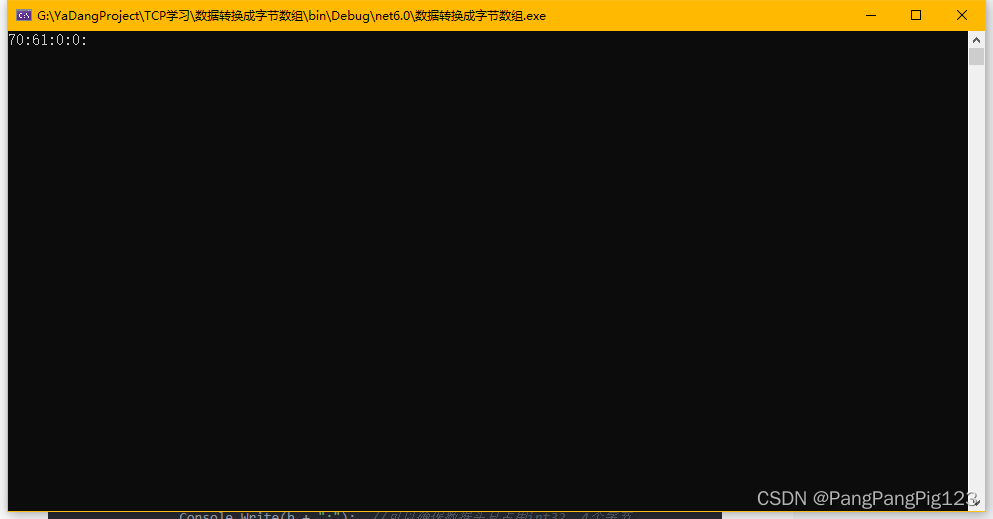
使用read_csv()函数读取phones.csv文件中的数据,并指定编码格式为gbk
使用head()方法指定获取phones.csv文件中前3行的数据
使用read_csv() 函数读取 itheima_books.txt文件中的数据,并指定编码格式为utf8
2、从Excel文件中读取数据
pandas中可使用read_excel读取Excel文件中的数据
使用read_excel() 函数读取Athletes_info.xlsx 文件,显示前5行
3、从JSON文件读取数据
pandas中可使用read_json()读取json文件中的数据
使用read_json() 函数读取 Animal_species.json 文件中的数据,并指定编码格式为utf8
4、从HTML文件读取数据
5、从数据库获取数据
6、从word文件读取数据 用python-dox库
python—docx库的基本使用
使用python-docx库读取'集合介绍.docx'文件中的段落内容
编辑
使用python-docx库读取'集合介绍.docx'文件中的表格内容
7、从pdf文件读取数据 用pdfplumber库
使用pdfplumber库读取"集合简介.pdf"文件中所有的文本数据
只提取pdf文件中的表格数据
# 可以通过page类对象中的extract_tables()方法实现
1、从csv和txt文件中读取数据
pandas中可使用read_csv读取csv或txt文件中的数据
read_csv(filepath_or_buffer,sep=',',delimiter=None,header='infer',
names=None,index_col=None,usecols=None,squeeze=False,prefix=None,
mangle+dupe_cols=True,encoding=None...)
filepath_or_buffer: 文件路径
sep: 分隔符,默认为“,”。
header : 表示将指定文件中的哪一行数据作为 DataFrame 类对象的列索引,默认为0。即将第一行数据作为列索引。
names: 表示 DataFrame 类对象的列索引列表,若文件中没有列标题,则 names 参数的值为 None。
encoding:表示指定的编码格式。
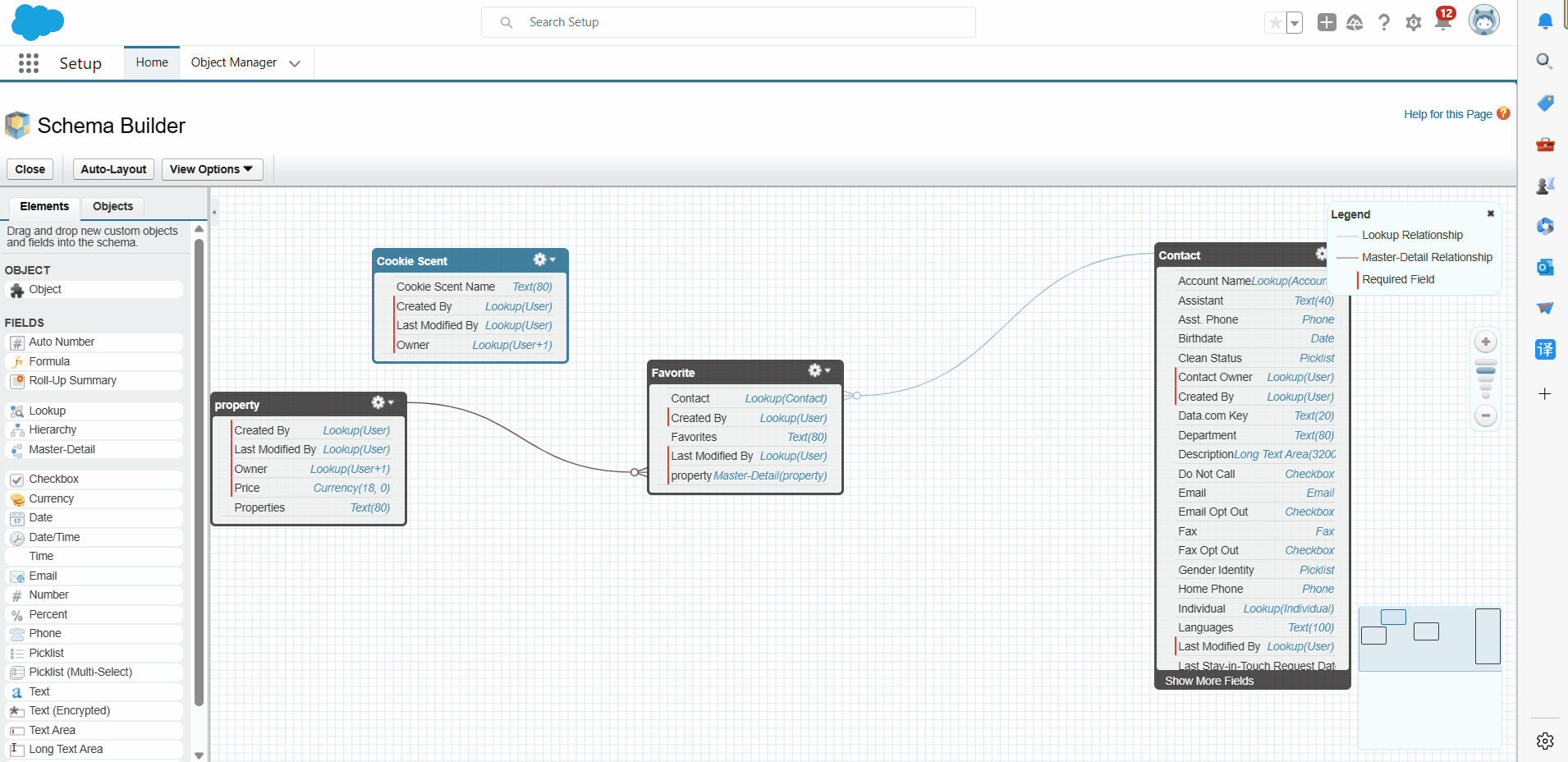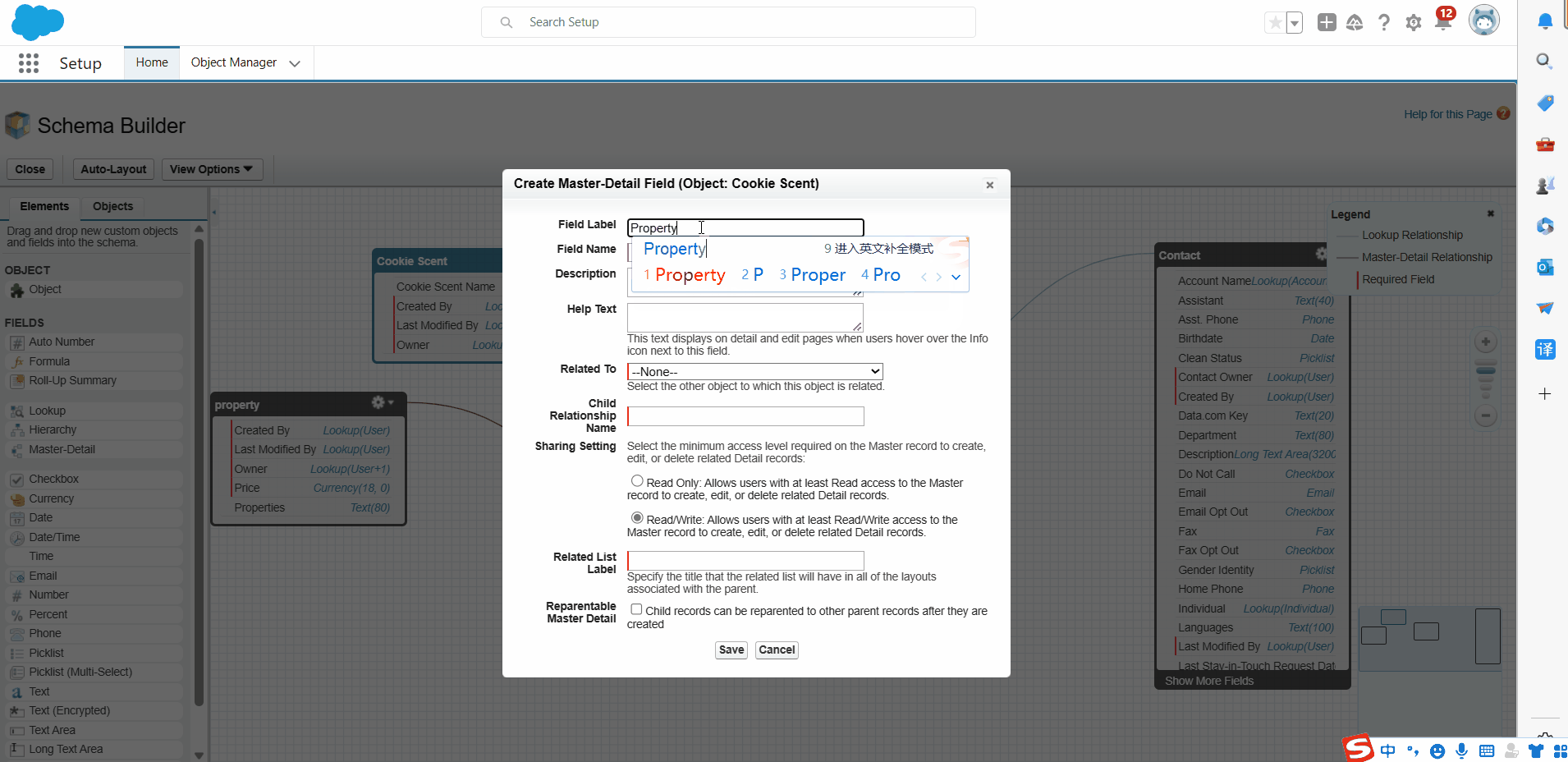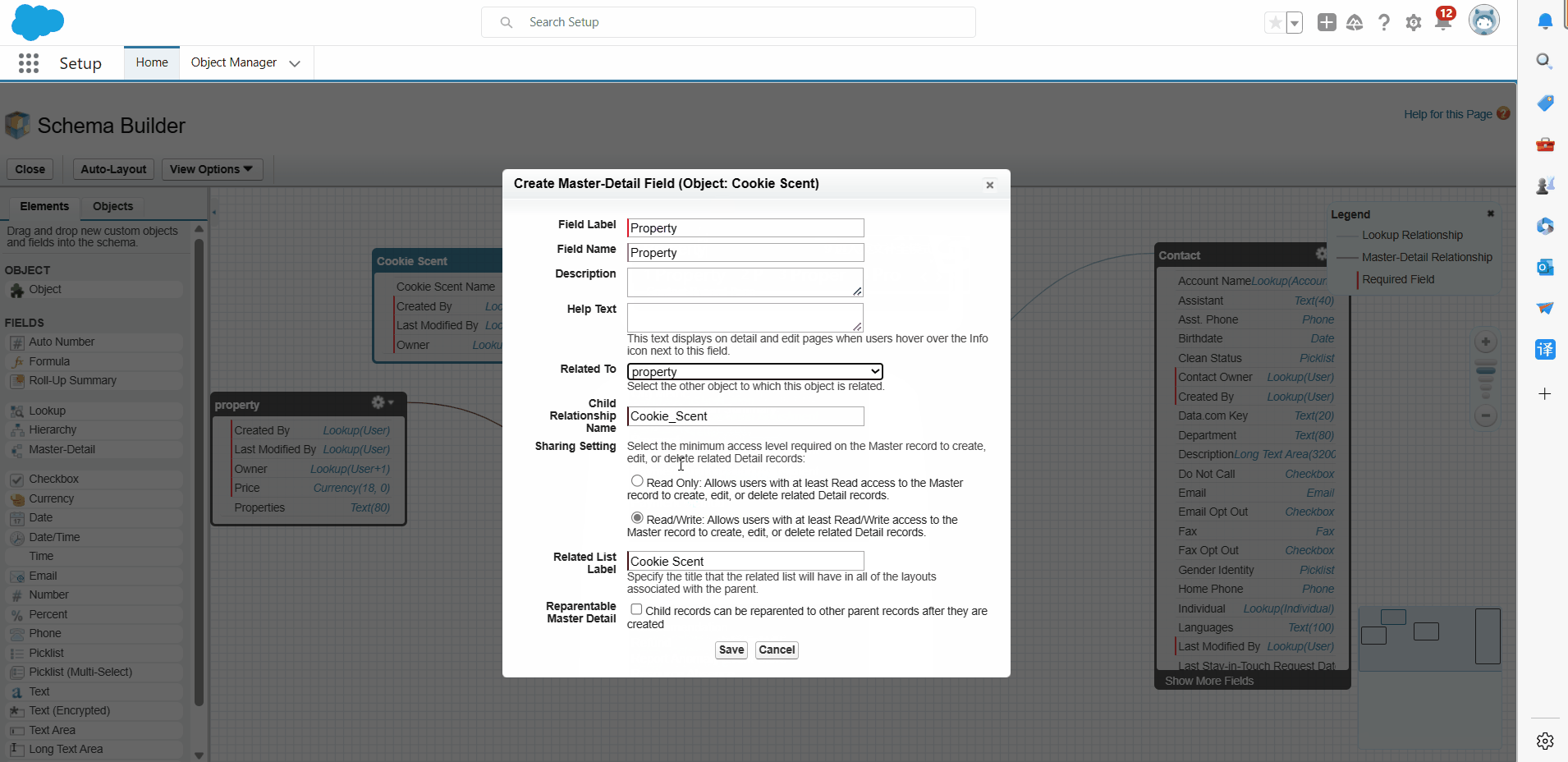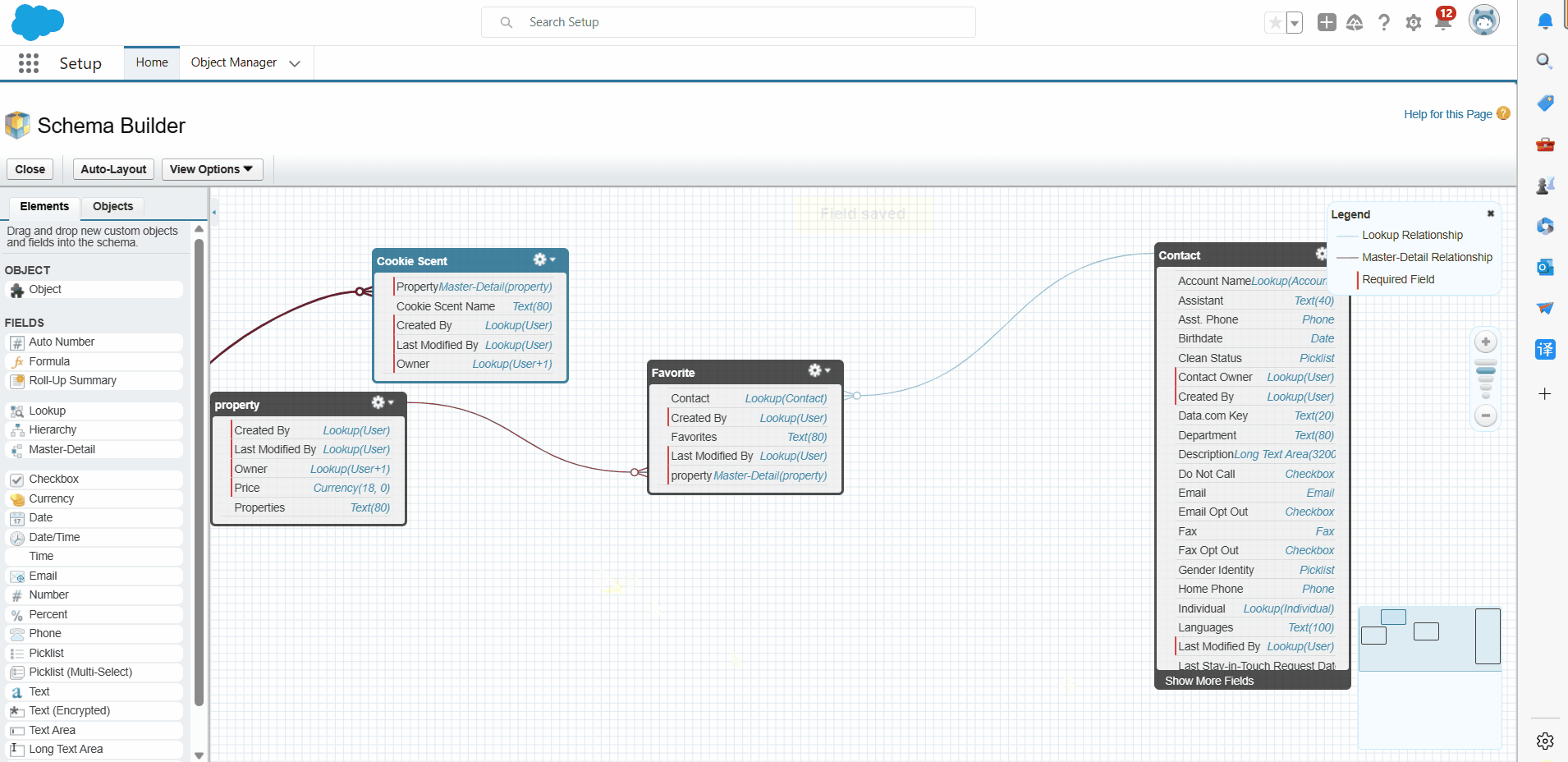
使用read_csv()函数读取phones.csv文件中的数据,并指定编码格式为gbk
import pandas as pd
import numpy as np
evaluation_data = pd.read_csv('C:/py数据/第4章数据获取/phones.csv', encoding='gbk')
print(evaluation_data)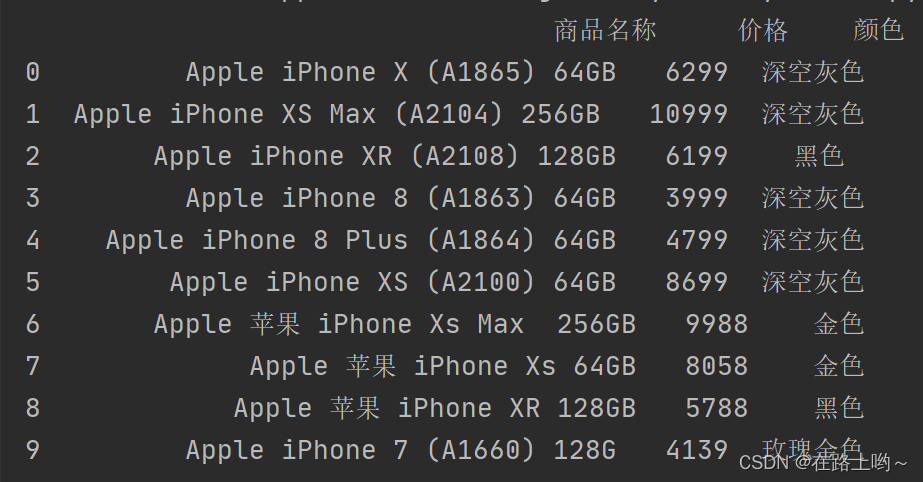
使用head()方法指定获取phones.csv文件中前3行的数据
print('\n前3行的数据\n', evaluation_data.head(3))
使用read_csv() 函数读取 itheima_books.txt文件中的数据,并指定编码格式为utf8
import pandas as pd
txt_data = pd.read_csv('C:/py数据/第4章数据获取/itheima_books.txt', encoding='utf8')
print(txt_data)2、从Excel文件中读取数据
pandas中可使用read_excel读取Excel文件中的数据
使用read_excel() 函数读取Athletes_info.xlsx 文件,显示前5行
import pandas as pd
excel_data = pd.read_excel('C:/py数据/第4章数据获取/Athletes_info.xlsx')
print(excel_data.head(5))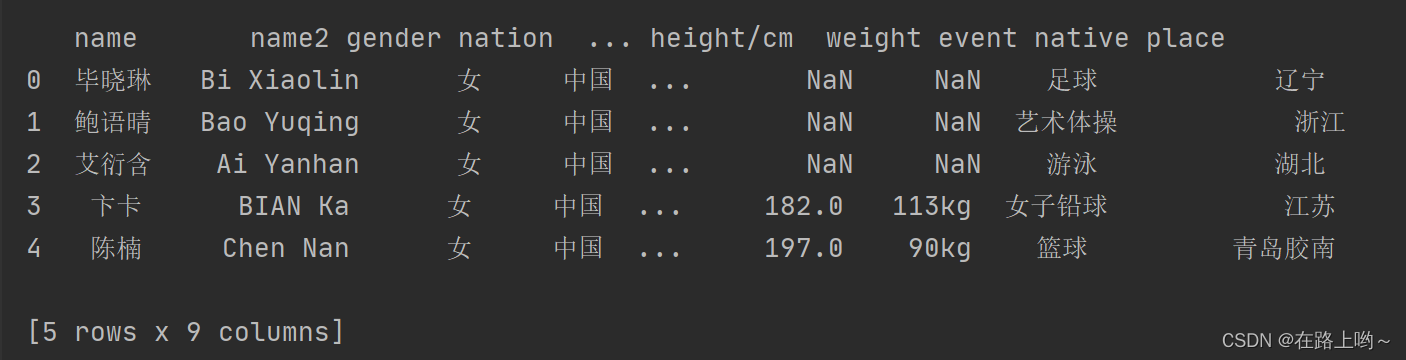
3、从JSON文件读取数据
pandas中可使用read_json()读取json文件中的数据
使用read_json() 函数读取 Animal_species.json 文件中的数据,并指定编码格式为utf8
import pandas as pd
json_data=pd.read_json('C:/py数据/第4章数据获取/Animal_species.json',encoding='utf8')
print(json_data)
4、从HTML文件读取数据
import requests
# 获取数据
html_data = requests.get('https://www.tiobe.com/tiobe-index/')
# 读取网页中所有表格数据
html_table_data = pd.read_html(html_data.content, encoding='utf-8')
# 获取索引为3的前5行表格数据
print(html_table_data[3].head(5))
5、从数据库获取数据
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/ttsx')
# 如果出现警告可使用如下(需使用pip安装mysql-connector-python)
# engine = create_engine('mysql+mysqlconnector://root:123456@127.0.0.1:3306/ttsx')
# 通过数据表名读取数据库的数据
category_data = pd.read_sql('C:/py数据/第4章数据获取/goodscategory', engine)
# 也可以通过SQL语句读取数据库的数据
# sql = "select * from goodscategory"
# category = pd.read_sql(sql,engine)
print(category_data)6、从word文件读取数据 用python-dox库
# Document类
# Paragraph类
# Table类
python—docx库的基本使用
使用python-docx库读取'集合介绍.docx'文件中的段落内容
步骤: 1、创建Document类对象 2、通过paragraphs属性获取段落对象 3、通过段落对象的text属性获取段落中的字符串
from docx import Document
# 创建Document类对象
docx = Document('C:/py数据/第4章数据获取/集合介绍.docx')
# 获取段落对象
paragraphs = docx.paragraphs
for i in paragraphs:
print(i.text)
使用python-docx库读取'集合介绍.docx'文件中的表格内容
步骤:
1、创建Document类对象
2、根据表格对象的rows属性获取行数据对象
3、通过单元格对象的cell()方法获取每个单元格对象
4、通过单元格对象的text属性获取对应的字符串
from docx import Document
# 创建Document类对象
docx = Document('C:/py数据/第4章数据获取/集合介绍.docx')
# 获取段落对象
tables = docx.tables
for table in tables:
for row in table.rows: # 获取行数据对象
row_conent = [] # 用于保存数据的列表
for cell in row.cells[:]: # 获取单元格对象
row_conent.append(cell.text) # 获取单元格中的字符串
print(row_conent) # 以列表的形式显示每一行数据
7、从pdf文件读取数据 用pdfplumber库
# pdf类
# page类
使用pdfplumber库读取pdf文件大致步骤:
1、加载pdf文件,生成pdf类对象
2、遍历获取page类对象的文本或表格
3、提取page类对象的文本或表格数据
使用pdfplumber库读取"集合简介.pdf"文件中所有的文本数据
步骤:
1、创建pdfplumber.pdf对象
2、通过page属性获取每页的实例对象
3、使用extract_text()方法提取页面中所有的文本数据和表格数据
import pdfplumber
with pdfplumber.open('C:/py数据/第4章数据获取/集合介绍.pdf') as pdf:
print(pdf.pages[0].extract_text())

只提取pdf文件中的表格数据
# 可以通过page类对象中的extract_tables()方法实现
import pdfplumber
with pdfplumber.open('C:/py数据/第4章数据获取/集合介绍.pdf') as pdf:
for page in pdf.pages:
for table in page.extract_table():
print(table)
从输出结果可以看出,程序读取了pdf文件中的表格数据,但返回的表格数据中包含空字符和None
使用fillter()函数和正则表达式可以去除这些无关的空字符和None
import pdfplumber, re
with pdfplumber.open('C:/py数据/第4章数据获取/集合介绍.pdf') as pdf:
for page in pdf.pages:
for table in page.extract_tables():
for data in table:
# 过滤数据中的None
clean_data = list(filter(None, data))
# 过滤数据中的换行符
print([re.sub('\n', '', value) for value in clean_data])

![[易语言][部署]使用易语言部署paddleocr的onnx模型api接口推理直接调用](https://i1.hdslb.com/bfs/archive/e37a5562f478e7b699888069f72b2191694ede8e.jpg@100w_100h_1c.png@57w_57h_1c.png)