介绍
在SEO(Search Engine Optimization)领域,比较常见的问题之一是如何快速有效地查找出两段文本的不同部分。这对于优化网站内容或对比竞争对手的网站内容都非常有用。Python作为一种强大的编程语言,其特性和库使得这种任务变得相对简单。在本文中,我们将介绍如何使用Python找出不同部分的三种方法。
方法一:基于difflib库的比较
Python的标准库中有一个名为difflib的库,专门用于比较序列之间的差异。我们可以利用这个库去比较原始文本和修改后的文本,并找出它们之间的不同部分。
下面是一段代码示例:
import difflib
old_text = "This is the old text"
new_text = "This is the new text"
d = difflib.Differ()
diff = d.compare(old_text.splitlines(), new_text.splitlines())
print('\n'.join(diff))
输出结果如下:
This is the old text
- This is the new text
我们可以看到,输出结果中使用了减号标记来表示新文本和原文本之间的不同之处。如果新文本包含了原始文本中不存在的行或单词,则输出结果中将使用加号标记来表示。
基于difflib库的比较非常方便,但是在某些情况下会产生误报,例如:所有标点符号将被视为不同之处,即使它们的位置和数量完全相同。
方法二:基于SequenceMatcher库的比较
与difflib库类似,Python中还有一个名为SequenceMatcher的库,用于比较任意两个序列之间的差异。这个库提供了一些比较准确的方法,同时也可以调整比较参数。
下面是一个示例代码:
from difflib import SequenceMatcher
old_text = "This is the old text"
new_text = "This is the new text"
similarity = SequenceMatcher(None, old_text, new_text).ratio()
print(similarity)
输出结果如下:
0.8627450980392157
与基于difflib库的比较相比,基于SequenceMatcher库的比较更加精确。调整参数后,可以将这种方法应用于更广泛的文本比较任务,例如比较两个HTML文档或两个PDF文件。
方法三:基于NLP库的比较
自然语言处理(Natural Language Processing,简称NLP)是一种人工智能领域,可以使机器理解和处理人类语言。通过使用NLP库,我们可以比较文本之间的相似性和差异。
下面是一个代码示例:
import nltk
from nltk.tokenize import word_tokenize
from nltk.tokenize import sent_tokenize
old_text = "This is the old text"
new_text = "This is the new text"
words_old = word_tokenize(old_text)
words_new = word_tokenize(new_text)
sentences_old = sent_tokenize(old_text)
sentences_new = sent_tokenize(new_text)
diff_words = set(words_old).symmetric_difference(set(words_new))
diff_sentences = set(sentences_old).symmetric_difference(set(sentences_new))
print("Different words:", diff_words)
print("Different sentences:", diff_sentences)
输出结果如下:
Different words: {'new'}
Different sentences: set()
在这个示例中,我们使用了NLTK库,它是一种开源的Python NLP工具包。通过将文本分成句子和单词列表,我们可以使用集合操作来找出差异部分。
这个方法是非常准确的,因为它考虑了语义和上下文,但是在比较长文档时可能会变慢。
结论
通过使用Python中的difflib、SequenceMatcher和NLP库,我们可以快速有效地比较任意两个文本之间的差异。这些方法的准确性和效率因任务而异,因此我们应该根据要求来选择最合适的方法。
如果文本量比较小,我们可以使用difflib库;如果要求更加准确,我们可以使用SequenceMatcher库;如果需要考虑语义和上下文,我们可以使用NLP库。在所有情况下,我们都可以使用Python来解决这些问题,从而使我们的SEO工作更加高效和富有成效。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲
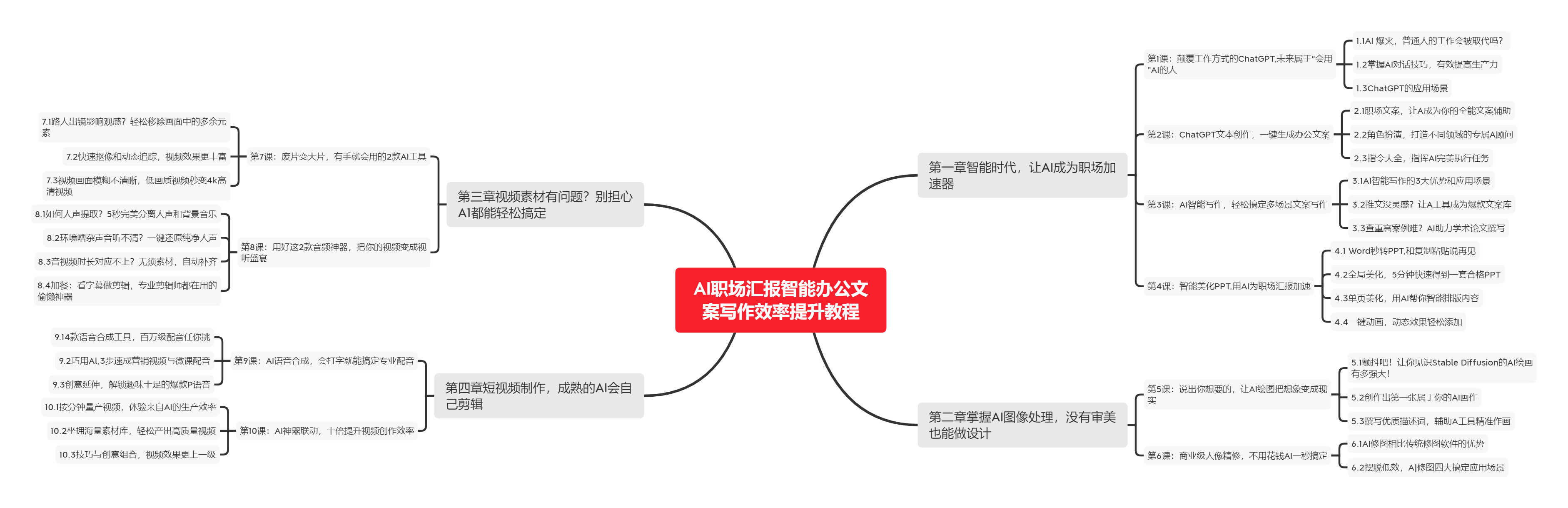

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |







![P31[10-1]软件模拟IIC通信协议(使用stm32库函数)(内含:实物连接+IIC时序解释+硬件电路+IIC基本时序单元(起始 终止 发送接收 ))](https://img-blog.csdnimg.cn/8daa1d681c6e45aa986067e0d8329314.png)