Java集合之ArrayList
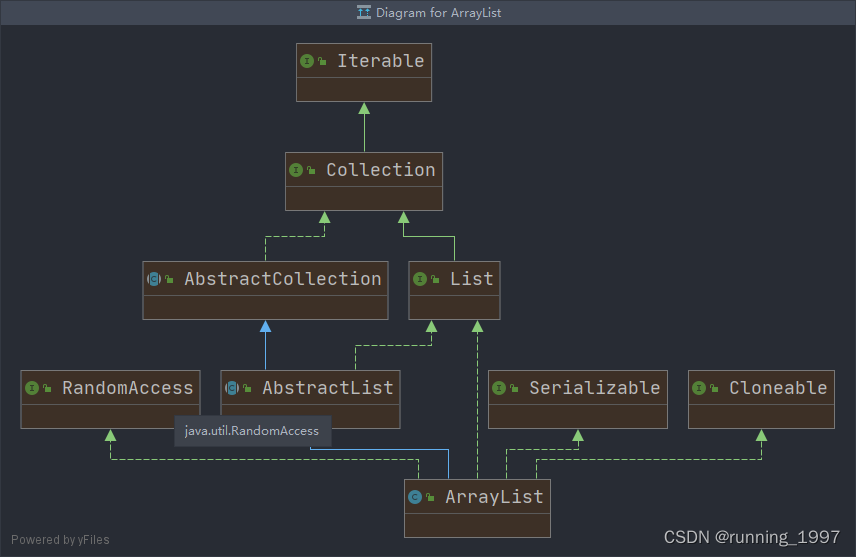
- 一、ArrayList类的继承关系
- 1. 基类功能说明
- 1.1. Iterator:提供了一种方便、安全、高效的遍历方式。
- 1.2. Collection:为了使ArrayList具有集合的基本特性和操作。
- 1.3. AbstractCollection:提供了一些通用的集合操作。
- 1.4. List:为了让其具有列表的特性和更多的操作。
- 1.5. Serializable:支持序列化。
- 1.6. AbstractList:为了使其具有列表的抽象特性和操作。
- 1.7. RandomAccess:支持随机访问。
- 1.8. Cloneable:支持克隆操作。
- 二、ArrayList的优缺点
- 1. 优点:
- 1.1. 速度快:支持通过下标访问
- 1.2. 高效的元素添加和删除:支持在末尾添加和删除
- 1.3. 可以存储任何类型的对象:基本类型和自定义类型
- 1.4. 可以动态扩容:使用起来非常灵活
- 2. 缺点:
- 2.1. 频繁的插入和删除操作开销较大:涉及元素移动
- 2.2. 内存浪费:容量设置过大,存在浪费内存空间
- 2.3. 不支持多线程操作:多线程下不安全
- 2.4. 查询和删除操作效率低:查询指定元素,需要依次遍历
- 三、ArrayList源码分析
- 1. 基本属性
- 1.1 DEFAULT_CAPACITY
- 1.2 EMPTY_ELEMENTDATA
- 1.3 DEFAULTCAPACITY_EMPTY_ELEMENTDATA
- 1.4 elementData
- 1.5 size
- 2. get方法
- 3. set方法
- 4. add方法
- 4.1 add方法流程图:
- 5. remove方法
- 5.1 remove(int index):
- 5.2 remove(Object o):
- 5.3 fastRemove(int index):
- 6. clear方法
- 四、ArrayList三种遍历方式
- 1、使用for循环遍历
- 2、通过下标遍历
- 3、使用Iterator迭代器遍历
- 4、增强for本质上也是迭代器
- 五、ArrayList之fail-fast 和fail-safe机制
- 1. fail-fast:Java集合当中的一种错误检测机制
- 1.1 简述:ConcurrentModificationException
- 1.2 原理:modCount#expectedModCount
- 1.3 使用场景:
- 1.4 注意:
- 2. fail-safe:集合被修改时创建副本,保证线程安全
- 2.1. 简述:拷贝集合
- 2.2. 原理:拷贝集合
- 2.3. 使用场景:
- 2.3.1 多线程环境下的并发读写操作:
- 2.3.2 数据量较小且读操作较多的场景:
- 2.3.3 不要求强一致性的场景:
- 2.4. 注意:
- 2.5. 扩展:集合容器对比
- 2.5.1. ArrayList#CopyOnWriteArrayList
- 2.5.2. LinkedList#CopyOnWriteArrayList
- 2.5.3. HashMap#ConcurrentHashMap
- 2.5.4. TreeMap#ConcurrentSkipListMap
- 2.5.6. HashSet#ConcurrentHashMap
- 2.5.7. TreeSet#ConcurrentSkipListSet
- 六、ArrayList在多线程下如何使其线程安全
- 1. 使用 Vector 代替 ArrayList。
- 2. 使用Collections.synchronizedList()方法。
- 3. 使用CopyOnWriteArrayList。
- 4. 使用Lock。
- 八、ArrayList的序列化机制
- 1. 自定义序列化机制 readObject、writeObject
- 2. 为什么用transient修饰elementData数组
一、ArrayList类的继承关系
1. 基类功能说明
1.1. Iterator:提供了一种方便、安全、高效的遍历方式。
-
Iterator是一个迭代器接口,它提供了一种安全的遍历集合元素的方法,可以避免在遍历过程中修改集合引起的ConcurrentModificationException异常,同时还可以避免在遍历过程中删除集合元素时出现索引越界等问题。
-
ArrayList使用Iterator遍历集合时,可以使用hasNext()方法判断是否还有元素,使用next()方法获取下一个元素,使用remove()方法安全地删除当前元素。因此,使用Iterator遍历ArrayList既方便又安全,是一种非常推荐的遍历方式。
-
另外,Iterator接口是Java集合框架中的一部分,实现Iterator接口可以使ArrayList更加符合集合框架的统一标准,方便与其他集合类一起使用。
1.2. Collection:为了使ArrayList具有集合的基本特性和操作。
- ArrayList是Java中常用的集合类之一,它实现了Collection接口,这是为了使ArrayList具有集合的基本特性和操作,例如添加、删除、遍历等。
- 实现Collection接口可以让ArrayList能够和其他Java集合类兼容,可以方便地进行集合之间的转换和使用。同时,实现Collection接口也使得ArrayList能够支持泛型,可以在编译期间进行类型检查,避免了运行时出现类型错误的问题。
- 总之,ArrayList实现Collection接口是为了使其具有更多的特性和更好的兼容性。
1.3. AbstractCollection:提供了一些通用的集合操作。
- 例如containsAll、removeAll、retainAll等方法,这些方法可以被ArrayList直接继承和使用,从而避免了重复实现这些操作。
- 同时,AbstractCollection也提供了一些抽象方法,例如size、iterator、toArray等方法,这些方法需要由具体的集合类去实现,ArrayList也需要实现这些方法以完成自身的功能。
1.4. List:为了让其具有列表的特性和更多的操作。
- ArrayList实现了List接口,是为了使其具有列表的特性和操作,例如按索引访问元素、插入、删除、替换等。List是Collection接口的子接口,提供了更多针对列表的操作。
- 例如按索引操作、排序、子列表等。因此,实现List接口可以让ArrayList具有更多的操作和更好的兼容性,可以和其他实现List接口的Java集合类进行交互和转换。
1.5. Serializable:支持序列化。
- 序列化是将对象转换为字节流的过程,可以用于持久化对象、网络传输等操作。实现Serializable接口可以让ArrayList的实例对象被序列化,以便于在需要的时候进行序列化操作。
1.6. AbstractList:为了使其具有列表的抽象特性和操作。
-
AbstractList是List接口的一个抽象实现,实现了List接口的大部分方法,包括添加、删除、获取元素、遍历等。
-
ArrayList作为List接口的一个具体实现,需要实现List接口中定义的所有方法。
-
通过继承AbstractList抽象类,ArrayList可以重用AbstractList中已经实现的方法,减少重复代码,提高代码的复用性和可维护性。
-
另外,AbstractList还提供了一些抽象方法,例如get()、set()、add()、remove()等,这些抽象方法需要ArrayList子类实现,从而使得ArrayList具备列表的基本操作。
-
AbstractList还提供了一些模板方法,例如addAll()、removeAll()等,这些方法可以通过调用抽象方法实现具体的操作。通过继承AbstractList抽象类,ArrayList可以利用这些模板方法快速实现各种列表操作,提高了开发效率。
综上所述,ArrayList实现了AbstractList抽象类是为了重用AbstractList中已经实现的方法,提高代码的复用性和可维护性,同时也能够利用AbstractList中提供的模板方法快速实现各种列表操作。
1.7. RandomAccess:支持随机访问。
-
ArrayList实现了RandomAccess接口,是为了提高随机访问的效率。RandomAccess接口是一个标记接口,用于表示实现该接口的集合支持快速随机访问,即可以通过下标直接访问集合中的元素,而不需要通过迭代器进行遍历。
-
对于ArrayList来说,它是一个基于数组实现的列表,因此可以通过下标直接访问数组中的元素。实现RandomAccess接口可以让ArrayList在随机访问时使用高效的数组访问方式,从而提高随机访问的效率。
-
如果一个集合没有实现RandomAccess接口,那么在进行随机访问时,会通过迭代器遍历集合中的元素,这个过程比直接访问数组的效率要低。因此,在需要频繁进行随机访问的情况下,实现RandomAccess接口可以大大提高访问效率。
-
需要注意的是,实现RandomAccess接口并不一定能提高集合的效率,它只是表明该集合支持快速随机访问的特性,具体效率的提升还要看具体的实现。
1.8. Cloneable:支持克隆操作。
-
Cloneable接口是一个标记接口,用于表示实现该接口的对象可以进行克隆操作。
-
在ArrayList中,克隆操作可以用于创建一个与原列表相同的新列表,这个新列表与原列表相互独立,对新列表的修改不会影响到原列表。这在某些场景下非常有用,例如需要对一个列表进行操作,但是又需要保留原列表不变的情况下,可以先克隆出一个新列表进行操作。
-
需要注意的是,ArrayList实现Cloneable接口只是表示它支持克隆操作,并不代表它的克隆操作一定是完全正确和安全的。在进行克隆操作时,需要注意可能存在的浅拷贝和深拷贝问题,以及可能会影响到对象的不变性和线程安全性问题等。
-
因此,在使用ArrayList的克隆操作时,需要仔细考虑其对程序的影响,并进行必要的安全性和正确性检查。
二、ArrayList的优缺点
1. 优点:
1.1. 速度快:支持通过下标访问
由于ArrayList底层是基于数组实现的,因此查询和随机访问速度非常快,时间复杂度为O(1)。
1.2. 高效的元素添加和删除:支持在末尾添加和删除
ArrayList支持在末尾添加和删除元素的操作,时间复杂度为O(1),因此在操作上非常高效。
1.3. 可以存储任何类型的对象:基本类型和自定义类型
ArrayList可以存储任何类型的对象,包括基本类型和自定义类型。
1.4. 可以动态扩容:使用起来非常灵活
ArrayList可以根据需要动态地扩展容量,因此它非常灵活。
2. 缺点:
2.1. 频繁的插入和删除操作开销较大:涉及元素移动
由于ArrayList底层是基于数组实现的,因此在进行频繁的插入和删除操作时,需要移动大量的元素,时间复杂度为O(n),开销较大。
2.2. 内存浪费:容量设置过大,存在浪费内存空间
由于ArrayList是基于数组实现的,因此在创建ArrayList时需要指定初始容量,如果容量设置过大,就会浪费内存空间。
2.3. 不支持多线程操作:多线程下不安全
由于ArrayList不是线程安全的,因此在多线程环境下需要进行额外的同步操作,否则会出现线程安全问题。
2.4. 查询和删除操作效率低:查询指定元素,需要依次遍历
当需要查询和删除某个元素时,需要遍历整个ArrayList,时间复杂度为O(n)。
三、ArrayList源码分析
1. 基本属性
1.1 DEFAULT_CAPACITY
默认初始容量,没什么可说的。
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
1.2 EMPTY_ELEMENTDATA
空实例数组。
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
1.3 DEFAULTCAPACITY_EMPTY_ELEMENTDATA
默认大小的空实例数组,在第一次调用ensureCapacityInternal方法时会初始化长度为10
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
1.4 elementData
存放元素的数组。
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
1.5 size
当前数据中有多少元素
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
2. get方法
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
E elementData(int index) {
return (E) elementData[index];
}
- 根据传入的下标
- 调用rangeCheck方法检查下标是否越界
- 由于底层是数组,可以直接根据index获取elementData数组对应下标位置的元素
3. set方法
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
E elementData(int index) {
return (E) elementData[index];
}
- 根据传入的下标index和元素element
- 调用rangeCheck方法检查下标是否越界
- 获取当前elementData数组对应的老数据
- 将当前元素,根据传入小标放入数组中指定位置
- 将当前下标对应的老数据进行返回
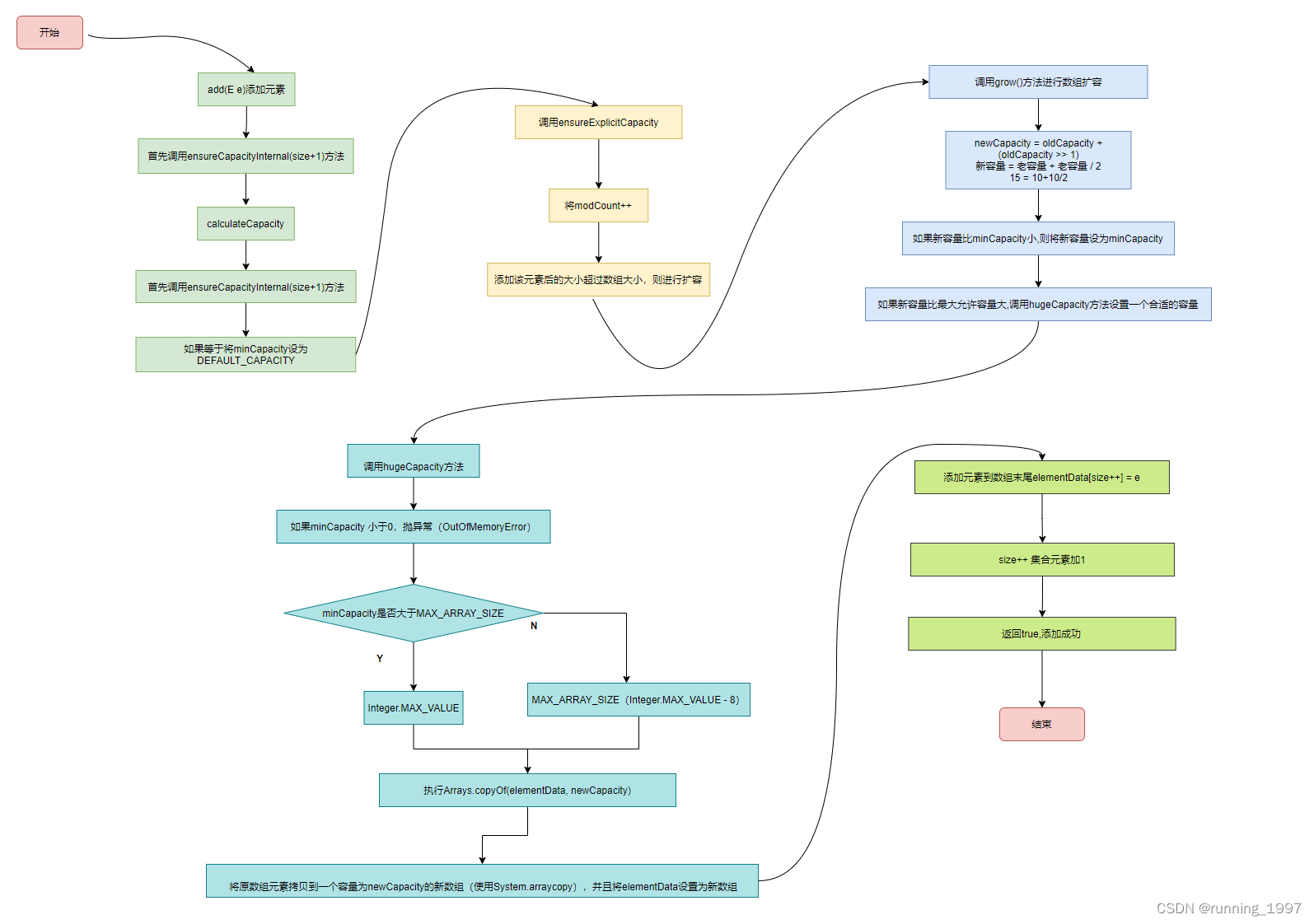
4. add方法
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
4.1 add方法流程图:
5. remove方法
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
5.1 remove(int index):
- 检查下标是否越界。
- 将modCount+1,计算需要移动的元素个数
- 如果需要移动,将index+1位置及之后的所有元素,向左移动一个位置。
- 将size-1位置的元素赋值为空(因为上面将元素左移了,所以size-1位置的元素为重复的,将其移除)。
5.2 remove(Object o):
- 如果传入元素为null,遍历数组,查找第一个为null的元素。
1.1. 调用fastRemove()方法。
1.2 移除成功,返回true。 - 如果传入元素不为null,则遍历数组查找是否存在元素与入参元素使用equals比较返回true。
2.1. 如果存在则调用fastRemove将该元素移除,并返回true表示移除成功 - 不存在目标元素,返回false
5.3 fastRemove(int index):
1.将modCount修改次数+1。
2. 计算需要移动的元素个数numMoved 。
3. 调用System.arraycopy,开始移动。
4. 将size-1,并将size-1位置的元素赋值为空。(否则存在重复元素)
6. clear方法
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
- 将modCount+1。
- 遍历数组将所有元素设置为null。
- size元素数量置为0。
四、ArrayList三种遍历方式
1、使用for循环遍历
ArrayList<String> list = new ArrayList<String>();
// 添加元素
for (String str : list) {
System.out.println(str);
}
2、通过下标遍历
ArrayList<String> list = new ArrayList<String>();
// 添加元素
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
3、使用Iterator迭代器遍历
ArrayList<String> list = new ArrayList<String>();
// 添加元素
Iterator<String> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
4、增强for本质上也是迭代器
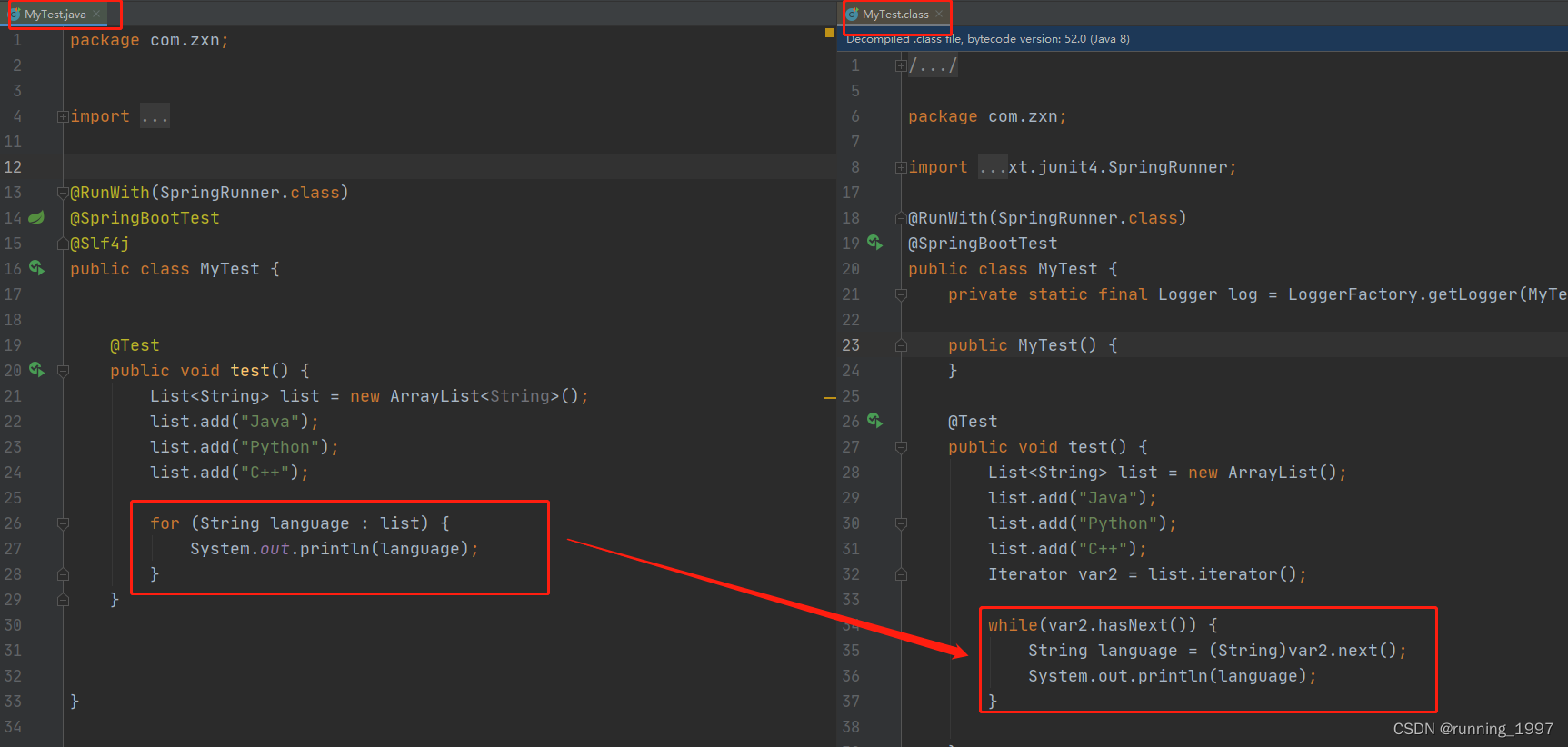
五、ArrayList之fail-fast 和fail-safe机制
1. fail-fast:Java集合当中的一种错误检测机制
1.1 简述:ConcurrentModificationException
- Java集合中的快速失败机制是通过在集合结构发生变化时,及时检查并发修改的情况,如果发现其他线程正在遍历该集合,就立即抛出ConcurrentModificationException异常,以防止并发修改导致数据不一致的问题。
1.2 原理:modCount#expectedModCount
-
当使用迭代器遍历集合时,会使用一个预期修改次数(expectedModCount)变量来记录当前集合的修改次数(modCount)。每次调用next()方法时,都会先检查expectedModCount和modCount是否相等。如果相等,则说明在遍历过程中没有发生并发修改,可以返回下一个元素;如果不相等,则说明在遍历过程中有其他线程进行了修改,就会抛出ConcurrentModificationException异常。
-
在集合结构发生变化时,会修改modCount的值,这样在遍历过程中就能够检测到并发修改情况。具体来说,当调用add()、remove()、clear()等方法时,会修改modCount的值,如果此时有其他线程正在遍历集合,则会在下一次遍历时检测到并抛出异常。
-
总的来说,Java集合中的快速失败机制是通过预期修改次数和实际修改次数的比较来检测并发修改的情况。这种机制虽然会增加一定的开销,但能够保证数据的一致性和可靠性。
1.3 使用场景:
java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)
1.4 注意:
- 如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount,就会导致迭代器没有检测到集合结构的变化,而继续执行下去,这样可能会引起数据不一致的问题。例如,如果集合中有两个相同的元素,但是在迭代过程中只返回了其中一个,这样就会导致数据不一致的问题。
2. fail-safe:集合被修改时创建副本,保证线程安全
2.1. 简述:拷贝集合
- 采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
2.2. 原理:拷贝集合
- 修改时不在原集合上做操作,而是基于原集合copy一个新的集合,在新的集合上做数据变动,会存在短暂的数据不一致问题。
2.3. 使用场景:
2.3.1 多线程环境下的并发读写操作:
使用fail-safe机制的集合类可以保证多个线程同时对集合进行读写操作时,不会出现并发修改异常,而且各个线程之间的访问不会相互阻塞。
2.3.2 数据量较小且读操作较多的场景:
由于fail-safe机制的集合类在进行读操作时不会阻塞其他线程的访问,因此适合于数据量较小且读操作较多的场景,比如缓存、配置信息等。
2.3.3 不要求强一致性的场景:
由于fail-safe机制的集合类使用了弱一致性迭代器,因此不能保证在迭代过程中能够看到所有修改之后的元素,适合于不要求强一致性的场景。
2.4. 注意:
使用fail-safe机制的集合类可能会对性能产生一定的影响,因此在对性能要求比较高的场景下,应该谨慎选择。同时,在使用fail-safe机制的集合类时,也需要注意它们的线程安全性和一致性问题。
2.5. 扩展:集合容器对比
2.5.1. ArrayList#CopyOnWriteArrayList
- ArrayList:ArrayList是一个可变数组,它的内部实现是一个数组,线程不安全,在多线程环境下要使用线程安全的集合类,比如CopyOnWriteArrayList。
2.5.2. LinkedList#CopyOnWriteArrayList
- LinkedList:LinkedList是一个链表,线程不安全,在多线程环境下要使用线程安全的集合类,比如CopyOnWriteArrayList。
2.5.3. HashMap#ConcurrentHashMap
- HashMap:HashMap是一个哈希表,线程不安全,在多线程环境下要使用线程安全的集合类,比如ConcurrentHashMap。
2.5.4. TreeMap#ConcurrentSkipListMap
- TreeMap:TreeMap是一个有序的键值对集合,线程不安全,在多线程环境下要使用线程安全的集合类,比如ConcurrentSkipListMap。
2.5.6. HashSet#ConcurrentHashMap
- HashSet:HashSet是一个哈希表,线程不安全,在多线程环境下要使用线程安全的集合类,比如ConcurrentHashMap的keySet方法返回的Set集合。
2.5.7. TreeSet#ConcurrentSkipListSet
- TreeSet:TreeSet是一个有序的集合,线程不安全,在多线程环境下要使用线程安全的集合类,比如ConcurrentSkipListSet。
六、ArrayList在多线程下如何使其线程安全
1. 使用 Vector 代替 ArrayList。
- 不推荐,Vector是一个历史遗留类。
- 具体来说,Vector是通过 synchronized 关键字来实现线程安全的,这意味着每次对Vector进行修改时,都需要获得对象级别的锁,这会导致多个线程之间频繁地竞争锁,从而降低了程序的性能。
2. 使用Collections.synchronizedList()方法。
- 该方法可以将一个非线程安全的ArrayList转换为线程安全的List,但是需要注意,对于多个并发访问的线程,需要对整个List进行同步操作。
3. 使用CopyOnWriteArrayList。
- 该类是一个线程安全的集合类,它在对集合进行修改时,会先将原来的集合复制一份,然后对复制后的集合进行修改。
- 这样可以避免竞态条件和不可见性的问题,但是会消耗额外的空间和时间开销。
4. 使用Lock。
- 可以使用java.util.concurrent.locks包中的Lock接口进行同步操作,保证多个线程对ArrayList的互斥访问。
- 但是需要注意,使用Lock可能会导致死锁等问题,需要仔细考虑锁的粒度和范围。
八、ArrayList的序列化机制
1. 自定义序列化机制 readObject、writeObject
- ArrayList通过两个方法readObject、writeObject自定义序列化和反序列化策略,实际直接使用两个流ObjectOutputStream和ObjectInputStream来进行序列化和反序列化。
2. 为什么用transient修饰elementData数组
- 出于效率的考虑,数组可能长度10,但实际只用了3个位置,剩下的7个位置空闲,其实不用序列化,这样可以提高序列化和反序列化的效率,还可以节省内存空间。





![[RockertMQ] Broker启动加载消息文件以及恢复数据源码 (三)](https://img-blog.csdnimg.cn/e7dbc98c9d944b64b7169917c3d3db57.png)