系列文章目录
第一章 AlexNet网络详解
第二章 VGG网络详解
第三章 GoogLeNet网络详解
第四章 ResNet网络详解
第五章 ResNeXt网络详解
第六章 MobileNetv1网络详解
第七章 MobileNetv2网络详解
第八章 MobileNetv3网络详解
第九章 ShuffleNetv1网络详解
第十章 ShuffleNetv2网络详解
第十一章 EfficientNetv1网络详解
第十二章 EfficientNetv2网络详解
第十三章 Transformer注意力机制
第十四章 Vision Transformer网络详解
第十五章 Swin-Transformer网络详解
第十六章 ConvNeXt网络详解
第十七章 RepVGG网络详解
第十八章 MobileViT网络详解
文章目录
- ResNeXt网络详解
- 0. 前言
- 1. 摘要
- 2. ResNeXt网络详解网络架构
- 1. ResNeXt_Model.py(pytorch实现)
- 2.
- 总结
0、前言
1、摘要
我们提出了一种简单、高度模块化的图像分类网络架构。我们的网络由重复的构建块构建,这些构建块聚集了一组具有相同拓扑的变换。我们的简单设计导致了一个具有少量超参数的同质、多分支架构。这种策略展示了一个新的维度,我们称之为“基数”(变换集的大小),它是除了深度和宽度之外的一种关键因素。在ImageNet-1K数据集上,我们经验证明,即使在保持复杂性的限制条件下,增加基数也能提高分类准确性。此外,当我们增加容量时,增加基数比增加深度或宽度更有效。我们的模型名为ResNeXt,是我们参加ILSVRC 2016分类任务的基础,我们获得了第二名。我们进一步对ResNeXt进行了ImageNet-5K集和COCO检测集的研究,结果比ResNet更好。代码和模型可在网上公开获取。
2、ResNeXt网络结构
1.本文介绍了一个高度模块化的图像分类网络结构,名为ResNeXt,通过增加变换的张量大小(cardinality)提高准确率。
2.本文研究的背景是图像分类网络结构设计和性能优化。
3.本文的主要论点是增加变换的张量大小可以提高图像分类网络的准确率。
4.以往的研究主要集中在增加网络深度或宽度来提高性能,但这样会增加计算复杂度和运算时间。本文提出的方法是增加变换的张量大小,这样可以在保持网络复杂度不变的前提下提高分类准确率。
5.本文的研究方法是构建一个多分支的图像分类网络结构,通过增加变换的张量大小来提高准确率。实验数据来自ImageNet-1K数据集、ImageNet-5K数据集和目标检测数据集COCO。
6.本文的发现是增加变换的张量大小是提高图像分类网络性能的一种有效方法,但由于实验数据集有限,该方法是否适用于其他数据集需要进一步研究。
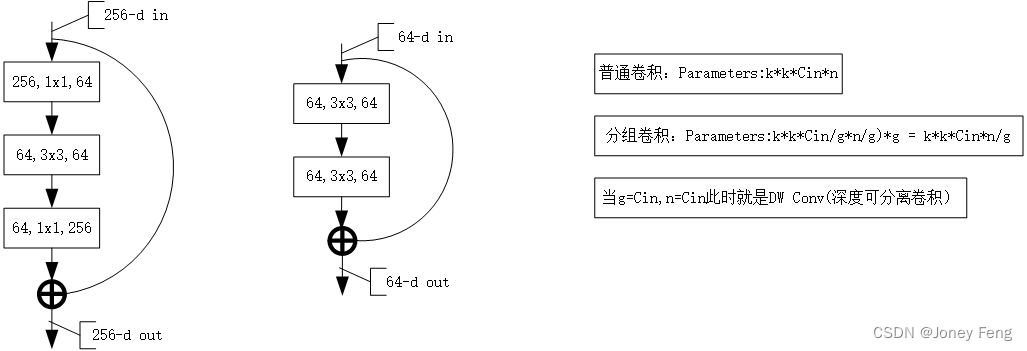

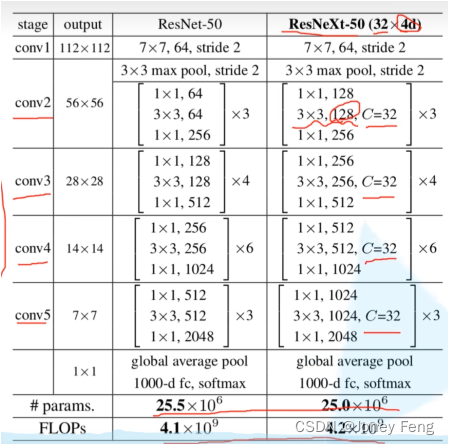
1.ResNeXt_Model.py(pytorch实现)
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self,num_classes=1000,init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(48, 128, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(128, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128*6*6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
2.train.py
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else 'cpu')
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = 'D:/100_DataSets/'
image_path = os.path.join(data_root, "03_flower_data")
assert os.path.exists(image_path), "{} path does not exits.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform = data_transform['train'])
train_num = len(train_dataset)
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 6
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
print('Using {} dataloder workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform['val'])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4,
shuffle=False,
num_workers=nw)
print("using {} image for train, {} images for validation.".format(train_num, val_num))
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
loss_fuction = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 10
save_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_fuction(outputs, labels.to(device))
loss.backward()
optimizer.step()
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:,.3f}".format(epoch+1, epochs, loss)
net.eval()
acc = 0.0
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch % d] train_loss: %.3f val_accuracy: %.3f' %
(epoch+1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(),save_path)
print("Finished Training")
if __name__ == '__main__':
main()
3.predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))]
)
img_path = "D:/20_Models/01_AlexNet_pytorch/image_predict/tulip.jpg"
assert os.path.exists(img_path), "file: '{}' does not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
img = data_transform(img)
img = torch.unsqueeze(img, dim=0)
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' does not exist.".format(json_path)
with open(json_path,"r") as f:
class_indict = json.load(f)
model = AlexNet(num_classes=5).to(device)
weights_path = "./AlexNet.pth"
assert os.path.exists(weights_path), "file: '{}' does not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path))
model.eval()
with torch.no_grad():
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3f}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()4.predict.py
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
rmtree(file_path)
os.makedirs(file_path)
def main():
random.seed(0)
split_rate = 0.1
#cwd = os.getcwd()
#data_root = os.path.join(cwd, "flower_data")
data_root = 'D:/100_DataSets/03_flower_data'
origin_flower_path = os.path.join(data_root, "flower_photos")
assert os.path.exists(origin_flower_path), "path '{}' does not exist".format(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path) if os.path.isdir(os.path.join(origin_flower_path, cla))]
train_root = os.path.join(data_root,"train")
mk_file(train_root)
for cla in flower_class:
mk_file(os.path.join(train_root, cla))
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
mk_file(os.path.join(val_root,cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path,cla)
images = os.listdir(cla_path)
num = len(images)
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{} / {}]".format(cla, index+1, num), end="")
print()
print("processing done!")
if __name__ == "__main__":
main()
总结
提示:这里对文章进行总结:
每天一个网络,网络的学习往往具有连贯性,新的网络往往是基于旧的网络进行不断改进。