文章目录
- 前言
- 双目相机标定
- 去畸变
- 极线校正(立体校正)
- 立体匹配
- 深度图生成
- 文章已经同步更新在3D视觉工坊啦,原文链接如下:
前言
双目立体视觉是计算机视觉中的一个重要领域,它利用两个相机拍摄同一场景的不同视角的图像,通过计算图像之间的对应关系,恢复出场景的三维结构信息。双目立体视觉的基本步骤包括双目标定、立体校正、立体匹配和三维重建。本文将介绍这些步骤,帮助你学会从双目标定到立体匹配的基本流程。
双目相机标定
双目标定是指确定两个相机之间的几何关系,包括内参矩阵、外参矩阵和基础矩阵。内参矩阵描述了相机的内部参数,如焦距、主点坐标和畸变系数。外参矩阵描述了相机的外部参数,如旋转矩阵和平移向量。基础矩阵描述了两个图像平面之间的对极几何关系,即任意一点在一个图像平面上的投影与另一个图像平面上的对应点所在的直线满足一个线性方程。
双目标定的方法有很多,常用的是基于棋盘格图案的张氏标定法,它利用多幅不同角度拍摄的棋盘格图像,通过提取角点坐标和求解最小二乘问题,得到两个相机的内参矩阵和外参矩阵,进而计算出基础矩阵。

tip:除了传统的标定方法的张正友标定法,还有什么标定方法?
传统的标定方法:除了张正友标定法还包括椎体标定法、光栅板标定法、点追踪标定法等,这些方法通常需要事先准备一些特定的标定物体和设备,采集一定数量的标定图像或者对标定物体进行特殊处理,然后通过求解投影矩阵和外参矩阵等参数,计算出相机的内部参数和外部参数。
自标定方法:也称为自标定技术或自动标定技术,它是一种无需特定标定物体和设备,通过对场景中的特征点或轮廓线进行跟踪、匹配和分析,利用统计学或优化算法实现相机标定的方法。这种方法与传统标定方法相比,具有更高的自动化程度和更广泛的适应性,但在精度和稳定性上稍有不足。
基于主动视觉的标定方法:主要包括基于结构光的方法和基于视觉后处理的方法。前者是通过光源和被测物体之间的互动关系,实现对相机内部参数和外部参数的标定;后者则是利用数字图像处理技术进行后处理,从而提高标定结果的精度和可靠性。这些方法因其高精度、高速度、无需接触、非侵入性等优点,在各种工业自动化、机器人视觉等领域都有广泛应用。但是标定过程复杂,设备成本高昂。
去畸变

标定板法是最常用的一种方法,它可以根据标定板上的特征点计算出相机的畸变参数,然后通过畸变参数对图像进行畸变校正。自适应分类法是一种基于图像边缘的方法,它可以通过检测图像边缘来估计畸变参数,然后对图像进行畸变校正。以图像边缘为基础的方法是一种基于图像边缘的方法,它可以通过检测图像边缘来估计畸变参数,然后对图像进行畸变校正。以特征点为基础的方法是一种基于特征点匹配的方法,它可以通过匹配特征点来估计畸变参数,然后对图像进行畸变校正。以直线为基础的方法是一种基于直线匹配的方法,它可以通过匹配直线来估计畸变参数,然后对图像进行畸变校正。
tip:假如已经通过张正友标定获取了相机的内外参数,接下来去畸变都可以使用什么算法?
如果已经获取了相机的内部参数和外部参数,可以使用 OpenCV 库中提供的 undistort() 函数对图像进行去畸变处理。在这种情况下,对于常见的径向畸变,undistort() 函数在默认情况下使用张正友畸变模型进行去畸变处理。具体实现过程如下:
-
根据所给的相机内部参数和外部参数,计算出投影矩阵 Q,即将相机坐标系下的三维点转换到像素坐标系下的映射矩阵。
-
根据 Q 矩阵和畸变系数,计算出相机坐标系下的径向畸变和切向畸变的校正系数。
-
通过校正系数对输入的图像进行去畸变处理。

极线校正(立体校正)
在双目视觉中,极线校正是一项关键的预处理步骤,极线校正的主要目标是将左右图像的极线对齐,并且使对应的像素在同一行上。这样,当进行立体匹配时,我们只需要在一条极线上搜索对应像素,而无需在整个图像上进行搜索。这极大地降低了计算复杂度,并提高了匹配的效率。

tip:有没有不需要极线校正的立体匹配算法?极线校正是立体匹配必须要提前进行的步骤吗?
事实上,并不一定需要进行极线校正才能进行立体匹配。以下几种算法可以在无需进行极线校正的情况下进行立体匹配:
-
基于特征的匹配算法:这类算法利用图像中的特征点(如SIFT,SURF等)进行匹配,在匹配过程中可以抵消一定角度的视角变化,无需极线校正。代表算法有SIFT立体匹配、SURF立体匹配等。
-
基于区块的匹配算法:这类算法将图像分割成多个区块,然后在两个图像中的对应区块中寻找最相似的区块进行匹配。匹配过程中也可以抵消一定的视角变化,无需极线校正。代表算法有区块匹配算法等。
-
基于光流的匹配算法:这类算法通过计算两个图像之间的光流场来寻找匹配,光流计算过程可以抵消一定视角变化,所以也无需进行极线校正。代表算法有Lucas-Kanade光流算法等。
-
基于深度学习的匹配算法:这类算法利用深度学习网络对立体图像对进行端到端的学习和匹配,网络在训练过程中可以学习视角变化,所以也无需进行极线校正。代表算法有PBC-Net等。
所以,总的来说,尽管极线校正可以简化立体匹配的难度,但并不是立体匹配一定要提前进行的步骤。使用上述几种算法都可以在无需进行极线校正的情况下实现立体匹配。
立体匹配
立体匹配是指寻找两个图像中相同物体或场景的对应点,从而计算出它们之间的视差。视差是指同一物体在两个图像中投影点之间的水平距离,它与物体到相机的距离成反比,因此可以用来估计物体的深度。
立体匹配的方法有很多,以下是一些常见的立体匹配算法:
-
基于块匹配的算法:这是一种经典的立体匹配算法,它将图像分成小的块,然后在两个摄像机图像中搜索具有最小差异的块对应区域。常见的块匹配算法包括贪婪匹配算法(例如最小绝对差异、最小均方差)和自适应窗口匹配算法(例如自适应支持窗口)。
-
基于特征匹配的算法:这些算法使用图像中的特征点或特征描述符来进行匹配。特征点可以是角点、边缘点或其他具有显著性的图像点。常见的特征匹配算法包括尺度不变特征变换(SIFT)、加速稳健特征(SURF)和特征点匹配算法(例如RANSAC)。
-
基于能量优化的算法:这些算法将立体匹配问题建模为能量最小化问题。通过定义能量函数和约束条件,可以使用动态规划、图割(graph cut)或消息传递等方法来求解最优匹配。常见的能量优化算法包括图割算法、Belief Propagation算法和Semi-Global Matching(SGM)算法。
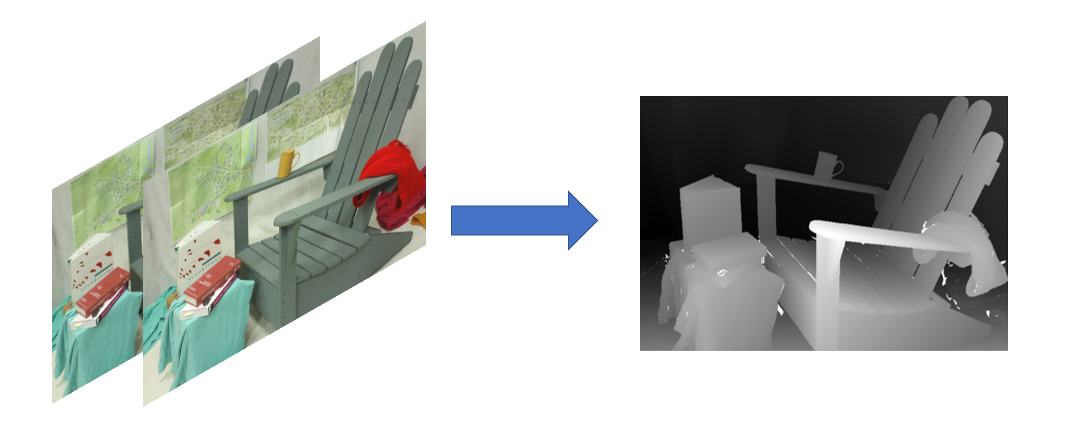
深度图生成
视差图是由两个不同位置的相机所拍摄到的两张图像组成的。深度图则是通过视差图来计算出物体所处的深度。以下是几种生成深度图的算法:
-
基线三角化:通过已知的相机位置和视差图的像素坐标之间的关系,使用三角化方法计算出物体深度。
-
统计学方法:通过对大量的视差数据进行简单统计,去除误差和离群点得到物体深度。
-
基于卷积神经网络(CNN)的方法:使用卷积神经网络训练模型,对输入的视差图进行处理,得到物体的深度图。
- 基于深度学习和立体视觉的融合方法:将深度卷积神经网络(DCNN)和立体视觉算法结合起来进行深度图生成,提高深度图的精度和鲁棒性。
tip:深度图和视差图有什么区别?
视差图指存储立体校正后单视图所有像素视差值的二维图像,是左图和右图对应点的x差值,单位一般是像素单位。深度图是在视差图基础上生成的图像,它的像素值表示场景中各点到相机的距离。深度图是一种单通道灰度图像,其中像素值越小表示物体距离相机越近,像素值越大表示物体距离相机越远。深度图可以用于计算物体的三维坐标,也可用于机器视觉和计算机图形学中的三维重建、虚拟现实等领域。
文章已经同步更新在3D视觉工坊啦,原文链接如下:
从零开始:入门双目视觉你需要了解的知识
欢迎大家加入知识星球,里面有很多大牛解答问题,还可以和小伙伴们一起讨论问题哦!








![[RockertMQ] Broker启动加载消息文件以及恢复数据源码 (三)](https://img-blog.csdnimg.cn/e7dbc98c9d944b64b7169917c3d3db57.png)