目录
- 前言
- 一、HyperTS介绍
- 二、HyperTS安装、使用
- 2-1、安装
- 2-2、HyperTS使用
- 三、案例
- 3-0、通用工作流程
- 3-1、时间序列预测
- 3-2、时间序列分类
- 3-3、时间序列异常检测
- 四、高级应用
- 4-1、模型的保存和加载
- 总结
前言
HyperTS是一个开源的时间序列分析库,主要用于处理和分析时间序列数据。一、HyperTS介绍
HyperTS是一个开源的时间序列分析库,是 DataCanvas Automatic Toolkits(DAT) 针对于 时间序列 任务推出了一款涵盖 自动机器学习(AutoML) 与 自动深度学习(AutoDL) 的全Pipeline学习工具。主要用于处理和分析时间序列数据。它提供了一系列功能强大的工具和算法,它涵盖了数据清洗、数据预处理、特征工程、模型选择、超参数优化、模型评估、预测可视化等一系列自动化的操作, 轻松几行代码便可以完全 端到端 地处理多种场景下的时间序列任务。
以下是关于HyperTS的一些详细介绍:
- HyperTS支持常见的时间序列分析任务,如平滑、滞后、差分等。它提供了一系列的函数和方法,可以方便地对时间序列数据进行处理和转换。例如,你可以使用smooth函数对时间序列进行平滑处理,使用lag函数对时间序列进行滞后处理。
- HyperTS提供了多种特征提取方法,用于从时间序列中提取有用的特征。这些特征可以用于构建机器学习模型和预测任务。例如,你可以使用autocorrelation函数计算自相关系数,使用fft函数进行快速傅里叶变换,以及使用wavelet函数进行小波变换。
- HyperTS支持多种常见的时间序列模型,如ARIMA、GARCH、VAR等。这些模型可以用于时间序列的建模和预测。例如,你可以使用arima函数建立ARIMA模型,使用garch函数建立GARCH模型,以及使用var函数建立VAR模型。
- HyperTS还提供了一些评估指标和可视化工具,用于评估模型的性能和结果的可视化。例如,你可以使用mse函数计算均方误差,使用plot函数绘制时间序列的图表。
总的来说,HyperTS是一个功能强大的时间序列分析库,可以帮助你处理和分析时间序列数据。你可以使用它进行时间序列的预处理、特征提取、模型建立和预测等任务。
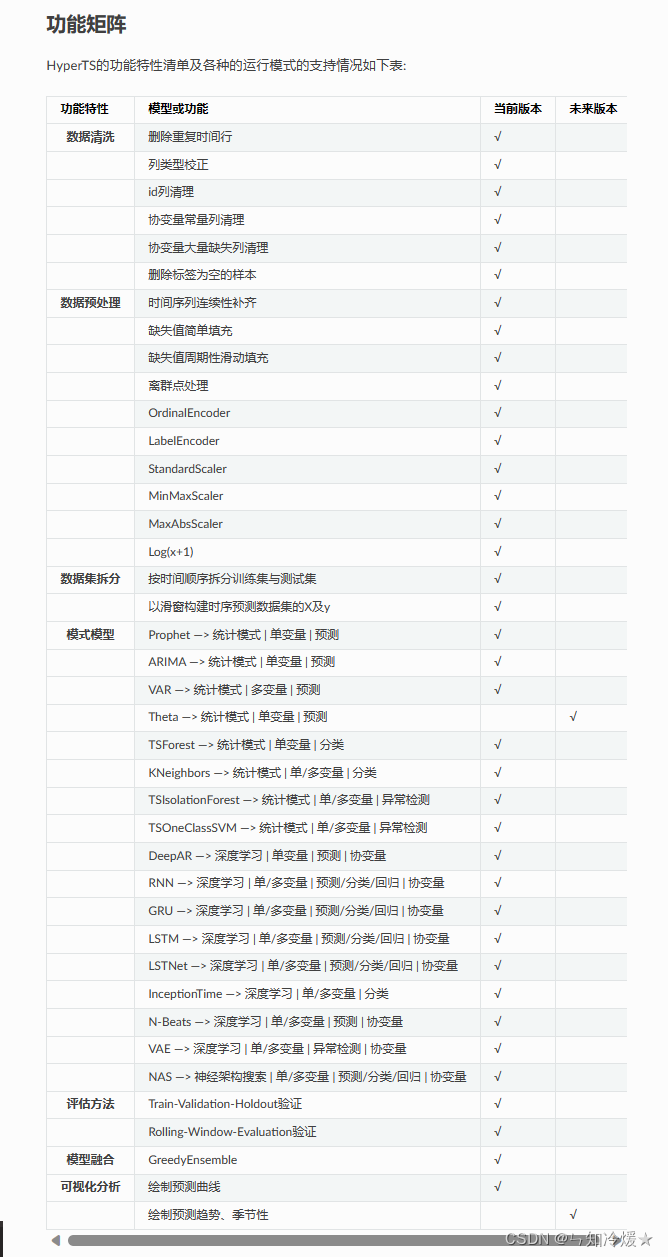
HyperTS的功能特性清单如下:
二、HyperTS安装、使用
2-1、安装
安装:
pip install prophet
pip install hyperts
可能会发生的是Numpy版本的一个兼容问题,更新Numpy:
pip install --upgrade numpy
**其他:可选择安装tensorflow **:
# 如果使用到深度学习时,需要安装
pip install tensorflow
2-2、HyperTS使用
主要是通过make_experiment函数来训练一个模型:
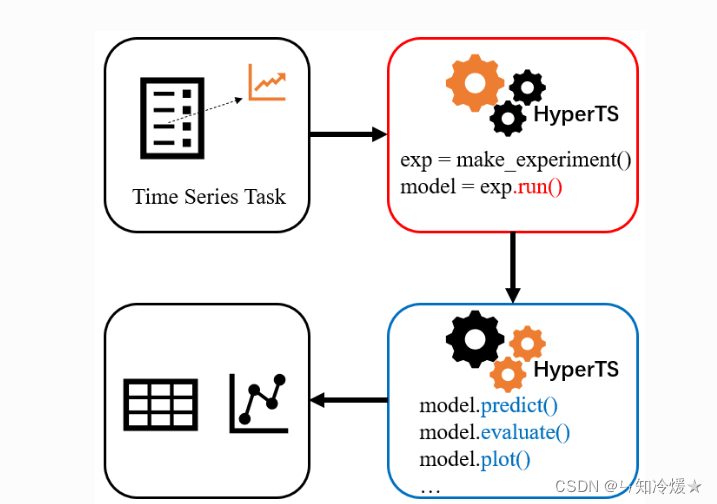
- Time Series Task:确定时间序列任务是什么,输入规范后的数据,确定相对应的模型。
- make_experiment: 通过make_experiment函数的训练,run之后最终得到了一个训练好的模型。
- predict、evaluate: 使用训练好的模型,去做预测任务、评估模型性能以及作图等。
三、案例
3-0、通用工作流程
通用工作流程:
- 导入所需要的库
- 加载数据集
- 使用train_test_split来分割训练集和验证集。
- 使用make_experiment函数来创建实验,确定任务、数据、模型,进行训练,run之后得到训练后的模型。
- 评估模型。
其他注意事项:
- 对于划分训练集和测试集,由于数据存在时间上的先后顺序,因此为了防止信息的泄露,我们设置shuffle=False,即不打乱数据集。
3-1、时间序列预测
时间序列预测: 在时间序列任务中,我们除了按照惯例的流程外,我们还需要向make_experiment中传入参数timestamp,即指定时间戳。如果存在协同变量,我们也需要指定协同变量covariates。
from hyperts import make_experiment
from hyperts.datasets import load_network_traffic
from sklearn.model_selection import train_test_split
data = load_network_traffic()
train_data, test_data = train_test_split(data, test_size=0.2, shuffle=False)
model = make_experiment(train_data.copy(),
task='multivariate-forecast',
mode='stats',
timestamp='TimeStamp',
covariates=['HourSin', 'WeekCos', 'CBWD']).run()
X_test, y_test = model.split_X_y(test_data.copy())
# 使用predict方法来执行结果的预测。
y_pred = model.predict(X_test)
scores = model.evaluate(y_test, y_pred)
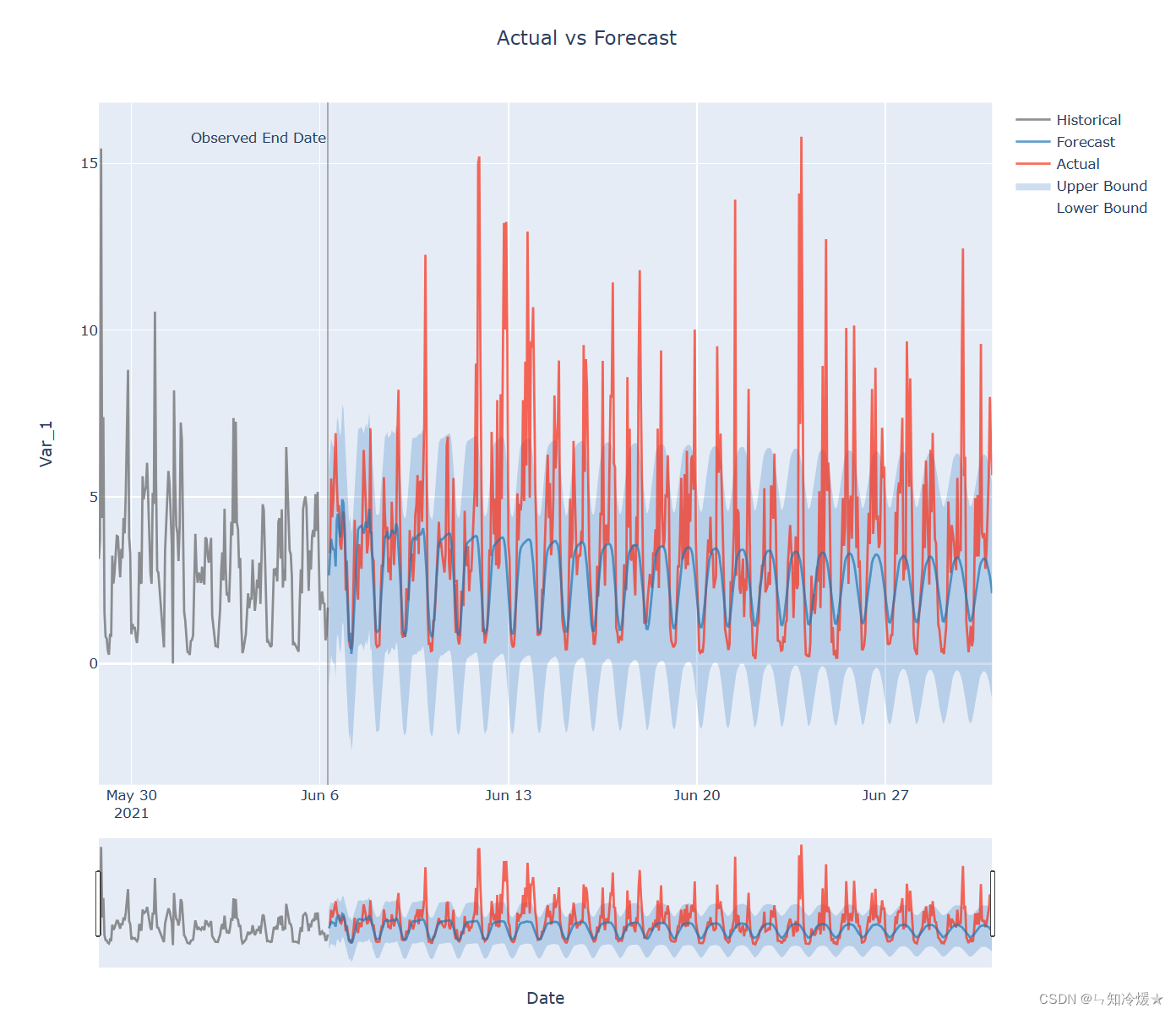
model.plot(forecast=y_pred, actual=test_data)
输出:
3-2、时间序列分类
from hyperts import make_experiment
from hyperts.datasets import load_basic_motions
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
data = load_basic_motions()
train_data, test_data = train_test_split(data, test_size=0.2)
model = make_experiment(train_data.copy(),
task='classification',
mode='dl',
tf_gpu_usage_strategy=1,
reward_metric='accuracy',
max_trials=30,
early_stopping_rounds=10).run()
X_test, y_test = model.split_X_y(test_data.copy())
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test)
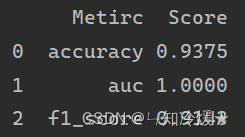
scores = model.evaluate(y_test, y_pred, y_proba=y_proba, metrics=['accuracy', 'auc', f1_score])
print(scores)
输出:
3-3、时间序列异常检测
from hyperts import make_experiment
from hyperts.datasets import load_real_known_cause_dataset
from sklearn.model_selection import train_test_split
data = load_real_known_cause_dataset()
ground_truth = data.pop('anomaly')
detection_length = 15000
train_data, test_data = train_test_split(data, test_size=detection_length, shuffle=False)
model = make_experiment(train_data.copy(),
task='detection',
mode='stats',
reward_metric='f1',
max_trials=30,
timestamp='timestamp',
early_stopping_rounds=10).run()
X_test, _ = model.split_X_y(test_data.copy())
y_test = ground_truth.iloc[-detection_length:]
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test)
scores = model.evaluate(y_test, y_pred, y_proba=y_proba)
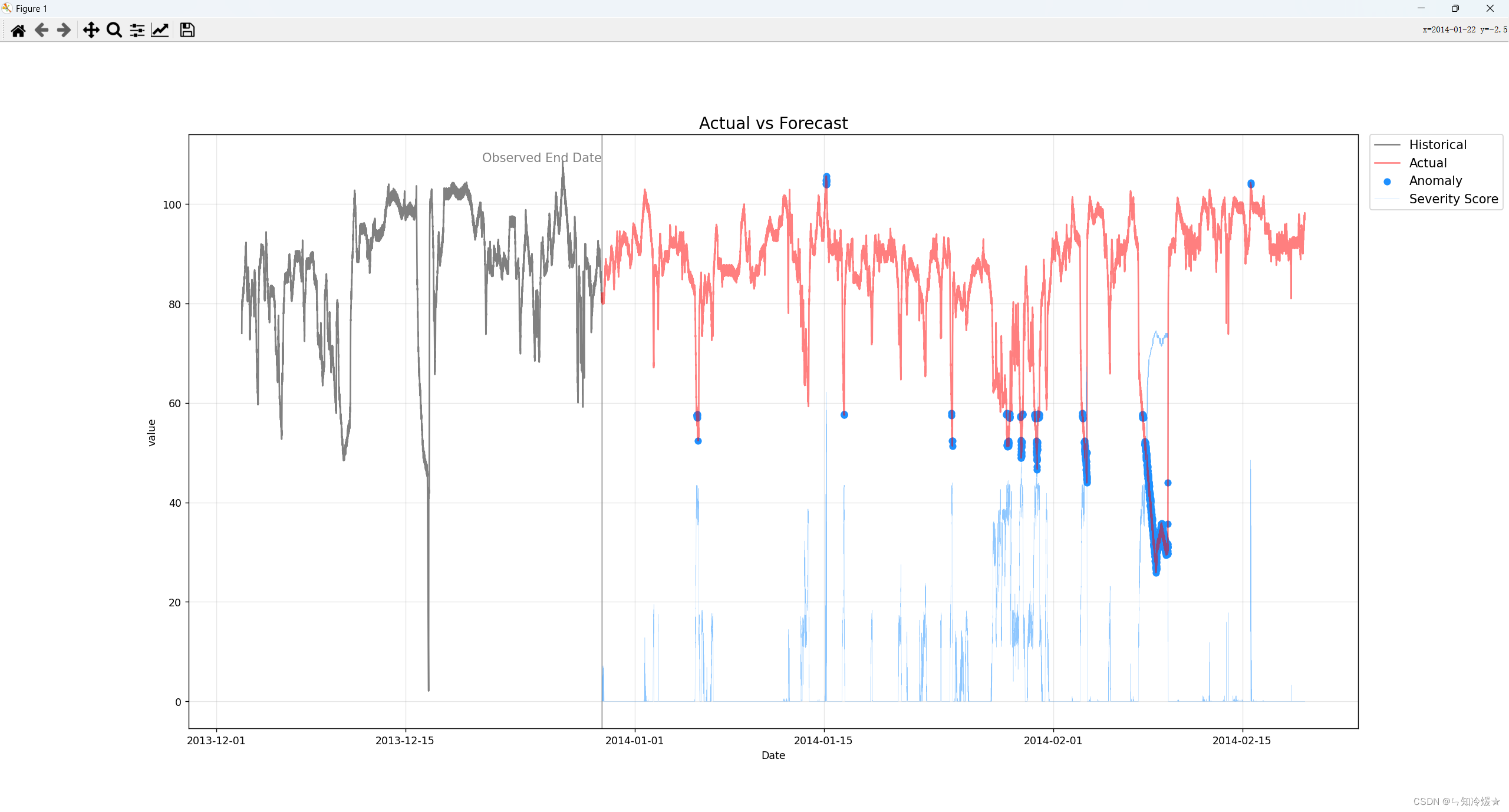
model.plot(y_pred, actual=test_data, history=train_data, interactive=False)
输出:
四、高级应用
4-1、模型的保存和加载
模型的保存:
model.save(model_file="./xxx/xxx/models")
# 或者是
from hyperts.utils.models import load_model
pipeline_model = load_model(model_file="./xxx/xxx/models/dl_models")
模型的加载:
from hyperts.utils.models import load_model
pipeline_model = load_model(model_file="./xxx/xxx/models/dl_models")
参考文章:
HyperTS官方文档.
github.
总结
明天是端午节啦~ 想她🥹