1.Embedding
一文读懂Embedding的概念,以及它和深度学习的关系 - 知乎
one-hot编码当矩阵过于稀疏时计算开销大,于是加上Embedding层,通过Embedding层(矩阵乘法)实现降维。
Embedding层将一个一个词(词源,token)转为向量
2.self_attention
2.1.attention
一文看懂 Attention(本质原理+3大优点+5大类型) - 知乎
Attention 机制最早是在计算机视觉里应用的,随后在NLP领域也开始应用了,真正发扬光大是在 NLP 领域,因为 2018 年BERT和 GPT 的效果出奇的好,进而走红。而 Transformer和 Attention 这些核心开始被大家重点关注.
一句话说明注意力机制(Attention Mechanism):用于在神经网络中处理序列数据的机制,允许模型集中关注输入序列的不同部分,根据输入的重要性来加权计算。这使得模型能够动态地选择性地关注与当前任务相关的信息。

小白都能看懂的超详细Attention机制详解 - 知乎
机器翻译中,不同语言之间的语序有别,于是有了Encoder-Decoder结构的循环神经网络,以中间隐藏层为媒介处理不同语言词的输出位置和形式。随着输入数据的维度增加,Encoder-Decoder网络的中间层容量达到上限,于是有了循环神经网络中的Attention机制。
Transformer也采用Encoder-Decoder结构
如何分配权重?
2.2.self_attention
超详细图解Self-Attention - 知乎

左:XX^T计算两个向量的相关度(向量的内积表征两个向量的夹角,表征一个向量在另一个向量上的投影),通过softmax归一化(每个字都有自己[0,1]之内的关注度),再和自己X相乘。
一句话说明自注意力(Self-Attention):Transformer中的注意力机制称为自注意力(Self-Attention),因为它允许模型在输入序列内部进行注意力计算,而不仅限于与其他输入序列之间的关系。
自注意力机制的主要组成部分是查询(Query)、键(Key)和值(Value)的计算。对于每个输入位置,通过将该位置的嵌入表示分别作为查询、键和值,计算出每个位置与其他位置之间的注意力分数。然后,根据注意力分数对值进行加权求和,生成最终的输出表示。
注意力机制使得模型能够根据输入序列的不同部分之间的相关性,对信息进行加权聚合,从而更好地捕捉上下文信息和序列中的长距离依赖关系。这有助于提高模型的性能,并在处理序列数据时取得更好的结果。
3.Transformer
3.1.评价指标
Attention Is All You Need
bleu采用了一种N-gram的匹配规则,去比较议文和参考译文n组词的相似比。分母取决于原文N(N是多少就画几个框),分子是翻译准确的个数。

但是仅采用bleu不合理,如下图所示,原文和译文相似度低,但是1-gram下的bleu都是1。
Count指的是参考译文的词'the'出现在译文里面的次数Count=2,Max_Ref_Count=4表示'the'在参考译文里面出现的次数。所以Count_{clip} = 2

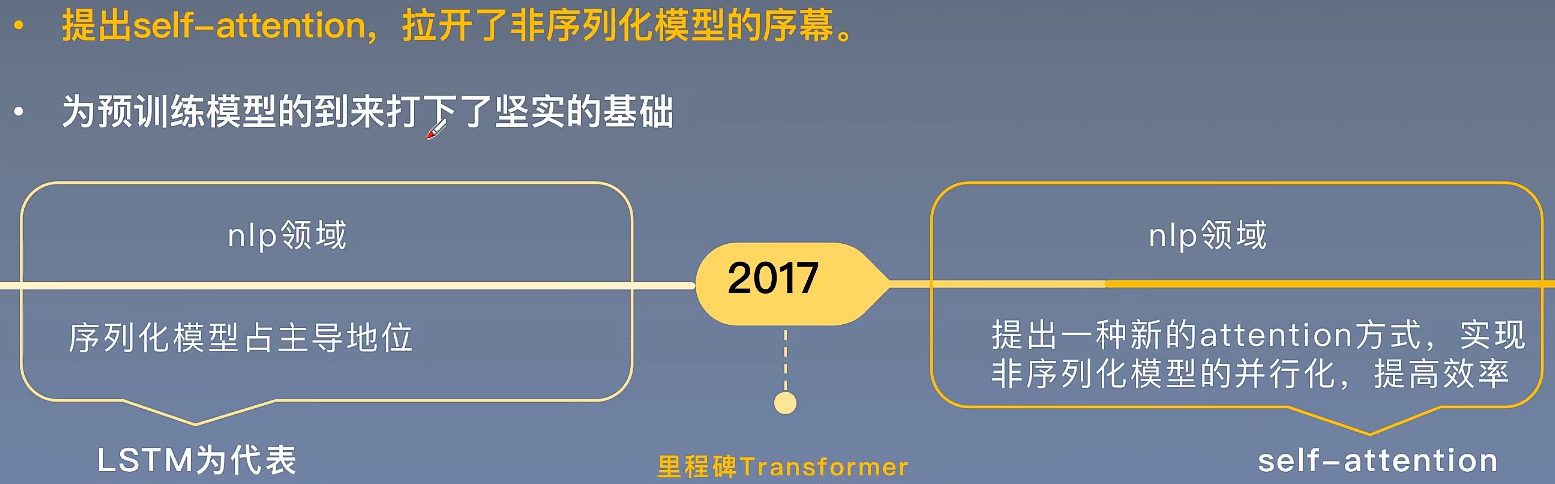
3.2.历史意义
Reference
1.Transformer(Attention is all you need)自然语音处理.【B站深度之眼镜】【论文复现代码数据集见评论区】Transformer(Attention is all you need)自然语音处理必读论文,为你提供论文复现+代码精讲_哔哩哔哩_bilibili
2.Transformer - Attention is all you need.【知乎】Transformer - Attention is all you need - 知乎
3.超详细图解Self-Attention.【知乎】超详细图解Self-Attention - 知乎
4.从Transformer到Bert.【知乎】从Transformer到Bert - 知乎
5.Transformer论文逐段精读.【B站】Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
6.Transformer论文逐段精读--笔记.【B站】Transformer论文逐段精读【论文精读】 - 哔哩哔哩







![环境配置 | Git的安装及配置[图文详情]](https://img-blog.csdnimg.cn/af3eedab5bf34413a3adbc21a55e9136.png)