作者:余辉,滴滴出行 OLAP 团队负责人/专家工程师;李明皇,滴滴出行高级软件开发工程师
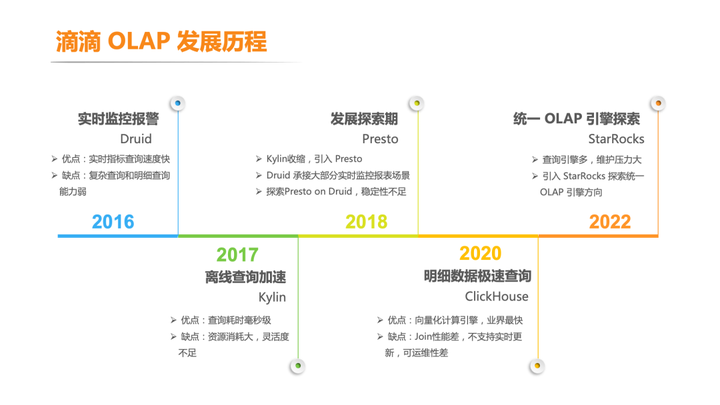
发展历程
滴滴的 OLAP 系统早期由用于实时监控系统的 Apache Druid (以下简称 Druid)和离线加速使用的 Apache Kylin(以下简称 Kylin)逐步发展起来。在 2018 年后开始全面发展,当时主要使用 Druid、Kylin 和 Presto 等引擎,用于承接实时监控、实时看板和数据分析等场景。随着业务使用量和业务复杂度的提升,原有的这些引擎由于性能、稳定性、易用性、维护成本等原因,已经无法满足各种复杂的使用需求,查询性能和稳定性难以满足。
在 2020 年后引入当时业界广泛使用的 ClickHouse 引擎。ClickHouse 是一款开源 OLAP 的列存数据库, 号称比 MySQL 快 100-1000 倍,最大的特色是高性能的向量化执行引擎,单机性能强悍。通过 ClickHouse,支持了当时网约车、 顺风车、青桔单车、橙心优选等多个业务线运营看板、实时分析等场景。经过长时间的发展和迭代, ClickHouse 和 Druid 成为当时滴滴内部主要的 OLAP 引擎,也初步让 OLAP 产品在滴滴内部发展壮大。
选型
随着在滴滴内部使用 OLAP 场景的不断增加,主要涵盖监控报表、日志分析、离线加速和实时数仓这四个场景。原有的基于 ClickHouse 和 Druid 建设的 OLAP 系统暴露的问题越来越多。主要有:
1. 维护困难:在 OLAP 场景中维护的引擎和组件有 5 个之多,每个引擎使用方式,运维方式不一样。导致难以维护, 难以发展。
2. 使用不便:不同引擎特点不同,它们针对的场景比较单一,用户难以根据业务场景正确选择引擎。另外,对于 ClickHouse 从能用到用好难度很大,经常出现查询性能未达预期。
3. 稳定性压力大:引擎多投入人力有限,问题频频发生,无有效解决方案。很多业务场景混合在一个集群中,缺少资源隔离机制,服务稳定性难保障。
4. 用户需求难以满足:部分用户有修改和删除数据的需求,现有引擎无法满足。对于高 QPS 场景,复杂度高查询场景、 Join 等场景,查询性能不能满足需要。
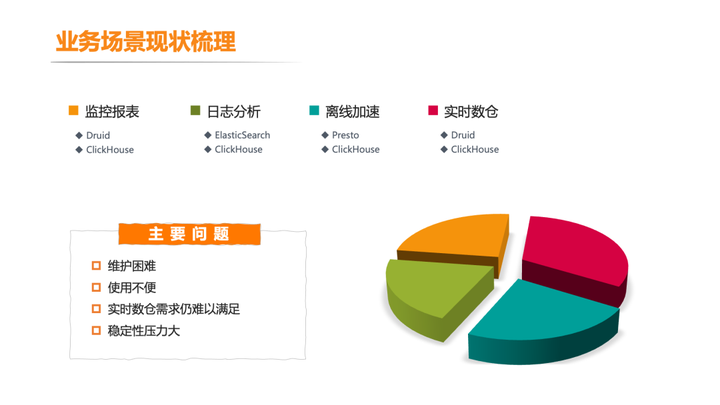
(上图为引进 StarRocks 之前的 OLAP 现状)
针对上面这些问题,我们于 2022 年开始引入 StarRocks。StarRocks 是新一代全场景 MPP 数据库,使用向量化、 MPP 架构、 CBO、智能物化视图、可实时更新的列式存储等技术,实现多维、实时、高并发的数据分析。StarRocks 在 GitHub 上已有 4.7k Star,并且增长迅速,社区也非常活跃。在国内各大互联网公司也有较为广泛的使用。
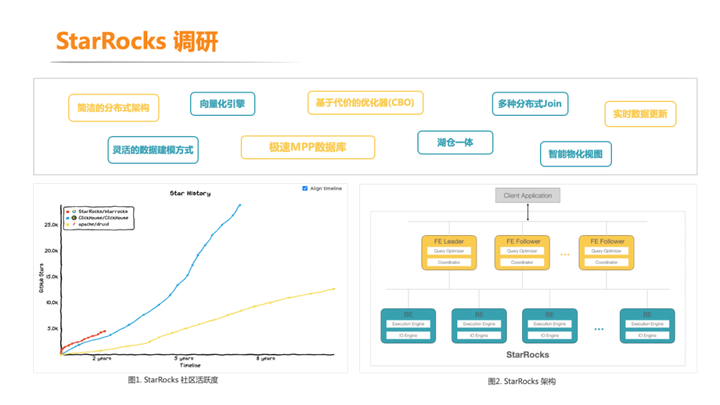
其主要特点有:
1. 简洁的分布式架构:StarRocks 采用简洁的分布式架构,可以水平扩展以处理大规模数据和高并发查询。它将数据分片存储在多个节点上, 实现了数据的并行处理和查询。
2. 高性能查询:由于采用了列式存储、分布式架构和向量化引擎,StarRocks 能够提供优秀的查询性能。它支持多种查询操作,包括聚合、排序、连接和过滤等,适用于复杂的分析查询,并且支持较高的 QPS。
3. 灵活的数据模型:StarRocks 支持多维度数据模型,可以方便地进行多维度分析。它提供了丰富的数据类型支持和灵活的数据模型设计,适用于各种数据分析需求。并且支持更新和删除。
4. 易于使用和管理:StarRocks 提供了易于使用的管理界面和命令行工具,方便用户进行集群的配置、监控和管理。它还支持资源隔离,可以比较容易的定位和解决用户之间查询影响导致的问题。
5. 统一的湖仓架构:StarRocks 原生支持统一管理数据湖和数据仓库, 支持联邦查询,可作为数据湖引擎的加速器,提供统一查询服务。能通过一套技术方案解决实时分析与湖仓分析。
在引入 StarRocks 后, 前期主要在平台和引擎两方面开展建设。通过一年多的建设和推广, StarRocks 逐渐替代 Druid 和 ClickHouse,成为滴滴内部的最主要 OLAP 引擎。
在业务和规模方面:
StarRocks 集群数大约 30+,数据量达 300TB+,日均查询 QPS 400w+。服务公司内部网约车、顺风车、两轮车、 金融、能源等多个业务线。
平台建设方面:
打通数据链路和上下游生态,包括实时、离线数据导入自动化等;建设云原生管控平台,提供高效的运维管理和业务交付能力。
引擎建设方面:
在稳定性上,通过容器化、资源隔离、双链路机制等方式,对不同稳定性要求的用户提供针对性的稳定性保障手段。
在易用性上,将慢查询监测告警功能和查询分析器开放给用户,让用户有办法感知到慢查询,并且能针对性的调优。
在性能上,重点推广物化视图,通过预处理技术为用户提供更好的查询性能和更低的成本。
StarRocks 在滴滴的实践
MAS 监控报警业务
业务背景
MAS 监控报警业务是针对客户端 APP,通过埋点采集数据,用于分析客户端 APP 性能或功能上的问题,为集团泛前端提供线上问题感知及定位能力,并持续赋能泛前端稳定性建设和保障工作。
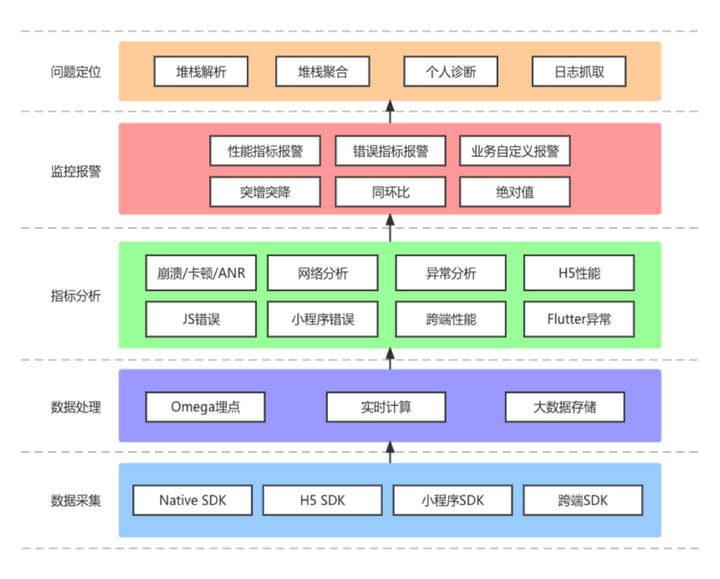
MAS 监控报警系统业务挑战:
数据量大:覆盖集团大部分业务线,数据摄入条数 45w/s,每天数据量 12TB。
监控维度筛选灵活:支持多种时间粒度,多个埋点组合,支持自定义筛选字段。
性能和稳定性要求高:查询耗时要求小于 1s, 稳定性要求 99.9%。
此系统原先使用 Druid 作为底层存储引擎,使用中存在下列问题:
-
查询存在性能瓶颈,有一定概率出现查询超时,影响报警的时效性;
-
Druid 集群成本高,大约需要 60+ 台机器,运维成本高;
-
Druid 集群查询容易受其他用户影响, 导致查询超时或报错,稳定性不足。
迁移过程
经过前期的调研和测试, StarRocks 可以解决 Druid 中的不足,将 MAS 监控报警业务从 Druid 升级到 StarRocks 上,可以提供更好的查询性能,更低的成本和更高的稳定性。在升级 StarRocks 的过程中,针对业务使用场景,在数据建模是根据 StarRocks 特点采用了深层优化手段,主要有:
聚合模型:分析类告警场景中使用大量的聚合计算,选用聚合模型对查询结果预计算,提升查询响应时间。
分区分桶:常见的查询都是按照时间和 APP 维度进行,合理选择时间分区和 app_name 分桶,有效减少单次查询扫描数据量,提升查询性能。
UV 指标:告警场景中关注的指标大部分是 UV 计算,关注的是指标变化趋势,采用 HLL 类型估算 UV 指标, 能提升查询性能。
预处理:使用物化视图,加速将常见的指标查询,按分钟粒度上卷。可以有效降低查询时扫描数据量。
数据导入:使用 Stream Load,相比 Druid 导入方式能降低数据导入成本。
效果收益
MAS 监控报警系统从 Druid 迁移到 StarRocks 之后,在查询性能和成本上有明显收益。在查询性能提升和集群规模缩小的双重影响下,以及 StarRocks 本身资源隔离和易于运维管理的功能下,服务的稳定性也有更好的保障。
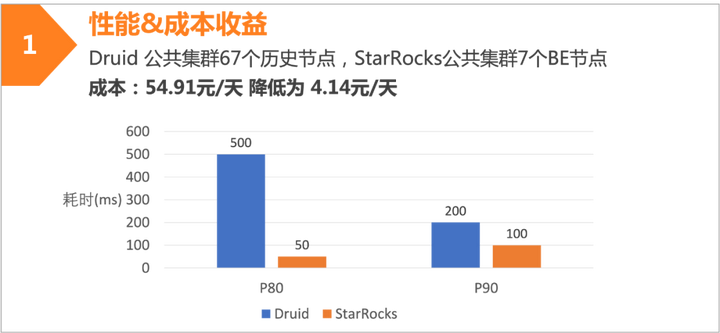
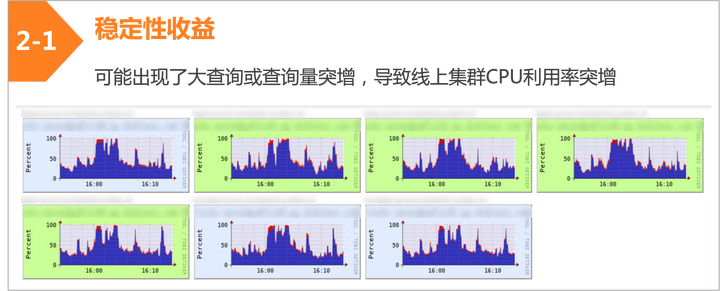
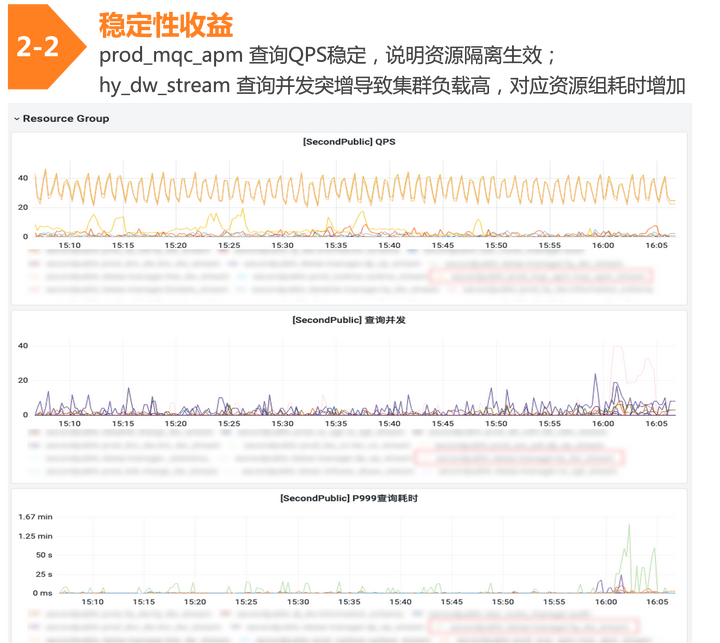
升级后的性能收益:
• 查询性能提升 4 倍
• 查询 P90 耗时从 500ms 提升到 150ms
升级后的成本收益:
• 集群规模从 60+节点下降到小于 10 节点• 数据存储量下降约 40%• 综合成本下降 80% 以上
02 金融数据门户建设
业务背景
金融数据门户是滴滴内部金融产品数据平台,主要为金融业务团队提供以数据驱动精细化运营的数据分析功能,解决传统报表对管、产、运指导不够灵活的弊端,想通过 OLAP 系统搭建一套支持全链路核心指标、维度下钻,异动分析等功能组合的数据解决方案。对 OLAP 引擎的要求有:支持自定义时间维度;支持全链路指标,联动分析。查询秒级返回。其中每日数据量大约有 10 亿条。
建设过程
经过前期的调研和测试,选用了 StarRocks 作为金融数据门户的 OLAP 引擎。将 10 亿级数据量下,支持秒级即席分析查询分析作为目标。通过下面四个方面优化手段以达成。
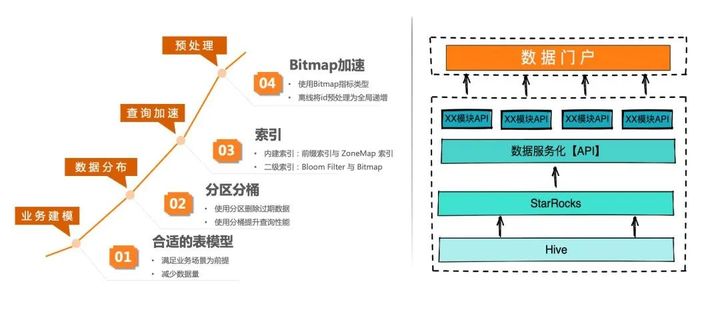
业务建模:通过对金融业务查询场景的需求和数据理解,设计合适的表模型。在满足业务查询和分析的要求的同时,使表的数据结构与存储结构有利于 StarRocks 查询。
数据分布:通过合理的分区和分桶设计,将海量的数据按查询的要求均分到集群各个节点的 tablet 中。使单次查询的数据量在合理范围并且能充分利用集群的计算资源。
查询加速:为了进一步提升查询性能,精心设计前缀索引和 ZoneMap 索引,以保证在查询中能够有效命中,起到大量过滤无效数据的要求,同时在关键查询条件上增加 BloomFilter 与 Bitmap 索引,进一步过滤无关数据,提升查询性能。
预处理:在索引无法覆盖的的优化场景外,通过使用物化视图加 Bitmap 对指标预处理,提升查询的响应时间。通过使用 Bitmap,以及将原来随机 ID 转换成连续递增 ID,进一步提速高基数去重指标的查询性能。
效果收益
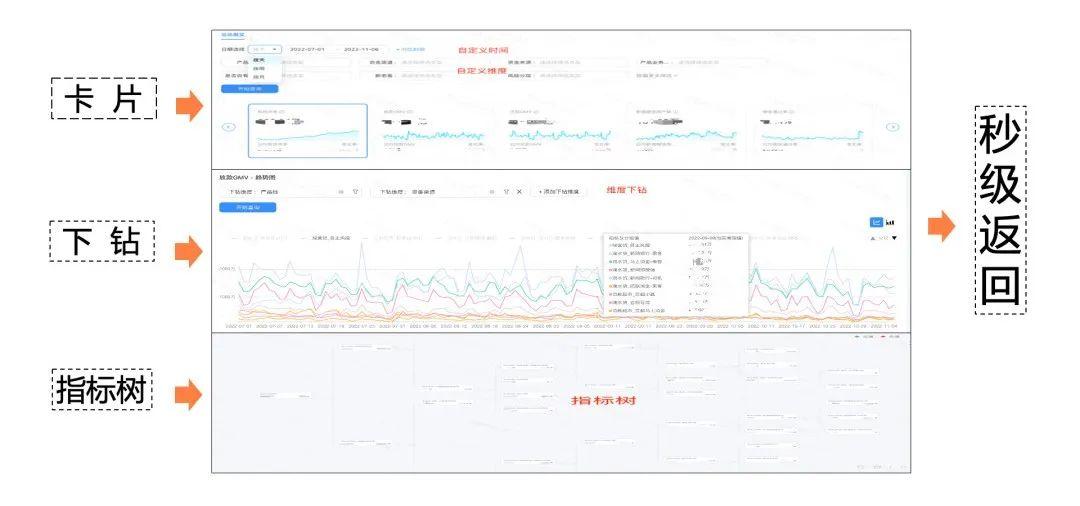
通过 StarRocks 提供低耗时的查询分析解决方案后,金融数据门户系统得以提供更为丰富和精细的业务功能。核心业务指标拆分成了卡片、维度下钻、 指标树的方式呈现,能够快速帮助业务通过数据来掌握业务的现状,数据价值能够得到很好的体现。
未来展望
经过一年多 StarRocks 的建设和实践, StarRocks 在滴滴内部已经成为 OLAP 场景中的主要引擎。伴随着大量业务从原有的 ClickHouse和 Druid 引擎上迁移到 StarRocks 上,也使得 StarRocks 能取代 ClickHouse 和 Druid,统一滴滴内部的 OLAP 引擎成为可能。使用 StarRocks 的 MPP 分布式、向量化查询引擎优势、和联邦查询能力搭建统一 OLAP 平台。解决原有的 OLAP 大数据生态领域,在成本,性能、实效性、易用性及灵活性等方面的各种问题。
以下几个 Feature 是我们认为能够解决这些问题的关键,也是我们后续在社区重点关注的方向:
物化视图:物化视图是解决 OLAP 场景中查询性能问题的关键手段之一。在海量的数据分析中秒级查询响应的要求下,物化视图的预处理技术,是从成本和性能上的最佳解决方案。物化视图预处理技术在 OLAP 的地位相当于 MapReduce 在离线数据处理中位置。目前我们在很多场景中使用物化视图,也取得很好的效果,后续将沉淀物化视图在不同场景下的最佳实践。
存算分离:存算分离架构是大数据处理和分析领域重要特性之一,可以满足不同的业务需求和数据处理场景。StarRocks 在使用存算分离后,成本可以下降 90%;计算节点变成无状态之后,可以通过快速弹性的方式来提高计算的容量,以应对重大活动期间突增的数据分析需求。目前 StarRocks 存储成本相对过高,还不具备单独增加计算资源能力。
湖仓一体:湖仓一体是 StarRocks 社区当前发展的方向,在 StarRocks 具备存算分离和数据湖分析能力之后, StarRocks 本身已经形成了一个分层结构的 Lakehouse 的架构,能够将 HDFS、Apache Hive、Apache Hudi、Apache Iceberg 统一在一起,利用 StarRocks 本身的技术优势来提升查询性能。另一方面,物化视图也可以在其中起到简化湖仓建模,实现查询加速等重要作用。通过引入湖仓一体,可以更容易将实时和离线分析统一到一起,实现统一数据口径,简化数仓开发的功效。同时也为亚实时数据分析场景提供更好的解决方案。
如对本篇文章有兴趣,可以点击下方链接观看余辉老师在 StarRocks & Friends 杭州站的分享:
StarRocks 统一 OLAP 引擎在滴滴的探索实践_哔哩哔哩_bilibili