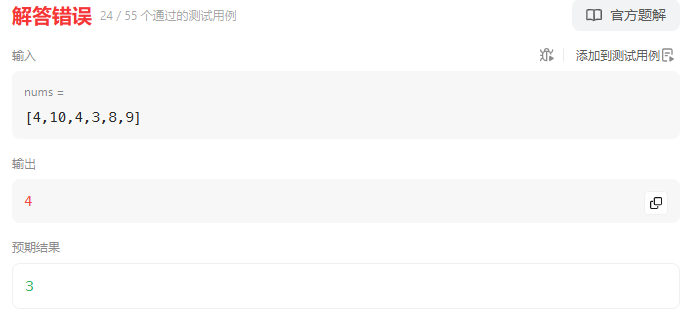
运行游戏并在 FreeVariableGroup 中遇到我们的断言
其实在美国,某些特定的小糖果(例如小糖蛋)只在圣诞节和复活节期间出售,导致有些人像我一样在这段时间吃得过多,进而增加体重。虽然这种情况每年都会发生,但也只能说,这是美国的生活现实。毕竟美国的健康状况普遍不太好,人们的饮食习惯常常导致肥胖。
回到开发的主题,今天的目标是完成内存管理的调试代码,特别是要处理一些内存释放的问题。昨天我们已经做了部分实现,但没有完全完成。具体来说,我们需要解决调试缓冲区(debug buffer)的问题,它是一个用于调试的内存缓冲区,用来存储各种临时数据和调试信息。
在调试过程中,我们遇到了一个问题:当缓冲区被填满后,系统会尝试为更多数据分配内存。如果缓冲区的空间不足,就会尝试释放一些内存。然而,目前的代码并没有正确处理内存释放操作,导致在尝试释放内存时触发了断言(assertion)错误。这个问题是由于我们当前的内存释放机制没有按照预期工作,因此我们需要进一步解决。
我们的代码中有一个“释放变量组”的函数,这个函数本来应该负责释放内存,但现在它仅仅是触发了断言错误。我们计划接下来解决这个问题,并确保内存释放操作正常进行。
同时,我们还讨论了关于线程安全的问题。我们使用了静态变量(static variables)来避免频繁查找数据,但有个问题是,某些版本的Visual Studio(比如2013版)并没有为静态变量提供线程安全的支持,而2015版则做了改进。虽然我们并不打算在实际游戏代码中使用静态变量,但在调试代码中使用了这些变量来简化操作。我们需要考虑是否要解决这个线程安全的问题,或者干脆接受调试代码中可能出现的偶发错误,比如调试变量被多次添加。
目前,我们的目标是完成内存管理的调试代码,并确保它能正确处理内存分配和释放操作。接下来,我们还会着手清理游戏的UI部分,使得程序的外观和功能更加完善。

game_debug.h: 考虑在处理时清理这些内容
接下来我们看一下“释放变量组”(free variable group)部分的实现,并探讨如何处理相关的内存管理问题。从代码的深度来看,我们应该能够很快理解这个部分是如何实现的。实际上,在处理这一部分时,存在一些不太整洁的地方,代码有点凌乱。我们可能需要在清理这些代码时直接进行重构,而不是先写释放代码,再做改动并重新整理代码。
实际上,我认为问题的关键在于,调试变量组(debug variable group)的结构本身并不需要被释放。真正需要释放的,是与调试事件相关的数据。调试变量组是一个结构体,它本身并不需要像调试事件那样被释放,因此在我们完成代码之前,实际上应当专注于释放调试事件的内存。
在这个过程中,最需要关注的部分是调试事件信息,而不是变量组本身。因此,释放内存的焦点应当集中在这些调试事件的数据上,而非整个变量组。我们正在思考如何优化这个结构,以便更有效地管理内存。
目前的计划是,首先完成调试事件相关的内存释放部分,再回头完善剩余的部分。虽然一开始考虑过直接跳到后面的工作,但现在回头想想,最好还是按顺序完成当前的部分,再继续进行后续的工作。这将帮助我们在处理复杂结构时更加有条理。

game_debug.h: 将 RootGroup 从 debug_frame 移到 debug_state
这段时间,遇到了一些架构上的问题,最终意识到以前的设计方式不太合理,甚至有些让人感到困惑。问题的核心在于,之前的设计把数据结构绑定到每一帧上,这是不明智的。真正需要的设计应该是将数据结构作为一个持久化的概念,并在整个调试系统中全局理解和管理,然后每一帧只需保存当时数据的状态。这才是我们真正想要实现的目标。
具体来说,之前的设计将结构体与每一帧的状态捆绑在一起,但这种方式存在问题。正确的方式是,将这些结构体(如调试事件)作为全局的概念存在,而每一帧只需要存储当时这些结构体的值变化。换句话说,我们不需要每一帧都重新构建数据结构,而是只需要更新数据值。
这意味着我们目前的代码大部分是没问题的,问题只是出在部分逻辑的设计上,需要做一些调整。主要的变化是,在调试过程中,不再每一帧都重建整个调试层级结构,而是让这个结构体在整个程序生命周期内持续存在。调试层级的结构应当在整个系统中一直存在,随着程序的运行,层级会不断增加,最终包含所有可能的调试点。这些调试点并不多,只是程序中定义好的几个位置。
这样一来,我们的调试系统不需要每次都销毁和重建这些结构,而是让它们持续存在,并且随着需要逐渐扩展。这种做法能更好地管理内存和调试状态,同时避免不必要的重复操作。

game_debug.h: 引入 debug_element 用于存储事件链
我们已经构建了调试层级结构,接下来的目标是让调试事件能够有序地堆叠并附属于这些结构中的某个部分。为了实现这一点,我们需要一个叫做 debug_element 的概念,这个结构体相当于调试系统的基本单元,用于组织和存储某一类调试事件。我们希望这些事件能够附加到 debug_element 上,并随着时间累积。
目前虽然还没有完全明确最终的实现方式,但可以先构思出一种最简单的方式:将所有调试事件通过链表结构串联起来。当内存需要释放时,再将这些事件从链中取出。这是一种非常基础且易于实现的方式。当然,也可以考虑使用更复杂的数据结构来实现,例如环形缓冲区或具有特定淘汰策略的队列,不过目前还未确定哪种方式最优。
核心目标很清晰:调试系统中应该维护一个全局结构,该结构代表某个调试变量(例如一个浮点变量 x),这个变量在调试系统中是一个固定存在的结构(不随帧而改变),而与其关联的事件(例如每一帧中该变量的数值)才是动态生成并随着时间推移而增加的内容。
这些调试事件本质上就是某个调试元素(如变量)在每一帧中记录的值。我们可以想象这样一个结构:调试元素拥有一个事件数组或链表,这些事件按时间顺序附加在该元素上。最简单的实现方式是固定每个元素最多容纳一定数量的事件,比如每个调试元素最多包含 8 个事件,新事件加入时旧的被淘汰。
如果不想做这种硬编码的设计,也可以允许这些事件不断堆叠,直到内存用尽。此时的问题变成:当需要回收内存时,如何知道应该释放哪些事件。释放策略就变得关键了。
一种可行的思路是:在内存回收时,遍历所有现有的调试元素,对每个调试元素都释放一个最早的事件。这样可以保证整体内存释放是均衡的,不会集中清除某个元素下的大量事件,而是将负担分摊在整个调试系统中。
不过,这里也提出一个疑问:是否应该将这些事件的链表设计成双向链表(double threaded)以方便插入和删除?这虽然可能提升操作效率,但结构复杂度会显著上升,因此需要慎重考虑是否值得。
总结来说,当前需要处理的关键问题包括:
- 如何将调试事件绑定到结构上;
- 如何组织这些事件(链表、数组、固定数量、可扩展等);
- 如何在内存不足时,有策略地释放这些事件;
- 如何保持调试层级结构的稳定性,使其成为一个持久存在的、全局有效的系统。
这些问题都将直接影响调试系统的内存管理效率和响应性能,因此需要在后续实现中认真规划。

game_debug.h: 引入 debug_stored_event
在调试接口中,我们目前的 debug_event 结构体实际上没有多余的空间来扩展额外信息,因为这些事件都直接写入主调试记录区,不能让其结构变得更臃肿。因此,正确的做法是引入一个单独的结构体,比如叫做 debug_stored_event,专门用来存储调试事件,并以链表的方式连接起来。
这种设计的思路是,每一个调试元素(如变量或状态)都有一个事件链,事件通过 debug_stored_event 链接起来。调试元素中会保留一个指针,指向事件链的起始节点。例如我们可以这样处理:调试元素包含一个 FirstStoredEvent 指针,指向第一个 debug_stored_event 实例,而这个实例中包含该事件的数据和一个指向下一个事件的指针,实现事件的堆叠。
这种结构是非常轻量且合理的,因为它将事件数据从主调试记录中分离出来,使得主调试系统的接口依旧保持简洁。事件的堆叠结构独立于核心数据结构,避免内存的膨胀,也便于管理和释放。
设计时只需保持这些 debug_stored_event 的结构足够简单,能够快速插入新事件,并在需要时方便地进行内存回收。调试系统的 UI 子系统可以随时指向某个调试元素,并遍历其事件链,动态地展示对应的调试信息。
总结这种方案的核心要点如下:
- 引入新的结构
debug_stored_event用于事件链; - 每个
debug_element包含一个指向事件链头部的指针; - 所有调试事件以链表的方式附加在调试元素上;
- 主调试结构保持简洁,避免数据膨胀;
- UI 可通过指针访问事件链,实现信息可视化;
- 内存回收机制可以基于事件链结构进行设计,精准释放不再需要的事件节点。
这个设计思路清晰、实用,有利于构建一个既高效又灵活的调试系统。


这是一个非常经典的内存管理技巧,union { debug_stored_event* Next; debug_stored_event* NextFree; }; 的设计目的是 节省内存并复用结构体字段,在不同的上下文中复用同一块内存区域,具体解释如下:
结构体作用背景
这个结构体 debug_stored_event 被用来:
- 存储调试事件链(即正常运行时,
Next指向下一个事件节点); - 同时也用于组成一个空闲链表池(内存回收时使用
NextFree来组织“空闲事件节点”)。
为什么用 union
在一个时间点,一个事件节点只会处于以下两种状态之一:
- 正在使用:它是调试事件链的一部分,用
Next指向下一个事件; - 未被使用(空闲):它在空闲内存池中,用
NextFree指向下一个空闲节点。
由于这两个指针永远不会同时有效,就可以用 union 来让它们共享内存。这样可以节省结构体的空间开销,比如原本需要两个指针(8字节 * 2 = 16字节),现在只需一个指针的大小(8字节)。
优点总结
| 优点 | 说明 |
|---|---|
| 节省内存 | 两个指针复用内存,只占一个指针大小的空间 |
| 简化管理 | 用同一结构体可同时管理活跃节点与空闲节点 |
| 提高效率 | 避免频繁堆内存分配与释放,配合内存池策略使用更高效 |
举个例子:
debug_stored_event* FreeList = nullptr;
// 分配节点
debug_stored_event* AllocateEvent() {
if (FreeList) {
debug_stored_event* Result = FreeList;
FreeList = FreeList->NextFree;
return Result;
} else {
return new debug_stored_event;
}
}
// 回收节点
void FreeEvent(debug_stored_event* Event) {
Event->NextFree = FreeList;
FreeList = Event;
}
上面示例中,只有在事件被释放时才用到 NextFree,而运行时串联事件时使用 Next,所以两个字段共用是完全合理且高效的。
总结一句话:
定义 union { Next; NextFree; } 是为了在事件存活和被释放这两种状态下复用指针字段节省内存,这是低层内存管理中常见且优雅的优化手法。
game_debug.h: 提供一种方法来遍历现有的 debug 元素并释放它们
我们目前的目标是优化调试事件(debug events)的内存管理策略,使系统在内存吃紧时可以有序地释放旧数据,同时保持整体架构的稳定性与效率。以下是我们思考和设计的详细过程总结:
总体设计目标:
我们已经建立了一个调试层级结构(debug hierarchy),现在我们想要的是:
- 所有调试元素(debug elements)内部能储存一连串调试事件(debug events);
- 在需要释放内存时,我们能从这些链表中「逐个」地移除最旧的事件;
- 同时确保系统只清理那些在特定帧(frame index)之前产生的事件,避免误删当前帧或未来帧的调试信息。
架构思路:
1. 每个调试元素持有事件链:
我们给每个 debug_element 增加一个链表,用于存储与该元素相关的事件。这些事件通过链表方式组织,每个节点是一个 debug_stored_event。
2. 事件节点结构(debug_stored_event):
结构中使用了 union { Next; NextFree; } 来复用指针字段,使事件节点既可在使用时参与事件链,也可在被释放后进入空闲链表,提高内存利用率。
3. 按需清理策略:
我们会在需要释放内存时,遍历所有调试元素,查看它们的事件链,并根据帧索引决定是否清理。
清理逻辑:
- 遍历调试元素:我们遍历所有存在的 debug_element。
- 检查其事件链表头节点:每个链表的头节点代表最早的事件。
- 比较帧索引:如果该事件的帧索引早于当前清理阈值,就可以将其从链表中移除,并将其归还到空闲池中。
- 重复过程:对所有元素执行该逻辑,每次释放一次,或在需要回收一定内存时批量释放多个。
如何遍历所有元素:
我们已经有完整的调试层级结构,在 UI 系统中也实现了遍历逻辑,因此我们可以重用这套遍历机制,用非递归方式对整个结构进行迭代,处理其中每一个 debug_element。
此外,之前曾避免使用递归遍历,可能是出于对栈空间或可控性的考虑,我们可以顺便整理一下那部分代码,使其更易懂一些。
帧索引设计:
为了准确识别调试事件所属的帧,我们在每个调试帧结构中增加了 FrameIndex 字段。
- 每次创建新帧时都会分配一个唯一帧索引。
- 所有调试事件都带有所属帧的索引,便于清理时进行判断。
简化与精炼:
我们也准备剔除一些旧的系统,比如「区域」(region)相关结构,这部分不再需要,可删除简化代码。
最终意图:
构建一个高效、自动回收的调试事件系统,使调试元素能够持续保存其事件历史,同时当内存不足时能以结构化的方式逐步释放旧数据,避免性能与稳定性问题。
这个结构是相对简单直接的实现方式,可能未来还会进一步精化,但目前已能满足我们的目标。我们接下来会尝试实现这个版本并观察实际效果。

game_debug.h: 添加 TotalFrameCount 并计算在 TotalFrameCount 回绕之前,调试系统可以运行多长时间
我们在设计调试系统时,需要为每一帧(frame)分配一个唯一的索引值(frame index),这个索引值用于标识该帧在整个调试序列中的位置,也是事件存储和清理的依据。因此我们引入了一个全局递增的帧计数器(例如 TotalFrameCount),用于为每一帧生成一个单调递增的编号。
设计思路详解:
引入帧索引:
- 每当创建一帧调试数据,就为其分配一个新的索引;
- 该索引来自一个全局递增变量;
- 这个索引在调试状态中是唯一的、连续的;
- 所有调试事件都可以附带其所属帧的索引,便于后续做基于时间的清理。
关于帧索引溢出的分析:
我们使用的是一个 32 位无符号整数(uint32_t),最大值为 2^32 - 1 = 4294967295,即约 42.9 亿帧。
假设游戏运行在 60 帧每秒,我们来估算这个索引值从 0 增长到最大值的时间:
- 一秒钟帧数:60 帧
- 一分钟帧数:60 × 60 = 3600 帧
- 一小时帧数:3600 × 60 = 216,000 帧
- 一天帧数:216,000 × 24 = 5,184,000 帧
- 最大帧数可持续天数:42.9 亿 ÷ 518.4 万 ≈ 828 天
即帧索引的溢出大约要 两年多时间。
实际结论:
- 几乎不会存在调试系统持续运行超过两年不重启的情况;
- 所以我们不需要担心帧索引的溢出问题;
- 使用简单递增的整数作为帧标识既安全又方便。
实际实现方式:
每次创建新帧时:
- 读取并使用
TotalFrameCount的当前值作为新帧的FrameIndex; - 然后将
TotalFrameCount++,为下一帧准备索引; - 这样我们就实现了一个持续增长的时间标尺,用于记录和回收调试数据。
总结:
引入帧索引的本质是为了让调试系统有一个「可对比」的时间锚点,以便在后续回收事件数据时判断事件是否属于旧帧。我们采用的 32 位递增计数器在实际使用中具有足够的寿命,简单、高效、易于实现,非常适合调试用途。
game_debug.cpp: #if 0 RegionIndex 并处理 VarLinkInteraction
我们现在决定暂时移除 RegionIndex,以便更专注地重构和完善调试系统中“事件存储与呈现”的部分。
我们的目标:
我们要把从调试事件流(debug stream)中提取出来的事件,放入一个结构化的、稳定的数据结构中,例如调试元素(debug element),并确保事件在其中有序地组织和存取。
VarLinkInteraction 的调整:
原本的 VarLinkInteraction(变量链接交互)机制,是直接链接到某个调试事件(debug event),但现在事件将嵌套在调试元素中,因此需要新的访问方式:
- 现在链接(Link)将不再直接指向事件;
- 我们必须通过链接定位到调试元素,然后从元素中查找事件;
- 每个调试元素应该记录:
- 一系列事件链(按时间排序);
- 最旧的事件(first)和最新的事件(last)指针,用于快速定位;
- 这样可确保我们可以顺利遍历、添加和查找事件。
事件访问与判断:
因为某些元素可能没有任何事件,所以在执行交互前,必须检查当前元素中是否有事件存在:
if (Element->MostRecentEvent) {
// 才允许交互
}
避免在事件为空的情况下进行操作。
与帧索引的关联(Frame Index):
我们还希望能按帧索引定位事件:
- 如果我们要查看某一特定帧的事件,
- 就必须在调试元素中的事件链里进行遍历,
- 查找是否包含目标帧编号的事件;
- 这会带来遍历成本,思考中我们也提出:
- 是否把这些事件按帧哈希存储(如哈希表),
- 以优化快速查找的效率;
- 虽然暂时不实现,但这是未来优化方向。
拆出公共事件访问逻辑:
由于其他部分(如事件驱动处理)也会访问事件:
- 所以我们打算把事件访问逻辑提取为一个工具函数(utility function);
- 保持逻辑集中、便于未来扩展;
- 比如可以统一检查事件有效性,统一处理交互入口等。
总结当前我们做的调整:
- 暂时移除 RegionIndex,减少干扰;
- 重构 VarLinkInteraction,通过调试元素访问事件;
- 在调试元素中维护事件链(最旧-最新);
- 增加空事件判断逻辑,避免访问空数据;
- 规划事件哈希方案,作为未来可能的优化;
- 提取事件访问函数,统一管理与调用。
这些更改将帮助我们逐步建立一个更清晰、稳定、可维护的调试事件管理系统。





game_debug.cpp: 引入 GetEventFromLinkα
我们现在围绕调试系统的事件链接(Link)与变量层级管理进行了进一步重构与思考。
统一通过 Link 获取调试事件
我们增加了一个明确的接口:从变量链接(DebugVariableLink)获取事件(DebugEvent)。
- 提供一个函数,比如
GetEventFromLink; - 外部只需传入 Link,我们统一返回对应的事件指针;
- 这个方式封装了事件访问细节,使得将来可以添加如帧过滤、状态选择等功能;
- 所有与变量交互的行为(如交互事件响应)可以统一从这个函数入口获取事件,便于维护和扩展;
- 原来在不同地方手动取事件的代码可删除,改为统一调用该工具函数。
Debug 变量链接(Link)结构调整
- 每个链接原本直接指向事件;
- 现在改为指向一个调试元素(Debug Element),事件链保存在该元素中;
- 我们统一从元素的
MostRecentEvent取当前要显示或交互的事件; - 在没有事件时自动返回空指针,避免冗余判断。
变量层级管理逻辑重构(永久性结构)
原来的变量分组逻辑是临时性的,每帧重建:
- 比如
AddVariableToGroup的操作是基于当前帧的变量快照; - 现在我们转向构建一个永久性层级结构,变量结构不再每帧重新构建,而是稳定保留并随着事件推移更新;
- 这就要求我们在构建变量层级(Hierarchy)时将其视为一个常驻的数据结构,调试事件附加到已有层级上,而不是每次都重建树。
拆分两类层级系统的思考
我们进一步区分了两种层级概念:
-
调试数据的实际来源层级:
- 例如变量是哪个模块、函数、子系统产生的;
- 这个层级基本是稳定的;
- 应该构成一棵静态层级树,调试事件在其上积累。
-
用户界面层级(UI层次):
- 用户希望在调试界面中如何组织与查看变量;
- 可能支持用户拖拽、重新排列等交互;
- 是动态的,可重构的;
- 未来可能需要独立管理这部分结构,与真实事件产生的层级分离。
目前我们优先构建的是第一类静态层级,确保事件落点清晰、持久。
临时逻辑清除与定位缺失代码
- 暂时移除了
AddRegion相关的逻辑; - 当前我们不清楚是否还需要区域划分(Region Count),因此将这部分搁置;
- 正在理清事件插入的结构入口、构建持久层级时的递归过程;
- 目前正在定位变量是如何被映射(或注入)进层级结构的;
- 我们通过
debug_interface做了某种“合成”变量插入操作(synthetic insertion),这部分的入口还在查找中,具体函数位置正在核实。
当前核心结构变化与方向总结:
- 提供统一事件访问入口:
GetEventFromLink; - 所有变量交互统一通过该函数获取事件;
- 调试变量层级改为持久性存储;
- 拆分“实际层级”与“UI层级”两个结构逻辑;
- 暂时移除 RegionIndex / AddRegion 相关结构;
- 理清 Synthetic 插入流程,为事件入层级结构做准备。
我们正在建立一个更具结构化、清晰化、可扩展的调试数据管理系统。接下来将继续梳理变量插入机制,确保事件准确归档进合适的层级结构。


game_debug_interface.h: 刷新我们对 DEBUGInitializeValue 和 RecordDebugEvent 的记忆
我们回顾并梳理了调试系统中与 静态调试变量初始化与事件记录机制 相关的逻辑,目的是搞清楚在初始阶段是如何创建和引用这些静态调试值的。
静态调试变量初始化流程回顾
我们最开始就设计了一个机制,允许在程序中注册一次调试值,并能够在后续永久引用这个调试信息。这个机制主要围绕以下几个步骤运作:
调试值初始化函数
- 使用的是一个叫做
DebugInitializeValue的函数; - 这个函数背后的核心逻辑是调用
RecordDebugEvent; - 它创建一个
DebugEvent,事件类型通常是DebugType_MarkDebugValue; - 这样系统“知道”了我们注册了一个调试值。
实际事件创建细节
但在深入之后,我们发现:
RecordDebugEvent返回的是一个DebugEvent的指针;- 而这个
DebugEvent是存储在一个事件表中,可能是全局的; - 然而,这个事件本身并没有任何额外信息被存储到一个长期表结构中,比如说一个永久变量表;
- 也就是说我们并没有一个中心表结构去映射这些静态调试变量的位置或者名字,只有事件的临时记录。
本地持久变量(Local Persist)机制
- 我们通过一个
local_persist局部静态变量机制保存了DebugEvent的指针; - 由于静态变量存储在全局或堆中,所以我们依赖该地址保持不变;
- 调试系统并不实际“管理”这个变量,它只是记录了“有这么一个变量存在”;
- 其生命周期由宿主控制,调试系统只是依附引用。
问题与不满点
这个机制的问题在于:
- 我们无法在调试系统中真正建立一个静态调试变量的“正式入口”;
- 没有建立一个映射关系,如:变量名 ➝ 全局调试结构 ➝ 实际数据;
- 所以目前是以一种“外部引用 + 地址唯一性” 的形式存在。
潜在解决思路:基于地址的哈希表
为了让这些静态变量能真正纳入调试系统的结构中,我们考虑:
- 使用一个哈希表,以变量的内存地址作为 key;
- 每当系统遇到该地址时,即可识别出对应的调试变量;
- 这样就能建立起一个可靠的查询映射机制;
- 在逻辑上等价于:“这个地址就是这个调试变量的唯一 ID”;
- 地址本身在程序生命周期内是稳定的(尤其是静态变量),所以可用作索引键。
小结:当前机制优缺点
优点:
- 静态变量地址天然唯一,可用作索引;
- 不需要额外构建唯一 ID 生成逻辑;
- 结构简单,适用于现阶段调试系统需求。
缺点:
- 缺乏正式的注册中心和集中管理;
- 可扩展性弱,不方便构建复杂的层级、分组或标签系统;
- 如果未来需要持久化或跨模块统一管理,这种机制会成为瓶颈。
下一步可能目标
我们可以考虑构建一个结构化调试变量注册表,具体包括:
- 变量名 ➝ 内存地址 ➝ 层级路径 ➝ 关联事件链;
- 初始化时注册静态变量,并建立完整记录;
- 允许在调试界面中快速定位、归类、管理这些调试项;
- 实现更强大的可视化、筛选、分组与历史回溯功能。
我们对当前机制已基本掌握其运作逻辑及局限性,接下来可以围绕哈希表索引、结构性注册等方向继续完善调试系统。
"给我谜题吧,蝙蝠侠"β
在当前的调试系统中,主要目标是如何有效地管理和定位不同的调试元素。具体来说,我们有两个关键部分需要处理:一是存储调试元素的值,二是如何在系统中查找这些调试元素,并与其对应的实际数据进行关联。
现有问题
-
调试元素与值的关联:调试元素的存储是通过一种树状结构(或者类似的分层结构)来进行展示的。在这个结构中,每个调试元素都可能包含不同的值,这些值需要被关联起来。但过去使用的计数器方法,虽然能够唯一标识调试元素,但它也带来了复杂性,因为计数器需要在多个翻译单元(Translation Unit)中共享和定义,这增加了不必要的复杂性。
-
计数器带来的问题:由于使用计数器需要在不同的翻译单元之间进行定义和同步,这导致了实现上的一些困难,尤其是在跨越不同的模块或组件时。
解决思路:哈希表与静态变量地址
-
使用静态变量的地址作为唯一标识:为了简化调试元素的关联,可以利用静态变量的内存地址作为每个调试元素的唯一标识符。这个标识符类似于计数器,它能够保证每个调试元素的唯一性。尽管它不像计数器那样可以线性排列,但它仍然能有效地提供唯一性。
-
哈希表的应用:通过哈希表来存储这些调试元素的唯一标识符(即静态变量的地址),可以方便地查找和关联调试元素。哈希表能够根据地址来定位每个元素,避免了传统计数器所带来的复杂性。
-
与UI交互的关联问题:如果想要在用户界面中显示这些调试元素,当前的哈希表方法似乎是一个合理的选择。然而,需要注意的是,哈希表的实现可能需要与具体的UI框架进行适配,这也可能带来额外的复杂性。
-
增强的标识符管理:除了静态变量的地址,还可以考虑使用一个递增的变量来生成线性增长的唯一ID。这样做可以在保持唯一性的同时,尽可能避免地址带来的不规则性,从而提供更加线性的标识符。
总结
目前来看,使用哈希表和静态变量的地址作为调试元素的唯一标识符是一个合理的解决方案。它能够避免传统计数器带来的复杂性,同时也提供了一种灵活的方式来管理调试元素。然而,哈希表的实现可能需要与UI层进行适配,具体实现时需要考虑到不同调试元素的显示和管理需求。在此过程中,递增的ID也是一个可选的优化方案,能够进一步简化调试元素的管理。
game_debug.h: 向 debug_state 添加 ElementHash 并讨论系统
在当前的设计中,我们正在考虑对调试系统进行一系列重构,主要目的是简化调试元素的管理,同时提供更清晰、灵活的调试视图。以下是对当前思路的详细总结:
调试系统的结构调整
-
哈希表管理调试元素:
- 我们决定使用哈希表来存储调试元素。通过这种方式,可以根据需要将不同的元素按需插入哈希表,并通过它们的唯一标识符快速访问。
- 这样做的好处是避免了传统的计数器方法所带来的复杂性,同时也能保持元素的唯一性和快速查找。
-
调试元素树的重构:
- 调试元素将组织成树状结构,这个树结构代表了调试数据的层级关系。树的根节点是调试数据的起点,之后的数据节点则依赖于树的构建方式。
- 这种结构能够有效地表示数据之间的父子关系,并且随着系统运行,树会不断更新,以反映当前的调试状态。
-
视图哈希和用户界面:
- 视图哈希用于存储用户界面(UI)的状态信息,表示当前视图的展示方式及其各个元素的状态。这部分主要用于管理调试过程中的UI更新和状态变更。
- 对于调试元素而言,它们会随着时间推移而更新,这些更新会反映在树结构中。调试元素树就是记录这些变化的地方,它能够帮助开发人员跟踪调试过程中的状态。
-
调试元素与用户界面的交互:
- 用户可以通过交互式UI来创建和管理调试树。这意味着用户能够动态地修改树结构,添加新的调试元素,或者调整现有元素的状态。
- 然而,为了避免用户误操作或不小心破坏系统的稳定性,还需要有一个“规范树”或“标准树”。这个树是系统的基础树,用户只能在此基础上进行修改,而不能随意改变其结构。
- 这个“标准树”是整个系统的核心,它确保了调试数据的正确性和一致性,避免了可能的错误或不一致性。
-
树状结构中的元素层级:
- 在调试树中,元素的层级关系非常重要。例如,可以有一个根元素“ground chunks”,其下可能包含多个子元素如“checkerboards”。每个子元素可以具有不同的状态或属性(比如开关状态)。
- 这些元素和它们的状态是动态更新的,可以通过UI进行交互修改。而“标准树”确保了这些元素的层级和关系始终保持一致,避免因用户操作导致的不稳定性。
总结
这种重构的设计思想主要集中在以下几个方面:
- 哈希表:通过哈希表管理调试元素的唯一标识符,实现快速查找和插入。
- 树状结构:调试元素会组织成树状结构,这有助于清晰地展示和管理元素之间的关系。
- 用户界面和视图哈希:视图哈希负责管理UI的状态,使得调试元素的显示和交互更加直观。
- 标准树和交互限制:引入一个“标准树”作为调试元素的规范,防止用户随意修改核心数据结构,保证系统的稳定性。
整体而言,这种设计将极大简化调试元素的管理,增强系统的灵活性和可维护性,同时避免了过去因计数器和复杂数据结构带来的问题。

game_debug.h: 向 debug_state 添加 debug_tree *RootTree
除了元素哈希表,我们还需要一个单独的调试树,作为根树(root tree),这个树的作用是为调试元素提供一个结构化的组织方式。具体来说,这个调试树用于存储元素的层级关系,当新的调试元素到来时,我们会通过名称匹配的方式将其插入到合适的位置。这是为了确保每个元素在树中的位置是正确的,并能够按照一定的规则进行更新和查询。
这个调试树的设计目的有两个主要方面:
-
元素的插入与位置确定:
- 每当一个新的调试元素出现时,系统会通过名称匹配(例如元素的名字或某种标识符)来找到它应该插入树中的位置。
- 这种方式确保了调试树在不断增长的过程中能够保持结构的完整性,避免乱序或不一致。
-
与元素哈希表的配合:
- 调试树本身是为了组织调试元素的结构化数据,而哈希表则负责存储和快速访问这些元素。
- 哈希表作为一种高效的查找方式,保证了可以根据唯一标识符快速找到调试元素的具体数据。而调试树则提供了一个更具层级性和结构化的视图,帮助开发人员更清晰地了解元素之间的关系。
因此,除了哈希表存储调试元素,我们还需要一个根树,用来维护元素的层级关系和顺序。这个树将帮助系统在动态插入新的调试数据时,保持元素的组织性和可追溯性。

game_debug.h: 减少 ElementHash 数组的大小
对于调试元素哈希表,有一个考虑是,哈希表的大小应该控制在一个适中的范围内。原因在于,调试系统中的哈希表可能会频繁被迭代,尤其是当需要释放内存时,必须遍历哈希表中的元素并进行清理。因此,如果哈希表过大,频繁的内存回收操作会变得低效。
在实际使用中,调试点的数量通常不会很多,代码中涉及到这些调试点的地方相对较少。因此,虽然遍历哈希表可能会有一定的性能开销,但由于元素数量有限,遍历的开销应该是可以接受的。
此外,虽然可以通过优化来减少性能开销,但考虑到调试系统的主要目的是为开发人员提供帮助,并且最终用户不会直接使用这些代码,所以在性能上不必过于苛刻。只要调试系统足够快速,能够在调试过程中提供及时反馈,就已经足够满足需求,不必追求极致的优化。

game_debug.cpp: 重写 FreeFrame
在处理内存释放时,特别是在释放某个帧的调试信息时,思路是首先通过一个循环遍历调试状态中的哈希表,查找所有存储的调试事件,并按帧索引判断哪些事件应该被释放。具体过程如下:
-
遍历哈希表:通过调试状态中的元素哈希表,遍历每个存储的调试元素。
-
查找事件链:每个调试元素都有一个事件链,事件链中的每个事件都有一个帧索引。遍历事件链,检查每个事件的帧索引。
-
判断是否需要释放:对于每个事件,如果它的帧索引小于或等于当前正在释放的帧索引,那么就可以释放这个事件。释放时,通过一个
while循环判断是否满足条件:即检查事件的帧索引是否小于或等于当前帧的索引。如果满足条件,释放这个事件。 -
更新指针:当释放某个事件后,需要更新指针,确保链条正确连接。具体来说:
- 如果当前释放的事件是当前调试元素的最旧事件(
oldest event),则更新最旧事件指针为下一个事件。 - 如果释放的是当前调试元素的最新事件(
most recent event),则相应地更新最新事件指针为NULL。
- 如果当前释放的事件是当前调试元素的最旧事件(
-
回收内存:释放的事件会通过一个内存池进行回收。这样,这些事件对象会被重新加入到内存池中,以便未来的使用。
-
处理新的事件:虽然目前假设在释放帧后不会有新的事件被添加到该帧中,但为了保险起见,可以在代码中添加一个机制,确保即使新事件在之后到达,也能被适当处理和清理。
总结来说,释放一个帧的调试信息的过程就是遍历该帧中的所有事件,找到那些帧索引小于或等于当前释放帧的事件并清理它们,同时更新相关的指针。最后,所有被释放的事件会被加入内存池中以供复用。这种方法保证了调试数据的内存管理,并确保了不会有过多的内存占用。


game_debug.h: 向 debug_state 添加 debug_stored_event *FirstFreeStoredEvent
在释放帧之后,我们会进入一个新的阶段:重新利用释放出来的调试事件存储结构。整个逻辑围绕着一个“事件内存池”(即一个自由链表)来展开,用于高效管理和复用调试事件的内存,以避免频繁的内存分配和释放。
具体机制如下:
-
维护自由链表:我们维护一个
debug_stored_events类型的自由链表指针,比如叫first_free_stored_event。这个链表保存了当前所有可供复用的调试事件节点。 -
释放帧时加入自由链表:在释放某一帧的过程中,把不再需要的事件节点从其所属的元素事件链上摘除,并加入到这个自由链表中,供后续复用。
-
复用事件节点:当新的调试事件发生、需要存储时,就不再新建一个事件结构体,而是直接从自由链表中取出一个已有的节点进行复用。这种做法可以显著减少内存分配的开销,提升运行效率。
-
典型使用场景:
- 在调用“决策器”或类似的逻辑处理函数时(如打分排序、状态存储等),需要记录新的事件。
- 此时,从
first_free_stored_event中弹出一个空闲的节点。 - 填写该节点的数据(比如事件类型、时间戳、帧索引等)并将其插入目标调试元素的事件链上。
-
内存安全:整个流程中会确保链表连接正确,避免悬挂指针或内存泄漏。比如在从链中弹出一个节点时,会将其从自由链表中移除并清理指针;在释放帧时也会正确更新链表末尾。
-
目的与优势:
- 避免频繁的内存分配与释放操作。
- 提高调试系统的性能和响应速度。
- 保持内存使用的可控性和可预测性,防止长期运行中内存碎片过多。
总之,在帧释放的基础上引入自由链表机制,形成了一个完整的调试事件存储回收和再利用系统。每次释放帧时就将相关事件回收,每次记录新事件时就从池中取用,实现了内存高效利用与系统稳定性。


game_debug.cpp: 删除 HackyGroup
现在我们需要继续推进并完成剩下关于 group(组)相关的部分处理。
我们重新审视了之前的逻辑,主要围绕“树(tree)”结构与变量组(variable group)的关系展开。我们开始质疑树结构是否还有必要保留,并进行了如下分析与处理:
1. 关于树结构的功能与必要性
我们回顾了树结构的实际用途,发现它基本没有承担任何关键功能,似乎只是简单地记录了某个节点“原本在什么位置”之类的信息。从目前逻辑来看:
- 树结构并没有承担变量组织、状态维护或逻辑分派等职责;
- 所有实质性的行为基本都已经转移到了变量组(variable group)及元素哈希(element hash)中;
- 因此可以判断:树结构已经没有存在的必要。
2. 移除树结构相关代码
基于以上判断,我们决定完全移除树相关的内容。这些结构与相关处理逻辑被彻底删除,以简化系统并减少维护成本。
- 所有 debug tree 的定义、处理逻辑、使用点都已清理;
- 不再调用创建、遍历或操作 tree 的任何接口;
- 所有变量和状态现在都通过变量组和 element hash 来处理。
3. 重新整理变量处理逻辑
在清理树结构之后,我们着手修正变量相关的逻辑,特别是对旧有调试变量系统的清理与替换。
- 原来存在一个旧式的变量管理机制(如 game variable / debug variable),我们确认已经完全移除;
- 原先还引用的一些变量定义文件和结构已不再被使用,也已经清理;
- 变量的创建方式也被更新:不再手动显式创建调试变量项。
4. 变量的当前生成逻辑
我们检视了 create_variable 的调用与定义逻辑,发现现在的系统架构下已经不再需要显式地调用该函数来生成变量。
- 原因是我们已经取消了“变量是主动生成并注册”的旧机制;
- 新机制是基于观察到的事件和状态自动插入到
ElementHash中; - 所以,调试变量不再通过调用
create_variable创建,而是在数据流中自动生成并注册。
5. 接下来的修复任务
虽然树和旧变量系统都已移除,但部分代码依旧保留了旧逻辑,例如“collation(归集整理)”的处理方式仍旧使用旧模型。
- 这些地方仍需修复,使其适配
ElementHash和事件驱动的调试数据模型; - 当前部分变量分组、分类方式仍旧在用旧方法处理,需要根据新的架构重新整理;
- 后续将聚焦于将这些旧接口或功能点逐步替换为与
ElementHash和变量组统一管理逻辑相匹配的形式。
总结:我们已经完成了树结构和旧调试变量系统的清理工作,并对变量管理逻辑进行了现代化重构。后续的工作重点是进一步清理与修复遗留的旧式处理逻辑,确保整个系统基于 ElementHash 和变量组的统一架构正常运行。

game_debug.cpp: 考虑移除 Region 的概念,并将所有 BeginBlock 和 EndBlock 发送到 ElementHash 中
现在我们的系统架构进一步简化与统一,所有与事件(event)相关的数据处理逻辑都将在一个核心位置集中完成,这个位置正是用于接收与处理调试事件的主要入口。
1. 事件处理的统一入口
目前,所有事件数据的处理将统一集中在一个位置完成:
- 当一个事件到来时,如果它是某种数据类事件(即需要被存储的),就会在这一逻辑点被处理;
- 不再区分原先不同类别的事件处理流程,例如不再特殊处理类似
begin block或end block类型的事件。
2. 关于 block 区块事件的新处理方式
原本对于 begin block / end block 事件,会以创建“区域(region)”的方式进行特殊处理。但现在我们重新设计了这一流程:
- 决定完全移除 region 的概念;
- 不再为其设计单独的数据结构;
begin block和end block将被当作普通事件一样处理与存储;- 它们会被统一存入
ElementHash中,作为某个 key 对应的标准事件链的一部分。
这样做的好处是:
- 所有事件的处理逻辑得以统一,简化了代码;
- 不再需要维护一套专用于 block 区域的额外结构;
ElementHash成为所有事件状态的唯一容器,增强系统一致性。
3. 简化结构,统一事件流模型
整体而言,这些变化意味着:
- 整个调试系统的数据流进一步简化;
- 不再有区域、变量、树等独立结构,取而代之的是统一的元素哈希表;
- 所有事件不论类型如何,都会以一致的形式存入该表;
- 存储、清理、遍历等操作都集中围绕
ElementHash实现。
4. 后续优化可能性
虽然目前已实现逻辑统一,但未来仍可以在不改变结构的前提下优化性能,例如:
- 针对 block 事件在视觉表现或调试工具中的处理做高层封装;
- 在 hash 存储逻辑内部添加标志位或元信息,简化后续识别;
- 如有需要,也可设计辅助索引加速查询,但不影响主流程结构。
总结:我们已经将 begin block / end block 等事件完全纳入标准事件流模型中,不再为其保留特殊结构或逻辑。所有事件现在统一通过 ElementHash 存储与管理,形成一个简洁、高一致性的调试系统架构。
向着一个连贯的架构迈进
我们现在对整个架构的满意度正在逐步提升,感觉一切正在往正确的方向发展。虽然花了很长时间才逐步摸索出合适的结构,但如今系统开始变得清晰、有条理,并逐渐呈现出应有的形态,这种转变令人非常欣慰。
1. 结构逐渐清晰带来的信心提升
- 一开始我们其实并不确定是否已经抵达理想的系统架构。
- 经常会遇到一种情况:觉得架构还差点什么,说不上来具体哪里不对,但就是不够清晰、不够协调。
- 然而现在不同了,我们开始真正感受到一种结构“落地”的踏实感,说明我们正朝着合理、有效的体系靠近。
2. 长期架构经验帮助我们识别“不对劲”的架构
- 虽然无法总是确定是否已经找到了最优解,但凭借以往处理架构问题的经验,我们有足够的直觉去判断当前的架构是否“还不行”。
- 在之前,我们知道还没达到那个“可以接受的最低标准”,很多部分仍然混乱、职责模糊。
- 一直到最近,我们才逐步建立起这样一个明确的三层模型结构,才开始逐步打破之前的不确定性。
3. 三个核心组件让系统概念清晰化
现在整个系统清晰地分成了三部分,各自职责明确,关系清楚:
- 事件缓冲区(events buffer):记录调试过程中产生的所有原始事件,是数据来源。
- 静态命名结构(static naming of debug points):为调试点提供统一、稳定的名称,构成逻辑结构上的锚点。
- UI 层级结构(UI hierarchies):用于展示和组织调试信息的可视化结构,与用户交互密切相关。
这三者之间的区分和关系形成了稳定的框架:
- 事件流存储;
- 命名规则建立;
- 结构层次展现。
这一切的逻辑都开始清晰地连接起来,互不混淆,各自独立但又彼此支撑。
4. 现在任务聚焦在“实现一个合理的版本”
- 架构已经基本确定,现在不再是混沌不清、方向模糊的阶段;
- 接下来的重点是:用一套可接受的方式实现这个架构;
- 我们不追求极致优化或完美抽象,而是首先实现一个“足够好用”的版本;
- 一旦有了清晰结构,后续优化、重构、拓展都将更加有的放矢。
总结:现在整个系统架构已经走出了混沌,形成了清晰的三层结构思维,架构感也变得稳定可控。我们不再纠结于“是否还缺点什么”,而是聚焦于“怎么把这套思路实现得足够合理”。这种状态非常关键,是从“不断试探”进入“明确落地”的标志性节点。接下来我们只需继续推进实现的细节,就能稳步构建出一个实用、高效、清晰的调试系统。
game_debug_interface.h: 找出如何唯一标识事件
我们目前对 open data block 和 close data block 的处理,其实核心用途只是为了构建调试信息的层级结构,用于展示时进行父子关系的组织。它们的唯一重要作用,是帮助我们理解哪些调试信息是嵌套的、属于哪个“父”代码块。因此,它们的使用更像是一种组织手段,而不是实际的数据载体。
当前调试系统中的数据来源分析:
我们检查了实际传入的数据种类,发现目前我们真正接收到的数据,只有 debug_value 类型的事件:
- 调试变量(debug_variable) 并不会从程序端回传到调试工具端。
- 调试值(debug_value) 才是调试信息的实际传输通道,并且是双向同步的一部分。
- 因此,在 frame 刷新过程中,我们只会接收到
debug_value类型的事件,其它调试结构是不会反复传输的。
debug_value 的接收处理方式:
我们在接收数据时,大致流程如下:
- 开始解析数据块(open data block);
- 接收到的
debug_value数据类型被标记和解析; - 将其存入对应的事件列表或调试结构中;
- 结束数据块(close data block)。
目前所有这些处理都是围绕着 debug_value 这一类型在展开。
如何唯一标识 debug_value 事件:
由于 debug_value 并不会伴随静态变量一起发送,因此我们不能通过地址或全局符号的方式来进行唯一标识。但我们可以采用另一种思路:
- 使用文件名 + 行号的组合,来作为唯一标识符。
- 我们甚至可以构造一个更加紧凑的
file:line:counter的字符串来形成哈希键。
这一组合方式可以确保:
- 每个调试点都有一个唯一且稳定的标识;
- 不需要依赖静态变量,也不会污染命名空间或符号表;
- 能够无状态地解析并定位调试信息来源。
关于 RecordDebugEvent 的改进建议:
当前的事件记录逻辑中,RecordDebugEvent 接收的是 file_name,但我们可以进一步增强:
- 可以在调用该函数时,将文件名、行号和局部计数器拼接为一个字符串;
- 该字符串用作调试值的唯一 key,从而进入调试系统的哈希结构中;
- 这种方式兼具唯一性与稳定性,而且适合后续的数据更新或 UI 层级更新。
总结:
我们目前的系统逻辑中,open/close data block 仅用于构建调试信息的层级结构,而真正的调试数据仅由 debug_value 承担。在实现中,我们将摒弃对静态变量的依赖,而使用 file + line + counter 的组合方式来唯一标识每个调试点。这种方式简洁、安全、不依赖外部静态符号,有助于保持调试系统的高可维护性与可扩展性。后续我们只需在事件记录和解析中贯彻这一唯一标识策略,即可构建完整、高效的调试数据体系。


game_debug_interface.h: 向 RecordDebugEvent 添加 GUID
我们可以通过文件名加上一个局部计数器(counter)组合出一个全局唯一的字符串标识符,用来唯一识别每一个调试点。例如,我们构造一个字符串,内容形如:
"<file_path>:<counter>"
这个字符串会具备两个关键特性:
- 文件路径本身具有唯一性 —— 每个源码文件路径是明确的;
- 计数器是编译时自动递增的宏值 —— 保证在同一个文件中每个调试点都有唯一编号。
所以,只要我们把这两者拼接起来,就能够确保每个调试点的唯一性。
技术实现的方式:
- 我们可以使用 C/C++ 宏中的
__FILE__和__COUNTER__实现这一点; - 为了生成字符串,可以定义一个辅助宏来拼接这两个信息;
- 生成的结果会是一个
const char*字符串; - 这个字符串可以作为哈希 key,放入哈希表中用于调试数据的查找与组织。
唯一性保证逻辑:
- 因为
__COUNTER__是一个在预处理期间不断自增的宏,所以每次使用都会得到不同的值; - 即使在同一个文件中多次使用调试宏,也不会有冲突;
- 加上
__FILE__后,即使不同的翻译单元之间有重复的计数值,也不会发生冲突; - 所以这套机制在绝大多数场景下都能保证全局唯一性。
对于 inline 函数的影响:
- 如果调试语句出现在 内联函数中,可能会被多个调用点“复制”进不同的翻译单元;
- 这时,
__FILE__依然是定义 inline 函数的那个源文件,__COUNTER__也是首次定义时的那个值; - 也就是说,如果该函数被多次内联,会出现多个地方共享同一个调试 key;
- 但其实即使换做静态变量的地址作为 key,也会在这种情况下失效 —— 因为静态变量在 inline 函数中通常是“共享”的,地址也会一样。
所以即使 inline 函数中可能存在一定重复,也不比地址法更糟,并且在调试实际过程中,我们通常并不会太在意这种情况下的重复记录。
总结:
通过将文件名与编译时自动增长的计数器组合成字符串,我们可以实现一个在整个程序构建过程中都全局唯一的调试标识符。这个方法实现简单、可靠,不依赖运行时信息,也不污染全局变量命名空间,适用于调试值的唯一性标识。即使在少数特殊情况下(例如 inline 函数多次展开),也不会比传统静态地址标识更差,因此完全可以接受并推广使用。

game_debug_interface.h: #define UniqueFileCounterString
可以通过构造一个 唯一的文件+计数器字符串 来实现调试变量的全局唯一标识。这种方式不仅简单,而且避免了过多依赖其他信息,能够在编译期直接生成所需的唯一值。
具体做法如下:
定义一个用于生成唯一字符串的宏,比如:
#define UNIQUE_FILE_COUNTER_STRING __FILE__ "(" __LINE__ ")." __COUNTER__
或者分成多个步骤宏展开拼接,这种做法虽然繁琐(因为宏不支持字符串拼接中的变量替换),但已经是 C/C++ 中用于生成编译期唯一标识的通用“技巧”。虽然实现上略显笨拙,但非常实用。
构造的字符串格式如下:
"<文件路径>(<行号>).<计数器编号>"
例如:
"src/debug/logger.cpp(127).5"
这个字符串具备几个显著优势:
-
全局唯一性:
- 文件路径唯一;
- 行号定位到代码中具体的某一行;
- 计数器可以防止同一行写了多个调试点时发生冲突。
-
可读性强:
- 一眼可以看出这个调试变量是在哪个文件的哪一行生成的;
- 点号后的计数可以提示这是该行上第几个调试声明,方便排查。
-
简化数据发送:
- 一旦这条唯一的字符串生成后,在调试系统内部就可以不再重复传输
__FILE__和__LINE__; - 减少通信成本,提高效率。
- 一旦这条唯一的字符串生成后,在调试系统内部就可以不再重复传输
应用场景举例:
- 用这个唯一字符串作为哈希表中的 key,储存每个 debug 值;
- 用作调试记录或 UI 显示标签;
- 可在程序运行时直接通过该 key 快速定位和访问对应数据。
兼容性说明:
- 即使这个调试语句被写在 inline 函数中,也不会造成严重问题;
- 因为 inline 函数的内容通常来自同一个文件,同一个代码行,且计数器依然是编译期处理的;
- 如果出现多个调用展开,那它们本身在可调试性上也是等价的,使用相同标识是可接受的;
- 如果某些极端情况真的要求区分不同展开点,那可以进一步引入
__FUNCTION__或其他额外上下文信息,但大多数时候这不是必要的。
总结:
通过拼接 文件路径 + 行号 + 编译计数器 构造出唯一字符串,可以非常高效且安全地标识每一个调试变量。这种方式不仅避免了地址重复、变量污染,还具备优秀的可读性和灵活性。是构建调试系统、事件记录、可视化工具等基础设施时非常推荐的方案。

game_debug_interface.h: 移除 FileName 和 LineNumber
如果我们采用这种方式(使用唯一的文件 + 行号 + 计数器字符串作为标识),那么之后所有的调试数据都会包含一个唯一的 ID(我们称之为 GUID),这样整个流程就变得更加简洁和高效。
具体好处如下:
-
每个事件都具备唯一标识:
使用GUID之后,不需要再依赖其他外部信息,就可以唯一识别每一个调试事件或变量。 -
简化系统结构:
原本为了识别调试事件所使用的额外字段,比如某些变量名、函数名、路径信息等等,都可以被替代或者简化;- 比如,原本用于识别块的名称等信息可以选择保留(如果在其他地方还有用途),但不再是系统唯一性识别的必要条件;
- 所以那些辅助信息字段可以直接去除。
-
节省内存和带宽:
不再需要每次事件都传递完整的文件路径、行号等长文本信息,只需要传一次GUID;- 数据更小;
- 带宽更低;
- 系统响应更快。
-
统一调试数据入口:
所有的调试数据,不论是变量的值、事件的触发,还是块的开始结束等,都可以统一通过GUID作为 key 写入 hash 表;- 利用
GUID进行查找和更新; - 实现调试状态的完整管理;
- 清晰可控。
- 利用
新的处理逻辑简述:
- 在数据进入系统的地方(例如事件处理器或调试写入函数),统一根据当前文件名、行号、计数器生成
GUID; - 使用这个
GUID作为 hash 表的 key 进行存储; - 原先需要判断事件类型、解析变量名、比较路径信息等操作可以简化或去除;
- 后续展示、筛选、查询也可以基于
GUID快速定位。
额外保留的信息:
虽然大部分内容可以删除,但也有些内容可能需要保留,比如:
- block 名称:
用于用户界面展示或某些调试逻辑场景中仍有意义;- 比如用来分组显示;
- 或者用来表示某些逻辑块的含义。
这些可以按需保留,但不会再承担标识的作用,只是作为附加信息存在。
总结:
系统改为使用 GUID 之后,所有调试数据都可以通过统一的方式进入 hash 表,极大地提高了结构清晰度、运行效率和逻辑简洁性。
多余的信息字段可以被剔除,系统开销更小。
唯一性也不再依赖复杂路径或静态变量地址,完全由编译期保证,实现更稳健的调试数据处理机制。

game_debug.cpp: 引入 HashThisEvent,但关闭 GANE_INTERNAL
目前我们已经基本完成了结构重构,系统整体状态良好。尽管还有一些细节尚未完全处理,例如缓存相关机制等,但现阶段的主要架构部分已经进入一个稳定构建状态。
为了保持当前构建的稳定性,暂时关闭了 GAME_INTERNAL 标志,确保编译通过,系统能正常运行。尽管还有待完善的内容,但这样可以在后续继续开发时有一个清晰的起点。
由于时间有限,每天只能投入大约一小时的开发时间,因此进展会相对缓慢。但整体方向清晰,只要有更多的编程时间,就能继续推进剩余工作。
当前状态总结如下:
- 架构已经成型:核心结构已经搭建好,主要机制运作清晰;
- 调试系统整理完毕:事件结构、唯一标识、数据分组逻辑都已经完成;
- 非关键功能暂时关闭:如
GAME_INTERNAL,为了稳定构建先行关闭; - 缓存等次要逻辑待开发:例如一些优化项、缓存策略尚未着手;
- 后续只需继续填充细节和功能实现:整体框架已搭建完毕,剩余工作以代码填充为主。
整体而言,系统已经站在一个良好的基础之上,后续只需逐步推进就可以完成剩余目标。
对于 UI 编程,你怎么看 MVC(模型视图控制器)模式?它在实际应用中有用吗?
我们认为 Model-View-Controller(MVC)这种模式基本上是一个接近正确、或至少是一个非常不错的方式来看待 UI 架构的。但它并不是完全准确的表达,因为其中的一些部分——尤其是 Controller 的角色和实现方式——往往在实际使用中显得模糊,缺乏清晰的定义和操作逻辑。
我们在理解 UI 架构时,通常会非常认可 MVC 中的 Model 和 View 两部分:
- View(视图):这部分很明确,就是我们用来渲染界面内容的部分。它负责将数据以可视的方式展现出来,是整个 UI 表现层的主要组成。
- Model(模型):我们理解为背后的数据结构或数据库,也就是视图所依据的数据来源。我们在操作 UI 的时候,实质上是对这个数据模型进行编辑。
所以这两部分——Model 和 View——的抽象是合理的,且在实践中具有很强的现实意义。
问题更多出现在 Controller(控制器) 上:
- 在实际应用中,Controller 的定义通常不够明确。它被描述为独立于视图的逻辑处理模块,但我们发现,这其实很难做到完全分离。
- 实际上,Controller 的一部分功能常常嵌入到了 View 里面,特别是输入事件的响应、控件状态的处理等,基本上都与 View 紧密耦合。
- 此外,Controller 实际上也分成两类功能:一部分是和视图逻辑绑定的事件处理器,另一部分则是通用的逻辑控制。传统 MVC 并未对这种拆分给出很好的定义。
因此我们倾向于更具体、更清晰的命名方式,比如将 Controller 明确拆解成:
- 输入处理器(Input Processor)
- 交互操控器(Manipulator)
- 视图逻辑器(View-bound Logic)
这样会更真实地反映出它在系统中的角色。
综上所述,尽管 MVC 是一种非常古老的架构模式,但其基本思想仍然是非常优秀的。只是在实际应用中,需要特别小心 Controller 部分的含义,避免掉入“术语陷阱”,导致架构不清晰或者模块耦合混乱。
我们会更倾向于在实际设计中,将这个模式适当延展和重新命名,使它更贴合系统实际的运行机制和职责分离逻辑。
能否谈谈你之前做过的其他调试系统?我做过各种调试系统,不像你现在做的这个,我很好奇你可能做过的其他一些系统(简要描述即可,一句话就行)。谢谢!
我们曾经处理过各种不同类型的调试系统,每个都在不同的环境下应用,有些跟当前正在做的事情相似,也有一些完全不同,涵盖了从简单日志记录到复杂的实时调试系统等各个方面。
一个比较有趣的例子是在“Granny”项目中,我们设计了一个相对独特的调试系统。这个系统允许我们通过调用 DLL 的接口来获取调试信息,基本上可以实时查看正在运行的“Granny”应用程序的内部数据。具体来说,系统会提供一个调试视图应用程序,可以显示当前运行中的所有数据。通过这种方式,我们可以外部查看正在执行的应用程序的所有内容,类似于一个实时的调试工具。这种方法很有趣,因为它允许我们在应用运行时进行数据检查,而无需暂停或中断程序。
此外,还做过类似当前项目中事件流调试系统的事情,虽然其实现方式有所不同,但基本的概念类似。我们也曾设计过基于日志记录的调试系统,这类系统将事件或调试数据流式记录到日志中。这些系统通常比较简单,但也具有一定的实用性。目前正在为某个代码库开发的调试系统与这些有所不同,它主要是基于可扩展缓冲区的方式处理数据,具有一些特定的目标和需求,比如更像操作系统级的内核日志记录工具。
一个较为复杂和具有挑战性的项目是关于“Mustache”的调试系统。这是一个涉及到更高阶的调试工具,它的功能看起来有些魔法般神奇,实际运作时提供了一些非常强大的功能。比如,它能够追踪屏幕上的某个像素,并且告诉你这个像素是如何生成的,这实际上类似于某些复杂的调试工具,如 Pix 或其他图形调试系统。这种调试系统不仅能对图形渲染进行追踪,甚至可以应用到整个代码库的调试中,提供全方位的调试信息。这种方式大大增强了调试的可视化和实时性。
这些调试系统的设计和实现涵盖了从简单的数据记录到复杂的实时追踪等多种方式,每一种都有其独特的应用场景和目的,能够在不同的开发阶段和需求中提供有效的帮助。
Pix 是一个由微软开发的图形调试工具,主要用于 Windows 平台上的图形应用程序,特别是涉及 DirectX 的游戏和图形应用程序。它提供了强大的功能,用于捕获、分析和调试图形应用程序中的图形调用(如绘制命令、着色器等)。
Pix 的主要功能包括:
-
帧捕获与回放:
- Pix 可以捕捉一个帧的所有图形调用,并将其记录下来。这允许开发者在图形渲染的过程中回溯并检查每一个渲染命令的执行顺序和效果,从而帮助定位和解决渲染相关的问题。
-
GPU 性能分析:
- Pix 提供了详细的性能数据,可以帮助开发者分析 GPU 的工作负载,并识别潜在的性能瓶颈。这些信息对于优化图形性能至关重要。
-
着色器调试:
- Pix 允许开发者对 GPU 上运行的着色器进行调试,开发者可以逐步执行着色器代码,检查变量值,并分析渲染过程中的每个步骤。这对于解决图形中的视觉错误和优化渲染效果非常有帮助。
-
渲染状态检查:
- Pix 可以帮助开发者查看每个图形调用的渲染状态,如纹理、渲染目标、深度缓冲等。通过检查这些状态,开发者可以了解渲染输出的每一个细节,帮助排除问题。
-
捕获和分析 DirectX 12 和 Vulkan 应用程序:
- Pix 支持捕获和分析 DirectX 12 和 Vulkan 的应用程序,适用于现代图形 API 的调试和优化。
-
图形数据的详细视图:
- Pix 提供了对图形数据的详细视图,包括每个渲染调用的输入、输出数据、缓冲区内容等,帮助开发者更全面地理解图形渲染的过程。
总结:
Pix 是一个强大的工具,专门为 Windows 上的图形开发和调试设计,特别是那些涉及 DirectX 和 Vulkan 的应用程序。它为开发者提供了全面的图形性能分析、调试和优化功能,使开发者能够更轻松地找到并解决渲染相关的问题。
能否解释一下宏的“讨厌”之处?为什么有两个下划线“层级”?
在讨论宏定义时,提到了一个与C++预处理器的行为相关的问题。预处理器在处理传递给宏的变量时,表现出不同的行为,特别是在变量被多次传递的情况下。这种行为可能会导致一些不容易理解的现象。
-
宏替换的复杂性:
- 预处理器会将传递给宏的变量看作是两个不同的对象:一个是宏定义中的变量,另一个是宏替换后的结果。第一个传入的参数通常只是作为一个占位符,预处理器将其替换为实际的内容,但这个替换在第一次使用时并不会直接变成预期的值。相反,它会被替换成一个以“__”为前缀的变量名。
-
宏的实际行为:
- 比如,当宏传入一个参数(如行号)时,如果直接传递该参数,可能会得到的是带有“__”前缀的字符串(比如“line”)。然而,第二次传入时,预处理器会将其转换成实际的值或表达式。因此,在编写宏时,需要对传入的每一个变量的使用方式非常小心。
-
宏中嵌套的多次替换:
- 为了确保替换结果符合预期,有时需要将变量传递两次或者通过额外的替换步骤来避免预处理器的干扰。这种多次替换的行为就是所谓的“宏的嵌套替换”。例如,在某些情况下,宏的参数可能需要被“额外”传递一次,这样可以避免预处理器错误地处理变量。
-
理解预处理器的规则:
- 由于预处理器的行为在不同的情况下可能会有所不同,因此在编写宏时,很难一开始就完全记住所有规则。常见的做法是加入一些额外的步骤或参数,尽管这些可能并不总是必要的。这样做是为了确保宏在每次使用时都能正确地处理和替换变量,避免预处理器的替换规则出现不符合预期的情况。
总结来说,C++预处理器在处理宏定义时的复杂性,特别是在多次传递参数时的替换行为,可能会导致一些难以预见的问题。在使用宏时,需要谨慎处理每一个参数的传递和替换过程,以确保最终结果符合预期。
这里是一个关于C++宏的例子,展示了宏预处理器如何在多次传递变量时处理它们,以及如何引发一些不可预见的行为:
示例 1:宏替换中的问题
假设有一个简单的宏,它尝试将传递给它的行号打印出来:
#include <iostream>
#define PRINT_LINE(x) std::cout << "Line: " << x << std::endl;
int main() {
PRINT_LINE(__LINE__);
return 0;
}
输出:
Line: 7
在这个例子中,__LINE__ 是一个内置宏,它在每一行代码中被预处理器自动替换为当前的行号。在调用 PRINT_LINE(__LINE__) 时,__LINE__ 被替换为当前行号 7。
示例 2:宏参数的多次传递引起的替换错误
接下来,假设我们想要在宏中传递行号和列号,但我们误用了宏的参数传递方式:
#include <iostream>
#define PRINT_FILE_AND_LINE(file, line) std::cout << "File: " << file << ", Line: " << line << std::endl;
int main() {
PRINT_FILE_AND_LINE(__FILE__, __LINE__);
return 0;
}
输出:
File: "main.cpp", Line: 13
在这个例子中,__FILE__ 和 __LINE__ 是预定义的宏,它们分别代表文件名和当前行号。此时,PRINT_FILE_AND_LINE(__FILE__, __LINE__) 被正确地替换为 File: "main.cpp", Line: 13。
示例 3:错误的宏替换导致问题
现在,假设我们定义了一个稍复杂的宏,它试图通过宏参数进行多次传递:
#include <iostream>
#define DEBUG_VAR(var) std::cout << "Value of " #var " is " << var << std::endl;
int main() {
int a = 10;
DEBUG_VAR(a);
return 0;
}
输出:
Value of a is 10
此时,宏 DEBUG_VAR(a) 被替换为 std::cout << "Value of " "a" " is " << a << std::endl;,输出的内容就是 Value of a is 10。这是因为 #var 用于将宏参数转为字符串,这样 a 就被转化为 "a",然后宏正确输出了变量 a 的值。
示例 4:宏多次替换的问题
接下来,假设我们没有正确处理宏中嵌套的替换步骤:
#include <iostream>
#define PRINT_WITH_REPLACEMENT(x) std::cout << "Replacement: " << __LINE__ << std::endl;
#define CALL_PRINT() PRINT_WITH_REPLACEMENT(__LINE__)
int main() {
CALL_PRINT();
return 0;
}
假设你期望 CALL_PRINT() 会打印出某个特定的行号,但输出可能不是你预期的:
输出:
Replacement: 12
在这个例子中,CALL_PRINT() 调用了 PRINT_WITH_REPLACEMENT(__LINE__),而 __LINE__ 被预处理器替换为当前的行号。在预处理器执行替换时,它实际上会将 __LINE__ 替换为当前的行号 12,这意味着最终输出的行号是 12,而不是你原本期望的其他值。
总结
这些例子展示了宏如何在多次传递时被预处理器替换,特别是在传递参数、字符串化以及嵌套宏时可能会导致不可预期的行为。要避免这种情况,需要在使用宏时小心处理每个传入的参数,并确保理解预处理器如何在每次替换时工作。
你认为你的引擎让新程序员可以轻松地加入并添加功能吗?
在讨论引擎是否易于新程序员加入并添加功能时,表示并不关心这个问题,因为目前项目中没有其他程序员参与,因此这个目标并不重要。相反,更关心的是自己能否轻松地进入并添加功能,这才是主要关注的点。
我在 OpenGL 中实现阴影贴图。似乎有很多问题和伪影:阴影痤疮、彼得泛滥等,为了绕过这些问题,你最终会得到更复杂且昂贵的解决方案。我有点难以相信图形不错的游戏使用这种技术。你知道有什么其他好的阴影实现方法吗?还是我们只能解决它的局限性?
在讨论阴影映射时,首先提到的是硬边阴影与光照遮蔽的区别。硬边阴影相对简单,通常涉及直接光照。虽然阴影映射在理论上很有用,但实际上它常常会带来很多问题,尤其是当试图通过技术(如级联阴影映射)来提高分辨率时,这些问题变得更加复杂和麻烦。尽管这些方法能有所改善,但它们本身也非常复杂,且并不是一种理想的解决方案。
目前,许多人开始尝试利用光线追踪技术来处理阴影,尤其是在有足够计算能力的情况下。光线追踪可以减少分辨率的伪影问题,因此,未来可能会有更多的游戏采用光线追踪来实现直接光照。现在的计算能力已经足够支持直接光照的光线追踪,但对于间接光照(如环境光)等其他类型的光线追踪,计算资源仍然是一个限制。
尽管光线追踪可以提供更好的质量,但它的实现并不简单。尤其是当试图在3D硬件上完全实现时,仍然存在很多复杂性,比如构建加速结构或使用体素光线追踪(Voxel ray tracing),这种技术通过将三角形数据转化为体素网格进行处理。这些方法虽然可以解决一些问题,但也引入了更复杂的计算和技术需求。
最终,阴影映射的一个优势在于它的前向映射特性。通过将三角形数据直接输入阴影映射系统,而不需要额外的空间划分或加速结构,就能够高效地进行阴影计算。相比之下,光线追踪等方法虽然可以产生更高质量的阴影,但也需要更多的计算资源和更复杂的系统来处理空间查询等问题。
移动平台是否仅限于安卓(不包括 iOS)?有什么特定原因吗?
在讨论平台支持时,明确表示只会支持开放平台,而不会支持封闭平台。特别是对于iOS平台,之所以不支持,是因为苹果的政策不允许用户直接将应用程序加载到设备上,除非设备被越狱(即通过绕过苹果的限制来修改设备的操作系统)。这种行为直到最近才被库协会通过豁免,否则它实际上是非法的。由于苹果的开发者政策被认为是反开发者的,因此只要苹果不改变这种政策,就不会在任何平台上支持iOS。这种决策反映了对开放平台的偏好,并明确表示只支持那些允许用户自由安装应用的系统。
那如果我们只模糊阴影的边缘呢?(高斯模糊)
讨论阴影问题时,指出问题的根本并不在于阴影的边缘是否模糊。使用高斯模糊并不能解决问题,因为阴影问题的根本原因在于深度信息的分辨率不足。即便对阴影边缘进行模糊处理,结果依然是会出现模糊的闪烁,而不是更平滑、稳定的效果。问题不在于边缘是否硬,而在于闪烁本身。深度分辨率不足是导致阴影效果不理想的主要原因,而模糊只会加重这种问题。
你认为命名空间真的解决了命名冲突的问题吗?还是不需要它们,通常的 C 风格的 ‘SystemName_Function’ 就足够了?
讨论命名冲突时,提到有一种方法可以帮助解决命名冲突问题,但并不是每种情况都需要这样做。通常的命名约定(比如下划线命名法)已经足够处理大多数命名问题。而一些新的命名方式确实有一点优势,比如可以避免使用using声明来引入功能,且不需要在名称中添加下划线。然而,这种方法的优势并不足以让人非常关注或强烈依赖,所以虽然它不是完全没有用,但在实际应用中,这种改变的必要性不大。
是的,但 Windows 有什么不同吗,难道不需要在 Windows 上编译 Windows 程序吗?
讨论的核心问题是关于操作系统和平台对于开发者自由的限制,特别是与苹果和微软的政策相比。对于苹果设备来说,如果想将一个程序安装到设备上,开发者必须支付一定的费用,获得签名证书,并且只能在一定的设备数量上安装。除此之外,若想将程序推广到更多设备上,就必须通过App Store。这种做法被视为过于严格,甚至有点“专制”,不被接受。
与之不同,Windows平台没有类似的限制。开发者可以在不支付任何费用的情况下,将自己的程序编译好并直接发送给其他人运行,无需任何权限认证。因此,针对Windows Store的政策,也明确表示不会支持该平台。相比之下,Windows平台的自由度显然更高,因为它不限制开发者如何分发程序。
对于一些平台(例如苹果)来说,规定开发者必须经过授权才能开发和分发程序,这种做法被认为是出于利益驱动的“贪婪”行为,而非经济或市场的自然需求。更进一步,这种行为被视为一种对开发者基本权利的侵犯,就像是对思想和言论的控制,甚至被比作极权主义的压迫。
在此背景下,认为开发者应当拥有自由发布程序的权利,这被视为一种基本的人权。如果硬件平台限制开发者的创作和发布能力,那么这种行为是不可接受的,应该受到强烈的反对和谴责。
解决世界饥饿问题γ
如果一个硬件平台被推出,但却不允许人们在其上进行编程,这种行为被视为无法辩解的错误。这样的限制被认为是出于贪婪或其他不正当动机。对于这种行为,没有任何辩解的余地,因为它直接剥夺了开发者应有的自由。这样的平台没有任何正当理由来支持它们的做法,因此应当受到严厉的批评和抵制。
这种做法被视为对开发者基本权利的极大压迫,甚至比作一种极端的惩罚,类似于将其“碾碎成香肠来喂饱人们”。通过这种夸张的比喻,强调了这种限制对人们创造力和自由的压制是无法接受的。

![python manimgl数学动画演示_微积分_线性代数原理_ubuntu安装问题[已解决]](https://i-blog.csdnimg.cn/direct/91cbb2b855cc414281f519f33a4e280a.png)