目录
- 一、注意力机制介绍
- 1、什么是注意力机制?
- 2、注意力机制的分类
- 3、注意力机制的核心
- 二、S2-MLPv2模块
- 1、 S2-MLPv2模块的原理
- 2、实验结果
- 3、应用示例
- 三、NAM模块
- 1、NAM 的原理
- 2、实验结果
- 3、应用示例
大家好,我是哪吒。
🏆本文收录于,目标检测YOLO改进指南。
本专栏均为全网独家首发,内附代码,可直接使用,改进的方法均是2023年最近的模型、方法和注意力机制。每一篇都做了实验,并附有实验结果分析,模型对比。
在机器学习和自然语言处理领域,随着数据的不断增长和任务的复杂性提高,传统的模型在处理长序列或大型输入时面临一些困难。传统模型无法有效地区分每个输入的重要性,导致模型难以捕捉到与当前任务相关的关键信息。为了解决这个问题,注意力机制(Attention Mechanism)应运而生。
一、注意力机制介绍
1、什么是注意力机制?
注意力机制(Attention Mechanism)是一种在机器学习和自然语言处理领域中广泛应用的重要概念。它的出现解决了模型在处理长序列或大型输入时的困难,使得模型能够更加关注与当前任务相关的信息,从而提高模型的性能和效果。
本文将详细介绍注意力机制的原理、应用示例以及应用示例。
2、注意力机制的分类
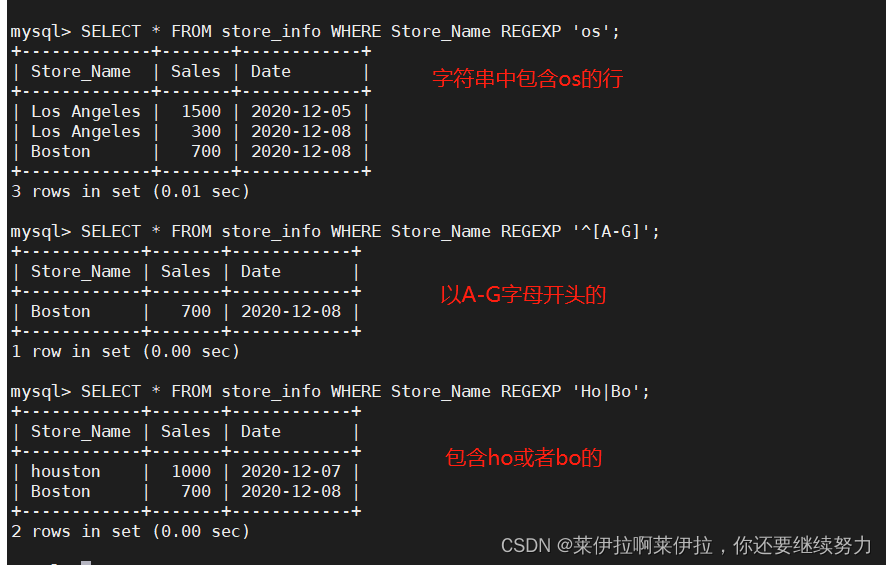
| 类别 | 描述 |
|---|---|
| 全局注意力机制(Global Attention) | 在计算注意力权重时,考虑输入序列中的所有位置或元素,适用于需要全局信息的任务。 |
| 局部注意力机制(Local Attention) | 在计算注意力权重时,只考虑输入序列中的局部区域或邻近元素,适用于需要关注局部信息的任务。 |
| 自注意力机制(Self Attention) | 在计算注意力权重时,根据输入序列内部的关系来决定每个位置的注意力权重,适用于序列中元素之间存在依赖关系的任务。 |
| Bahdanau 注意力机制 | 全局注意力机制的一种变体,通过引入可学习的对齐模型,对输入序列的每个位置计算注意力权重。 |
| Luong 注意力机制 | 全局注意力机制的另一种变体,通过引入不同的计算方式,对输入序列的每个位置计算注意力权重。 |
| Transformer 注意力机制 | 自注意力机制在Transformer模型中的具体实现,用于对输入序列中的元素进行关联建模和特征提取。 |
3、注意力机制的核心
注意力机制的核心思想是根据输入的上下文信息来动态地计算每个输入的权重。这个过程可以分为三个关键步骤:计算注意力权重、对输入进行加权和输出。首先,计算注意力权重是通过将输入与模型的当前状态进行比较,从而得到每个输入的注意力分数。这些注意力分数反映了每个输入对当前任务的重要性。对输入进行加权是将每个输入乘以其对应的注意力分数,从而根据其重要性对输入进行加权。最后,将加权后的输入进行求和或者拼接,得到最终的输出。注意力机制的关键之处在于它允许模型在不同的时间步或位置上关注不同的输入,从而捕捉到与任务相关的信息。
🏆YOLOv5/v7 添加注意力机制,30多种模块分析①,SE模块,SK模块
🏆YOLOv5/v7 添加注意力机制,30多种模块分析②,BAM模块,CBAM模块
🏆YOLOv5/v7 添加注意力机制,30多种模块分析③,GCN模块,DAN模块
🏆YOLOv5/v7 添加注意力机制,30多种模块分析④,CA模块,ECA模块
🏆YOLOv5/v7 添加注意力机制,30多种模块分析⑤,SOCA模块 ,SimAM模块
二、S2-MLPv2模块
1、 S2-MLPv2模块的原理
基于多层感知机(MLP)的视觉骨干网络开始出现。这些具有较少归纳偏见的MLP视觉架构在图像识别方面表现与CNN和Vision Transformers相当竞争力。其中,采用直接的空间位移操作的spatial-shift MLP(S2-MLP)比包括MLP-mixer和ResMLP在内的开创性作品表现更好。更近期,采用具有金字塔结构的小尺寸补丁的Vision Permutator(ViP)和Global Filter Network(GFNet)比S2-MLP表现更好。改进了S2-MLP视觉骨干网络。沿通道维度扩展特征图,并将扩展后的特征图分为几个部分。对分割部分进行不同的空间位移操作。并利用分割注意力操作来融合这些分割部分。采用小规模补丁并使用金字塔结构来提高图像识别精度。将改进的spatial-shift MLP视觉骨干网络称为S2-MLPv2。

S2-MLP和S2-MLPv2中空间平移操作的比较:在S2-MLP中,通道被平均分成四个部分,每个部分沿不同方向进行平移。然后对这些平移后的通道进行MLP操作。相反,在S2-MLPv2中,c通道特征图被扩展为3c通道特征图。然后将扩展的地图沿通道维度平均分为三个部分。对于每个部分,我们进行不同的空间平移操作。然后通过分裂-注意力操作(Zhang等人,2020)合并平移的部分以生成c通道特征图。
2、实验结果

在没有额外数据的ImageNet-1K基准测试中,与类似MLP的骨干网络的比较。S2-MLPv2-Medium/7在中等规模的MLP模型中实现了最先进的性能,甚至超过了现有的大规模MLP模型。其中,M表示百万,B表示十亿。
3、应用示例
以下是S2-MLPv2模块的应用示例:
import torch
import torch.nn as nn
class S2Module(nn.Module):
def __init__(self, channels):
super(S2Module, self).__init__()
self.fc1 = nn.Linear(channels, channels)
self.act = nn.SiLU()
self.fc2 = nn.Linear(channels, channels)
def forward(self, x):
identity = x
x = self.fc1(x)
x = self.act(x)
x = self.fc2(x)
x = torch.sigmoid(x)
return identity * x + identity
class CSPBlock(nn.Module):
def __init__(self, in_channels, out_channels, num_blocks, bottleneck_ratio=0.5):
super(CSPBlock, self).__init__()
hidden_channels = int(out_channels * bottleneck_ratio)
self.conv1 = nn.Conv2d(in_channels, hidden_channels, 1, bias=False)
self.bn1 = nn.BatchNorm2d(hidden_channels)
self.conv2 = nn.Conv2d(in_channels, hidden_channels, 1, bias=False)
self.bn2 = nn.BatchNorm2d(hidden_channels)
self.conv3 = nn.Conv2d(hidden_channels, hidden_channels, 3, padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(hidden_channels)
self.conv4 = nn.Conv2d(hidden_channels, hidden_channels, 3, padding=1, bias=False)
self.bn4 = nn.BatchNorm2d(hidden_channels)
self.conv5 = nn.Conv2d(hidden_channels, out_channels, 1, bias=False)
self.bn5 = nn.BatchNorm2d(out_channels)
self.s2module = S2Module(out_channels)
def forward(self, x):
y = self.conv1(x)
y = self.bn1(y)
y = nn.SiLU()(y)
x = self.conv2(x)
x = self.bn2(x)
x = nn.SiLU()(x)
x = torch.cat((x, y), dim=1)
x = self.conv3(x)
x = self.bn3(x)
x = nn.SiLU()(x)
x = self.conv4(x)
x = self.bn4(x)
x = nn.SiLU()(x)
x = self.conv5(x)
x = self.bn5(x)
x = self.s2module(x)
return x
在这段代码中,S2Module类定义了S2-MLPv2模块的具体实现,它包括两个全连接层和一个 sigmoid 激活函数。 CSPBlock 类是一个组合模块,它包含了两个分支(self.conv1 和 self.conv2),这些分支通过 S2-MLPv2 模块进行融合(self.s2module),最终输出的是一个合并后的张量。
三、NAM模块
1、NAM 的原理

NAMAttention是一种新型的注意力模型,其原理基于神经网络中的自注意力机制。在传统的注意力机制中,输入序列中的每个位置只能关注固定数量的其他位置。而NAMAttention则解决了这一限制,允许任意位置对所有位置进行关注。
NAMAttention的计算过程可以分为以下几步:
- 输入经过线性变换,得到查询向量Q、键向量K和值向量V。
- 使用点积注意力计算权重,即将Q和K相乘并除以一个缩放因子,再进行softmax归一化。
- 将权重与值向量V相乘,得到加权后的表示。
- 最后将加权表示通过线性变换得到输出向量。
2、实验结果

3、应用示例
以下是在使用NAMAttention模块的应用示例:
import torch
import torch.nn as nn
class NAMAttention(nn.Module):
def __init__(self, channels, reduction=4):
super(NAMAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(channels, channels // reduction, 1, bias=False)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(channels // reduction, channels, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return x * self.sigmoid(out)
class CSPBlock(nn.Module):
def __init__(self, in_channels, out_channels, num_blocks, bottleneck_ratio=0.5):
super(CSPBlock, self).__init__()
hidden_channels = int(out_channels * bottleneck_ratio)
self.conv1 = nn.Conv2d(in_channels, hidden_channels, 1, bias=False)
self.bn1 = nn.BatchNorm2d(hidden_channels)
self.conv2 = nn.Conv2d(in_channels, hidden_channels, 1, bias=False)
self.bn2 = nn.BatchNorm2d(hidden_channels)
self.conv3 = nn.Conv2d(hidden_channels, hidden_channels, 3, padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(hidden_channels)
self.conv4 = nn.Conv2d(hidden_channels, hidden_channels, 3, padding=1, bias=False)
self.bn4 = nn.BatchNorm2d(hidden_channels)
self.conv5 = nn.Conv2d(hidden_channels, out_channels, 1, bias=False)
self.bn5 = nn.BatchNorm2d(out_channels)
self.namodule = NAMAttention(out_channels)
def forward(self, x):
y = self.conv1(x)
y = self.bn1(y)
y = nn.SiLU()(y)
x = self.conv2(x)
x = self.bn2(x)
x = nn.SiLU()(x)
x = torch.cat((x, y), dim=1)
x = self.conv3(x)
x = self.bn3(x)
x = nn.SiLU()(x)
x = self.conv4(x)
x = self.bn4(x)
x = nn.SiLU()(x)
x = self.conv5(x)
x = self.bn5(x)
x = self.namodule(x)
return x
在这段代码中,NAMAttention类定义了NAMAttention模块的具体实现,它包括两个全局池化层和两个卷积层。 CSPBlock 类是一个组合模块,它包含了两个分支(self.conv1 和 self.conv2),这些分支通过 NAMAttention 模块进行融合(self.namodule),最终输出的是一个合并后的张量。
参考论文:
- https://arxiv.org/pdf/2108.01072.pdf
- https://arxiv.org/pdf/2111.12419.pdf

🏆本文收录于,目标检测YOLO改进指南。
本专栏均为全网独家首发,🚀内附代码,可直接使用,改进的方法均是2023年最近的模型、方法和注意力机制。每一篇都做了实验,并附有实验结果分析,模型对比。
🏆华为OD机试(JAVA)真题(A卷+B卷)
每一题都有详细的答题思路、详细的代码注释、样例测试,订阅后,专栏内的文章都可看,可加入华为OD刷题群(私信即可),发现新题目,随时更新,全天CSDN在线答疑。
🏆哪吒多年工作总结:Java学习路线总结,搬砖工逆袭Java架构师。
🏆往期回顾:
YOLOv5/v7 添加注意力机制,30多种模块分析①,SE模块,SK模块
YOLOv5/v7 添加注意力机制,30多种模块分析②,BAM模块,CBAM模块
YOLOv5/v7 添加注意力机制,30多种模块分析③,GCN模块,DAN模块
YOLOv5/v7 添加注意力机制,30多种模块分析④,CA模块,ECA模块
YOLOv5/v7 添加注意力机制,30多种模块分析⑤,SOCA模块 ,SimAM模块