目录标题
- 前言
- 环境使用:
- 模块使用:
- python技术实现: <基本流程步骤>
- 代码展示
- 尾语
前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

环境使用:
-
Python 3.8
-
jupyter --> pip install jupyter notebook
-
pycharm 也可以
模块使用:
-
requests >>> pip install requests 数据请求模块
-
parsel >>> pip install parsel 数据解析模块
-
csv 内置模块
第三方模块安装:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
如果出现爆红, 可能是因为 网络连接超时, 可切换国内镜像源,命令如下:
pip install -i https://pypi.doubanio.com/simple/ requests
python资料、源码、教程\福利皆: 点击此处跳转文末名片获取
python技术实现: <基本流程步骤>
-
发送请求, 模拟浏览器对于url地址发送请求
请求链接地址: https://cs.****.com/ershoufang/
-
获取数据, 获取响应数据
获取数据: 网页源代码 <整个网页数据内容>
-
解析数据, 提取我们需要数据
提取数据: 房源基本信息
-
保存数据, 把数据保存本地文件
保存数据: csv表格文件当中
-
多页数据采集
代码展示
获取数据:
# 导入csv模块
import csv
# 创建文件
f = open('data.csv', mode='w', encoding='utf-8', newline='')
# 添加字段名
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'小区',
'区域',
'总价',
'单价',
'户型',
'面积',
'朝向',
'装修',
'楼层',
'年份',
'建筑结构',
'详情页'
])
# 写表头
csv_writer.writeheader()
# 导入数据解析模块 第三方模块, 需要安装
import parsel
# 导入数据请求模块 第三方模块 需要安装 pip install requests
import requests
for page in range(1, 101):
# 请求链接
url = f'https://cs.lianjia.com/ershoufang/pg{page}/'
# 伪装浏览器 --> headers 请求头
headers = {
# User-Agent 用户代理 表示浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url, headers=headers)
html_data = response.text # <Response [200]> 响应对象 表示请求成功
# 把获取下来 html字符串数据内容 <html_data>, 转成可解析对象
selector = parsel.Selector(html_data)
"""
selector <Selector xpath=None data='<html class=""><head><meta http-equiv...'> 选择器对象
selector.css() 根据标签属性提取数据内容
selector.xpath()
"""
# 提取所有li标签里面房源信息 --> 返回列表, 列表里面元素是选择器对象
lis = selector.css('.sellListContent li .info')
# for循环遍历, 提取出来, 然后也可以使用css语法或者xpath语法 提取具体数据内容
for li in lis:
"""
get() 获取第一个标签数据内容 <返回字符串>
getall() 获取所有标签数据内容 <返回列表>
strip() 去除字符串左右两端空格
replace('元/平', '') 字符串替换, 把字符串当中 元/平 替换成 '' --> 相当于删除
split(' | ') 字符串分割犯法, 把字符串以 | 作为切割, 分割成列表
"""
title = li.css('.title a::text').get() # 标题
info = li.css('.positionInfo a::text').getall()
area = info[0].strip() # 列表第一个元素 小区
area_1 = info[1] # 区域
totalPrice = li.css('.totalPrice span::text').get() # 总价
unitPrice = li.css('.unitPrice span::text').get().replace('元/平', '') # 单价
houseInfo = li.css('.houseInfo::text').get().split(' | ')
"""
有年份, 列表元素就是7个, 没有年份列表元素6个
"""
house_type = houseInfo[0] # 户型
house_area = houseInfo[1] # 面积
face = houseInfo[2] # 朝向
house = houseInfo[3] # 装修
fool = houseInfo[4] # 楼层
if len(houseInfo) == 7:
date = houseInfo[5] # 年份
house_1 = houseInfo[6] # 建筑结构
elif len(houseInfo) == 6:
date = '未知'
house_1 = houseInfo[-1] # 建筑结构
href = li.css('.title a::attr(href)').get() # 详情页
# 保存字典里面
dit = {
'标题': title,
'小区': area,
'区域': area_1,
'总价': totalPrice,
'单价': unitPrice,
'户型': house_type,
'面积': house_area,
'朝向': face,
'装修': house,
'楼层': fool,
'年份': date,
'建筑结构': house_1,
'详情页': href,
}
# csv_writer.writerow(dit)
# print(dit)
# print(title, area, area_1, totalPrice, unitPrice, house_type, house_area, face, house, fool, date, house_1, sep='|')
数据可视化:
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
df.head()
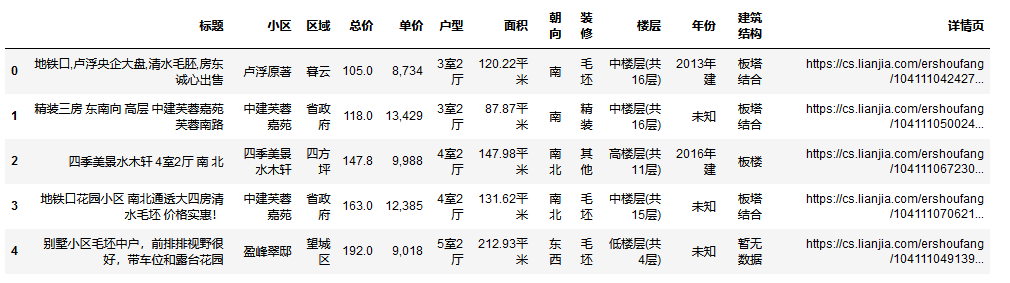
house_type_num = df['户型'].value_counts().to_list()
house_type = df['户型'].value_counts().index.to_list()
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
c = (
Pie()
.add("", [list(z) for z in zip(house_type, house_type_num)])
.set_global_opts(title_opts=opts.TitleOpts(title="二手房源户型"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.load_javascript()
c.render_notebook()
house_num = df['装修'].value_counts().to_list()
house_type_1 = df['装修'].value_counts().index.to_list()
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
c = (
Pie()
.add("", [list(z) for z in zip(house_type_1, house_num)])
.set_global_opts(title_opts=opts.TitleOpts(title="二手房源装修占比分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()
date_num = df['年份'].value_counts().to_list()
date_type = df['年份'].value_counts().index.to_list()
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
c = (
Pie()
.add("", [list(z) for z in zip(date_type, date_num)])
.set_global_opts(title_opts=opts.TitleOpts(title="二手房源年份占比分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()
df.head()
尾语
感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。

![[建议收藏] Mysql+ETLCloud CDC+Doris实时数仓同步实战](https://img-blog.csdnimg.cn/fd2c0ab9820443faa67d994272223b70.png)