Toolformer:可以教会自己使用工具的语言模型
- 摘要
- Introduction
- 现有大模型的局限
- 处理办法
- 本文的idea
- Approach
- 样例化API调用
- 执行API调用
- 筛选API调用
- 模型微调
- 实验
- 局限

论文地址点这里
摘要
语言模型(LMs)呈现了令人深刻的仅使用少量的范例或文本说明,就能处理大规模的新问题。矛盾的是,他们面临着挑战去完成一些基础功能,比如:数据统计或是事实查找,在一些更为简单、更为小的模型表格中。这篇论文将展现语言模型通过简单的API学会使用外部工具,实现两全其美。在这篇论文中,引入了Toolformer,这是一个被训练的模型,可以决策使用哪些API,什么时候调用这些API,有哪些参数需要传递,以及如何把结果合并到未来的token预测中。这是一种自监督方式,且只需要对每一个API进行少量的演示。它将计算器、问答系统、搜索引擎、翻译系统和日历整合起来。这个Toolformer对于一些下行任务基本实现了zero-shot的性能提升,在不牺牲核心语言建模能力下,可以和一些大模型竞争。
Zero-shot指的是:语言模型可以在没有经过特殊训练的任务上进行预测。例如:模型在训练过一些词条语料后直接用以进行对话任务,而没有学习一些精选对话场景。
Introduction
现有大模型的局限
Introduction部分,阐述了大语言模型会遇到的几个问题:
- 难以从最新事件中获取最新信息
- 产生幻觉倾向
- 难以理解低资源语言
- 在精确计算上缺乏数学技巧
- 对于进程时长的无意识
大语言模型要解决上述问题,基本就要扩大训练域的规模,而且有些在训练集的加大后,反倒会适得其反,比如ai幻觉这事,openAI说是在GPT-4上扩大了上下文窗口达到了一个比GPT-3.5更加好的hallucination风险处理,但是,很明显这种做法造成的算力浪费也是巨大的。
处理办法
作者认为一个大语言模型使用一些外部工具将是一种简单的方式克服这些问题。但是,这些工具不是依赖大量人类的标注,就是被限制只能处理特定的任务。然后,就是作者提出Toolformer用以一种奇特的方式去学习使用这些外部工具。
对于这个Toolformer有两点基本原则:
- 这些外部工具的使用学习是不用依赖于大量的人类标注的。这不仅是为了节省人工标注的工作量,而且还是因为人类认为有用的信息并不代表是模型认为有用的。
- 该语言模型是不会失去其泛化能力,并且它是可以自主的决定什么时候、如何去使用这些外部工具。这点与当前的方法相比,它是有更深刻的外部工具使用理解,以至于它不会将工具的使用拘囿于特定的任务场景。
本文的idea
作者团队最新的idea是使用上下文本训练的大语言模型去从头生成全部的数据集,以实现上述的目标,即:
- 仅使用少量的人工编写的API使用案例训练语言模型
- 再让该模型去注释一个大语言建模的数据集,这个过程模型是有潜在可能使用了这些API的。
- 然后,我们再去使用自监督损失确定哪些API的调用方式是对模型未来的token预测是有用的。
- 最后,我们再对自监督学习中找到的模型认为有用的API调用方式的语言模型中进行微调,使得该语言模型融入对这些API的使用。
API使用的注释训练过程如图:
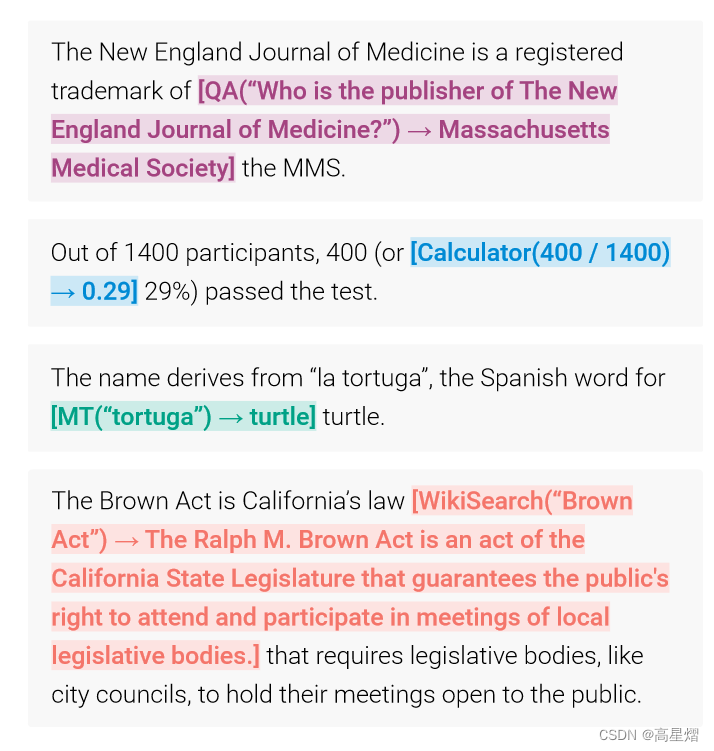
简单来说就是,作者先对一些人工编写的API使用方法进行训练,使得该语言模型掌握了这些API的使用方法;在进行自监督学习进行文本内部的API使用学习(即:学习如何在文本中使用API,何时使用API),这个部分就分为两个训练过程一个 in a task-agnostic way,一个in a task-specific way。上述的第2、3步就是自监督学习中无关数据的预训练过程,最后一步就是任务相关性训练。
原论文中似乎是将人工编写的API使用作为了一个输入,故直接使用这个输入对模型进行自监督学习的预训练,但是我这里是对人工编写使用API数据的纯粹性存疑,加上了一个训练剔除噪音的过程。我认为这个是有必要的,当然这个也可以是出现在数据预处理部分。(事实上,就是一开始读论文的时候看错了😅),既然,这里是使用了一个task-agnostic way,那么这就对于前期的输入数据集关系不大,我们就可以更好的迁移这些训练。
Introduction里还介绍了一下这个方法对比GPT-3的提升,可以去看一下。
Approach
上述的Introduction部分中,已经大致描述了作者的idea了,这里我们要将其以算法的形式展现出来。这里要求每一个API的输入以及输出均表示为文本序列。
首先,我们可以表示每一个API的调用为一个元组
c
=
(
a
c
,
i
c
)
c=(a_c,i_c)
c=(ac,ic),这里的
a
c
a_c
ac是该API的名字,
i
c
i_c
ic是对应API的输入。于是,一个API的调用就可以被表示为下述的一个线性序列,
不包含API输出结果r,如下:
e
(
c
)
=
<
A
P
I
>
a
c
(
i
c
)
<
/
A
P
I
>
e(c)=<API>a_c(i_c)</API>
e(c)=<API>ac(ic)</API>
包含API输出结果r,如下:
e
(
c
,
r
)
=
<
A
P
I
>
a
c
(
i
c
)
→
r
<
/
A
P
I
>
e(c,r)=<API>a_c(ic)\to r</API>
e(c,r)=<API>ac(ic)→r</API>
然后,给定一个平坦的文本数据集
C
=
{
x
1
,
.
.
.
,
x
∣
C
∣
}
C = \{x^1,...,x^{|C|}\}
C={x1,...,x∣C∣},这里需要将这个平坦的数据集C转换成扩充了API调用的数据集
C
∗
C^*
C∗,这个过程需要经历三步:
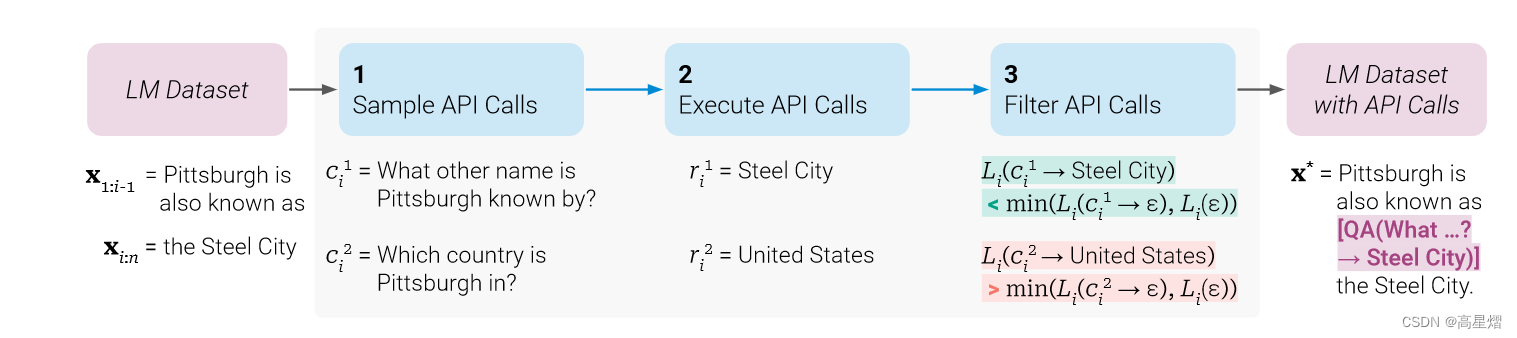
- 对模型M进行上下文训练,抽样出潜在的API调用。
- 执行这些API调用。
- 通过过滤评判,检查得到的回应是否是对未来的token预测有帮助。
在经历上述的数据集处理后,需要将不同工具的API调用以及他们最后的结果合并到增广数据集 C ∗ C^* C∗中,使用这个增广数据集对模型M进行微调。这就是整个算法的流程。下面,我将对每个步骤的实现原理一一进行剖析。
样例化API调用
对于每一个API,我们均写一个提示函数
P
(
x
)
P(x)
P(x)去让语言模型去使用API标记一个例子
x
=
x
1
,
.
.
.
,
x
2
\bold x=x_1,...,x_2
x=x1,...,x2。下图是一个关于问答工具的一个提示

在连续的序列
z
1
,
.
.
.
,
z
n
z_1,...,z_n
z1,...,zn后,模型M分配
z
n
+
1
z_{n+1}
zn+1的概率是
p
M
(
z
n
+
1
∣
z
1
,
.
.
.
,
z
n
)
p_M(z_{n+1}|z_1,...,z_n)
pM(zn+1∣z1,...,zn)。同理,当我们想要找寻k个候补位置用来使用API,需要我们对序列的每个位置进行计算其可能使用API的可能性:
p
i
=
p
M
(
<
A
P
I
>
∣
P
(
x
)
,
x
1
:
i
−
1
)
p_i=p_M(<API>|P(x),x_{1:i-1})
pi=pM(<API>∣P(x),x1:i−1)
通过设定一个阈值
τ
s
\tau_s
τs,保留位置是
I
=
{
i
∣
p
i
>
τ
s
}
I=\{i | p_i>\tau_s\}
I={i∣pi>τs},如果超过了k个就去最大的那k组位置。再对筛选出的这些位置I,我们可以通过样例化模型M中的以序列
[
P
(
x
)
,
x
1
,
.
.
.
,
x
i
−
1
,
<
A
P
I
>
]
[P(\bold x),x_1,...,x_{i-1},<API>]
[P(x),x1,...,xi−1,<API>]作为前缀以
<
/
A
P
I
>
</API>
</API>作为结尾的token,得到m个API的调用
c
i
1
,
.
.
.
,
c
i
m
c_i^1,...,c_i^m
ci1,...,cim。
执行API调用
在这一步骤里,我们执行模型M生成所有的API调用,以获得相应结果。这里的API调用执行就是完成涉及每一API。这些API有些可能需要使用Python脚本、有些可能涉及其他的神经网络,亦或者是一些其他的搜索系统。但是,需要注意的是对于每一个API调用 c i c_i ci的回复是需要一个单独的文本序列 r i r_i ri。
筛选API调用
令i是API调用
c
i
c_i
ci在序列
x
=
x
1
,
.
.
.
,
x
n
\bold x=x_1,...,x_n
x=x1,...,xn中的位置,
r
i
r_i
ri是这个API的回复。我们可以提前设出一组权重向量
(
ω
i
∣
i
∈
N
)
(\omega_i|i\in\mathbb{N})
(ωi∣i∈N),用以计算特定前缀
z
\bold z
z下的交叉熵:
L
i
(
z
)
=
−
∑
j
=
i
n
ω
j
−
i
⋅
l
o
g
p
M
(
x
j
∣
z
,
x
i
:
j
1
)
L_i(\bold z)=-\sum_{j=i}^n\omega_{j-i}\cdot log\ p_M(x_j|\bold z,x_{i:j1})
Li(z)=−j=i∑nωj−i⋅log pM(xj∣z,xi:j1)
神经网络中的损失计算多用交叉熵而非极大似然,原因是在通过激活函数激活后不会导致梯度消失
利用上式,可以写出使用API调用并给出结果给模型作为前缀(插入使用上API)的加权损失是:
L
i
+
=
L
i
(
e
(
c
i
,
r
i
)
)
L_i^+=L_i(e(c_i,r_i))
Li+=Li(e(ci,ri))
同样,我们可以写出不调用API,或是调用的API不将结果作为前缀的加权损失,这里取这俩者中的极小值:
L
i
−
=
m
i
n
(
L
i
(
ε
)
,
L
i
(
e
(
c
i
,
ε
)
)
)
L_i^-=min(L_i(\varepsilon),L_i(e(c_i,\varepsilon)))
Li−=min(Li(ε),Li(e(ci,ε)))
其中,
ε
\varepsilon
ε表示为空序列。
凭借直觉,可以做出判断,在模型中调用了这些API,是会对模型的预测起到很大的帮助的,所以
L
i
+
L_i^+
Li+肯定是小于
L
i
−
L_i^-
Li−。因此,这里要设置一个筛选阈值
τ
f
\tau_f
τf,我们只会在不调用API或是不获取API调用结果的损失值较于调用了API并返回结果的损失值高到超过这个阈值(不调用API的损失比调用的超过阈值),再去调用API,即满足下式:
L
i
−
−
L
i
+
≥
τ
f
L_i^--L_i^+\ge \tau_f
Li−−Li+≥τf
模型微调
在进行完抽样以及筛选API的调用后,再将这些API调用合并起来,使用原始输入将这些API的调用间隙填补起来(不同的API调用在不同的位置,其中的没有API调用的位置使用原始输入补白)。即,对于输入文本 x = x 1 , . . . , x n \bold x=x_1,...,x_n x=x1,...,xn,i处对应的API调用结果是 ( c i , r i ) (c_i,r_i) (ci,ri),则补白后的文本序列为 x ∗ = x 1 : i − 1 , e ( c i , r i ) , x i : n \bold x^*=x_{1:i-1},e(c_i,r_i),x_{i:n} x∗=x1:i−1,e(ci,ri),xi:n,这是一个API调用的。我们将多个API调用的序列如此得出后,可以得到一个新的增广数据集,将这个增广数据以一个标准的语言建模目标微调模型,则是自监督学习的最后一步。值得注意的是,对于文本序列中与原输入相同的部分,语言模型的微调是和之前相同的,而作为API调用的插入以及其输入将会帮助到模型对于未来token预测,也就是说,在对增广数据集进行微调的时候,是可以让语言模型纯纯通过这些上述筛选后的而反馈来决定何时及如何使用这些工具。
这个应该就是Approach的全部了。当然后面还有规定 → \to →作为反射API的调用, < A P I > <API> <API>和 < / A P I > </API> </API>分别作为API调用解码的开始与结束。
实验
该论文实验部分,为了测试调查该方法是否使模型能够在没有任何进一步监督的情况下使用工具,并自行决定何时以及如何调用可用的工具,选择了各种下游任务,并假设至少有一个考虑的工具是有用的,并在零射击设置中评估性能。除此之外,为了确保该方法不会损害模型的核心语言建模能力;通过查看两个语言建模数据集的复杂度来验证这一点。最后,研究了学习使用工具的能力如何受到模型大小的影响。
(但是,由于这里测试的API的来源以及训练数据的来源,我现在在国内是很难完成这个论文实验部分的复现,这个留到之后再完成复现,可以follow一下我的github仓库GAO-Xingyi)
局限
对于通过在自监督的方法实现语言模型使用各种工具的方法(Toolformer)是存在着一些局限的:
- Toolformer是不能链式使用工具
- 现有的Toolformer不能使语言模型以交互的方式使用工具
- Toolformer对于是否调用API是总是对输入的某些词更加敏感
- 对于一些工具,这个方法的样本效率是非常低下的
- 目前Toolformer在决定是否调用API时还没有将涉及使用工具的算力成本考虑进去
大概解释一下,第一点就是这个模型还不能将一个工具的使用结果作为另一个工具使用的输入,这个原因是出在训练设计上的,我们对于每一个工具的训练是分开独立的,最后在直接用增广数据集合到一起的。第二点,比如在让语言模型使用搜索引擎的时候,它只能返回搜索引擎的结果,而不能帮我们进行一次筛选。第三点,这也是预料以内的吧,这个对于语言模型的敏感词问题是one-shot、few-shot比较难避免的。第四点,这个设计到一些工具的使用文档并不适合于机器去学习使用,有一种解决思路是在相关引导下迭代的是使用这个工具。最后一个就是单纯没考虑。。。