一、计算机发展应用
神经网络主要用于特征提取
卷积神经网络主要应用在图像领域,解决传统神经网络出现的过拟合、权重太多等风险
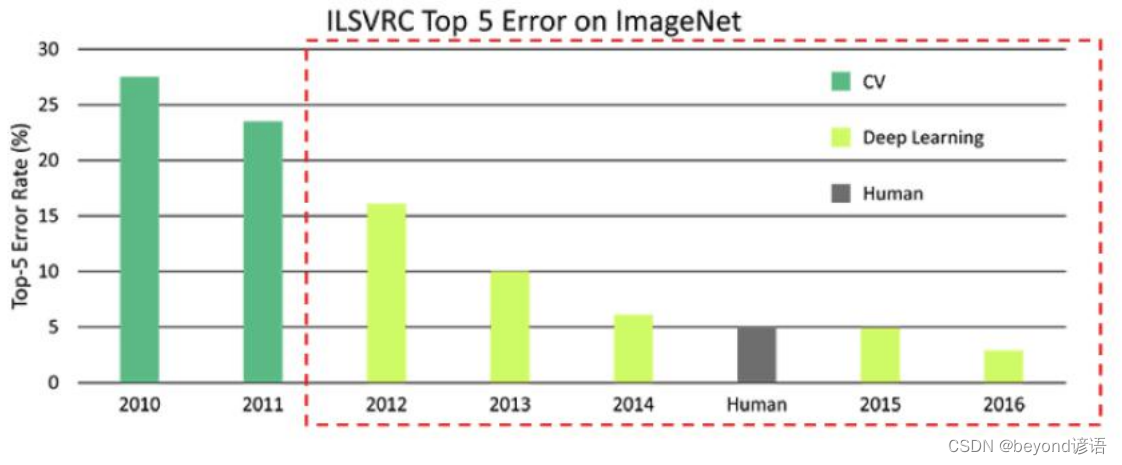
1,CV领域的发展
Computer vision计算机视觉的发展在2012年出现的AlexNet开始之后得到了挽救
之前都是一些传统的机器学习算法,但是错误率始终下不去,12年之后深度学习开始登上舞台中央,直到2016年,深度学习模型错误率已经低于人类肉眼识别水平,2017年该挑战赛达到了预期效果,就不再举办了。
2,卷积神经网络CNN应用场景
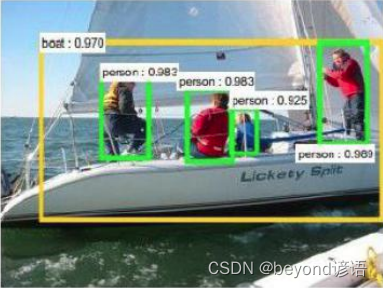
Ⅰ 检测任务
目标检测
语义分割(人、车、建筑物…)
实例分割(人a、人b、车a、车b、车c、建筑物a…)

Ⅱ 分类与检索
分类:判断这张图像是什么?

检索:输入一张图像,返回同款内容,类似于tb和jd里面的拍照购物,不知道是啥,拍照就能检索出来,也就是找相似度更接近的东西

Ⅲ 超分辨率重构
给出一张较为模糊的图像,对其进行分辨率重构,提高分辨率

Ⅳ 无人驾驶

Ⅴ 人脸识别

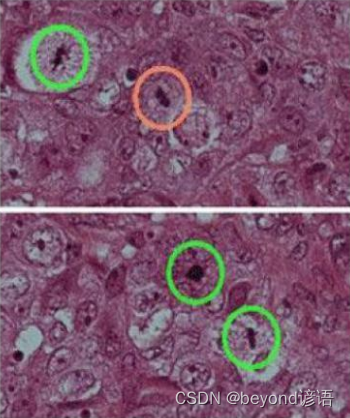
Ⅵ 其他领域应用
①细胞检测
②OCR字体识别

③标志识别

3,卷积神经网络和传统神经网络区别
传统神经网络:输入的是一列特征,需要把数据reshape成一个向量进行处理
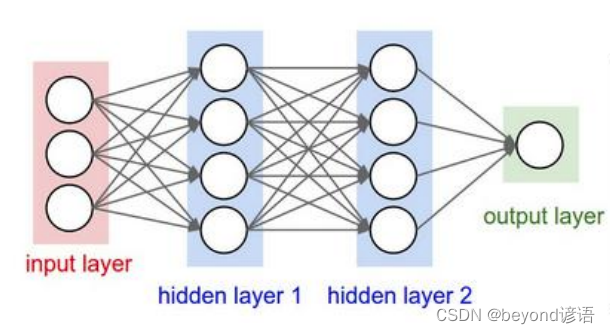
卷积神经网络:保存原有图像特征,直接进行处理
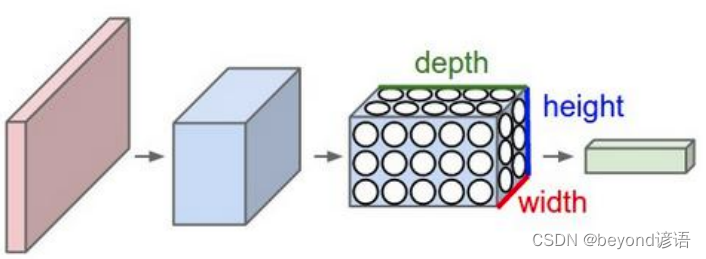
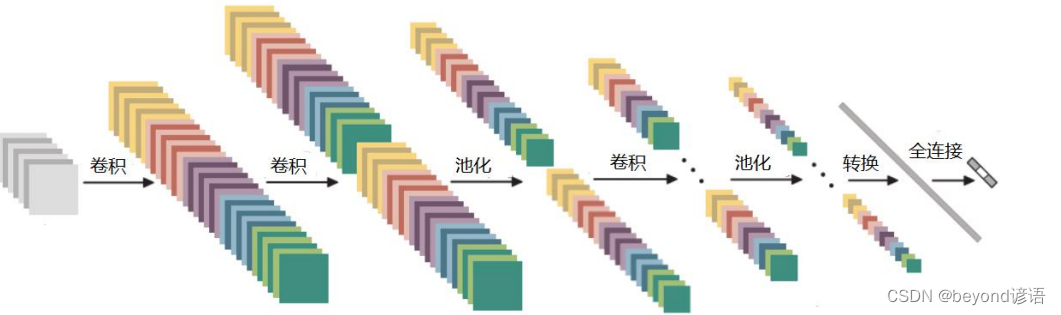
二、卷积神经网络整体架构
卷积神经网络整体架构主要包括:输入层、卷积层、池化层、全连接层
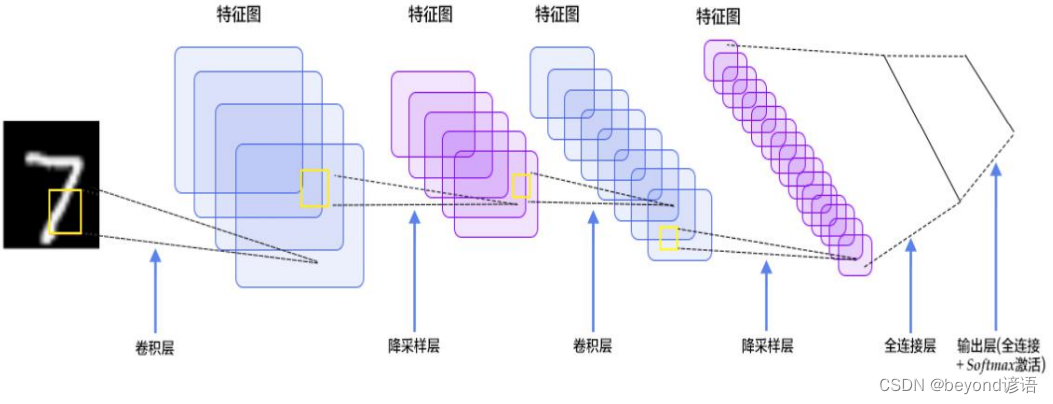
1,输入层
这个比较简单,也就是输入待训练或待检测的图像
2,卷积层
卷积操作也比较简单,这里我就不再过多赘述,只选择较为的核心内容。
卷积运算实则就是内积操作:对应元素相乘再相加
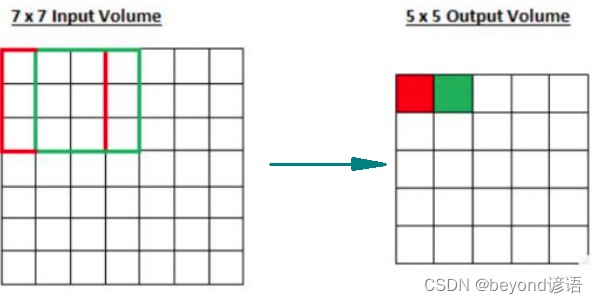
Ⅰ 滑动窗口步长
原图是7*7像素大小,卷积核大小为3*3,红色和绿色为两次卷积,滑动窗口步长为1
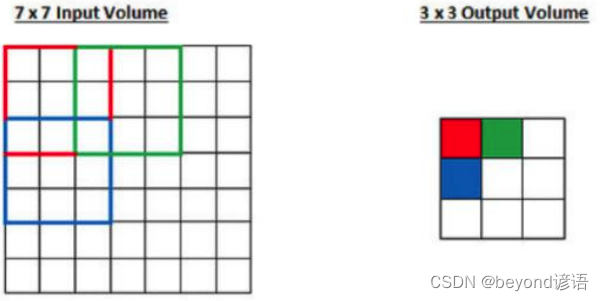
滑动窗口步长为2,也就是一行一行扫描式的进行卷积;左往右步长为2,那么上往下也是步长为2
Ⅱ 卷积核(filter)大小
一般常用的卷积核大小为3*3,当然7*7也可以,但一般都是奇数大小
卷积核的大小决定卷积之后得到的特征图的大小
Ⅲ 卷积核个数
卷积核的个数取决于卷积之后得到的特征图的深度
每个卷积核的内核均不一样
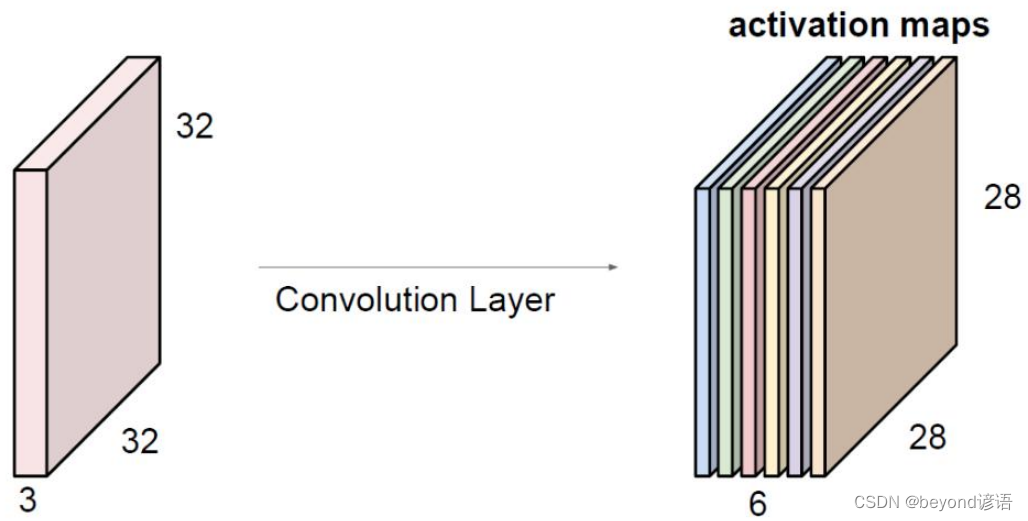
- 卷积核的大小决定[32,32]—>[28,28]
- 卷积核的个数决定最终的activation maps中的深度6
- 因为图像是3颜色通道的,故卷积核的大小也必须为3
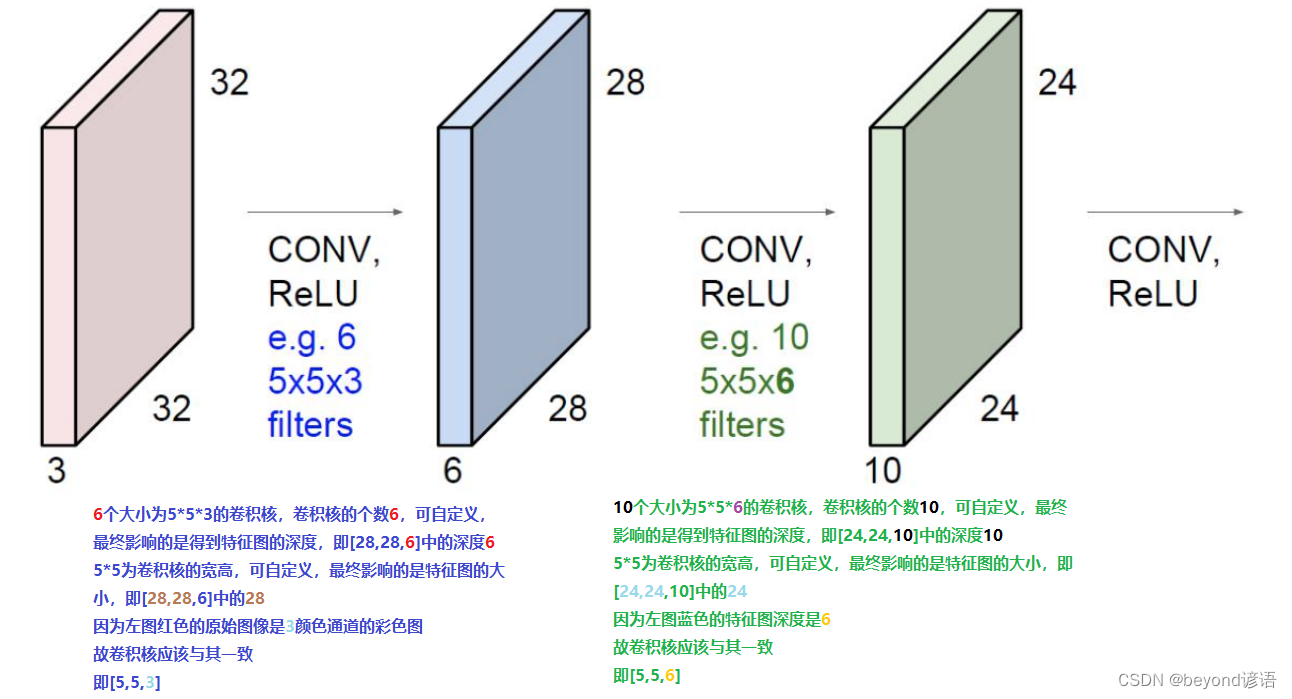
Ⅳ 边缘填充
在卷积的过程中,很容易可以看出,边缘的区域相对于中间的区域作用较小,但边缘信息也不是不重要的,故可以通过边缘填充将原先在边缘区域的信息给移到里面,从而弥补了一些边界信息缺失,对边界特征相对公平一些。
一般情况加边,加一圈全是0,加的东西不能产生其他的影响,故加0;有时为了方便计算,也可以自定义加边的圈数。

Ⅴ 卷积结果计算
PyTorch官网给的卷积结果计算公式


简化一下公式就是:

举例:输入数据为[32,32,3],使用10个[5,5,3]的卷积核进行卷积,步长为1,边界填充为2,求最终得到的特征图规模。

Ⅵ 卷积参数共享
卷积参数共享也就是说:若一张三颜色通道的彩色图像,三个通道,都使用同一个卷积核参数进行卷积。
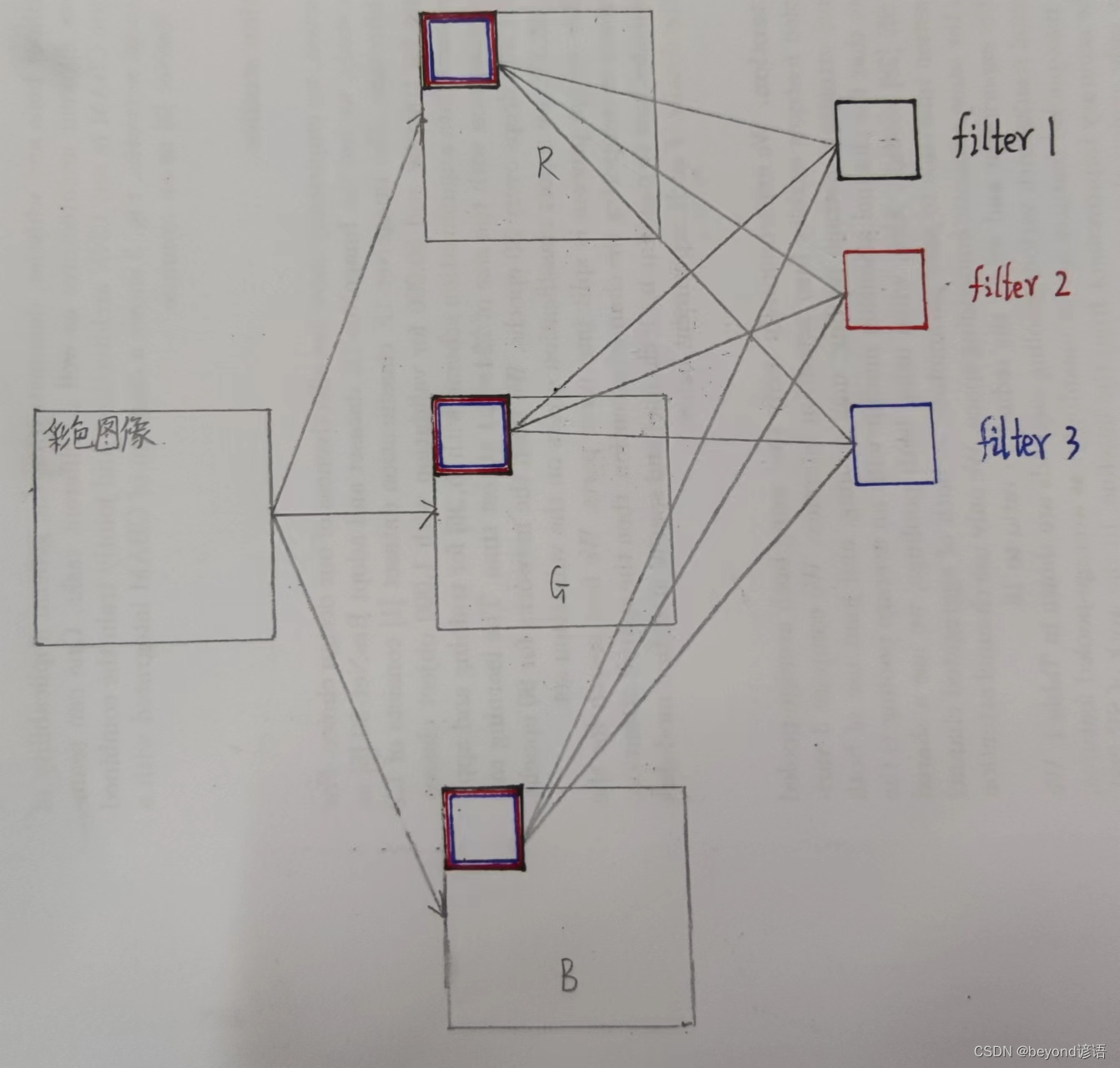
若使用10个553的卷积核filter进行卷积,5*5*3=75,每个卷积核需要75个参数,75*10=750,共10个filter,750+10=760,每个filter都有一个偏置项bias,最终需要760个权重参数。相较于全连接而言,权重少的太多了。
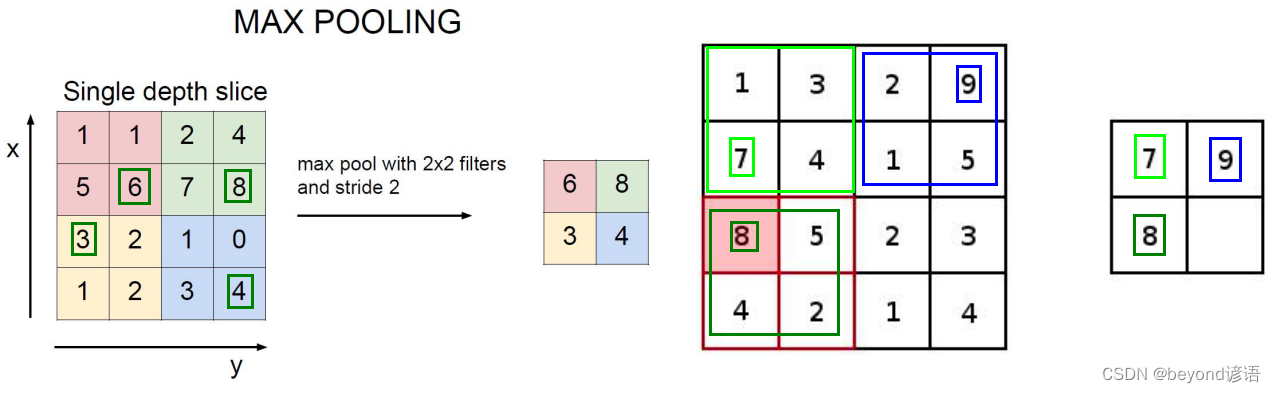
3,池化层
池化层也称下采样、压缩,其主要目的为了减少特征参数,无任何运算。
主要有:最大池化、平均池化等池化操作,其中最大池化最常用,效果也最好
4,全连接层
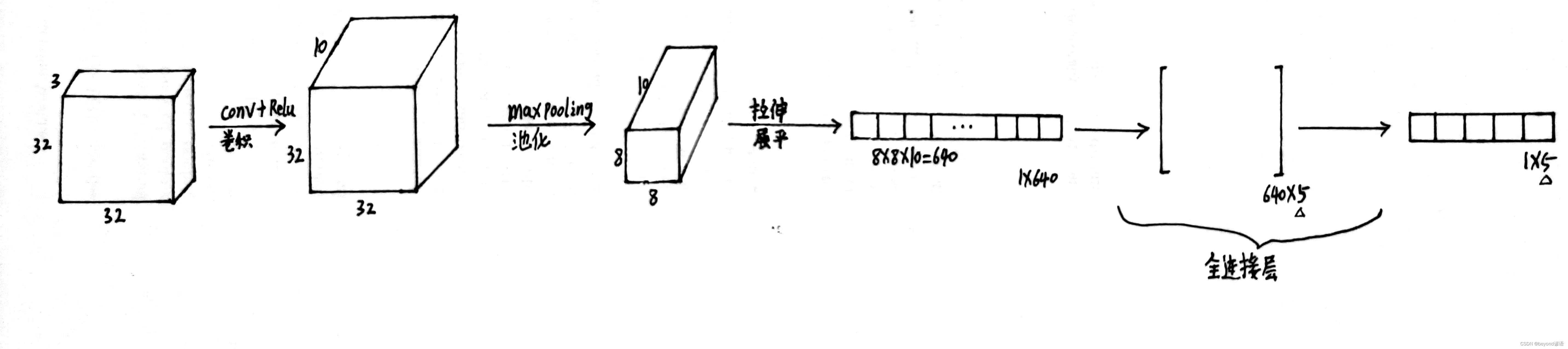
通过卷积(特征图深度增加),池化(减少特征参数)之后,得到一个三维的特征图,此时需要将该特征图进行拉长成一行向量的形式,最后再接FC全连接层根据实际的情况进行输出。
举例:最终归为5分类任务,即最后得到5个结果的概率值









![Goby 漏洞发布|WordPress Extensive VC Addons 插件 options[template] 文件包含漏洞](https://img-blog.csdnimg.cn/4d9de0eda6aa43c49040c054865d3163.gif#pic_center)