GPT-1是OpenAI在《Improving Language Understanding by Generative Pre-Training》中于2018年提出的生成式预训练语言模型。
1.GPT-1 简介
在自然语言处理任务中,存在大量无标签的语料数据,而有标签的语料数据相对较少,因此基于有监督训练的模型性能的提升大大受限于数据集。为了解决这个问题,GPT-1的作者们提出先在大量的无标签数据上训练一个语言模型,然后再在下游具体任务的有标签数据集上进行Fine-Turn。
GPT-1:使用通用的预训练提升自然语言的理解能力,使用没有标号的文本来预训练模型,最后在子任务上微调模型。
2.GPT-1 详情
2-1 GPT的出现
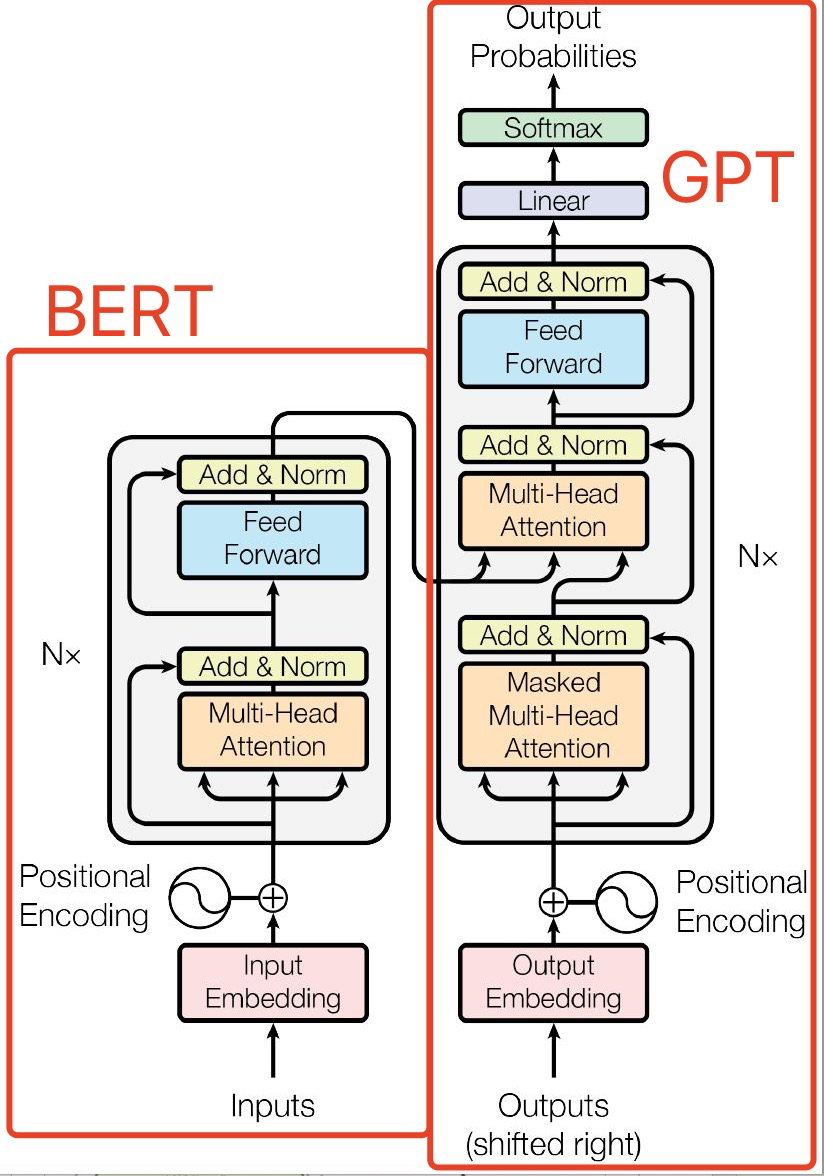
GPT是基于Transformer发展而来。因为Transformer是一个语言翻译模型。其整个模型由编码器和解码器两部分组成,而这两部分的训练方法有所不同。编码器考验的是对语言的理解,所以它使用的方法是完形填空,训练时给出先后文,把中间的字MASK,让模型给出MASK位置的词;而解码器是要根据意思,翻译成另外一种语言,考验的是语言的生成,训练方法是词语接龙,训练时给出前文,让模型给出后续的词。Google和OpenAI分别使用Transformer的编码器和解码器,训练出了自己的语言模型。Google训练的模型重在语言理解,叫做BERT,OpenAI训练的模型重在语言生成,叫做GPT。

2-2 GPT-1结构
GPT-1由12层Transformer Decoder的变体组成,称其为变体,是因为与原始的Transformer Decoder相比,GPT-1所用的结构删除了Encoder-Decoder Attention层,只保留了Masked Multi-Head Attention 层和Feed Forward层。Transformer结构提出之始便用于机器翻译任务,机器翻译是一个序列到序列的任务,因此Transformer设计了Encoder用于提取源端语言的语义特征,而用Decoder提取目标端语言的语义特征,并生成相对应的译文。GPT-1目标是服务于单序列文本的生成式任务,所以含弃了关于Encoder部分,包括Decoder的 Encoder-Dcoder Atcnion层。
GPT保留了Decoder的Masked Multi-Atenlion 层和 Fed Forward层,并扩大了网络的规模。将层数扩展到12层,GPT-1还将Atention 的维数扩大到768(原来为512),将Attention的头数增加到12层(原来为8层),将Fed Forward层的隐层维数增加到3072(原来为2048),总参数达到1.5亿。GPT-1还优化了学习率预热算法,使用更大的BPE码表,活函数ReLU改为对梯度更新更友好的高斯误差线性单元GeLU,将正余弦构造的位置编码改为了带学习的位置编码。
2-2 模型训练
GPT1的训练主要分成无监督预训练和有监督微调两部分:
- 无监督预训练指的是现在大规模语料下,训练一个语言模型;
- 有监督微调指的是基于下游任务的标注数据进行模型参数调整。
2-2-1 无监督预训练
给一组无监督学习语料的tokens:,我们以语言模型的目标函数作为目标,最大化其似然函数:
![]()
k表示窗口大小, P 表示由参数Θ决定的神经网络所输出的条件概率值。
在GPT中,作者对position embedding矩阵进行随机初始化,让模型自己学习,而不是采用正弦余弦函数进行计算。(原Transformer用的三角函数)
从GPT的计算公式来看,其实跟Transformer基本是一样的,只是对每个时间步,都只考虑左侧窗口大小的上下文信息。由于使用了Masked Self-Attention,所以每个位置的词都不会“看见”后面的词,也就是预测的时候是看不见“答案”的,即避免了see themselves 的问题,保证了模型的合理性,这也是为什么OpenAI采用了单向Transformer的原因。
这里再简单用公式阐述下前言中提到的本文核心的多头transformer-decoder层:
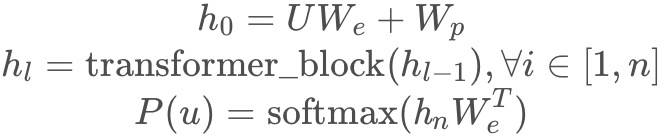
其中是文本的tokens向量,n是transformer的层数,
是token embedding矩阵,
是position embedding矩阵。
2-2-2 有监督学习
在完成了无监督学习后,我们希望在有标签的数据集上对模型进行有监督的微调。我们定义标注数据集为 C,对于每一组序列tokens:,都对应一个标签y。输入
通过预训练模型后得到最后一层transformer层的隐向量
,通过一个线性层+softmax预测标签y:
![]()
为全连接层参数,有监督目标是使下面这个目标函数最大化:
![]()
在有监督微调的训练中,如果加入语言模型的目标函数,可以有两个好处:(a)使得有监督模型具备更强的生成能力;(b)加快训练的收敛。所以我们如下定义最终的目标函数:
![]()
作者并没有直接使用𝐿2,而是向其中加入了𝐿1,并通过𝜆λ调节权重,一般采用0.5。
2-3 GPT 算法关键
无监督训练的模型采用Transformer的decoder,目标函数采用标准的语言模型的目标函数,通过前k个词来预测第k+1个词。目标函数其实是比BERT模型完形填空式(根据上下文信息来预测中间被mask的词)的语言模型目标函数要难,因为预测未来要比预测中间难。这可能也是导致GPT在训练和效果上比BERT差一些的一个原因。 由于是通过前k个词来预测,因此GPT使用的是transformer的解码器(只在当前及之前的特征上做自注意力,之后的都被mask)而非编码器(可以看到全局的特征)。
有监督fine-tune采用标准的分类目标函数。此外,作者发现在有监督训练时额外加上语言模型的目标函数更好,能够提高模型的泛化性和加速模型收敛。
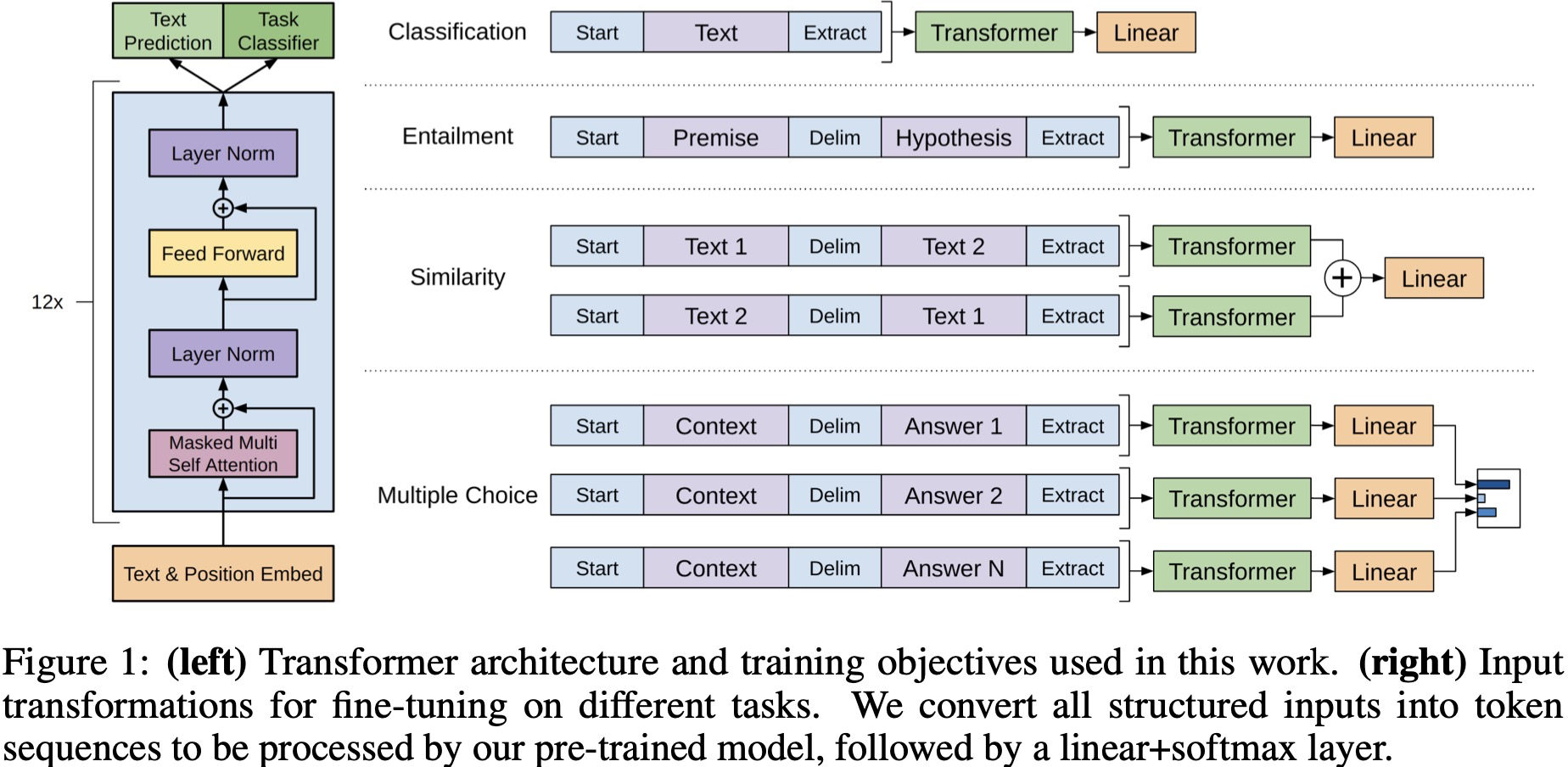
微调:类似BERT,针对不同下游任务采用特殊符号如开始和分隔、抓取等,用prompt提示来分辨任务类型,最后用抓取这一个向量的输出训练一个全连接层解决问题(进行分类)。整个过程只微调模型参数,不改变模型结构。
2-4 针对不同下游任务的输入与输出
对于不同的下游任务,将数据转换成统一的形式送入预训练好的语言模型,因为预训练模型是在连续的文本序列上训练的,需要一些修改才能将其应用于这些任务,之后再接一层线性层进行分类等。可以发现,在fine-tune时,仅需要对预训练的语言模型做很小的结构改变,即加一层线性层,即可方便地应用于下游各种任务。
1.分类任务:将起始和终止的token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接层得到预测的概率分布;
2.NLI任务:将前提和假设同通过分割符隔开,两端加上起始和终止token,再一次通过transformer和全连接得到预测结果;
3.语义相似度任务:输入两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到特征向量拼接后再送给全连接得到预测结果;
4.问答和常识推断:将𝑛n个选项的问题抽象化为𝑛n二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。
具体示例如下图所示,包括了transform层的基本结构(mask多头attention+残差链接+LaryerNorm+FNN)
2-5 补充说明
2-5-1 特定的微调任务
-
1.自然语言推理(NLI):
-
判断两个句子是否包含关系,矛盾关系,中立关系;
-
-
2.问答和常识推理:
-
类似多选题,输入文章,问题以及若干候选答案,输出为每个答案的概率;
-
-
3.语义相似度:
-
判断两个句子语义上是否相关;
-
-
4.分类:
-
判断输入文本是指定的那个类别。
-
2-5-2 训练数据集
GPT-1使用的数据集BooksCorpus,包含7000本没有发布的书籍。使用原因由两点:
- 有助于未见过的数据集上训练语言模型,该数据不太可能在下游任务的测试集中找到;
- 数据集拥有长的合理的上下文依赖关系,使得模型学习更长的依赖关系
2-5-3 实现细节
1.使用字节对编码(BPE:byte pair encoding),共有4000个字节对;
2.词编码长度为768;
3.位置编码也需要学习;
4.12层transformer,每个transformer块有12个头;
5.位置编码的长度是3072;
6.Attention,残差,Dropout等机制用来进行正则化,drop比例为0.1;
7.激活函数GLUE;
8.训练的batchsize为64,学习率为2.5𝑒−42.5e−4,序列长度为512,序列epoch为100。
2-3-6 与BERT对比
1.GPT在预训练时并没有引入[CLS]和[SEP], Bert全程引入;
2.Bert是真正能够捕捉所有层上下文信息的,受益于自注意力机制,将所有token距离直接缩短到1,GPT-1是单向捕捉信息;
3.input: GPT采用BPE, Bert用了Word Piece. GPT有位置编码, Bert有位置编码和段编码.
3.总结
GPT-1模型的核心思想:通过二段式的训练,第一个阶段是利用语言模型进行预训练(无监督形式),第二阶段通过 Fine-tuning 的模式解决下游任务(监督模式下)。GPT-1可以很好地完成若干下游任务,包括分类、蕴含、相似度、多选等。在多个下游任务中,微调后的GPT-1系列模型的性能均超过了当时针对特定任务训练的SOTA模型。
![[建议收藏] Mysql+ETLCloud CDC+Doris实时数仓同步实战](https://img-blog.csdnimg.cn/fd2c0ab9820443faa67d994272223b70.png)