CUDA introduction

文章目录
- CUDA introduction
- 异构计算架构
- 典型的CUDA程序的执行流程
- 函数类型限定词
- Kernel 线程层次结构
- 线程ID号计算:
- Example
- 加法实例
- 托管内存
- 乘法
- 性能分析工具 Nsight System
- 功能
- 用法
- Reference
- 欢迎关注公众号【三戒纪元】
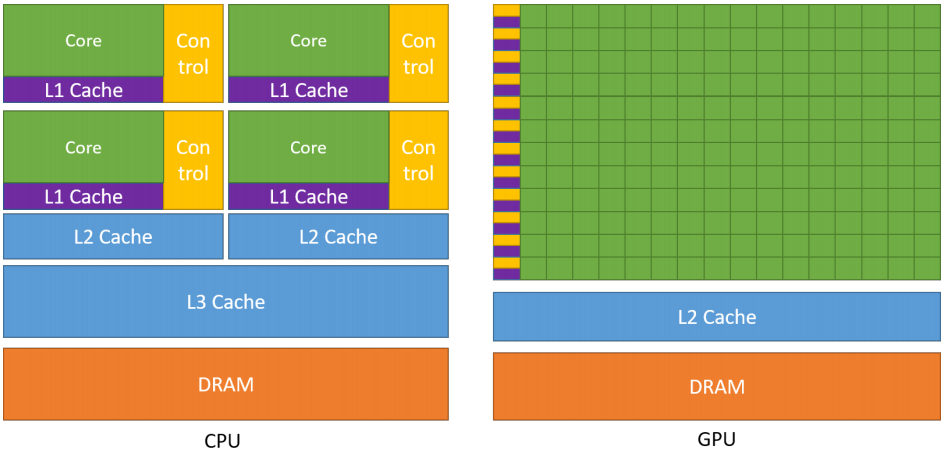
异构计算架构
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。
在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)
| 特点 | CPU | GPU |
|---|---|---|
| 运算核心 | 运算核心少,但可以实现复杂的逻辑运算,适合控制密集型任务 | 运算核心数多,适合数据并行的计算密集型任务,如大型矩阵运算 |
| 线程 | 线程是重量级的,上下文切换开销大 | 多核心,因此线程是轻量级的 |
典型的CUDA程序的执行流程
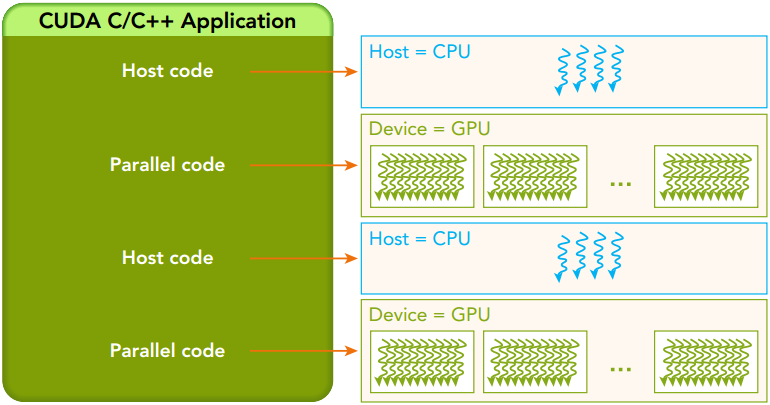
CUDA编程模型是一个异构模型,需要CPU和GPU协同工作。
在CUDA中,host和device是两个重要的概念,我们用host指代CPU及其内存,而用device指代GPU及其内存。
CUDA程序中既包含host程序,又包含device程序,它们分别在CPU和GPU上运行。
同时,host与device之间可以进行通信,这样它们之间可以进行数据拷贝
函数类型限定词
__global__: 在device上执行函数,从host 中调用(特定GPU也从device调用)。返回类型必须是void,不支持可变参数,不能是类成员函数。host不会等待kernel执行完就执行下一步。__device__:在device上执行,尽可以从device中调用,不可与__global__同时使用。__host__:在host上执行且仅可以从host中调用,一般省略。不可与__global__同时使用,但可以和__device__同时使用,此时函数会在device 和 host 都编译。
Kernel 线程层次结构
GPU是并行化的轻量级线程,而kernel在device上执行时,是启动了多个线程。
层次1:1个kernel启动的所有线程称为1个网格(Grid),同1个grid共享相同的全局内存空间
层次2:grid可以氛围很多线程块(block),1个block包含多个线程thread
下图是1个grid和block均为2-dim的线程组织。
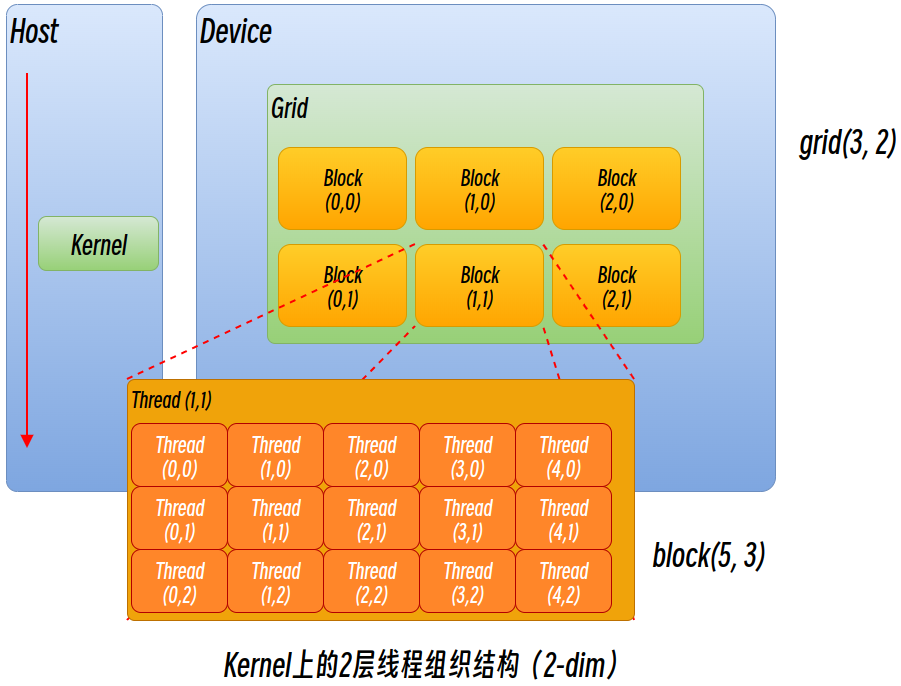
grid和block都是定义为dim3类型的变量,可看成是3个无符号整数(x,y,z)成员的结构体变量,定义时初始化为1.
dim3 grid(3, 5);
dim3 block(6, 3);
kernel_fun<<< grid, block >>>(prams...);
// 上图:
threadIdx.x = 1
threadIdx.y = 1
blockIdx.x = 1
blockIdx.y = 1
grid和block可以灵活地定义为 1-dim, 2-dim以及3-dim结构。
可以通过执行配置<<<grid, block>>>指定kernel所使用的线程数及结构。
想象着grid就是一栋办公大楼,大楼内部有很多部门,每个部门又有很多办公室,根据部门楼层、办公室门牌号就能够找到相应的线程。
线程ID号计算:
2-dim的block( D x , D y D_x, D_y Dx,Dy),线程(x,y)的ID值为( x + y ∗ D x x+y*D_x x+y∗Dx)
3-dim的block( D x , D y , D z D_x, D_y, D_z Dx,Dy,Dz),线程(x,y,z)的ID值为( x + y ∗ D x + z ∗ D x ∗ D y x+y*D_x+z*D_x*D_y x+y∗Dx+z∗Dx∗Dy)
线程还有内置变量gridDim,用于获得网格块各个维度的大小
因此,kernel这种线程组织结构非常适合 vector、matrix等运算,如果利用上图2-dim的结构实现2个矩阵加法,每个线程负责处理每个位置的2个元素相加,代码如下:
// Kernel定义
__global__ void MatrixAdd(float A[N][N], float B[N][N], float Randy[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
Randy[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel 线程配置
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// kernel调用
MatrixAdd<<<numBlocks, threadsPerBlock>>>(A, B, Randy);
...
}
Example
加法实例
- 在device上分配内存的cudaMalloc 函数:
/**
* \brief Allocate an array on the device
*
* \p width and \p height must meet certain size requirements. See ::cudaMalloc3DArray() for more details.
*
* \param array - Pointer to allocated array in device memory
* \param desc - Requested channel format
* \param width - Requested array allocation width
* \param height - Requested array allocation height
* \param flags - Requested properties of allocated array
*
* \return
* ::cudaSuccess,
* ::cudaErrorInvalidValue,
* ::cudaErrorMemoryAllocation
extern __host__ cudaError_t CUDARTAPI cudaMallocArray(cudaArray_t *array, const struct cudaChannelFormatDesc *desc, size_t width, size_t height __dv(0), unsigned int flags __dv(0));
其中 p指向所分配内存的指针,s 为内存大小。
-
释放分配的内存
/** * \brief Frees memory on the device * * \param devPtr - Device pointer to memory to free * * \return * ::cudaSuccess, * ::cudaErrorInvalidValue * \notefnerr * \note_init_rt * \note_callback extern __host__ __cudart_builtin__ cudaError_t CUDARTAPI cudaFree(void *devPtr); -
负责host和device之间数据通信的cudaMemcpy函数:
/** * \brief Copies data between host and device * * * \param dst - Destination memory address * \param src - Source memory address * \param count - Size in bytes to copy * \param kind - Type of transfer * * \return * ::cudaSuccess, * ::cudaErrorInvalidValue, * ::cudaErrorInvalidMemcpyDirection * \notefnerr * \note_init_rt * \note_callback * extern __host__ cudaError_t CUDARTAPI cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind); -
加法计算代码:
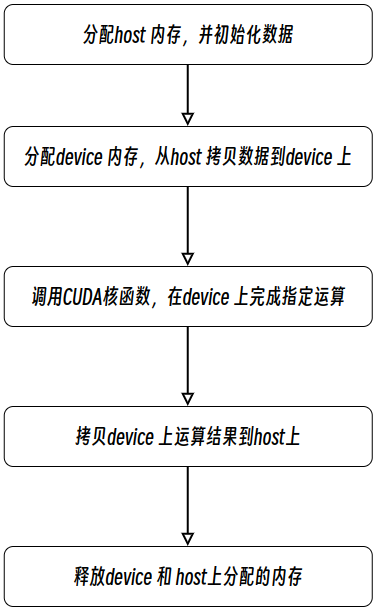
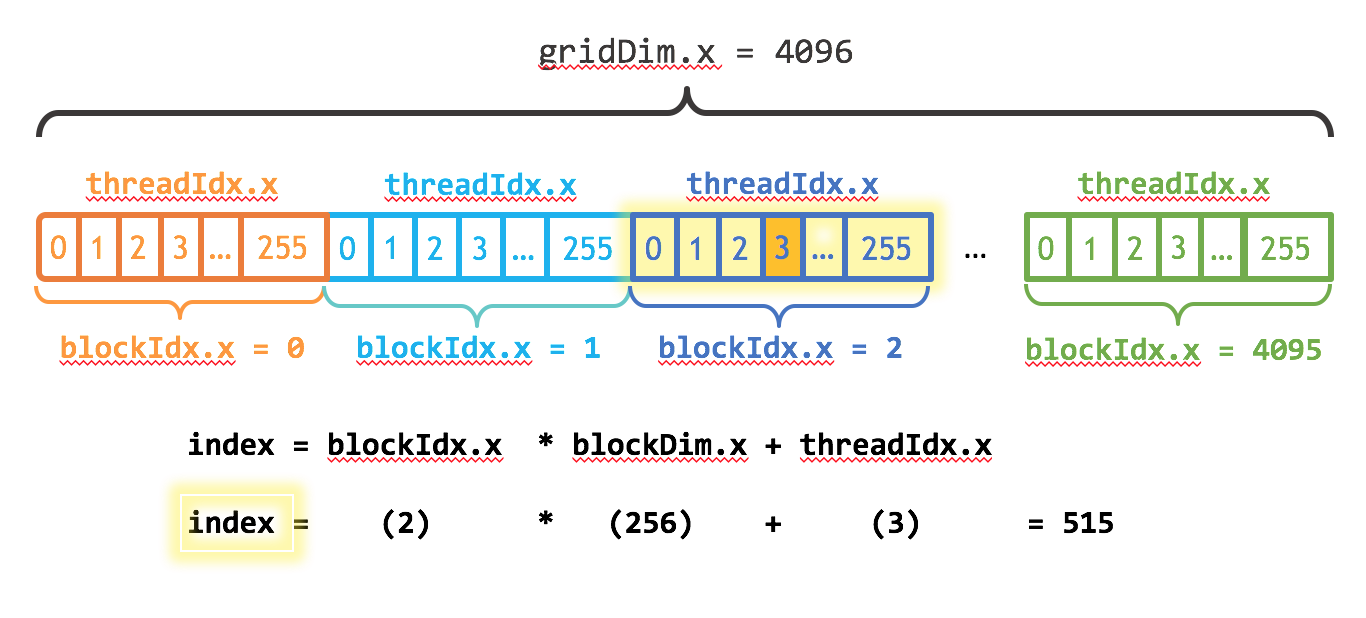
#include <cuda.h> #include <iostream> // 两个向量加法kernel,grid和block均为一维 __global__ void add(float* x, float * y, float* z, int n) { // 获取全局索引 int index = threadIdx.x + blockIdx.x * blockDim.x; // 步长 int stride = blockDim.x * gridDim.x; for (int i = index; i < n; i += stride) { z[i] = x[i] + y[i]; } } int main() { int N = 1 << 20; std::cout << "N: " << N << std::endl; // N: 1048576 int nBytes = N * sizeof(float); std::cout << "nBytes: " << nBytes << std::endl; // nBytes: 4194304 // 申请host内存 float *x, *y, *z; x = (float*)malloc(nBytes); y = (float*)malloc(nBytes); z = (float*)malloc(nBytes); // 初始化数据 for (int i = 0; i < N; ++i) { x[i] = 10.0; y[i] = 20.0; } // 申请device内存 float *d_x, *d_y, *d_z; cudaMalloc((void**)&d_x, nBytes); cudaMalloc((void**)&d_y, nBytes); cudaMalloc((void**)&d_z, nBytes); // 将host数据拷贝到device cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice); cudaMemcpy((void*)d_y, (void*)y, nBytes, cudaMemcpyHostToDevice); // 定义kernel的执行配置 dim3 blockSize(256); std::cout << "blockSize.x: " << blockSize.x << std::endl; // blockSize.x: 256 std::cout << "blockSize.y: " << blockSize.y << std::endl; // blockSize.y: 1 std::cout << "blockSize.z: " << blockSize.z << std::endl; // blockSize.z: 1 std::cout << "(N + blockSize.x - 1): " << (N + blockSize.x - 1) << std::endl; // (N + blockSize.x - 1): 1048831 std::cout << "(N + blockSize.x - 1) / blockSize.x: " << (N + blockSize.x - 1) / blockSize.x << std::endl; // (N + blockSize.x - 1) / blockSize.x: 4096 dim3 gridSize((N + blockSize.x - 1) / blockSize.x); // 执行kernel add << < gridSize, blockSize >> >(d_x, d_y, d_z, N); // 将device得到的结果拷贝到host cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyDeviceToHost); // 检查执行结果 float maxError = 0.0; for (int i = 0; i < N; i++){ std::cout << "z["<< i << "]: " << z[i] << std::endl; maxError = fmax(maxError, fabs(z[i] - 30.0)); } std::cout << "Max error: " << maxError << std::endl; // Max error: 0 // 释放device内存 cudaFree(d_x); cudaFree(d_y); cudaFree(d_z); // 释放host内存 free(x); free(y); free(z); return 0; }这里向量大小为1<<20(1048576),而block大小为256,那么grid大小是4096,kernel的线程层级结构如下图所示:
托管内存
CUDA 使用一个托管内存来共同管理host和device中的内存,并且自动在host和device中进行数据传输。
CUDA中使用cudaMallocManaged函数分配托管内存:
cudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned int flag=0);上述程序可以简化为:
int main() { int N = 1 << 20; int nBytes = N * sizeof(float); // 申请托管内存 float *x, *y, *z; cudaMallocManaged((void**)&x, nBytes); cudaMallocManaged((void**)&y, nBytes); cudaMallocManaged((void**)&z, nBytes); // 初始化数据 for (int i = 0; i < N; ++i) { x[i] = 10.0; y[i] = 20.0; } // 定义kernel的执行配置 dim3 blockSize(256); dim3 gridSize((N + blockSize.x - 1) / blockSize.x); // 执行kernel add << < gridSize, blockSize >> >(x, y, z, N); // 同步device 保证结果能正确访问 cudaDeviceSynchronize(); // 检查执行结果 float maxError = 0.0; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(z[i] - 30.0)); std::cout << "最大误差: " << maxError << std::endl; // 释放内存 cudaFree(x); cudaFree(y); cudaFree(z); return 0; }kernel执行是与host异步的,由于托管内存自动进行数据传输,这里要用cudaDeviceSynchronize()函数保证device和host同步。
乘法
#include <cuda.h>
#include <cuda_runtime.h>
#include <iostream>
// 矩阵类型,行优先,M(row, col) = *(M.elements + row * M.width + col)
struct Matrix {
int width;
int height;
float *elements;
};
// 获取矩阵A的(row, col)元素
__device__ float getElement(Matrix *A, int row, int col) {
return A->elements[row * A->width + col];
}
// 为矩阵A的(row, col)元素赋值
__device__ void setElement(Matrix *A, int row, int col, float value) {
A->elements[row * A->width + col] = value;
}
// 矩阵相乘kernel,2-D,每个线程计算一个元素
__global__ void matMulKernel(Matrix *A, Matrix *B, Matrix *C) {
float Cvalue = 0.0;
int row = threadIdx.y + blockIdx.y * blockDim.y;
int col = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = 0; i < A->width; ++i) {
Cvalue += getElement(A, row, i) * getElement(B, i, col);
}
setElement(C, row, col, Cvalue);
}
int main() {
int width = 1 << 10;
int height = 1 << 10;
std::cout << width << ", " << height << std::endl; // 1024, 1024
Matrix *A, *B, *C;
// 申请托管内存
cudaMallocManaged((void **)&A, sizeof(Matrix));
cudaMallocManaged((void **)&B, sizeof(Matrix));
cudaMallocManaged((void **)&C, sizeof(Matrix));
int nBytes = width * height * sizeof(float);
cudaMallocManaged((void **)&A->elements, nBytes);
cudaMallocManaged((void **)&B->elements, nBytes);
cudaMallocManaged((void **)&C->elements, nBytes);
// 初始化数据
A->height = height;
A->width = width;
B->height = height;
B->width = width;
C->height = height;
C->width = width;
for (int i = 0; i < width * height; ++i) {
A->elements[i] = 1.0;
B->elements[i] = 2.0;
}
// 定义kernel的执行配置
dim3 blockSize(32, 32);
std::cout << "blockSize.x: " << blockSize.x << std::endl; // blockSize.x: 32
std::cout << "width: " << width << std::endl; // width: 1024
std::cout << "(width + blockSize.x - 1): " << (width + blockSize.x - 1)
<< std::endl; // (width + blockSize.x - 1): 1055
std::cout << "(width + blockSize.x - 1) / blockSize.x: "
<< (width + blockSize.x - 1) / blockSize.x
<< std::endl; // (width + blockSize.x - 1) / blockSize.x: 32
dim3 gridSize((width + blockSize.x - 1) / blockSize.x,
(height + blockSize.y - 1) / blockSize.y);
// 执行kernel
matMulKernel<<<gridSize, blockSize>>>(A, B, C);
// 同步device 保证结果能正确访问
cudaDeviceSynchronize();
// 检查执行结果
float maxError = 0.0;
for (int i = 0; i < width * height; ++i)
maxError = fmax(maxError, fabs(C->elements[i] - 2 * width));
std::cout << "最大误差: " << maxError << std::endl; // 最大误差: 0
return 0;
}
性能分析工具 Nsight System
功能
usage: nsys [--version] [--help] <command> [<args>] [application] [<application args>]
The most commonly used nsys commands are:
profile Run an application and capture its profile into a QDSTRM file.
launch Launch an application ready to be profiled.
start Start a profiling session.
stop Stop a profiling session and capture its profile into a QDSTRM file.
cancel Cancel a profiling session and discard any collected data.
stats Generate statistics from an existing QDREP or SQLite file.
status Provide current status of CLI or the collection environment.
shutdown Disconnect launched processes from the profiler and shutdown the profiler.
sessions list List active sessions.
export Export QDREP file into another format.
nvprof Translate nvprof switches to nsys switches and execute collection.
Use 'nsys --help <command>' for more information about a specific command.
To run a basic profiling session: nsys profile ./my-application
For more details see "Profiling from the CLI" at https://docs.nvidia.com/nsight-systems
用法
nsys profile --stats=true ./randy
Processing [==============================================================100%]
Saved report file to "/tmp/nsys-report-d411-abfb-46e3-5075.qdrep"
Exporting 3343 events: [==================================================100%]
Exported successfully to
/tmp/nsys-report-d411-abfb-46e3-5075.sqlite
Generating CUDA API Statistics...
CUDA API Statistics (nanoseconds)
Time(%) Total Time Calls Average Minimum Maximum Name
------- -------------- ---------- -------------- -------------- -------------- --------------------------------------------------------------------------------
96.6 74091546 3 24697182.0 32580 74025890 cudaMalloc
2.7 2052619 3 684206.3 377277 1288879 cudaMemcpy
0.7 504217 3 168072.3 135789 203486 cudaFree
0.0 19610 1 19610.0 19610 19610 cudaLaunchKernel
Generating CUDA Kernel Statistics...
CUDA Kernel Statistics (nanoseconds)
Time(%) Total Time Instances Average Minimum Maximum Name
------- -------------- ---------- -------------- -------------- -------------- --------------------------------------------------------------------------------------------------------------------
100.0 36193 1 36193.0 36193 36193 add(float*, float*, float*, int)
Generating CUDA Memory Operation Statistics...
CUDA Memory Operation Statistics (nanoseconds)
Time(%) Total Time Operations Average Minimum Maximum Name
------- -------------- ---------- -------------- -------------- -------------- --------------------------------------------------------------------------------
51.9 689203 1 689203.0 689203 689203 [CUDA memcpy DtoH]
48.1 638162 2 319081.0 313481 324681 [CUDA memcpy HtoD]
CUDA Memory Operation Statistics (KiB)
Total Operations Average Minimum Maximum Name
------------------- -------------- ------------------- ----------------- ------------------- --------------------------------------------------------------------------------
8192.000 2 4096.000 4096.000 4096.000 [CUDA memcpy HtoD]
4096.000 1 4096.000 4096.000 4096.000 [CUDA memcpy DtoH]
Reference
CUDA编程入门极简教程